Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Utilisez Azure Batch pour exécuter des programmes de traitement par lots de calcul haute performance (HPC) en parallèle, efficacement et à grande échelle dans Azure. Ce tutoriel décrit un exemple Python d’exécution d’une charge de travail parallèle à l’aide de Batch. Vous apprendrez un flux de travail d'application Batch courant et comment interagir par programme avec les ressources Batch et de stockage.
- S’authentifier avec des comptes Batch et de stockage.
- Charger des fichiers d’entrée sur le stockage.
- Créer un pool de nœuds de calcul pour exécuter une application.
- Créer un travail et des tâches pour traiter les fichiers d’entrée.
- Surveiller l’exécution d’une tâche.
- Récupérer les fichiers de sortie.
Dans ce tutoriel, vous convertissez des fichiers multimédias MP4 au format MP3, en parallèle, à l’aide de l’outil open source ffmpeg.
Si vous ne disposez pas d’un compte Azure, créez-en un gratuitement avant de commencer.
Conditions préalables
Un compte Azure Batch et un compte de stockage Azure lié. Pour créer ces comptes, consultez les guides de démarrage rapide Batch pour le portail Azure ou Azure CLI.
Accordez l’accès à vos comptes Batch et Stockage
Ce tutoriel montre comment s’authentifier auprès d’Azure Batch et stockage Azure en utilisant Microsoft Entra ID avec DefaultAzureCredential. L’application n’utilise pas les clés de compte. Avant d’utiliser l’application, assurez-vous que l’identité que vous utilisez contient les rôles requis sur les deux comptes.
Connectez-vous en utilisant l’interface Azure CLI.
DefaultAzureCredentialDétecte automatiquement cette connexion :az loginAttribuez à votre compte utilisateur un rôle permettant d’effectuer des opérations sur le plan de données du compte Batch, tel que Azure Batch Data Contributor. Ce rôle est nécessaire pour créer des pools, des emplois et des tâches. Vous pouvez attribuer le rôle sur la page de contrôle d'accès (IAM) du compte Batch dans le portail Azure, ou utiliser la CLI Azure CLI :
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Azure Batch Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Batch/batchAccounts/<batch-account-name>"Attribuez à votre compte utilisateur le rôle de Contributeur de données de Blob de stockage sur le compte de stockage. Ce rôle est nécessaire pour créer des conteneurs, téléverser les fichiers d’entrée et demander la clé de délégation utilisateur qui signe les URL de signature d’accès partagé (SAS) utilisées par les tâches :
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Storage Blob Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Storage/storageAccounts/<storage-account-name>"Notez les valeurs suivantes, que vous ajoutez au fichier config.py de l’échantillon dans la section suivante. Vous pouvez les trouver sur la page d'aperçu de chaque compte dans le portail Azure :
- Nom du compte Batch
- URL de compte batch, par exemple
https://mybatchaccount.westus2.batch.azure.com - Nom du compte de stockage
Note
Il peut falloir quelques minutes pour que les attributions de rôles se propagent. Si l’application échoue avec une erreur d’autorisation juste après avoir attribué les rôles, attendez quelques minutes et réessayez.
Télécharger et exécuter l’exemple d’application
Important
L’exemple téléchargeable dans le dépôt batch-python-ffmpeg-tutorial est en cours de mise à jour pour correspondre à ce tutoriel. Jusqu’à la publication de cette mise à jour, le dépôt pourrait encore contenir l’authentification basée sur les clés antérieure et le code Ubuntu 20.04. Le code de cet article est la source de vérité. Si l’échantillon téléchargé ne correspond pas aux extraits ici, suivez le code montré dans cet article.
Télécharger l’exemple d’application
Téléchargez ou clonez l’exemple d’application à partir de GitHub. Pour cloner le référentiel d’exemple d’application avec un client Git, utilisez la commande suivante :
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
Accédez au répertoire qui contient le fichier batch_python_tutorial_ffmpeg.py.
Dans votre environnement Python, installez les packages requis à l’aide de pip.
pip install -r requirements.txt
Utilisez un éditeur de code pour ouvrir le fichier config.py. Mettez à jour les valeurs du compte Batch et du compte de stockage avec les noms propres à vos comptes. L’exemple utilise DefaultAzureCredential pour s’authentifier, de sorte que les clés de compte ne sont plus nécessaires. Par exemple:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
Assurez-vous d’être connecté en utilisant az login et que votre identité comporte les rôles décrits dans Accorder l’accès à vos comptes Batch et Stockage.
