Tutoriel : Configurer un groupe de disponibilité dans plusieurs sous-réseaux (SQL Server sur des machines virtuelles Azure)
S’applique à :![]() SQL Server sur la machine virtuelle Azure
SQL Server sur la machine virtuelle Azure
Conseil
Il existe de nombreuses méthodes pour déployer un groupe de disponibilité. Simplifiez votre déploiement pour éviter d’utiliser un équilibreur de charge Azure ou un nom de réseau distribué (DNN) pour votre groupe de disponibilité Always On, et créez vos machines virtuelles SQL Server dans plusieurs sous-réseaux au sein du même réseau virtuel Azure. Si vous avez déjà créé votre groupe de disponibilité dans un seul sous-réseau, vous pouvez le migrer vers un environnement multi-sous-réseau.
Ce tutoriel montre comment créer un groupe de disponibilité Always On pour SQL Server sur des machines virtuelles Azure dans plusieurs sous-réseaux. Le tutoriel complet crée un cluster de basculement Windows Server ainsi qu’un groupe de disponibilité avec deux réplicas SQL Server et un écouteur.
Durée estimée : ce tutoriel prend environ 30 minutes si vous avez configuré les prérequis.
Prérequis
Le tableau suivant liste les prérequis que vous devez configurer avant de commencer ce tutoriel :
| Condition requise | Description |
|---|---|
 Deux instances SQL Server Deux instances SQL Server |
- Chaque machine virtuelle dans deux zones de disponibilité Azure différentes ou dans le même groupe à haute disponibilité - Dans des sous-réseaux distincts au sein d’un réseau virtuel Azure - Avec deux IP secondaires attribuées à chaque machine virtuelle - Dans un seul domaine |
| Compte de service SQL Server |
Un compte de domaine utilisé par le service SQL Server pour chaque machine |
| Ouvrir les ports du pare-feu |
- SQL Server : 1433 pour l’instance par défaut - Point de terminaison de mise en miroir de bases de données : 5022 ou n’importe quel port disponible |
| Compte d’installation de domaine |
- Administrateur local sur chaque SQL Server - Membres du rôle de serveur fixe sysadmin pour chaque instance de SQL Server |
Ce tutoriel suppose que vous avez des notions de base sur les groupes de disponibilité Always On SQL Server.
Créer le cluster
Le groupe de disponibilité Always On s’appuie sur l’infrastructure de cluster de basculement Windows Server. Par conséquent, avant de déployer votre groupe de disponibilité, vous devez d’abord configurer le cluster de basculement Windows Server, qui comprend l’ajout de la fonctionnalité, la création du cluster et la définition de l’adresse IP du cluster.
Ajouter la fonctionnalité de cluster de basculement
Ajoutez la fonctionnalité de cluster de basculement aux deux machines virtuelles SQL Server. Pour ce faire, procédez comme suit :
Connectez-vous à la machine virtuelle SQL Server avec le protocole Bureau à distance (RDP) en utilisant un compte de domaine qui a l’autorisation de créer des objets dans AD, par exemple, le compte de domaine CORP\Install créé dans l’article des prérequis.
Ouvrez le Tableau de bord de gestionnaire de serveur.
Sélectionnez le lien du tableau de bord Ajouter des rôles et fonctionnalités.
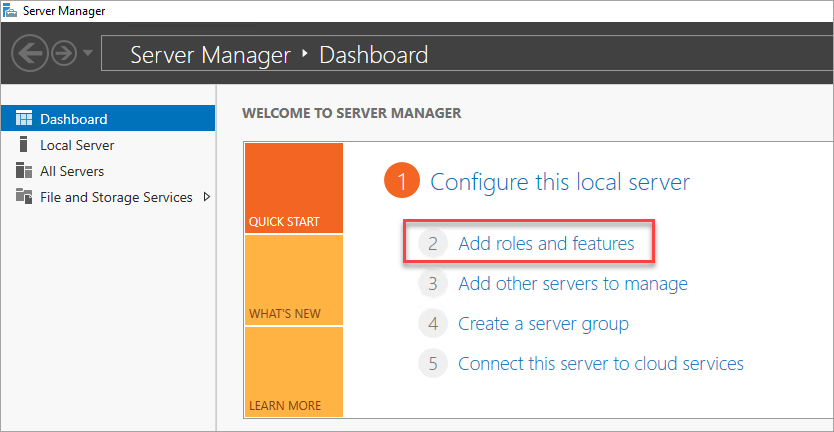
Sélectionnez Suivant jusqu’à ce que vous atteigniez la section Fonctionnalités de serveur.
Dans Fonctionnalités, sélectionnez Clustering de basculement.
Ajoutez les fonctionnalités supplémentaires requises.
Sélectionnez Installer pour ajouter les fonctionnalités.
Répétez les étapes sur l’autre machine virtuelle SQL Server.
Créer un cluster
Après l’ajout de la fonctionnalité de cluster à chaque machine virtuelle SQL Server, vous êtes prêt à créer le cluster de basculement Windows Server.
Pour créer le cluster, suivez ces étapes :
Utilisez le protocole Bureau à distance (RDP) pour vous connecter à la première machine virtuelle SQL Server (SQL-VM-1) en utilisant un compte de domaine qui a l’autorisation de créer des objets dans AD, par exemple, le compte de domaine CORP\Install créé dans l’article des prérequis.
Dans le tableau de bord Gestionnaire de serveur, sélectionnez Outils, puis sélectionnez Gestionnaire du cluster de basculement.
Dans le volet gauche, cliquez-droit sur Gestionnaire du cluster de basculement, puis sélectionnez sur Créer un cluster.
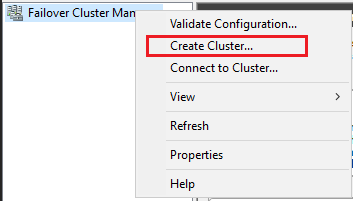
Dans l’Assistant Créer un cluster, créez un cluster à deux nœuds en exécutant les pages avec les paramètres fournis dans le tableau suivant :
Page Paramètres Avant de commencer Utilisez les valeurs par défaut. Sélection des serveurs Tapez le nom du premier serveur SQL (SQL-VM-1) dans Entrer le nom du serveur et sélectionnez Ajouter.
