Colocation de table dans Azure Cosmos DB for PostgreSQL
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
La colocation signifie que vous stockez ensemble des informations connexes sur les mêmes nœuds. Les requêtes peuvent s'exécuter rapidement lorsque toutes les données nécessaires sont disponibles sans aucun trafic réseau. La colocation de données associées sur différents nœuds permet aux requêtes de s’exécuter efficacement en parallèle sur chaque nœud.
Colocation de données pour les tables distribuées par hachage
Dans Azure Cosmos DB for PostgreSQL, une ligne est stockée au sein d’une partition si le hachage de la valeur de la colonne de distribution se situe dans la plage de hachage de la partition. Les partitions avec la même plage de hachage sont toujours placées sur le même nœud. Les lignes avec des valeurs de colonne de distribution égales sont toujours placées sur le même nœud dans toutes les tables. Le concept de tables de hachage distribuées est également appelé partitionnement basé sur les lignes. Dans le partitionnement basé sur le schéma, les tables d’un schéma distribué sont toujours colocalisées.
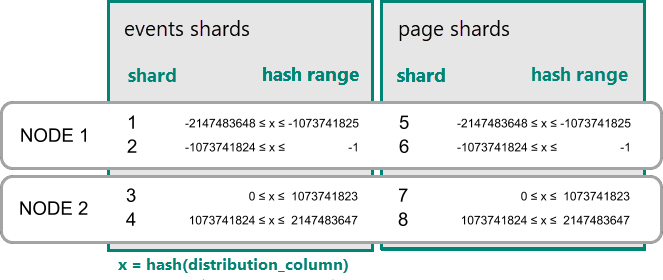
Exemple pratique de colocation
Imaginez les tableaux suivants, susceptibles de faire partie d’une solution SaaS d’analytique web multilocataire :
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Maintenant, nous voulons répondre aux requêtes qui peuvent être émises par un tableau de bord orienté client. Exemple de requête : « Renvoyer le nombre de visites la semaine dernière pour toutes les pages commençant par « /blog » dans le locataire six. »
Si nos données se trouvaient sur un seul serveur PostgreSQL, nous pourrions facilement exprimer notre requête à l’aide de l’ensemble complet d’opérations relationnelles offertes par SQL :
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Tant que la plage de travail pour cette requête tient en mémoire, une table de serveur unique est une solution appropriée. Prenons l’exemple d’opportunités de mise à l’échelle du modèle de données avec Azure Cosmos DB for PostgreSQL.
Distribuer les tables par ID
Les requêtes de serveur unique commencent à ralentir lorsque le nombre de locataires et les données stockées pour chaque locataire augmentent. La plage de travail ne tient plus en mémoire, et l’UC devient un goulot d’étranglement.
Dans ce cas, nous pouvons partitionner les données sur de nombreux nœuds à l’aide d’Azure Cosmos DB for PostgreSQL. Tout d'abord, en matière de partitionnement, nous devons choisir la colonne de distribution. Commençons naïvement par choisir event_id pour la table d’événements et page_id pour la table page :
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Lorsque les données sont dispersées sur différents workers, nous ne pouvons pas effectuer de jointure, comme nous le ferions sur un seul nœud PostgreSQL. Au lieu de cela, nous devons émettre deux requêtes :
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Ensuite, l’application doit combiner les résultats des deux étapes.
Les requêtes exécutées doivent consulter les données dans les partitions réparties entre les nœuds.
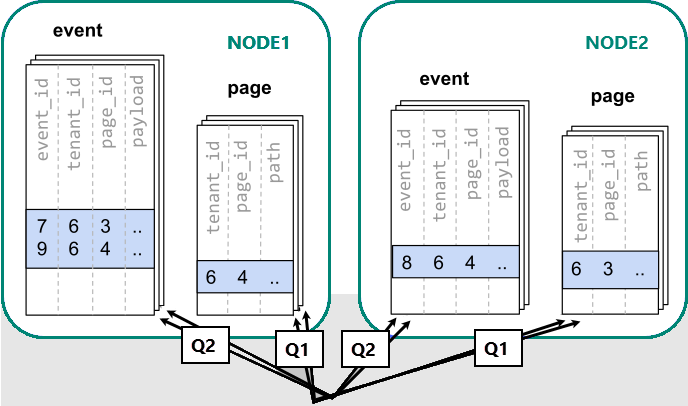
Dans ce cas, la distribution des données présente de sérieux inconvénients :
- Surcharge lors de l'interrogation de chaque partition et exécution de plusieurs requêtes.
- Surcharge de Q1, renvoyant beaucoup de lignes au client.
- Q2 devient volumineux.
- Le besoin d'écrire des requêtes en plusieurs étapes nécessite des modifications dans l'application.
Comme les données sont dispersées, les requêtes peuvent être parallélisées. Ce n'est utile que si la quantité de travail effectuée par la requête est nettement supérieure à la surcharge que représente l'interrogation de plusieurs partitions.
Distribuer les tables par locataire
Dans Azure Cosmos DB for PostgreSQL, les lignes dotées de la même valeur de colonne de distribution sont obligatoirement situées sur le même nœud. Si nous recommençons, nous pouvons créer nos tables avec tenant_id comme colonne de distribution.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Azure Cosmos DB pour PostgreSQL peut désormais répondre à la requête de serveur unique d’origine sans modification (Q1) :
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
En raison du filtre et de la jointure sur tenant_id, Azure Cosmos DB for PostgreSQL sait que l’intégralité de la requête peut être traitée à l’aide de l’ensemble de partitions colocalisées qui contiennent les données de ce locataire particulier. Un seul nœud PostgreSQL peut répondre à la requête en une seule étape.
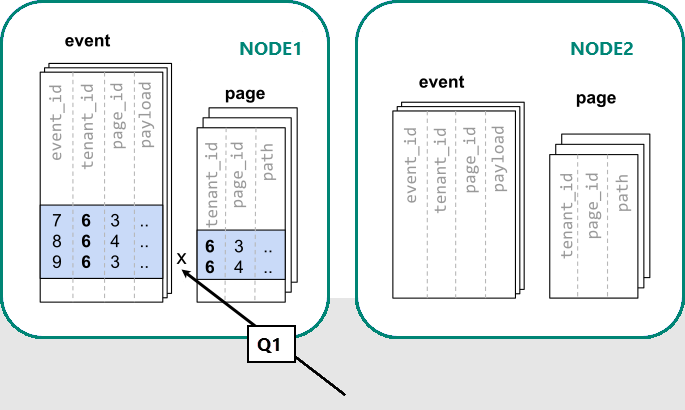
Dans certains cas, les requêtes et les schémas de table doivent être modifiés pour inclure l’ID de locataire dans des conditions de jointure et des contraintes uniques. Cette modification est généralement simple.
Étapes suivantes
- Découvrez comment les données des locataires sont colocalisées dans le tutoriel multilocataire.