DefaultAzureCredentialpeut également découvrir d’autres sources de crédences, telles qu’une identité managée, Visual Studio Code ou des variables d’environnement.
Exécuter l’application
Pour exécuter le script :
python batch_python_tutorial_ffmpeg.py
Lorsque vous exécutez l’exemple d’application, la sortie de la console est identique à ce qui suit. Pendant l’exécution, vous observez une pause à Monitoring all tasks for 'Completed' state, timeout in 00:30:00... lorsque les nœuds de calcul du pool sont démarrés.
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks reached the 'Completed' state within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
Accédez à votre compte Batch dans le portail Azure pour surveiller le pool, les nœuds de calcul, les travaux et les tâches. Par exemple, pour afficher une carte thermique des nœuds de calcul dans votre pool, sélectionnez Pools>LinuxFmpegPool.
Lorsque les tâches sont en cours d’exécution, la carte thermique est similaire à ce qui suit :
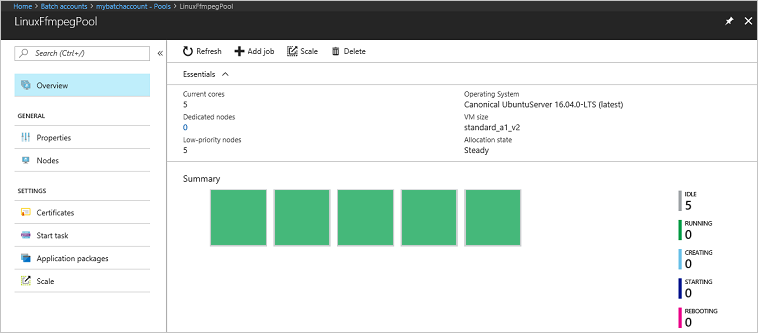
Le temps d’exécution classique est d’environ 5 minutes lorsque vous exécutez l’application dans sa configuration par défaut. La création d’un pool est l’opération la plus longue.
Récupérer les fichiers de sortie
Vous pouvez utiliser le portail Azure pour télécharger les fichiers de sortie MP3 générés par les tâches ffmpeg.
- Cliquez sur Tous les services>Comptes de stockage, puis sur le nom de votre compte de stockage.
- Cliquez sur BLOB>sortie.
- Cliquez avec le bouton droit sur l’un des fichiers de sortie MP3 puis cliquez sur Télécharger. Suivez les instructions dans votre navigateur pour ouvrir ou sauvegarder le fichier.
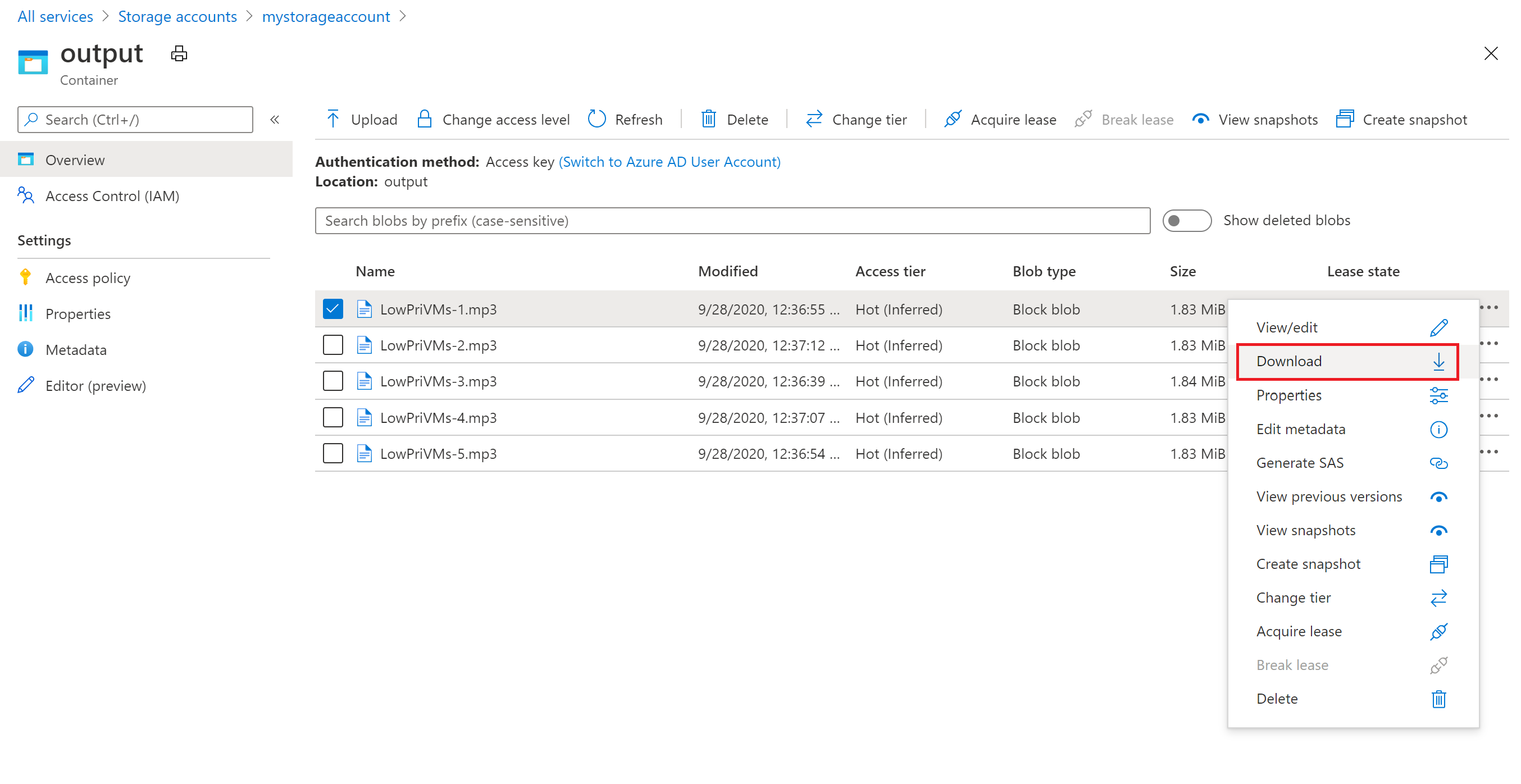
Même si ce n’est pas montré dans cet exemple, vous pouvez aussi télécharger les fichiers par programmation depuis les nœuds de calcul ou depuis le conteneur de stockage.
Vérifier le code
Dans les sections suivantes, nous examinons l’exemple d’application en nous servant des opérations qu’elle effectue pour traiter une charge de travail dans le service Batch. Reportez-vous au code Python pendant que vous lisez le reste de cet article, car aucune ligne de code de l’exemple n’est abordée.
Authentifier les clients Blob et Batch
L’exemple s’authentifie auprès de Storage et de Batch à l’aide de DefaultAzureCredential du package azure-identity.
