Diagnostic approfondi des applications et services web avec Application Insights
Cet article explique comment Application Insights s’intègre au cycle DevOps.
Pourquoi ai-je besoin d’Application Insights ?
Application Insights surveille votre application web en cours d’exécution. Il signale les défaillances et les problèmes de performances, et permet d’analyser comment les clients utilisent votre application. Il fonctionne pour les applications s’exécutant sur des plateformes comme ASP.NET, Java EE et Node.js. Il est hébergé dans le cloud ou localement.
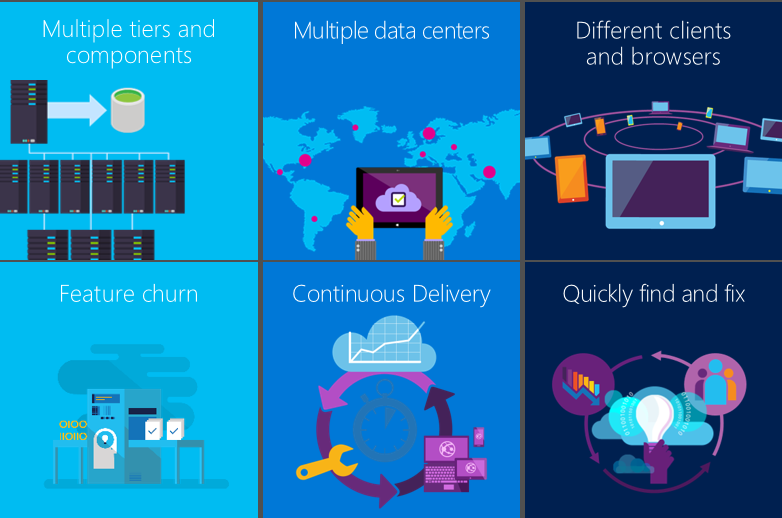
Monitorer une application moderne pendant son exécution est essentiel. Vous voulez détecter les défaillances avant vos clients. Vous voulez aussi découvrir et corriger les problèmes de performances qui ralentissent le fonctionnement ou pénalisent vos utilisateurs. Quand le système fonctionne comme prévu, vous voulez savoir ce que les utilisateurs en font. Par exemple, utilisent-ils la dernière fonctionnalité ? Sont-ils satisfaits par celle-ci ?
Les applications web modernes sont développées dans un cycle de livraison continue :
- Publier une nouvelle fonctionnalité ou une amélioration.
- Observer son fonctionnement pour les utilisateurs.
- Planifier l’incrément de développement suivant en fonction de ces connaissances.
La phase d’observation de ce cycle est essentielle. Application Insights fournit les outils permettant de surveiller les performances et l’utilisation d’une application web.
L’aspect le plus important de ce processus est le diagnostic. Si l’application échoue, on perd des clients. Le rôle principal d’une infrastructure de monitoring est de :
- Détecter les défaillances de manière fiable.
- Vous avertir immédiatement.
- Vous présenter les informations nécessaires pour diagnostiquer le problème.
Application Insights fait tout ça.
D'où proviennent les bogues ?
Dans les systèmes web, les défaillances proviennent généralement de problèmes de configuration ou de mauvaises interactions entre les multiples composants. La première tâche pour traiter un incident sur un site en ligne est de situer le problème. Quel est le composant ou la relation en cause ?
À une époque plus simple, un programme informatique s’exécutait sur un ordinateur. Les développeurs le testait à fond avant de livrer, et après la livraison, ils avaient rarement l’occasion de le revoir ou d’y repenser. Les utilisateurs devaient supporter les éventuels bogues résiduels pendant des années.
Le processus est très différent maintenant. Votre application s’exécute sur une multitude d’appareils différents et il est difficile de garantir exactement le même comportement sur chacun d’eux. L’hébergement d’applications dans le cloud signifie que les bogues peuvent être résolus rapidement. Toutefois, cela se traduit également par une concurrence permanente et l’attente de nouvelles fonctionnalités à intervalles rapprochés.