Tapez le nom du deuxième serveur SQL (SQL-VM-2) dans Entrer le nom du serveur et sélectionnez Ajouter.Avertissement de validation Sélectionnez Oui. Quand je clique sur Suivant, exécuter les tests de validation de configuration, puis revenir au processus de création du cluster. Avant de commencer Sélectionnez Suivant. Options de test Choisissez Exécuter uniquement les tests que je sélectionne. Sélection de test Décochez Stockage. Vérifiez que les options Inventaire, Réseau et Configuration système sont sélectionnées. Confirmation Sélectionnez Suivant.
Attendez que la validation se termine.
Sélectionnez Voir le rapport pour passer en revue le rapport. Vous pouvez ignorer en toute sécurité l’avertissement concernant les machines virtuelles accessibles sur une seule interface réseau. L’infrastructure Azure a une redondance physique et, par conséquent, vous n’avez pas besoin d’ajouter des interfaces réseau supplémentaires.
Sélectionnez Terminer.Point d'accès pour l'administration du cluster Tapez un nom de cluster, par exemple SQLAGCluster1 dans Nom du cluster. Confirmation Décochez Ajouter tout le stockage éligible au cluster et sélectionnez Suivant. Résumé Sélectionnez Terminer. Avertissement
Si vous ne décochez pas Ajouter tout le stockage éligible au cluster, Windows détache les disques virtuels pendant le processus de clustering. Par conséquent, ils n’apparaissent pas dans le Gestionnaire de disque ou dans l’Explorateur tant que le stockage n’est pas supprimé du cluster et rattaché en utilisant PowerShell.
Définir l’adresse IP du cluster de basculement
En règle générale, l’adresse IP attribuée au cluster est la même que celle attribuée à la machine virtuelle, ce qui signifie que, dans Azure, l’adresse IP du cluster est dans un état d’échec et ne peut pas être mise en ligne. Changez l’adresse IP du cluster pour mettre la ressource IP en ligne.
Pendant la configuration des prérequis, vous devez avoir attribué des adresses IP secondaires à chaque machine virtuelle SQL Server, comme dans l’exemple de tableau ci-dessous (vos adresses IP spécifiques peuvent varier) :
| Nom de la machine virtuelle | Nom du sous-réseau | Plage d’adresses de sous-réseau | Nom de l’IP secondaire | Adresse IP secondaire |
|---|---|---|---|---|
| SQL-VM-1 | SQL-subnet-1 | 10.38.1.0/24 | windows-cluster-ip | 10.38.1.10 |
| SQL-VM-2 | SQL-subnet-2 | 10.38.2.0/24 | windows-cluster-ip | 10.38.2.10 |
Attribuez ces adresses IP comme adresses IP du cluster pour chaque sous-réseau approprié.
Notes
Sur Windows Server 2019, le cluster crée un Nom de serveur distribué au lieu du Nom de réseau de cluster, et l’objet de nom de cluster (CNO) est automatiquement inscrit avec les adresses IP de tous les nœuds du cluster, ce qui évite d’avoir une adresse IP de cluster Windows dédiée. Si vous êtes sur Windows Server 2019, ignorez cette section et toutes les autres étapes qui référencent les Principales ressources du cluster ou créez un cluster basé sur un nom de réseau virtuel (VNN) avec PowerShell. Pour plus d’informations, consultez le blog Failover Cluster: Cluster Network Object.
Pour changer l’adresse IP du cluster, suivez ces étapes :
Dans Gestionnaire du cluster de basculement, accédez à Principales ressources du cluster et développez les détails du cluster. Vous devez voir le Nom et deux ressources Adresse IP de chaque réseau dans l’état Échec.
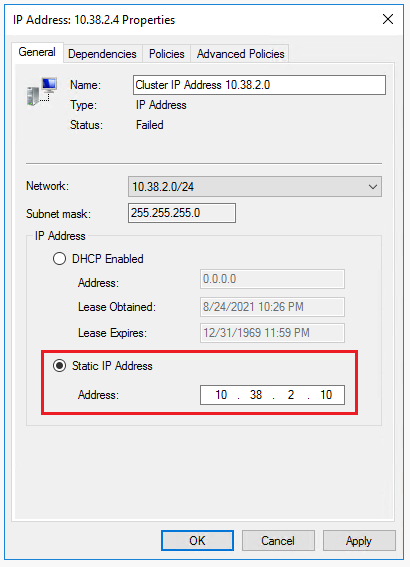
Cliquez avec le bouton droit sur la première ressource Adresse IP en échec, puis sélectionnez Propriétés.
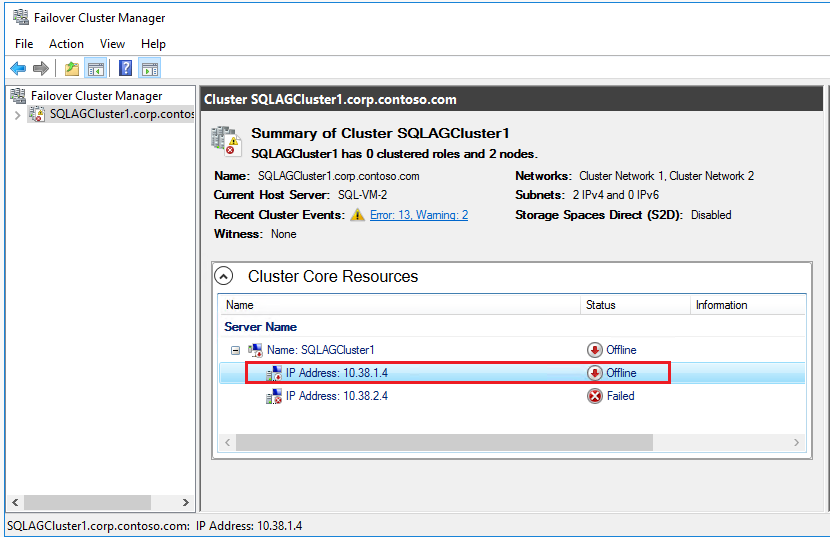
Sélectionnez Adresse IP statique et mettez à jour l’adresse IP sur l’adresse IP de cluster Windows dédiée dans le sous-réseau que vous avez attribué à la première machine virtuelle SQL Server (SQL-VM-1). Cliquez sur OK.
