Tutoriel : Détecter et analyser des anomalies à l’aide des fonctionnalités de Machine Learning KQL dans Azure Monitor
Le Langage de requête Kusto (KQL) inclut des opérateurs, des fonctions et des plug-ins Machine Learning pour l’analyse de séries chronologiques, la détection des anomalies, la prévision et l’analyse de la cause racine. Utilisez ces fonctionnalités KQL pour effectuer une analyse avancée des données dans Azure Monitor sans surcharge liée à l’exportation de données vers des outils de Machine Learning externes.
Dans ce tutoriel, vous apprenez à effectuer les opérations suivantes :
- Créer une série chronologique
- Identifier les anomalies dans une série chronologique
- Ajuster les paramètres de détection d’anomalie pour affiner les résultats
- Analyser la cause racine des anomalies
Notes
Ce tutoriel fournit des liens vers un environnement de démonstration Log Analytics dans lequel vous pouvez exécuter les exemples de requête KQL. Toutefois, vous pouvez implémenter les mêmes requêtes et principaux KQL dans tous les outils Azure Monitor qui utilisent KQL.
Prérequis
- Compte Azure avec un abonnement actif. Créez un compte gratuitement.
- Un espace de travail avec des données de journal.
Autorisations requises
Vous devez disposer d’autorisations Microsoft.OperationalInsights/workspaces/query/*/read dans les espaces de travail Log Analytics que vous interrogez, comme fourni par le rôle intégré de Lecteur Log Analytics, par exemple.
Créer une série chronologique
Utilisez l’opérateur KQL make-series pour créer une série chronologique.
