Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans les plans Consommation, Consommation flexible et Premium, Azure Functions met à l’échelle les ressources en ajoutant d’autres instances en fonction du nombre d’événements qui déclenchent une fonction.
La façon dont votre application de fonction se met à l’échelle dépend du plan d’hébergement :
Plan Consommation : chaque instance de l’hôte Functions dans le plan Consommation est typiquement limitée à 1,5 Go de mémoire et un seul processeur. Une instance de l’hôte prend en charge la totalité de l’application de fonction. Par conséquent, toutes les fonctions d’une application de fonction qui partagent des ressources dans une instance sont mises à l’échelle en même temps. Lorsque des applications de fonction partagent le même plan Consommation, elles sont tout de même mises à l’échelle indépendamment.
Plan Flex Consumption : Le plan utilise une stratégie de mise à l’échelle déterministe par fonction. Chaque fonction est mise à l’échelle indépendamment, à l’exception des fonctions déclenchées par HTTP, Blob et Durable Functions qui sont mises à l’échelle dans leurs propres groupes. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Mise à l’échelle par fonction. Ces instances sont ensuite mises à l’échelle en fonction du degré de concurrence de vos requêtes.
Plan Premium : la taille spécifique du plan Premium détermine la mémoire et l’UC disponibles pour toutes les applications de ce plan, sur cette instance. Le plan effectue un scale-out de ses instances en fonction des besoins de mise à l’échelle des applications dans le plan et les applications se mettent à l’échelle au sein du plan en fonction des besoins.
Les fichiers de code de fonction sont stockés dans des partages Azure Files du compte de stockage principal de la fonction. Lorsque vous supprimez le compte de stockage principal de l’application de fonction, les fichiers de code de fonction sont supprimés et ne peuvent pas être récupérés.
Mise à l’échelle du runtime
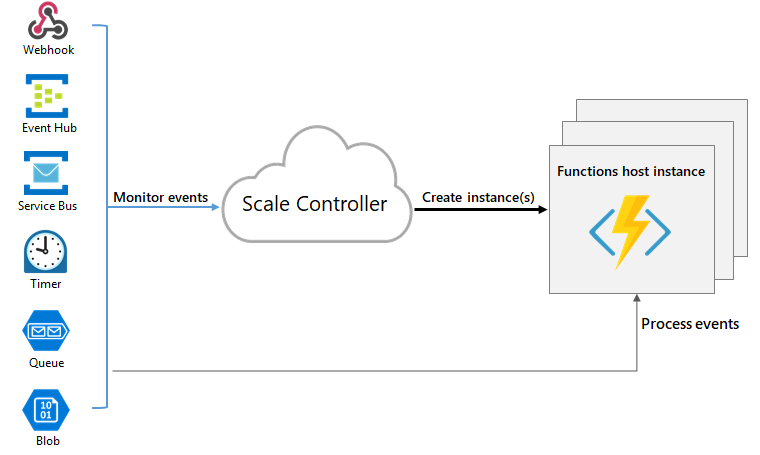
Azure Functions utilise un composant appelé contrôleur de mise à l’échelle pour surveiller la fréquence des événements et déterminer s’il convient d’effectuer un scale-out ou un scale-in. Le contrôleur de mise à l’échelle utilise une méthode heuristique pour chaque type de déclencheur. Par exemple, lorsque vous utilisez un déclencheur de stockage File d’attente Azure, il utilise la mise à l’échelle basée sur la cible.
L’unité d’échelle pour Azure Functions est la Function App. Quand les instances de l’application de fonction font l’objet d’une augmentation de taille, d’autres ressources sont allouées pour exécuter plusieurs instances de l’hôte Azure Functions. À l’inverse, quand la demande de calcul est réduite, le contrôleur de mise à l’échelle supprime des instances de l’hôte de fonction. Le nombre d’instances est finalement réduit si aucune fonction n’est exécutée dans une application de fonction.
Démarrage à froid
Si votre application de fonction reste inactive pendant quelques minutes, la plateforme peut décider de réduire à zéro le nombre d’instances sur lesquelles votre application s’exécute. La prochaine requête présente la latence supplémentaire de la mise à l’échelle de zéro à un. Cette latence est appelée démarrage à froid. Le nombre de dépendances requises par votre application de fonction peut avoir un impact sur le temps de démarrage à froid. Le démarrage à froid est plus problématique pour les opérations synchrones, telles que les déclencheurs HTTP, qui doivent retourner une réponse. Si les démarrages à froid affectent vos fonctions, envisagez d’utiliser un plan autre que le plan Consommation. Les autres plans fournissent ces stratégies pour atténuer ou éliminer les démarrages à froid :
Plan Premium : prend en charge les instances préchauffées et les instances toujours prêtes, avec un minimum d’une instance.