Dans ces conditions, la seule façon de garder le contrôle sur le nombre de bogues est d’automatiser les tests unitaires. Il est impossible de tout retester manuellement à chaque version. Le test unitaire fait désormais partie du processus de compilation. Des outils tels que Xamarin Test Cloud permettent d’automatiser le test d’interfaces utilisateur sur plusieurs versions de navigateur. Ils nous permettent de minimiser le nombre de bogues trouvés dans une application.
Les applications web classiques ont de nombreux composants actifs. En plus du client (dans un navigateur ou une application d’appareil) et du serveur web, il y a généralement un traitement de back-end important. Par exemple, le back-end est un pipeline de composants ou un ensemble moins imbriqué d’éléments en interrelation. Beaucoup d’entre eux ne sont pas sous votre contrôle. Il s’agit de services externes dont vous dépendez.
Dans de telles configurations, il peut être difficile et onéreux de tester ou prévoir, chaque mode de défaillance, outre le système lui-même.
Questions
Voici des questions à vous poser quand vous développez un système web :
- Votre application se bloque-t-elle ?
- Que s’est-il passé exactement ? Si une demande n’a pas pu être traitée, vous voulez savoir pourquoi. Vous avez besoin d’une trace des événements.
- Votre application est-elle assez rapide ? Combien de temps lui faut-il pour répondre aux demandes classiques ?
- Le serveur peut-il gérer la charge ? Lorsque le taux de demandes augmente, le temps de réponse reste-t-il stable ?
- Quel est le niveau de réactivité de vos dépendances (API REST, bases de données et autres composants appelés par votre application) ? En particulier, si le système est lent, est-ce que c’est dû à votre composant ou est-ce que vous recevez des réponses lentes de quelqu’un d’autre ?
- Votre application est-elle active ou inactive ? Le monde entier peut-il le voir ? Vous devez savoir si elle s’arrête.
- Quelle est la cause racine ? Le problème vient de votre composant ou d’une dépendance ? Est-ce un problème de communication ?
- Combien d’utilisateurs sont affectés ? Si vous avez plusieurs problèmes à résoudre, quel est le plus important ?
Présentation d’Application Insights
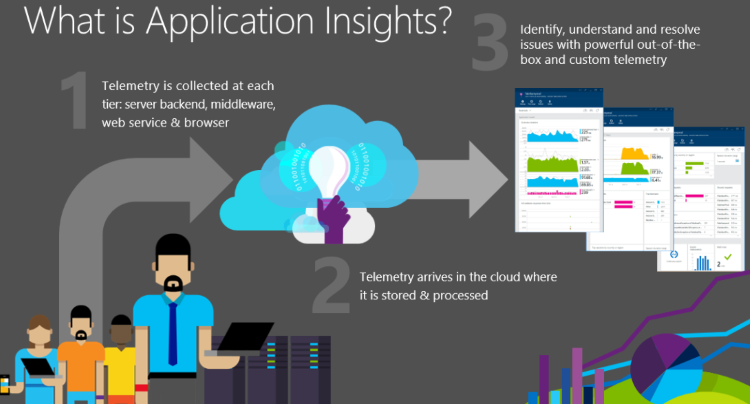
- Application Insights analyse votre application et envoie les données télémétriques la concernant pendant son exécution. Vous pouvez générer le SDK Application Insights dans l’application ou appliquer l’instrumentation pendant l’exécution. La première méthode est plus flexible, car vous pouvez ajouter votre propre télémétrie aux modules standard.
- Les données de télémétrie sont envoyées au portail Application Insights, où elles sont stockées et traitées. Bien qu’hébergé dans Azure, Application Insights peut monitorer toutes les applications web et pas seulement les applications Azure.
- Les données télémétriques sont présentées sous la forme de graphiques et de tableaux d’événements.