Créons une série chronologique basée sur les journaux dans la table Utilisation, qui contient des informations sur la quantité de données ingérées par chaque table d’un espace de travail toutes les heures, y compris les données facturables et non facturables.
Cette requête utilise make-series pour représenter le graphique de la quantité totale de données facturables ingérées par chaque table de l’espace de travail chaque jour, au cours des 21 derniers jours :
Cliquer pour exécuter la requête
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Dans le graphique résultant, vous pouvez voir clairement certaines anomalies, par exemple, dans les types de données AzureDiagnostics et SecurityEvent :
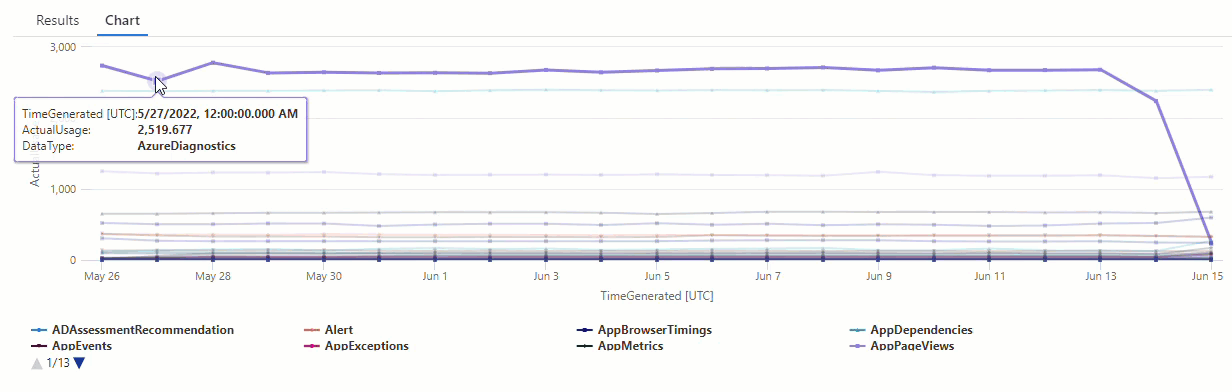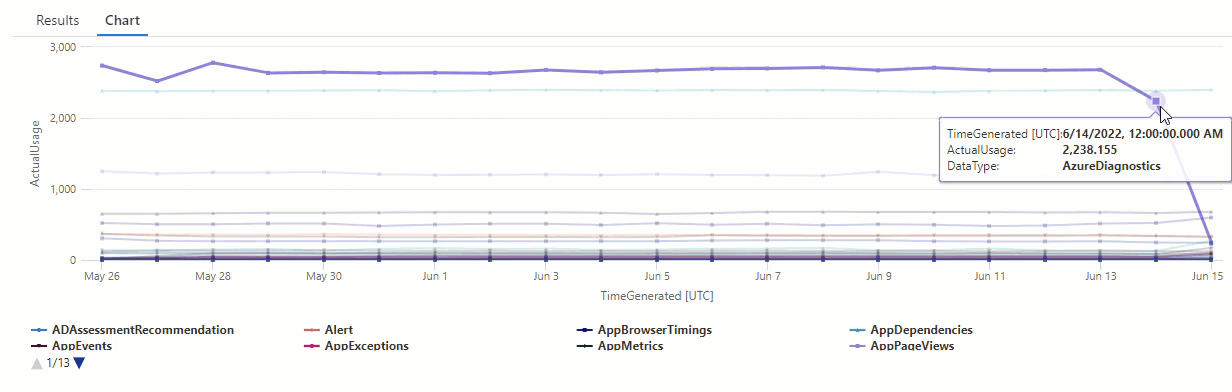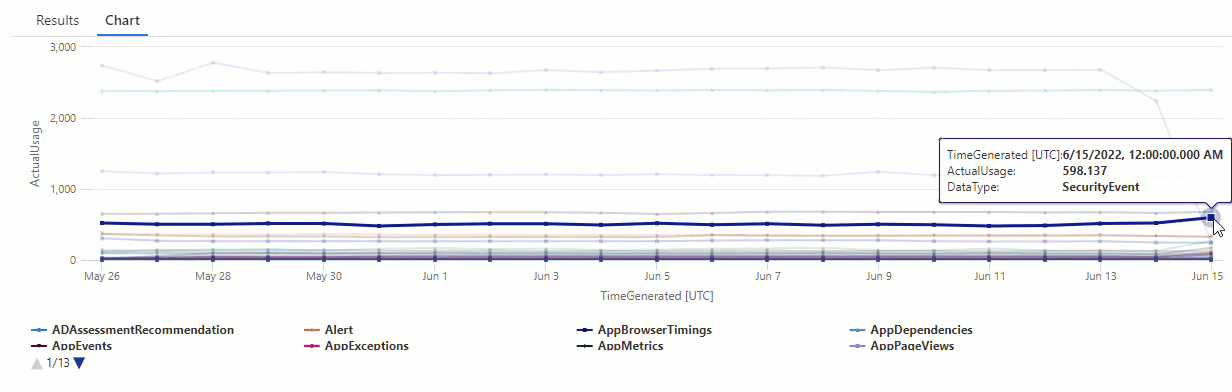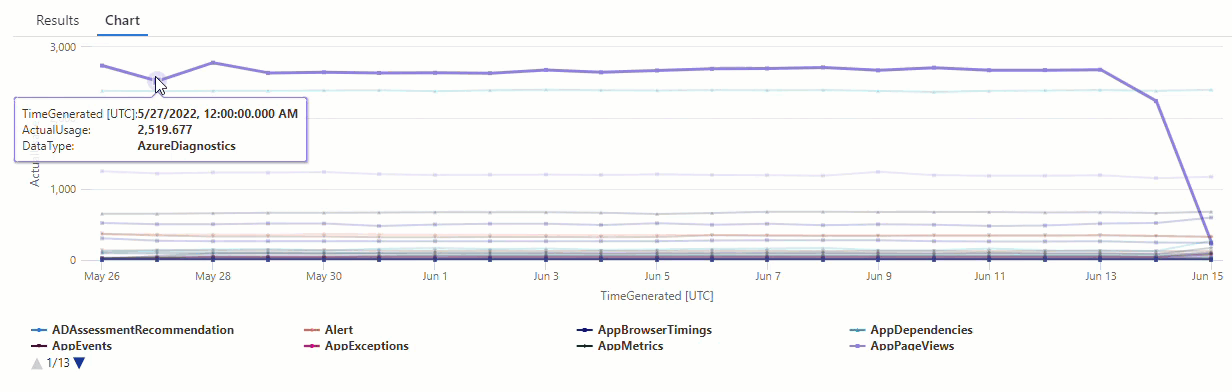
Ensuite, nous allons utiliser une fonction KQL pour répertorier toutes les anomalies d’une série chronologique.
Notes
Pour plus d’informations sur la syntaxe et l’utilisation de make-series, consultez Opérateur make-series.
Trouver les anomalies dans une série chronologique
La fonction series_decompose_anomalies() prend une série de valeurs comme entrée et extrait les anomalies.
Nous allons donner le jeu de résultats de notre requête de série chronologique comme entrée à la fonction series_decompose_anomalies() :
Cliquer pour exécuter la requête
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Cette requête retourne toutes les anomalies d’utilisation pour toutes les tables au cours des trois dernières semaines :