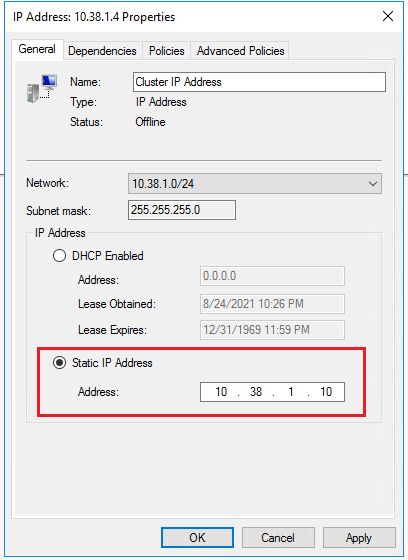
Répétez les étapes pour la deuxième ressource d’Adresse IP en échec, en utilisant l’adresse IP de cluster Windows dédiée pour le sous-réseau de la deuxième machine virtuelle SQL Server (SQL-VM-2).
Dans la section Principales ressources du cluster, cliquez-droit sur le nom du cluster et sélectionnez Mettre en ligne. Attendez que le cluster et l’une des ressources d’adresse IP soient en ligne.
Comme les machines virtuelles SQL Server se trouvent dans des sous-réseaux différents, le cluster a une dépendance OR sur les deux adresses IP de cluster Windows dédiées. Lorsque la ressource du nom du cluster apparaît en ligne, elle met à jour le contrôleur de domaine avec un nouveau compte d’ordinateur Active Directory (AD). Si les ressources principales du cluster changent de nœuds, une des adresses IP est mise hors connexion et l’autre est mise en ligne, ce qui met à jour le serveur du contrôleur de domaine avec la nouvelle association d’adresse IP.
Conseil
Quand vous exécutez le cluster sur des machines virtuelles Azure dans un environnement de production, remplacez les paramètres de cluster par un état de monitoring plus souple pour améliorer la stabilité et la fiabilité du cluster dans un environnement cloud. Pour plus d’informations, consultez Machine virtuelle SQL Server - Bonnes pratiques de configuration HADR.
Configurer un quorum
Sur un cluster à deux nœuds, un appareil de quorum est nécessaire pour assurer la fiabilité et la stabilité du cluster. Sur les machines virtuelles Azure, la configuration de quorum recommandée est le témoin cloud, bien que d’autres options soient disponibles. Les étapes de cette section configurent un témoin cloud pour le quorum. Identifiez les clés d’accès au compte de stockage, puis configurez le témoin cloud.
Obtenir les clés d’accès pour le compte de stockage
Quand vous créez un compte de stockage Microsoft Azure, il est associé à deux clés d’accès générées automatiquement : la clé d’accès primaire et la clé d’accès secondaire. Utilisez la clé d’accès primaire la première fois que vous créez le témoin cloud, mais vous pouvez utiliser les deux clés indifféremment pour le témoin cloud par la suite.
Utilisez le portail Azure pour voir et copier les clés d’accès de stockage pour le compte de stockage Azure créé dans l’article des prérequis.
Pour voir et copier les clés d’accès de stockage, suivez ces étapes :
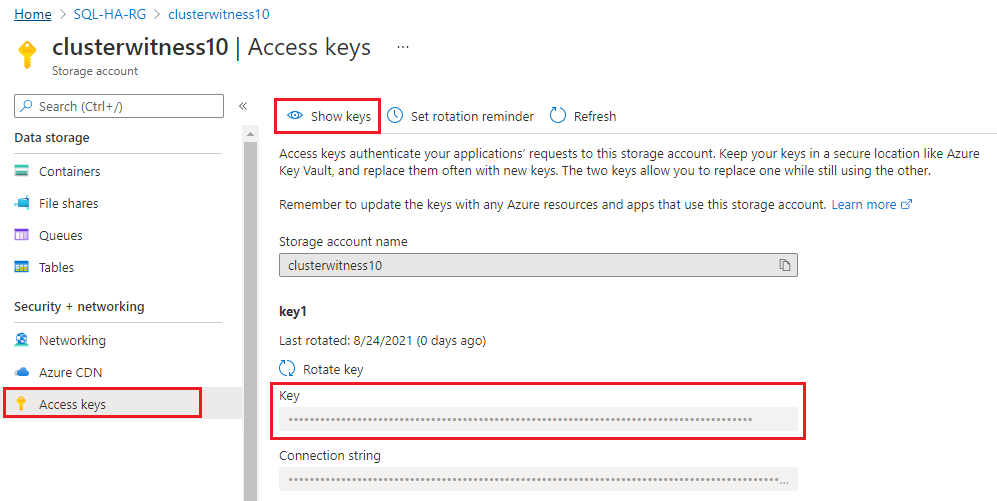
Accédez à votre groupe de ressources dans le portail Azure et sélectionnez le compte de stockage que vous avez créé.
Sélectionnez Clés d’accès sous Sécurité + réseau.
Sélectionnez Afficher les clés et copiez la clé.
Configurer le témoin cloud
Une fois que vous avez copié la clé d’accès, créez le témoin cloud pour le quorum du cluster.
Pour créer le témoin cloud, suivez ces étapes :
Connectez-vous à la première machine virtuelle SQL Server SQL-VM-1 avec le Bureau à distance.
Ouvrez Windows PowerShell en mode Administrateur.
Exécutez le script PowerShell pour définir la valeur de TLS (Transport Layer Security) sur 1.2 pour la connexion :
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12Utilisez PowerShell pour configurer le témoin cloud. Remplacez les valeurs du nom de compte de stockage et de la clé d’accès par vos informations spécifiques :
Set-ClusterQuorum -CloudWitness -AccountName "Storage_Account_Name" -AccessKey "Storage_Account_Access_Key"L’exemple de sortie suivant indique la réussite :

Les principales ressources de cluster sont configurées avec un témoin cloud.
Activer la fonctionnalité de groupe de disponibilité
La fonctionnalité de groupe de disponibilité Always On est désactivée par défaut. Utilisez le Gestionnaire de configuration SQL Server pour activer la fonctionnalité sur les deux instances SQL Server.
Pour activer la fonctionnalité de groupe de disponibilité, suivez ces étapes :
Lancez le fichier RDP sur la première machine virtuelle SQL Server (SQL-VM-1) avec un compte de domaine membre du rôle serveur fixe sysadmin, par exemple, le compte de domaine CORP\Install créé dans le document de prérequis
Dans l’écran Démarrer de l’une de vos machines virtuelles SQL Server, lancez le Gestionnaire de configuration SQL Server.