Plan Consommation flexible : prend en charge un nombre variable d’instances toujours prêtes, lesquelles peuvent être définies sur une base de mise à l’échelle par instance.
Plan dédié : le plan lui-même n’est pas mis à l’échelle dynamiquement, mais vous pouvez exécuter votre application en continu lorsque le paramètre Always On est activé.
Présentation des comportements de mise à l’échelle
La mise à l’échelle peut varier en fonction de plusieurs facteurs et la mise à l’échelle des applications s’effectue selon les déclencheurs et le langage sélectionnés. Il est nécessaire de connaître certaines subtilités relatives aux comportements de mise à l’échelle :
- Nombre maximal d’instances : une application de fonction peut faire l’objet d’un scale-out jusqu’au maximum autorisé par le plan. Toutefois, une seule instance peut traiter plusieurs messages ou requêtes à la fois. Vous pouvez spécifier une valeur maximale inférieure pour limiter l’échelle en fonction des besoins.
- Taux de nouvelles instances : pour les déclencheurs HTTP, de nouvelles instances sont allouées, au plus, une fois par seconde. Pour les déclencheurs non HTTP, de nouvelles instances sont allouées, au plus, une fois toutes les 30 secondes. La mise à l’échelle est plus rapide lors de l’exécution dans plan Premium.
- Mise à l’échelle basée sur des cibles : La mise à l’échelle basée sur des cibles fournit un modèle de mise à l’échelle rapide et intuitif pour les clients. Actuellement, cette méthode de mise à l’échelle est prise en charge pour les files d’attente et rubriques Service Bus, les files d’attente de stockage, Event Hubs, Apache Kafka et les extensions Azure Cosmos DB. Veillez à passer en revue la mise à l’échelle basée sur la cible pour comprendre leur comportement de mise à l’échelle.
- Mise à l’échelle par fonction : à quelques exceptions notables près, les fonctions exécutées dans le cadre du plan Consommation flexible sont mises à l’échelle sur des instances indépendantes. Les exceptions incluent des déclencheurs HTTP et des déclencheurs de stockage Blob (Event Grid). Chacun de ces types de déclencheurs est mis à l’échelle en tant que groupe sur les mêmes instances. De même, les déclencheurs de toutes les fonctions durables partagent des instances et se mettent à l’échelle ensemble. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Mise à l’échelle par fonction.
- Nombre maximal de déclencheurs supervisés : actuellement, le contrôleur de mise à l’échelle ne peut surveiller que 100 déclencheurs pour prendre des décisions de mise à l’échelle. Lorsque votre application comporte plus de 100 déclencheurs basés sur les événements, les décisions de mise à l’échelle sont prises uniquement en fonction des 100 premiers déclencheurs qui s’exécutent. Pour en savoir plus, consultez Bonnes pratiques et modèles pour les applications scalables.
Limiter le scale-out
Vous pouvez décider de restreindre le nombre maximal d’instances qu’une application peut utiliser pour effectuer un scale-out. Cette limitation est la plus courante pour les cas où un composant en aval comme une base de données a un débit limité. Pour connaître les limites de mise à l’échelle maximales lors de l’exécution des plusieurs plans d’hébergement, consultez Limites de mise à l’échelle.
Plan Consommation flexible
Par défaut, les applications qui s’exécutent dans le cadre d’un plan Consommation flexible ont une limite d’instances globales de 100. Actuellement, la valeur maximale la plus basse pour le nombre d’instances est 1 et la valeur maximale la plus élevée prise en charge est 1000. Lorsque vous utilisez la commande az functionapp create pour créer une application de fonction dans le cadre du plan Consommation flexible, utilisez le paramètre --maximum-instance-count pour définir ce nombre d’instances maximum pour votre application.
Bien que vous puissiez modifier le nombre maximal d’instances des applications Flex Consumption jusqu’à 1 000, la limite de quota pour vos applications est atteinte avant d’atteindre ce nombre. Consultez Quotas de mémoire régionaux de l’abonnement pour en savoir plus.
Cet exemple montre comment créer une application avec un nombre maximal de 200 instances :
az functionapp create --resource-group <RESOURCE_GROUP> --name <APP_NAME> --storage <STORAGE_ACCOUNT_NAME> --runtime <LANGUAGE_RUNTIME> --runtime-version <RUNTIME_VERSION> --flexconsumption-location <REGION> --maximum-instance-count 200
Cet exemple utilise la commande az functionapp scale config set pour faire passer le nombre maximal d’instances d’une application existante à 150 :
az functionapp scale config set --resource-group <RESOURCE_GROUP> --name <APP_NAME> --maximum-instance-count 150
Plans Consommation/Premium
Dans un plan Consommation ou Elastic Premium, vous pouvez spécifier une limite maximale inférieure pour votre application en modifiant la valeur du paramètre de configuration de site functionAppScaleLimit. Le functionAppScaleLimit peut être défini sur 0 ou sur null pour une utilisation sans restriction, ou sur une valeur valide comprise entre 1 et le maximum de l’application.