En examinant les résultats de la requête, vous pouvez voir que la fonction :
- Calcule une utilisation quotidienne attendue pour chaque table.
- Compare l’utilisation quotidienne réelle à l’utilisation attendue.
- Affecte un score d’anomalie à chaque point de données, indiquant l’étendue de l’écart entre l’utilisation réelle et l’utilisation attendue.
- Identifie les anomalies positives (
1) et négatives (-1) dans chaque table.
Notes
Pour plus d’informations sur la syntaxe et l’utilisation de series_decompose_anomalies(), consultez series_decompose_anomalies().
Ajuster les paramètres de détection d’anomalie pour affiner les résultats
Il est recommandé d’examiner les résultats initiaux de la requête et d’apporter des ajustements à la requête, si nécessaire. Les valeurs hors norme dans les données d’entrée peuvent affecter l’apprentissage de la fonction, et vous devrez peut-être ajuster les paramètres de détection d’anomalie de la fonction pour obtenir des résultats plus précis.
Filtrez les résultats de la requête series_decompose_anomalies() pour les anomalies dans le type de données AzureDiagnostics :

Les résultats montrent deux anomalies le 14 juin et le 15 juin. Comparez ces résultats avec le graphique de notre première requête make-series, où vous pouvez voir d’autres anomalies les 27 et 28 mai :

La différence dans les résultats se produit parce que la fonction series_decompose_anomalies() note des anomalies par rapport à la valeur d’utilisation attendue, que la fonction calcule en fonction de la plage complète de valeurs dans la série d’entrée.
Pour obtenir des résultats plus affinés à partir de la fonction, excluez l’utilisation du 15 juin (qui est une valeur aberrante par rapport aux autres valeurs de la série) du processus d’apprentissage de la fonction.
La syntaxe de la fonction series_decompose_anomalies() est la suivante :
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points spécifie le nombre de points à exclure du processus d’apprentissage (régression) à la fin de la série.
Pour exclure le dernier point de données, définissez Test_points sur 1 :
Cliquer pour exécuter la requête
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtrez les résultats pour le type de données AzureDiagnostics :

Toutes les anomalies dans le graphique de notre première requête make-series apparaissent maintenant dans le jeu de résultats.
Analyser la cause racine des anomalies
La comparaison des valeurs attendues à des valeurs anormales vous aide à comprendre la cause des différences entre les deux jeux.
Le plug-in KQL diffpatterns() compare deux jeux de données de la même structure et recherche les modèles qui caractérisent les différences entre les deux jeux de données.
Cette requête compare l’utilisation de AzureDiagnostics du 15 juin, la valeur aberrante extrême dans notre exemple, avec l’utilisation de la table les autres jours :
Cliquer pour exécuter la requête
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
La requête identifie chaque entrée de la table comme se produisant à la date AnomalyDate (le 15 juin) ou OtherDates. Le plug-in diffpatterns() fractionne ensuite ces jeux de données, appelés A (OtherDates dans notre exemple) et B (AnomalyDate dans notre exemple) et retourne quelques modèles qui contribuent aux différences entre les deux jeux :

En examinant les résultats de la requête, vous pouvez voir les différences suivantes :
- Il existe 24 892 147 instances d’ingestion à partir de la ressource CH1-GEARAMAAKS tous les autres jours dans l’intervalle de temps de requête, et aucune ingestion de données de cette ressource le 15 juin. Les données de la ressource CH1-GEARAMAAKS comptent pour 73,36 % de l’ingestion totale des autres jours dans l’intervalle de temps de requête et pour 0 % de l’ingestion totale le 15 juin.
- Il existe 2 168 448 instances d’ingestion à partir de la ressource NSG-TESTSQLMI519 tous les autres jours dans l’intervalle de temps de requête, et 110 544 instances d’ingestion à partir de cette ressource le 15 juin. Les données de la ressource NSG-TESTSQLMI519 comptent pour 6,39 % de l’ingestion totale des autres jours dans l’intervalle de temps de requête et pour 25,61 % de l’ingestion le 15 juin.
Notez que, en moyenne, il existe 108 422 instances d’ingestion à partir de la ressource NSG-TESTSQLMI519 au cours des 20 jours qui composent la période des autres jours (divisez 2 168 448 par 20). Par conséquent, l’ingestion de la ressource NSG-TESTSQLMI519 le 15 juin n’est pas significativement différente de l’ingestion de cette ressource les autres jours. Toutefois, étant donné qu’il n’y a pas d’ingestion de CH1-GEARAMAAKS le 15 juin, l’ingestion de NSG-TESTSQLMI519 constitue un pourcentage significativement plus élevé de l’ingestion totale à la date de l’anomalie par rapport aux autres jours.
La colonne PercentDiffAB indique la différence absolue en point de pourcentage entre A et B (|PercentA - PercentB|), qui est la principale mesure de la différence entre les deux jeux. Par défaut, le plug-in diffpatterns() retourne une différence de plus de 5 % entre les deux jeux de données, mais vous pouvez modifier ce seuil. Par exemple, pour retourner uniquement des différences de 20 % ou plus entre les deux jeux de données, vous pouvez définir | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) dans la requête ci-dessus. La requête ne retourne maintenant qu’un seul résultat :

Notes
Pour plus d’informations sur la syntaxe et l’utilisation de diffpatterns(), consultez Plug-in de modèles de différences.
Étapes suivantes
Pour en savoir plus :