Modéliser des applications d’analytique en temps réel dans Azure Cosmos DB for PostgreSQL
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Colocaliser des tables volumineuses avec une clé de partition
Pour sélectionner la clé de partition pour une application d’analytique opérationnelle en temps réel, suivez ces instructions :
- Choisir une colonne courante sur des tables volumineuses
- Choisissez une colonne qui est une dimension naturelle dans les données ou un élément central de l’application. Voici quelques exemples :
- Dans le monde financier, une application qui analyse les tendances de sécurité utiliserait probablement
security_id. - Dans une charge de travail d’analyse utilisateur dans laquelle vous souhaitez analyser les métriques d’utilisation du site web,
user_idserait une bonne colonne de distribution
- Dans le monde financier, une application qui analyse les tendances de sécurité utiliserait probablement
En colocalisant des tables volumineuses, vous pouvez envoyer des requêtes SQL vers des nœuds worker en parallèle. L’envoi de requêtes évite de mélanger les données entre les nœuds sur le réseau. Les opérations, comme les JOIN, les agrégats, les cumuls, les filtres et les LIMIT, peuvent être exécutées efficacement.
Pour visualiser des requêtes distribuées parallèles sur des tables colocalisées, tenez compte de ce diagramme :
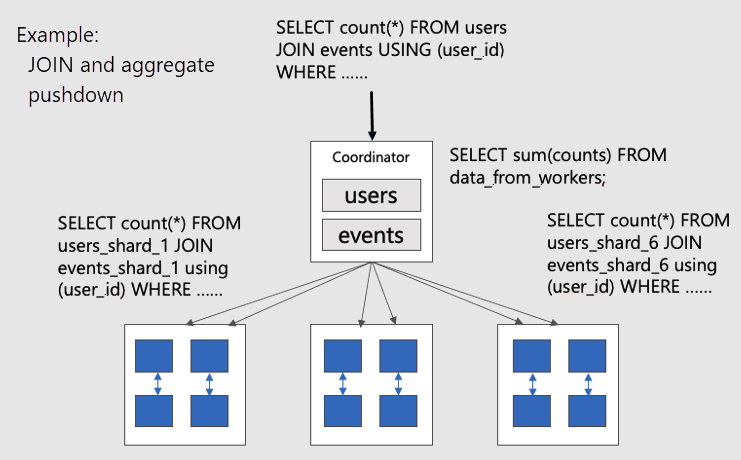
Les tables users et events tables sont partitionnées par user_id, de sorte que les lignes associées pour le même ID utilisateur sont placées ensemble sur le même nœud worker. Les SQL JOIN peuvent se produire sans extraire d’informations entre workers.
Modèle de données optimal pour les applications en temps réel
Poursuivons avec l’exemple d’une application qui analyse les visites et les métriques du site web utilisateur. Il existe deux tables de « faits » (utilisateurs et événements) et d’autres tables de « dimensions » plus petites.
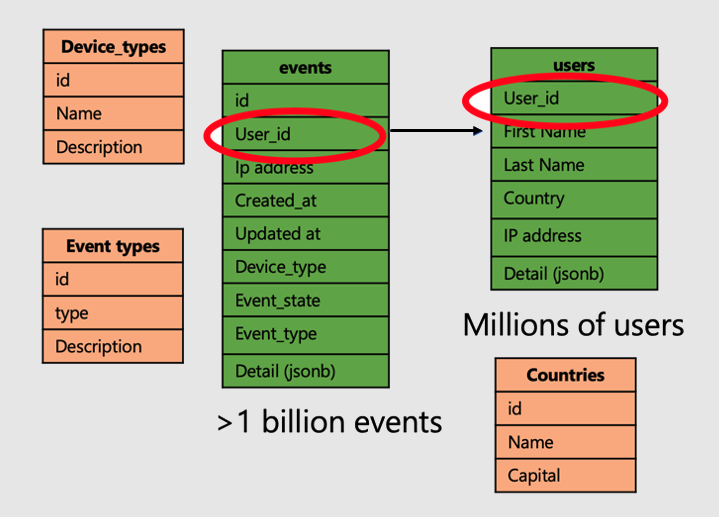
Pour appliquer la puissance des tables distribuées sur Azure Cosmos DB for PostgreSQL, procédez comme suit :
- Distribuez les tables de faits volumineuses sur une colonne commune. Dans notre cas, les utilisateurs et les événements sont distribués sur
user_id. - Marquez les tables plus petites/de dimension (
device_types,countrieset event_types) en tant que tables de référence. - Veillez à inclure la colonne de distribution dans les contraintes de clé primaire, unique et étrangère sur les tables distribuées. L’inclusion de la colonne peut nécessiter de rendre les clés composites. Il est nécessaire de mettre à jour les clés pour les tables de référence.
- Lorsque vous joignez de grandes tables distribuées, veillez à joindre à l’aide de la clé de partition.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Étapes suivantes
Nous avons terminé d’explorer la modélisation de données pour les applications scalables. L’étape suivante consiste à connecter et interroger la base de données avec le langage de programmation de votre choix.