Dans l’arborescence du navigateur, sélectionnez Services SQL Server, cliquez avec le bouton droit sur le service SQL Server (MSSQLSERVER) et sélectionnez Propriétés.
Sélectionnez l’onglet Haute disponibilité AlwaysOn, puis cochez la case Activer les groupes de disponibilité AlwaysOn :
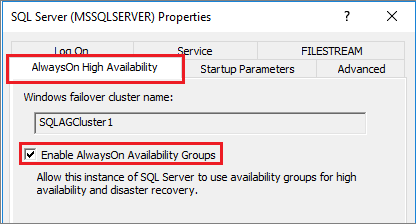
Sélectionnez Apply. Sélectionnez OK dans la boîte de dialogue de la fenêtre contextuelle.
Redémarrez le service SQL Server.
Répétez ces étapes pour l’autre instance SQL Server.
Activer la fonctionnalité FILESTREAM
Si vous n’utilisez pas FILESTREAM pour votre base de données dans le groupe de disponibilité, ignorez cette étape et passez à l’étape suivante : Créer une base de données.
Si vous prévoyez d’ajouter une base de données à votre groupe de disponibilité qui utilise FILESTREAM, alors FILESTREAM doit être activé, car cette fonctionnalité est désactivée par défaut. Utilisez le Gestionnaire de configuration SQL Server pour activer la fonctionnalité sur les deux instances SQL Server.
Pour activer la fonctionnalité FILESTREAM, suivez les étapes ci-dessous :
Lancez le fichier RDP sur la première machine virtuelle SQL Server (SQL-VM-1) avec un compte de domaine membre du rôle serveur fixe sysadmin, par exemple, le compte de domaine CORP\Install créé dans le document de prérequis
Dans l’écran Démarrer de l’une de vos machines virtuelles SQL Server, lancez le Gestionnaire de configuration SQL Server.
Dans l’arborescence du navigateur, sélectionnez Services SQL Server, cliquez avec le bouton droit sur le service SQL Server (MSSQLSERVER) et sélectionnez Propriétés.
Sélectionnez l’onglet FILESTREAM, puis cochez la case Activer FILESTREAM pour l’accès Transact-SQL :
Sélectionnez Apply. Sélectionnez OK dans la boîte de dialogue de la fenêtre contextuelle.
Dans SQL Server Management Studio, cliquez sur Nouvelle requête pour afficher l’Éditeur de requête.
Dans l'Éditeur de requête, entrez le code Transact-SQL suivant :
EXEC sp_configure filestream_access_level, 2 RECONFIGURECliquez sur Exécuter.
Redémarrez le service SQL Server.
Répétez ces étapes pour l’autre instance SQL Server.
Créer une base de données
Pour votre base de données, vous pouvez suivre les étapes de cette section afin de créer une base de données ou restaurer une base de données AdventureWorks. Vous devez aussi sauvegarder la nouvelle base de données pour initialiser la séquence de journaux de transactions consécutifs. Les bases de données qui n’ont pas été sauvegardées n’ont pas les prérequis pour rejoindre le groupe de disponibilité.
Pour créer une base de données, suivez ces étapes :
- Lancez le fichier RDP sur la première machine virtuelle SQL Server (SQL-VM-1) avec un compte de domaine membre du rôle serveur fixe sysadmin, par exemple, le compte de domaine CORP\Install créé dans le document de prérequis.
- Ouvrez SQL Server Management Studio et connectez-vous à l’instance SQL Server.
- Dans l’Explorateur d’objets, cliquez-droit sur Bases de données, puis cliquez sur Nouvelle base de données.
- Dans Nom de base de données, tapez MyDB1.
- Sélectionnez la page Options et choisissez Complet dans la liste déroulante Mode de récupération, s’il n’est pas complet par défaut. La base de données doit être en mode de récupération complète pour remplir les conditions de participation à un groupe de disponibilité.
- Sélectionnez OK pour fermer la page Nouvelle base de données et créer votre base de données.
Pour sauvegarder la base de données, suivez ces étapes :
Dans l’Explorateur d’objets, cliquez avec le bouton droit sur la base de données, sélectionnez Tâches, puis Sauvegarder... .
Sélectionnez OK pour effectuer une sauvegarde complète de la base de données dans l’emplacement de sauvegarde par défaut.
Créer un partage de fichiers
Créez un partage de fichiers de sauvegarde auquel ont accès aussi bien les machines virtuelles SQL Server que leurs comptes de service.
Pour créer le partage de fichiers de sauvegarde, suivez ces étapes :
Sur la première machine virtuelle SQL Server, dans le Gestionnaire de serveur, sélectionnez Outils. Ouvrez Gestion de l’ordinateur.
Sélectionnez Dossiers partagés.
Cliquez avec le bouton droit sur Partages et sélectionnez Nouveau partage... , puis utilisez l’Assistant Créer un dossier partagé pour créer un partage.
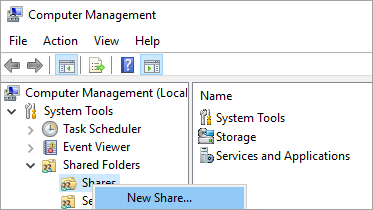
Pour le Chemin du dossier, sélectionnez Parcourir et recherchez ou créez un chemin pour le dossier partagé de la sauvegarde de base de données, par exemple,
C:\Backup. Sélectionnez Suivant.Dans Nom, Description et Paramètres, vérifiez le nom et le chemin d’accès du partage. Sélectionnez Suivant.
Dans Autorisations du dossier partagé, sélectionnez Personnaliser les autorisations. Sélectionnez Personnalisé.
Dans Personnaliser les autorisations, sélectionnez Ajouter.
Cochez Contrôle total pour accorder l’accès complet au partage au compte de service SQL Server (
Corp\SQLSvc) :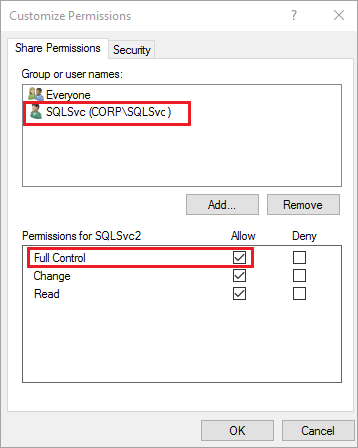
Cliquez sur OK.