DefaultAzureCredential tente plusieurs types d’informations d’identification dans l’ordre (variables d’environnement, identité managée, connexion Azure CLI, et ainsi de suite), ce qui rend le même code fonctionne dans le développement local et en production sans stocker de clés de compte.
Pour interagir avec un compte de stockage, l’application utilise le package azure-storage-blob pour créer un objet BlobServiceClient qui utilise les informations d’identification.
L’exemple importe les types d’identité et de stockage suivants, et lit les noms des comptes depuis config.py :
import config
from azure.identity import DefaultAzureCredential
from azure.storage.blob import (
BlobServiceClient,
BlobSasPermissions,
ContainerSasPermissions,
generate_blob_sas,
generate_container_sas,
)
credential = DefaultAzureCredential()
blob_service_client = BlobServiceClient(
account_url=f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.windows.net/",
credential=credential)
L’application crée un objet BatchClient pour créer et gérer des pools, des travaux et des tâches dans le service Batch. Le client Batch utilise le même DefaultAzureCredential pour s’authentifier via Microsoft Entra ID.
batch_client = BatchClient(
endpoint=config._BATCH_ACCOUNT_URL,
credential=credential)
Les nœuds de calcul par lots accèdent aux conteneurs d’entrée et de sortie en utilisant des URL de signature d’accès partagée (SAS). Comme l’application n’utilise pas la clé de compte de stockage, elle ne peut pas signer de jetons SAS avec. À la place, l'application demande une clé de délégation utilisateur au service Blob, qui est signée avec les identifiants Microsoft Entra de l'application, et utilise cette clé pour générer les jetons SAS. Pour en savoir plus, consultez Créer une SAS de délégation d’utilisateur.
start = datetime.datetime.now(datetime.timezone.utc)
expiry = start + datetime.timedelta(hours=4)
user_delegation_key = blob_service_client.get_user_delegation_key(
key_start_time=start, key_expiry_time=expiry)
# Sign the SAS tokens with the same expiry as the user delegation key.
sas_expiry = expiry
Note
La clé de délégation utilisateur dans cet exemple est valable pendant quatre heures. Un jeton SAS signé avec une clé de délégation utilisateur ne peut pas avoir une durée de validité supérieure à celle de la clé, et une clé de délégation utilisateur peut être valide pendant sept jours maximum. Pour les charges de travail de longue durée, demandez une nouvelle clé et régénérez les URL SAS avant leur expiration.