Il existe deux principaux types de données télémétriques : les instances agrégées et les instances brutes.
- Les données d’instance sont, par exemple, le rapport d’une demande reçue par votre application web. Vous pouvez rechercher et inspecter les détails d’une demande en utilisant l’outil de recherche du portail Application Insights. L’instance peut comprendre des données comme le temps de réponse de votre application à la demande, l’URL demandée et l’emplacement approximatif du client.
- Les données agrégées comprennent le nombre d’événements par unité de temps pour que vous puissiez comparer le nombre de demandes aux temps de réponse. Elles indiquent également les moyennes des métriques, comme les temps de réponse aux demandes.
Les principales catégories de données sont les suivantes :
- Demandes envoyées à votre application (généralement des requêtes HTTP), avec des données sur l’URL, le temps de réponse, et l’indication de réussite ou d’échec.
- Dépendances, comme des appels REST et SQL effectués par votre application, avec l’URI, les temps de réponse et l’indication de réussite.
- Exceptions, y compris les traces de pile.
- Données sur les vues de page, provenant des navigateurs des utilisateurs.
- Métriques, comme les compteurs de performances et les métriques que vous écrivez vous-même.
- Événements personnalisés que vous pouvez utiliser pour suivre les événements métier.
- Traces de journal utilisées pour le débogage.
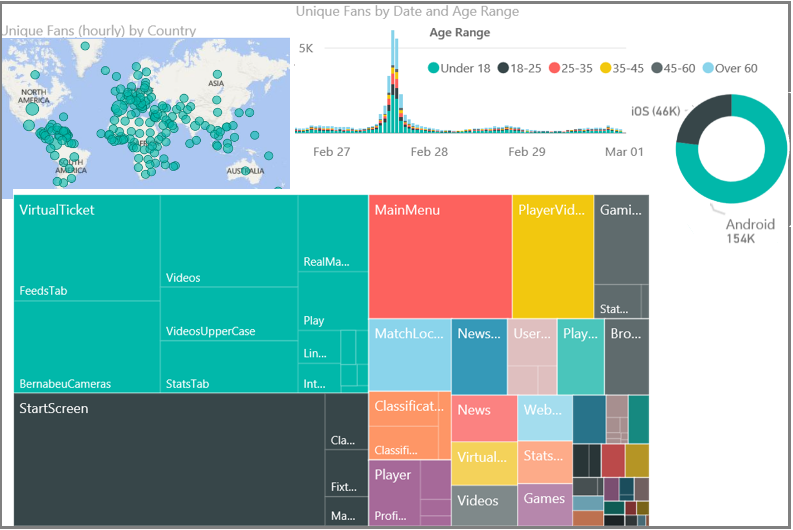
Étude de cas : Real Madrid F.C.
Le service web du club de football Real Madrid est visité par environ 450 millions de supporters dans le monde entier. Les supporters y accèdent par des navigateurs web et les applications mobiles du club. Les supporters peuvent acheter des billets, mais aussi accéder à des informations et regarder des vidéos sur les résultats, les joueurs et les prochains matchs. Ils peuvent faire des recherches avec des filtres, comme le nombre de buts marqués. Le site contient également des liens vers les réseaux sociaux. L’expérience utilisateur est très personnalisée et conçue comme une communication bidirectionnelle pour privilégier l’interaction avec les supporters.
La solution est un système de services et d’applications sur Azure. La scalabilité est une exigence clé. Le trafic est variable et peut atteindre des sommets avant, pendant et après les matchs.
Pour le Real Madrid, surveiller les performances du système est primordial. Application Insights offre une vue complète du système pour assurer un niveau de service fiable et élevé.
Le club en tire également une connaissance approfondie de ses supporters, comme où ils se trouvent (seulement 3 % sont en Espagne), leur intérêt vis-à-vis des joueurs, les résultats historiques, les prochains matchs et leurs réactions aux résultats.