Dans Autorisations du dossier partagé, sélectionnez Terminer. Sélectionnez Terminer.
Créer un groupe de disponibilité
Dès que votre base de données est sauvegardée, vous êtes prêt à créer votre groupe de disponibilité, qui effectue automatiquement une sauvegarde complète et une sauvegarde du journal des transactions du réplica SQL Server principal, et les restaure sur l’instance SQL Server secondaire avec l’option NORECOVERY.
Pour créer le groupe de disponibilité, suivez ces étapes suivantes.
Dans l’Explorateur d’objets dans SQL Server Management Studio (SSMS), sur la première machine virtuelle SQL Server (SQL-VM-1), cliquez avec le bouton droit sur Haute disponibilité Always On et sélectionnez Assistant Nouveau groupe de disponibilité.
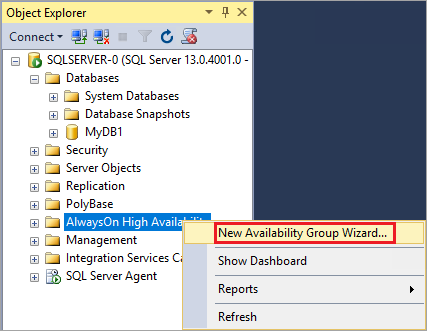
Dans la page Introduction, sélectionnez Suivant. Dans la page Spécifier le nom du groupe de disponibilité, tapez le nom du groupe de disponibilité dans Nom du groupe de disponibilité, (AG1). Cliquez sur Suivant.
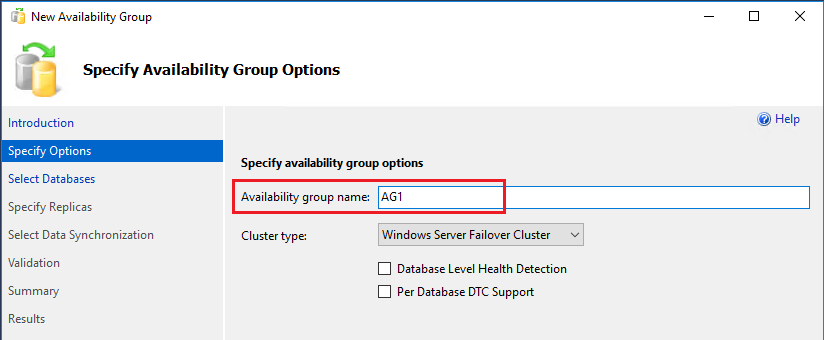
Dans la page Sélectionner des bases de données, sélectionnez votre base de données, puis Suivant. Si votre base de données ne remplit pas les conditions, vérifiez qu’elle est en mode de récupération complète et effectuez une sauvegarde :
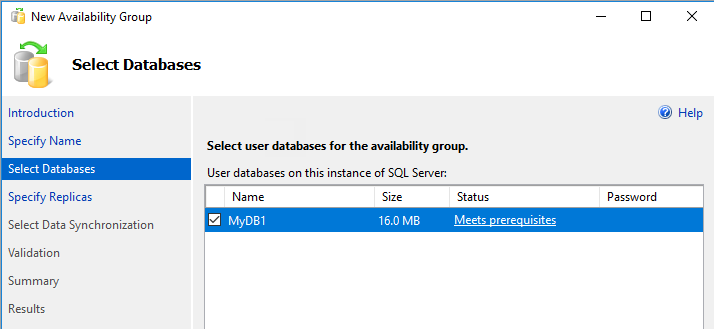
Dans la page Spécifier les réplicas, sélectionnez Ajouter un réplica.
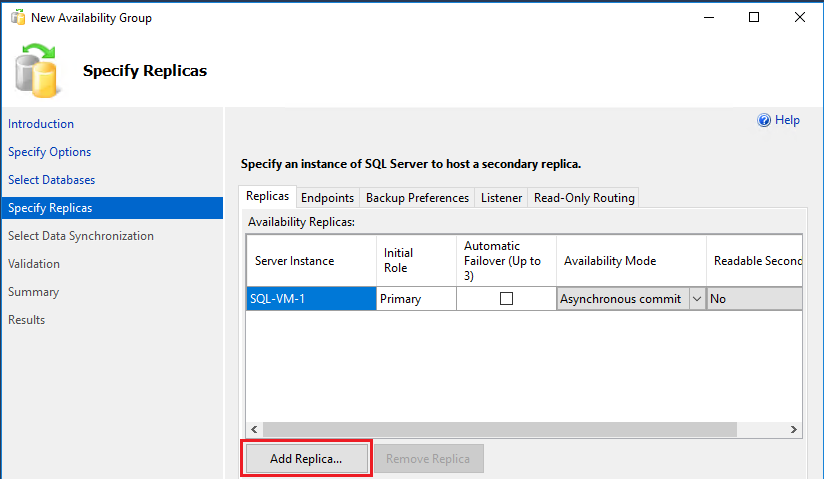
La boîte de dialogue Se connecter au serveur apparaît. Tapez le nom du deuxième serveur dans Nom du serveur, (SQL-VM-2). Sélectionnez Connecter.