Charger des fichiers d’entrée
Après avoir créé les conteneurs d’entrée et de sortie avec blob_service_client, l’application télécharge chaque fichier MP4 local dans le dossier InputFiles vers le conteneur d’entrée. L’assistant suivant upload_file_to_container téléverse un seul fichier, génère un jeton SAS en lecture seule signé avec la clé de délégation utilisateur, puis renvoie un objet Batch ResourceFile dont l’URL inclut le jeton SAS afin que Batch puisse ensuite télécharger le fichier vers un nœud de calcul. L’application appelle cet assistant une fois pour chaque fichier d’entrée :
def upload_file_to_container(blob_service_client, user_delegation_key,
sas_expiry, container_name, file_path):
blob_name = os.path.basename(file_path)
blob_client = blob_service_client.get_blob_client(container_name, blob_name)
with open(file_path, "rb") as data:
blob_client.upload_blob(data, overwrite=True)
sas_token = generate_blob_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=container_name,
blob_name=blob_name,
user_delegation_key=user_delegation_key,
permission=BlobSasPermissions(read=True),
expiry=sas_expiry)
sas_url = f"{blob_client.url}?{sas_token}"
return models.ResourceFile(http_url=sas_url, file_path=blob_name)
L’application génère également une URL SAS pour le conteneur de sortie qui accorde l’accès en écriture. Les tâches utilisent cette URL pour télécharger leurs fichiers de sortie en stockage :
sas_token = generate_container_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=output_container_name,
user_delegation_key=user_delegation_key,
permission=ContainerSasPermissions(write=True, create=True, list=True),
expiry=sas_expiry)
output_container_sas_url = (
f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
f"{output_container_name}?{sas_token}")
Créer un pool de nœuds de calcul
Ensuite, l’échantillon crée un pool de nœuds de calcul dans le compte Batch en appelant create_pool. Cette fonction définie utilise la classe BatchPoolCreateOptions pour définir le nombre de nœuds, la taille de machine virtuelle et une configuration de pool. Dans cette configuration, un objet VirtualMachineConfiguration spécifie une BatchVmImageReference à une image Ubuntu Server 22.04 LTS publiée sur Place de marché Azure. Azure Batch prend en charge une large gamme d'images de machines virtuelles dans l'Place de marché Azure, ainsi que des images de machines virtuelles personnalisées.
Le nombre de nœuds et la taille de machine virtuelle sont définis à l’aide de constantes définies. Azure Batch prend en charge les nœuds dédiés et les nœuds de faible priorité que vous pouvez utiliser dans vos pools. Les nœuds dédiés sont réservés à votre pool. Les nœuds de faible priorité sont proposés à prix réduit à partir de la capacité de machine virtuelle excédentaire dans Azure. Les nœuds Spot deviennent indisponibles si Azure n’a pas suffisamment de capacité. L’exemple par défaut crée un pool contenant seulement cinq nœuds Spot de taille Standard_A1_v2.
Outre les propriétés de nœud physiques, cette configuration de pool inclut un objet BatchStartTask . BatchStartTask s’exécute sur chaque nœud à mesure que ce nœud joint le pool, et chaque fois qu’un nœud est redémarré. Dans cet exemple, BatchStartTask exécute des commandes d’interpréteur de commandes Bash pour installer le package ffmpeg et les dépendances sur les nœuds.
La méthode create_pool envoie le pool au service Batch.
new_pool = models.BatchPoolCreateOptions(
id=pool_id,
virtual_machine_configuration=models.VirtualMachineConfiguration(
image_reference=models.BatchVmImageReference(
publisher="canonical",
offer="0001-com-ubuntu-server-jammy",
sku="22_04-lts",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 22.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=models.BatchStartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=models.UserIdentity(
auto_user=models.AutoUserSpecification(
scope=models.AutoUserScope.POOL,
elevation_level=models.ElevationLevel.ADMIN)),
)
)
batch_client.create_pool(pool=new_pool)
Note
Les images VM du Marketplace et les agents de nœuds Batch ont des dates de fin de support. Les images Ubuntu Server 20.04 LTS et l’agent de nœud batch.node.ubuntu 20.04 ne sont plus pris en charge dans les nouveaux pools Batch. Pour obtenir la liste des références d’image et des références SKU des agents de nœud actuellement prises en charge par votre compte Batch, appelez la méthode list_supported_images.