La plupart de ces données de télémétrie sont collectées automatiquement sans code ajouté, ce qui simplifie la solution et réduit la complexité opérationnelle. Pour le Real Madrid, Application Insights gère 3,8 milliards de points de télémétrie par mois.
Le Real Madrid utilise le module Power BI pour voir sa télémétrie.
Détection intelligente
Diagnostics proactifs est une fonctionnalité récente. Sans aucune configuration particulière, Application Insights détecte automatiquement et signale toute hausse inhabituelle du nombre de défaillances dans votre application. L’application est suffisamment intelligente pour ignorer les défaillances occasionnelles et les hausses qui sont simplement proportionnelles à une hausse des demandes.
Par exemple, il peut y avoir une défaillance dans l’un des services dont vous dépendez. Peut-être aussi que la nouvelle build que vous avez déployée ne fonctionne pas bien. Vous le saurez dès que vous consulterez vos e-mails. Les webhooks vous permettent aussi de déclencher d’autres applications.
Par ailleurs, cette fonction effectue quotidiennement une analyse approfondie de vos données télémétriques, en y recherchant des performances inhabituelles difficiles à détecter. Par exemple, elle peut identifier un faible niveau de performance dans une zone géographique ou avec une version spécifique d’un navigateur.
Dans les deux cas, l’alerte vous indique les symptômes qu’elle a découverts. Elle vous donne aussi les données dont vous avez besoin pour diagnostiquer le problème, comme les rapports d’exception correspondants.

Le client Samtec a déclaré : « Récemment, pendant une interruption du service, nous avons trouvé une base de données sous-dimensionnée qui atteignait la limite de ses ressources, provoquant l’expiration des délais d’attente. Des alertes de détection proactives nous parvenaient pendant que nous étions en temps de traiter le problème, en quasi temps réel comme annoncé par notre publicité. Ces alertes, couplées à celles de la plateforme Azure, nous ont permis de résoudre le problème presque instantanément. Temps d’arrêt total < 10 minutes. »
Live Metrics Stream (Flux continu de mesures)
Le déploiement de la dernière build en date peut être très stressant. S’il y a des problèmes, vous voulez le savoir immédiatement pour corriger la situation si nécessaire. Live Metrics Stream (Flux continu de mesures) fournit des mesures clés avec une latence d’environ une seconde.
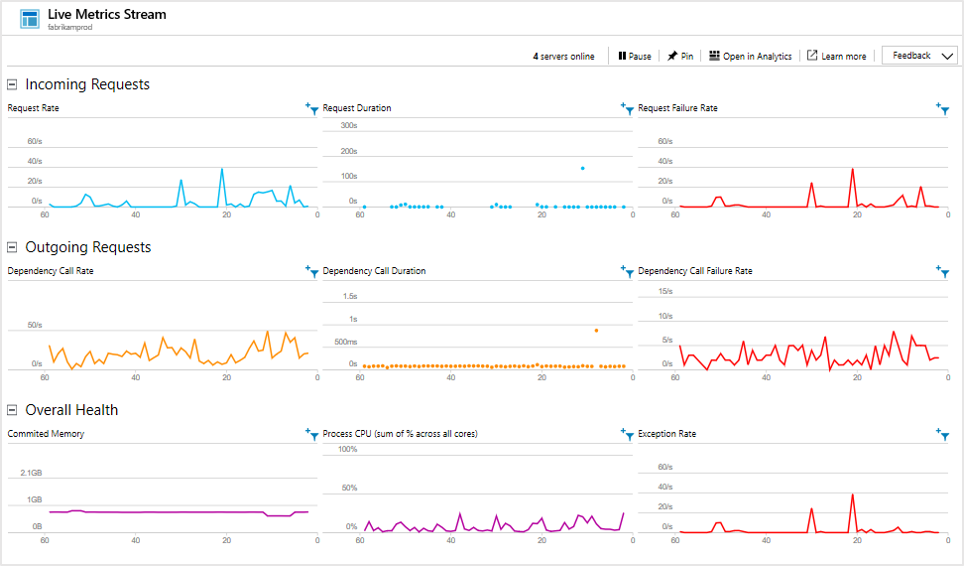
Il vous permet d’inspecter immédiatement un échantillon des échecs ou exceptions éventuels.