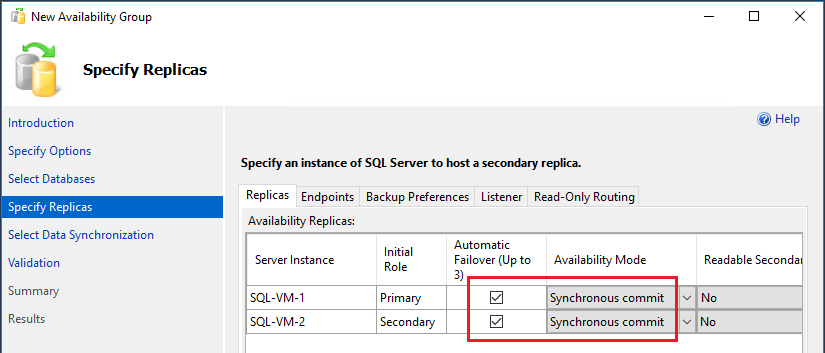
Dans la page Spécifier les réplicas, cochez les cases pour le Basculement automatique et choisissez Validation synchrone comme mode de disponibilité dans la liste déroulante :
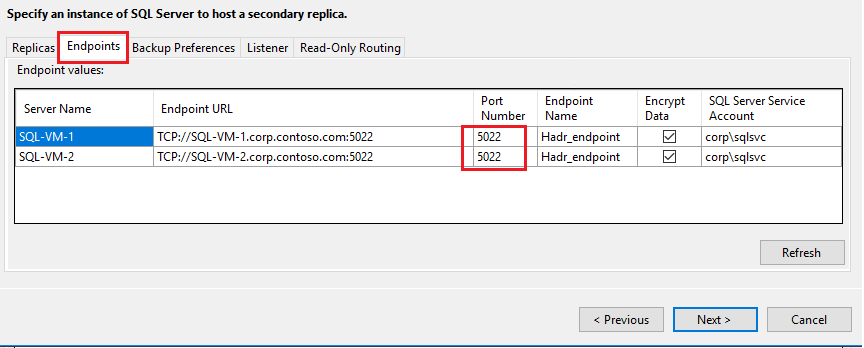
Sélectionnez l’onglet Points de terminaison pour confirmer que les ports utilisés pour le point de terminaison de mise en miroir de bases de données sont ceux que vous avez ouverts dans le pare-feu :
Sélectionnez l’onglet Écouteur et choisissez Créer un écouteur de groupe de disponibilité avec les valeurs suivantes pour l’écouteur :
Champ Valeur Nom DNS de l’écouteur : AG1-Listener Port Utilisez le port SQL Server par défaut. 1433 Mode réseau : Adresse IP statique Sélectionnez Ajouter pour fournir l’adresse IP dédiée secondaire de l’écouteur pour les deux machines virtuelles SQL Server.
Le tableau suivant montre les exemples d’adresses IP créées pour l’écouteur à partir du document de prérequis (vos adresses IP spécifiques peuvent varier) :
Nom de la machine virtuelle Nom du sous-réseau Plage d’adresses de sous-réseau Nom de l’IP secondaire Adresse IP secondaire SQL-VM-1 SQL-subnet-1 10.38.1.0/24 availability-group-listener 10.38.1.11 SQL-VM-2 SQL-subnet-2 10.38.2.0/24 availability-group-listener 10.38.2.11 Choisissez le premier sous-réseau (10.38.1.0/24) dans la liste déroulante de la boîte de dialogue Ajouter une adresse IP, puis fournissez l’adresse IPv4 dédiée secondaire de l’écouteur,
10.38.1.11. Cliquez sur OK.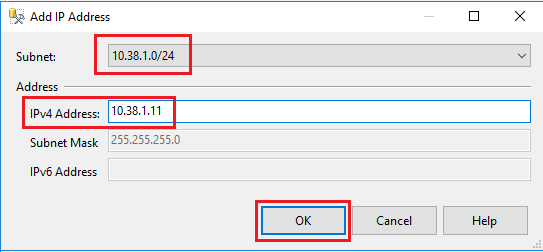
Répétez cette étape, mais choisissez l’autre sous-réseau dans la liste déroulante (10.38.2.0/24) et fournissez l’adresse IPv4 dédiée secondaire de l’écouteur de l’autre machine virtuelle SQL Server,
10.38.2.11. Cliquez sur OK.
Après avoir vérifié les valeurs de la page Écouteur, sélectionnez Suivant :

Dans la page Sélectionner la synchronisation de données initiale, choisissez Sauvegarde complète de la base de données et des journaux et indiquez l’emplacement du partage réseau que vous avez créé précédemment,
\\SQL-VM-1\Backup.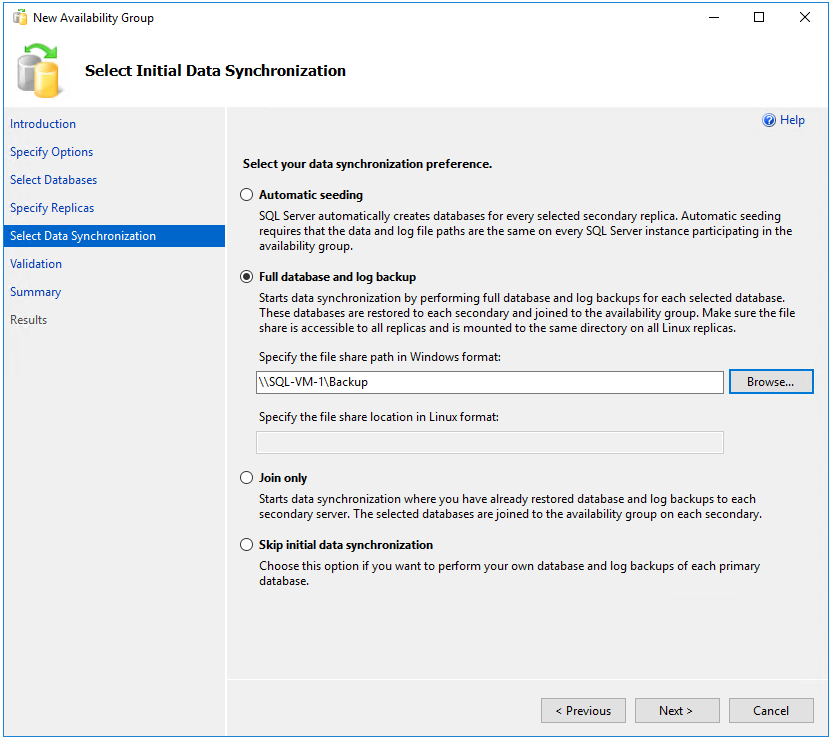
Remarque
La synchronisation complète effectue une sauvegarde complète de la base de données sur la première instance de SQL Server et la restaure sur la deuxième instance. Pour les bases de données volumineuses, une synchronisation complète n’est pas recommandée, car elle peut prendre longtemps. Vous pouvez réduire ce temps en effectuant manuellement une sauvegarde de la base de données et en la restaurant avec
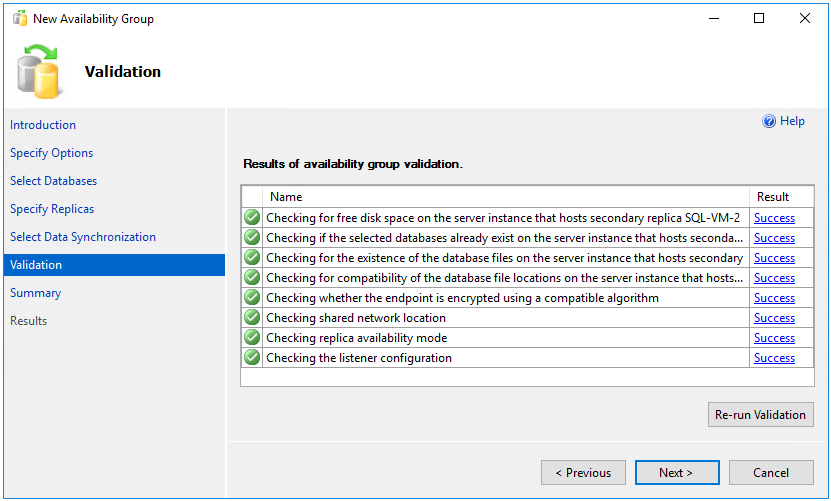
NO RECOVERY. Si la base de données a été restaurée avecNO RECOVERYsur le deuxième serveur SQL avant la configuration du groupe de disponibilité, choisissez Joindre uniquement. Si vous souhaitez effectuer la sauvegarde après avoir configuré le groupe de disponibilité, choisissez Ignorer la synchronisation de données initiale.Dans la page Validation, vérifiez que toutes les vérifications de validation ont réussi, puis choisissez Suivant :
Dans la page Récapitulatif, sélectionnez Terminer et attendez que l’Assistant configure votre nouveau groupe de disponibilité. Dans la page Progression, choisissez Plus de détails pour voir la progression détaillée. Dès que vous voyez que l’Assistant a terminé dans la page Résultats, examinez le récapitulatif pour vérifier que le groupe de disponibilité et l’écouteur ont bien été créés.