Créer un travail
Un job par lots spécifie un pool de ressources pour exécuter des tâches et des paramètres facultatifs tels qu'une priorité et un planning du travail. L’exemple crée une tâche en appelant create_job. Cette fonction utilise la classe BatchJobCreateOptions pour créer une tâche dans votre pool. La méthode create_job soumet la tâche au service Batch. Au début, le travail n’a pas de tâches.
job = models.BatchJobCreateOptions(
id=job_id,
pool_info=models.BatchPoolInfo(pool_id=pool_id))
batch_client.create_job(job=job)
Créer des tâches
L’application crée des tâches dans le travail avec un appel à add_tasks. Cette fonction définie crée une liste d’objets de tâche à l’aide de la classe BatchTaskCreateOptions . Chaque tâche exécute ffmpeg pour traiter un objet d’entrée resource_files à l’aide d’un command_line paramètre. ffmpeg a été précédemment installé sur chaque nœud lors de la création du pool. Ici, la ligne de commande exécute ffmpeg pour convertir chaque fichier (vidéo) MP4 en fichier MP3 (audio).
L’exemple crée un objet OutputFile pour le fichier MP3 après l’exécution de la ligne de commande. Les fichiers de sortie de chaque tâche (un, dans ce cas) sont chargés dans un conteneur dans le compte de stockage lié, à l’aide de la propriété de output_files la tâche.
Ensuite, l’application ajoute des tâches au travail avec la méthode create_tasks , qui les met en file d’attente pour s’exécuter sur les nœuds de calcul.
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(models.BatchTaskCreateOptions(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[models.OutputFile(
file_pattern=output_file_path,
destination=models.OutputFileDestination(
container=models.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=models.OutputFileUploadConfiguration(
upload_condition=models.OutputFileUploadCondition.TASK_SUCCESS))]
)
)
batch_client.create_tasks(job_id=job_id, task_collection=tasks)
Surveiller les tâches
Lorsque des tâches sont ajoutées à un travail, Batch met automatiquement en file d’attente et planifie leur exécution sur les nœuds de calcul dans le pool associé. En fonction des paramètres que vous spécifiez, Batch gère toutes les tâches de mise en file d’attente, de planification, de nouvelle tentative et d’autres tâches d’administration des tâches.
Il existe de nombreuses approches pour surveiller l’exécution des tâches. La wait_for_tasks_to_complete fonction de cet exemple utilise l’objet BatchTaskState pour surveiller les tâches d’un certain état, dans ce cas l’état terminé, dans une limite de temps.
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_client.list_tasks(job_id=job_id)
incomplete_tasks = [task for task in tasks if
task.state != models.BatchTaskState.COMPLETED]
if not incomplete_tasks:
print()
return True
else:
time.sleep(5)
...
Nettoyer les ressources
Après avoir exécuté les tâches, l'application supprime automatiquement le conteneur de stockage d'entrée qu'elle a créé et vous offre la possibilité de supprimer le pool et la tâche du service Azure Batch. Les méthodes begin_delete_job et begin_delete_pool de la BatchClient classe lancent chacune l’opération de suppression correspondante lorsque vous confirmez l’invite. Bien qu’aucuns frais ne vous soient facturés pour les travaux et les tâches eux-mêmes, des frais vous sont facturés pour les nœuds de calcul. N’allouez donc des groupes que lorsque nécessaire. Lorsque vous supprimez le pool, tous les résultats de tâche sur les nœuds sont supprimés. Toutefois, les fichiers de sortie restent dans le compte de stockage.
Lorsque vous n’en avez plus besoin, supprimez le groupe de ressources, le compte Batch et le compte de stockage. Pour ce faire, dans le portail Azure, sélectionnez le groupe de ressources du compte Batch et choisissez Supprimer le groupe de ressources.
Étapes suivantes
Dans ce tutoriel, vous avez appris à :
- S’authentifier avec des comptes Batch et de stockage.
- Charger des fichiers d’entrée sur le stockage.
- Créer un pool de nœuds de calcul pour exécuter une application.
- Créer un travail et des tâches pour traiter les fichiers d’entrée.
- Surveiller l’exécution d’une tâche.
- Récupérer les fichiers de sortie.
Pour plus d’exemples d’utilisation de l’API Python pour planifier et traiter des charges de travail Batch, consultez les exemples Batch Python sur GitHub.