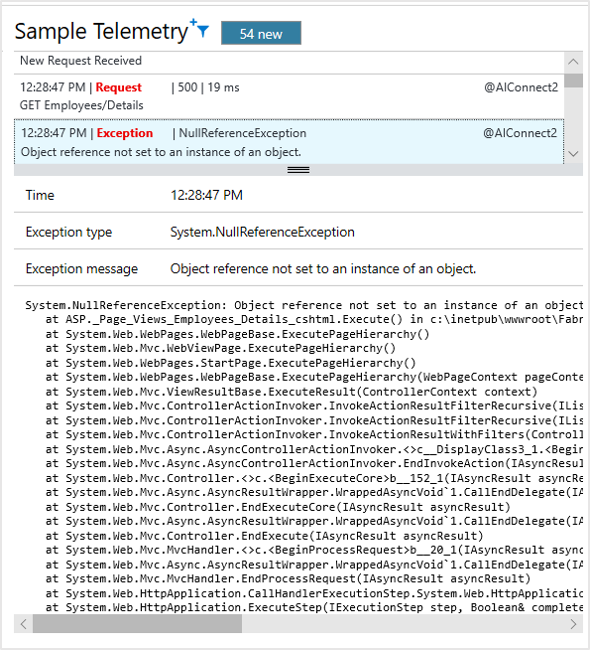
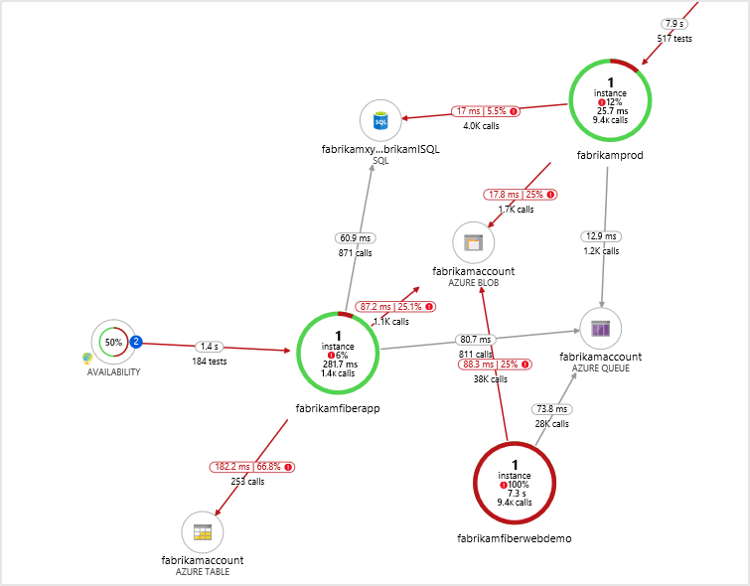
Mise en correspondance d'applications
La cartographie d’application découvre automatiquement la topologie de votre application. Elle place les informations de performances sur la carte pour vous permettre d’identifier facilement les goulots d’étranglement et les flux problématiques dans votre environnement distribué. Avec la cartographie d’application, vous pouvez découvrir les dépendances d’application sur les services Azure.
Vous pouvez orienter un problème en comprenant s’il est lié au code ou à une dépendance. Sans changer d’endroit, vous pouvez utiliser l’expérience de diagnostic associée. Par exemple, votre application peut échouer en raison d’une détérioration des performances dans une couche SQL. Avec la cartographie d’application, vous pouvez le voir immédiatement et utiliser l’expérience SQL Index Advisor ou Query Insights.