az resource update --resource-type Microsoft.Web/sites -g <RESOURCE_GROUP> -n <FUNCTION_APP-NAME>/config/web --set properties.functionAppScaleLimit=<SCALE_LIMIT>
Comportements de scale-in
La mise à l’échelle pilotée par les événements réduit automatiquement la capacité lorsque la demande de vos fonctions est réduite. Il effectue cette réduction en vidant les instances de leurs exécutions de fonction actuelles, puis supprime ces instances. Ce comportement est enregistré en mode maintenance. La période de grâce pour les fonctions en cours d’exécution peut aller jusqu’à 10 minutes pour les applications du plan Consommation et jusqu’à 60 minutes pour les applications des plans Consommation flexible et Premium. La mise à l’échelle pilotée par les événements et ce comportement ne s’appliquent pas aux applications de plan dédié.
Les considérations suivantes s’appliquent aux comportements de scale-in :
- Pour les applications s’exécutant sur Windows dans un plan Consommation, seules les applications créées après mai 2021 ont des comportements de mode drain activés par défaut.
- Pour activer l’arrêt normal pour les fonctions à l’aide du déclencheur Service Bus, utilisez la version 4.2.0 ou une version ultérieure de l’extension Service Bus.
Mise à l’échelle par fonction
S’applique uniquement au plan Consommation flexible.
Le plan Consommation flexible est unique dans la mesure où il implémente un comportement de mise à l’échelle par fonction. Dans le cadre de la mise à l’échelle par fonction, à l’exception des déclencheurs HTTP, des déclencheurs Blob (Event Grid) et des fonctions durables, tous les autres types de déclencheurs de fonction de votre application sont mis à l’échelle sur des instances indépendantes. Les déclencheurs HTTP de votre application sont tous mis à l’échelle ensemble en tant que groupe sur les mêmes instances, comme tous les déclencheurs Blob (Event Grid) et tous les déclencheurs Durable Functions, qui ont leurs propres instances partagées.
Considérez une application de fonction hébergée par un plan Flex Consumption qui a les fonctions suivantes :
| function1 | function2 | function3 | function4 | function5 | function6 | function7 |
|---|---|---|---|---|---|---|
| Déclencheur HTTP | Déclencheur HTTP | Déclencheur d’orchestration (durable) | Déclencheur d’activité (durable) | Déclencheur Service Bus | Déclencheur Service Bus | Déclencheur Event Hubs |
Dans cet exemple :
- Les deux fonctions déclenchées par HTTP (
function1etfunction2) s’exécutent ensemble sur leurs propres instances et se mettent à l’échelle ensemble en fonction des paramètres de concurrence HTTP. - Les deux fonctions Durables (
function3etfunction4) s’exécutent ensemble sur leurs propres instances et se mettent à l’échelle ensemble en fonction des limites de concurrence configurées. - La fonction
function5déclenchée par Service Bus s’exécute de manière autonome et est mise à l’échelle indépendamment en fonction des règles de mise à l’échelle basées sur la cible pour les files d’attente et les rubriques Service Bus. - La fonction
function6déclenchée par Service Bus s’exécute de manière autonome et est mise à l’échelle indépendamment en fonction des règles de mise à l’échelle basées sur la cible pour les files d’attente et les rubriques Service Bus. - Le déclencheur Event Hubs (
function7) s’exécute dans ses propres instances et est mis à l’échelle indépendamment en fonction des règles de mise à l’échelle basées sur la cible pour Event Hubs.
Bonnes pratiques et modèles pour les applications scalables
Nombreux sont les aspects d’une application de fonction qui impactent sa mise à l’échelle, notamment la configuration de l’hôte, l’empreinte du runtime et l’efficacité des ressources. Pour plus d’informations, consultez la section sur l’extensibilité dans l’article Considérations relatives aux performances. Vous devez également savoir ce qu’il se passe au niveau des connexions lors de la mise à l’échelle de votre application de fonction. Pour plus d’informations, consultez How to manage connections in Azure Functions (Comment gérer des connexions dans Azure Functions).
Si votre application comporte plus de 100 fonctions qui utilisent des déclencheurs basés sur des événements, envisagez de la fractionner en une ou plusieurs applications dans lesquelles chaque application a moins de 100 fonctions basées sur des événements.
Pour plus d’informations sur la mise à l’échelle dans Python et Node.js, consultez la section Mise à l’échelle et performances du guide du développeur Python Azure Functions et de la section Mise à l’échelle et concurrence du guide du développeur azure Functions Node.js.
Étapes suivantes
Pour en savoir plus, consultez les articles suivants :