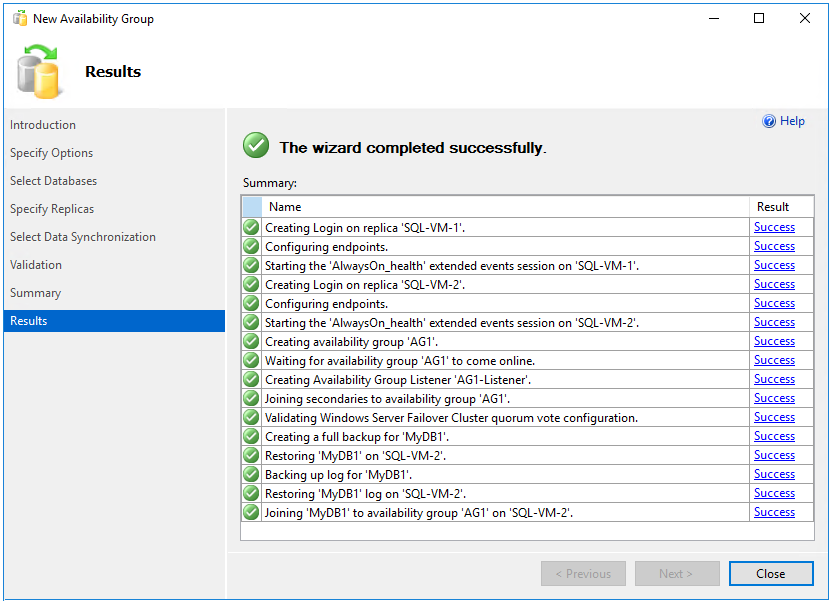
Pour quitter l’Assistant, sélectionnez Fermer.
Vérifier le groupe de disponibilité
Vous pouvez vérifier l’intégrité du groupe de disponibilité avec SQL Server Management Studio et le Gestionnaire du cluster de basculement.
Pour vérifier l’état du groupe de disponibilité, suivez ces étapes :
Dans l’Explorateur d’objets, développez Haute disponibilité Always On, puis Groupes de disponibilité. Vous devez maintenant voir le nouveau groupe de disponibilité dans ce conteneur. Cliquez avec le bouton droit sur le groupe de disponibilité et sélectionnez Afficher le tableau de bord.
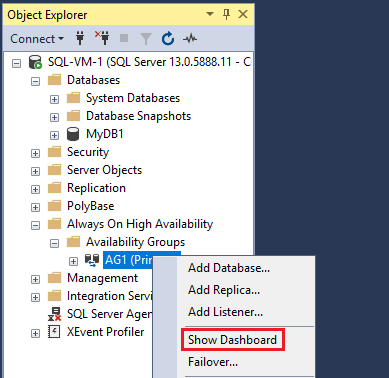
Le tableau de bord du groupe de disponibilité montre le réplica, le mode de basculement de chaque réplica et l’état de synchronisation, comme dans l’exemple suivant :
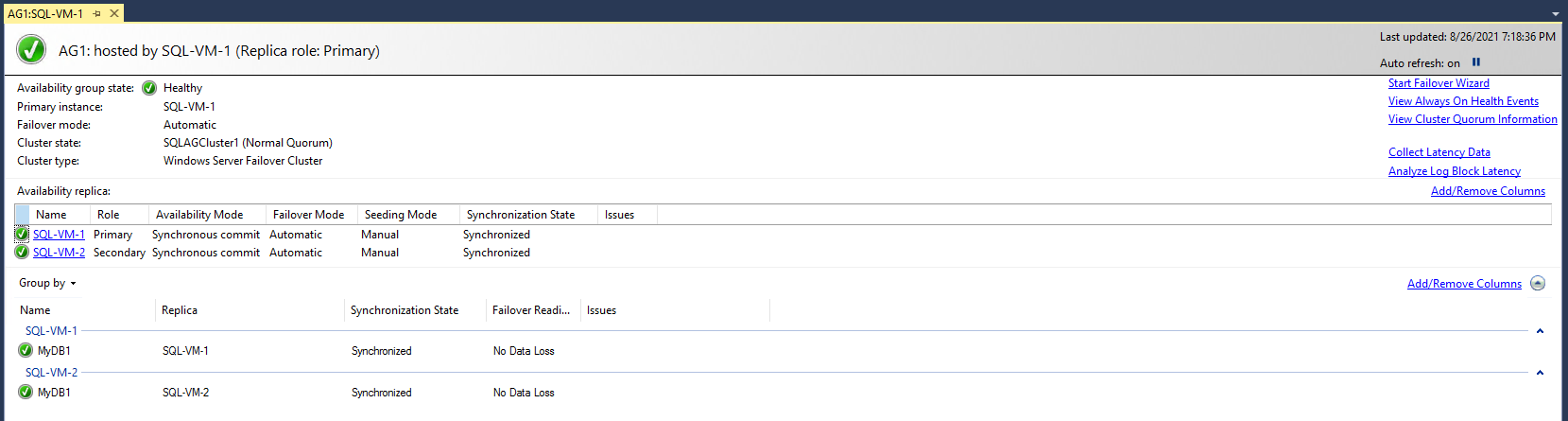
Ouvrez le Gestionnaire du cluster de basculement, sélectionnez votre cluster, puis choisissez Rôles pour voir le rôle du groupe de disponibilité que vous avez créé au sein du cluster. Choisissez le rôle AG1 et sélectionnez l’onglet Ressources pour voir l’écouteur et les adresses IP associées, comme dans l’exemple suivant :
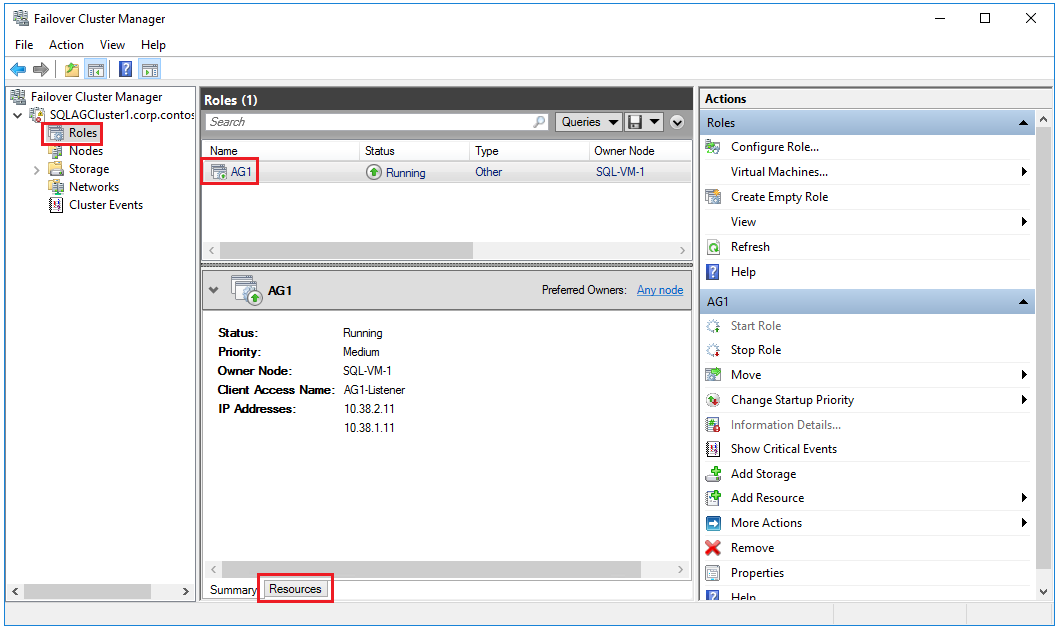
À ce stade, vous avez un groupe de disponibilité avec des réplicas sur deux instances SQL Server ainsi que l’écouteur de groupe de disponibilité correspondant. Vous pouvez vous connecter en utilisant l’écouteur, et déplacer le groupe de disponibilité d’une instance à l’autre avec SQL Server Management Studio.
Avertissement