Application Insights Log Analytics
Avec Log Analytics, vous pouvez écrire des requêtes arbitraires dans un langage puissant de type SQL. Le diagnostic sur l’ensemble de la pile d’application devient facile quand les diverses perspectives sont connectées. Vous pouvez ensuite poser les bonnes questions pour mettre en corrélation les performances du service avec les métriques métier et l’expérience client.
Vous pouvez interroger toutes les données des mesures et de l’instance de télémétrie, stockées dans le portail. Le langage comprend des opérations de filtrage, de jointure, d’agrégation et autres. Vous pouvez calculer des champs et effectuer une analyse statistique. Des visualisations tabulaires et graphiques sont disponibles.
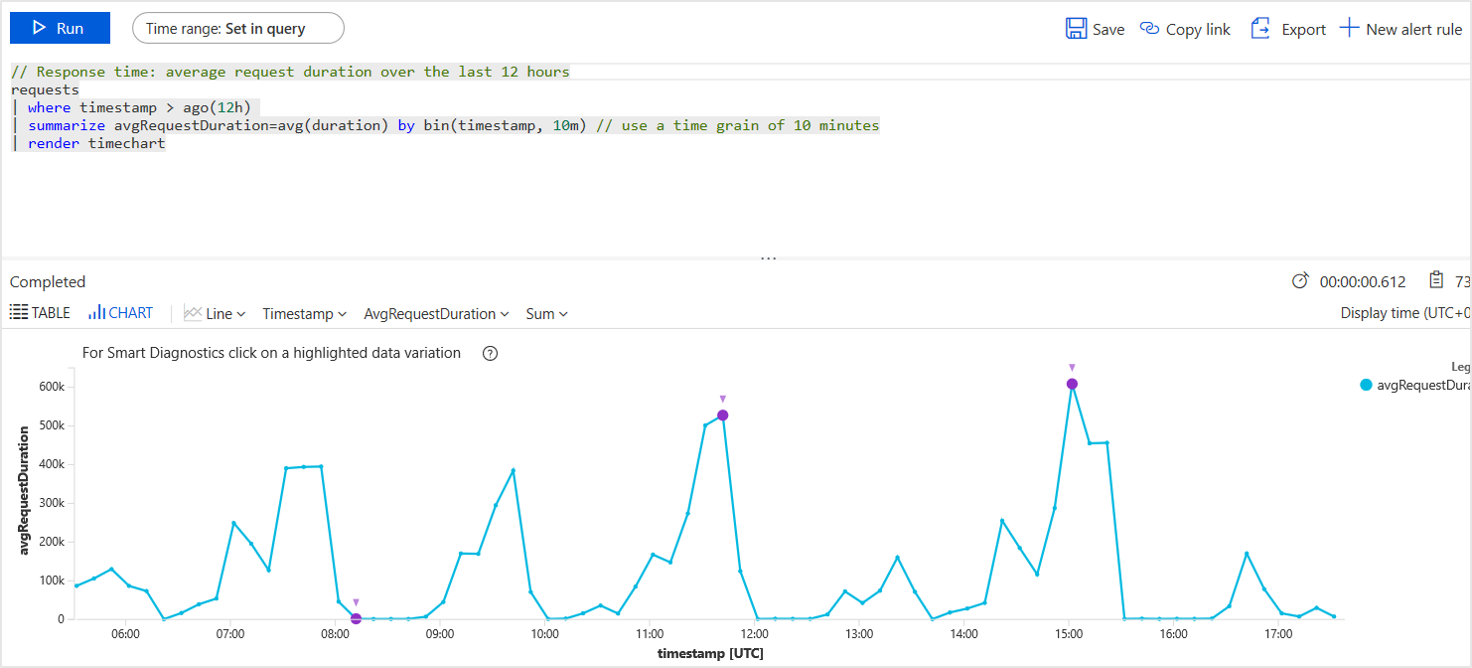
Par exemple, les opérations suivantes sont faciles :
- Segmenter les données de performances des demandes de votre application par niveaux de client pour comprendre leur expérience.
- Rechercher des codes d’erreur spécifiques ou des noms d’événement personnalisés pendant l’analyse d’un site actif.
- Explorer l’utilisation de l’application par certains clients pour déterminer comment les fonctionnalités sont acquises et adoptées.
- Analyser les sessions et les temps de réponse de certains utilisateurs pour permettre aux équipes de support et d’exploitation d’aider les clients instantanément.
- Déterminer les fonctionnalités d’application fréquemment utilisées pour répondre aux questions sur la hiérarchisation des fonctionnalités.
Le client DNN a déclaré : « Application Insights nous a fourni la pièce manquante du puzzle en nous permettant de combiner, trier, interroger et filtrer les données selon nos besoins. Le fait que notre équipe puisse utiliser sa propre ingéniosité et sa propre expérience pour trouver des données grâce à un puissant langage d’interrogation nous a permis de mettre au jour des informations et de résoudre des problèmes dont nous-même ignorions l’existence. Beaucoup de réponses intéressantes font suite à des questions commençant par '' Je me demande si...'' . »
Intégration d’outils de développement
Application Insights s’intègre aux outils de développement.
Configurer Application Insights
Visual Studio et Eclipse ont des outils pour configurer les packages SDK correspondant au projet que vous développez. Il existe une commande de menu permettant d’ajouter Application Insights.
Si vous utilisez un framework de journalisation des traces, comme Log4N, NLog ou System.Diagnostics.Trace, vous pouvez envoyer les journaux à Application Insights avec les autres données de télémétrie, ce qui facilite la mise en corrélation des traces avec les demandes, les appels de dépendance et les exceptions.
Recherche de données télémétriques dans Visual Studio
Quand vous développez et déboguez une fonctionnalité, vous pouvez voir et rechercher les données de télémétrie directement dans Visual Studio. Vous pouvez utiliser les mêmes fonctionnalités de recherche que dans le portail web.
Quand Application Insights journalise une exception, vous pouvez voir le point de données dans Visual Studio et accéder directement au code concerné.
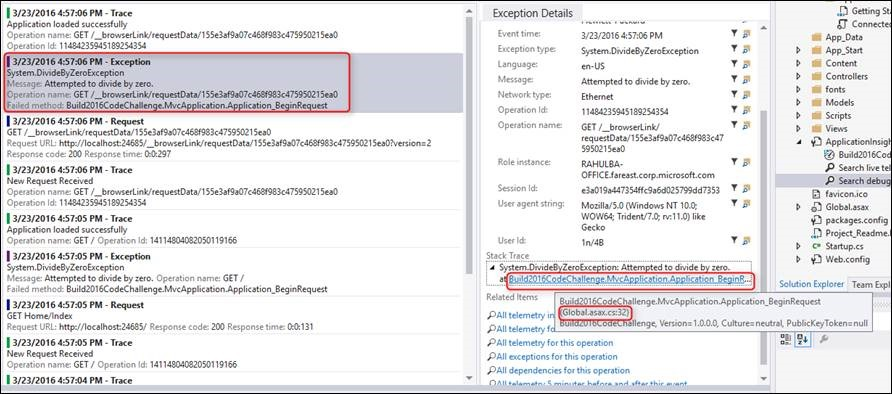
Pendant le débogage, vous pouvez conserver les données de télémétrie dans votre machine de développement. Vous pouvez le voir dans Visual Studio sans l’envoyer dans le portail. Cela évite de mélanger le débogage avec les données télémétriques de production.
Éléments de travail
Lorsqu’une alerte est émise, Application Insights peut automatiquement créer un élément de travail dans votre système de suivi du travail.