Ne tentez pas de basculer le groupe de disponibilité en utilisant le Gestionnaire du cluster de basculement. Vous devez effectuer toutes les opérations de basculement dans SQL Server Management Studio, en utilisant le Tableau de bord Always On ou Transact-SQL (T-SQL). Pour plus d’informations, consultez Restrictions d’utilisation du Gestionnaire de cluster de basculement avec des groupes de disponibilité.
Tester la connexion de l’écouteur
Dès que votre groupe de disponibilité est prêt et que votre écouteur a été configuré avec les adresses IP secondaires appropriées, testez la connexion à l’écouteur.
Pour tester la connexion, suivez ces étapes :
Utilisez le protocole RDP pour vous connecter à un serveur SQL qui se trouve dans le même réseau virtuel, mais qui n’a pas le réplica, par exemple, l’autre instance SQL Server au sein du cluster ou toute autre machine virtuelle sur laquelle SQL Server Management Studio est installé.
Ouvrez SQL Server Management Studio et, dans la boîte de dialogue Se connecter au serveur, tapez le nom de l’écouteur (AG1-Listener) dans Nom du serveur : , puis sélectionnez Options :
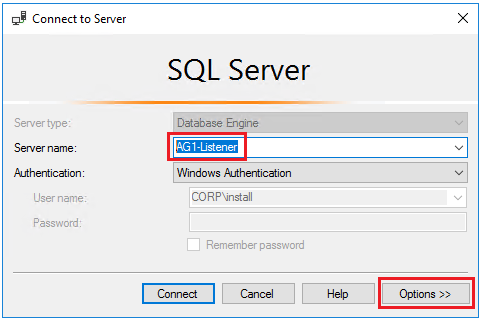
Entrez
MultiSubnetFailover=Truedans la fenêtre Paramètres de connexion supplémentaires, puis choisissez Se connecter pour vous connecter automatiquement à l’instance qui héberge le réplica SQL Server principal :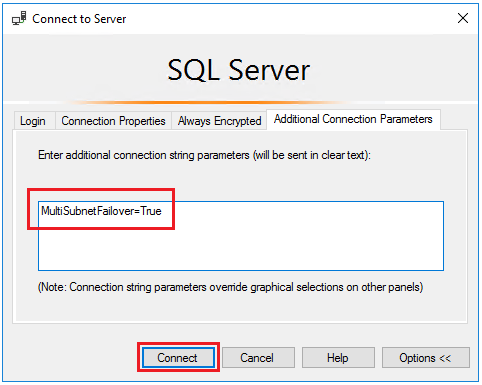
Remarque
- Si vous vous connectez au groupe de disponibilité sur des sous-réseaux différents, la définition de
MultiSubnetFailover=truepermet plus rapidement de détecter le réplica principal actuel et de s’y connecter. Consultez Connexion avec MultiSubnetFailover
Étapes suivantes
Maintenant que vous avez configuré votre groupe de disponibilité multi-sous-réseaux, si nécessaire, vous pouvez l’étendre à plusieurs régions.
Pour en savoir plus, consultez :
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour