Utiliser l’activité de commande Azure Data Factory pour exécuter des commandes de gestion Azure Data Explorer
Azure Data Factory (ADF) est un service d’intégration de données basé sur le cloud qui vous permet d’effectuer une combinaison d’activités sur les données. Utilisez ADF pour créer des workflows basées sur les données afin d’orchestrer et d’automatiser le déplacement et la transformation des données. L’activité commande Azure Data Explorer dans Azure Data Factory vous permet d’exécuter des commandes de gestion Azure Data Explorer au sein d’un flux de travail ADF. Cet article explique comment créer un pipeline avec une activité de recherche et une activité ForEach contenant une activité de commande Azure Data Explorer.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Une source de données.
- Une fabrique de données. Créez une fabrique de données.
Créer un pipeline
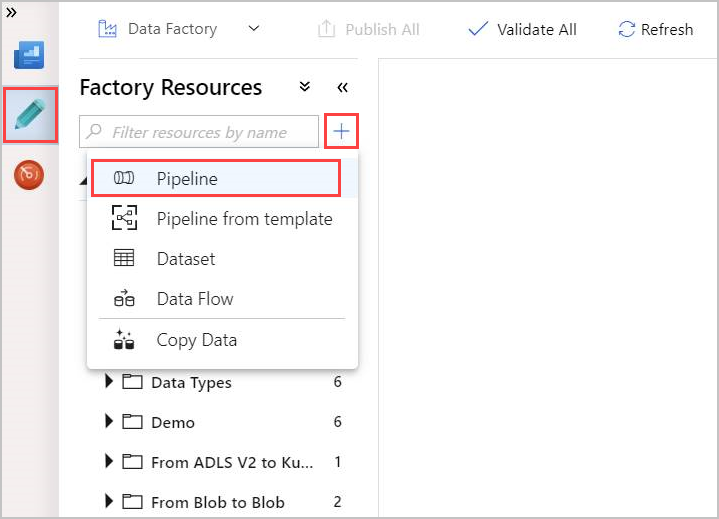
Sélectionnez l’outil crayon Author (Créer).
Créez un pipeline en sélectionnant +, puis sélectionnez Pipeline dans la liste déroulante.
Créer une activité Lookup
Une activité Lookup peut récupérer un jeu de données à partir de n’importe quelle source de données compatible Azure Data Factory. La sortie de l’activité Lookup peut être utilisée dans une activité ForEach ou une autre activité.
Dans le volet Activities, sous General, sélectionnez l’activité Lookup. Faites-la glisser et déposez-la dans le canevas principal à droite.
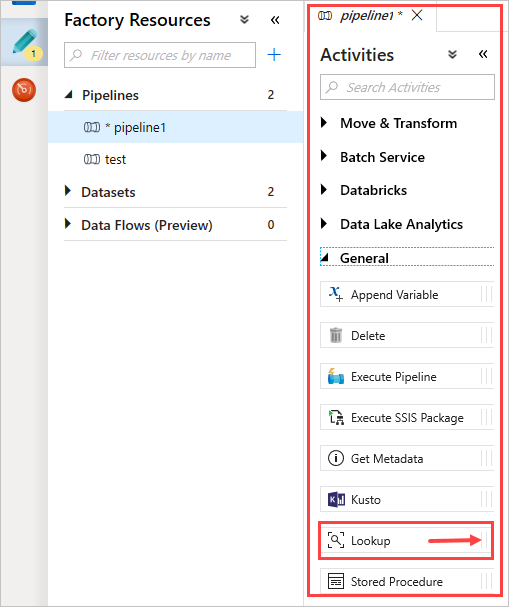
Le canevas contient maintenant l’activité Lookup que vous avez créée. Utilisez les onglets situés sous le canevas pour changer les paramètres appropriés. Dans General, renommez l’activité.
Conseil
Cliquez sur la zone de canevas vide pour voir les propriétés du pipeline. Utilisez l’onglet General pour renommer le pipeline. Notre pipeline est nommé pipeline-4-docs.
Créer un jeu de données Azure Data Explorer dans l’activité de recherche
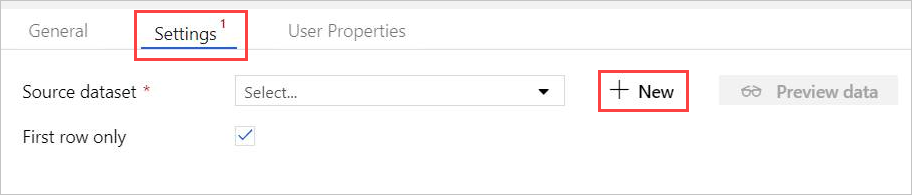
Dans Settings (Paramètres), sélectionnez le jeu de données source Azure Data Explorer préalablement créé, ou sélectionnez + New pour créer un jeu de données.
Sélectionnez le jeu de données Azure Data Explorer (Kusto) à partir de la fenêtre New Dataset (Nouveau jeu de données). Sélectionnez Continuer pour ajouter le nouveau jeu de données.
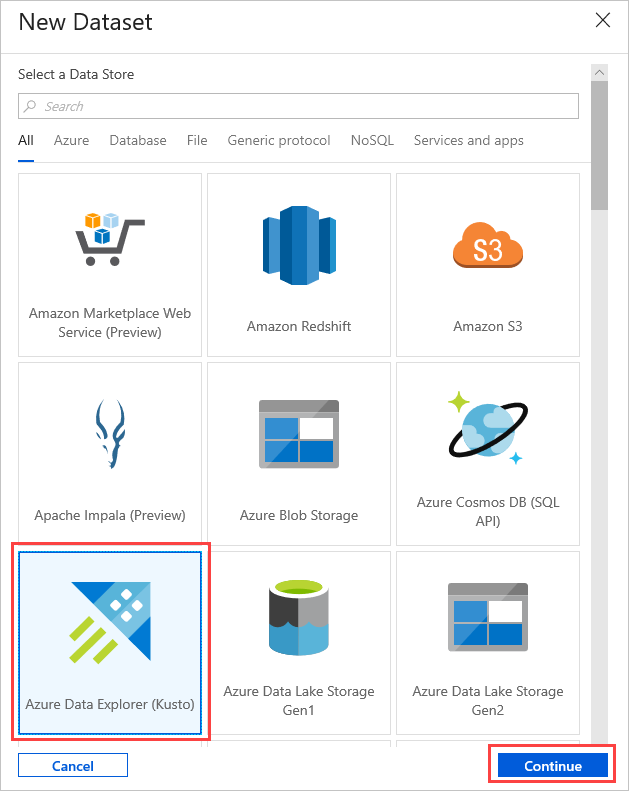
Les nouveaux paramètres du jeu de données Azure Data Explorer sont visibles dans Paramètres. Pour mettre à jour les paramètres, sélectionnez Modifier.
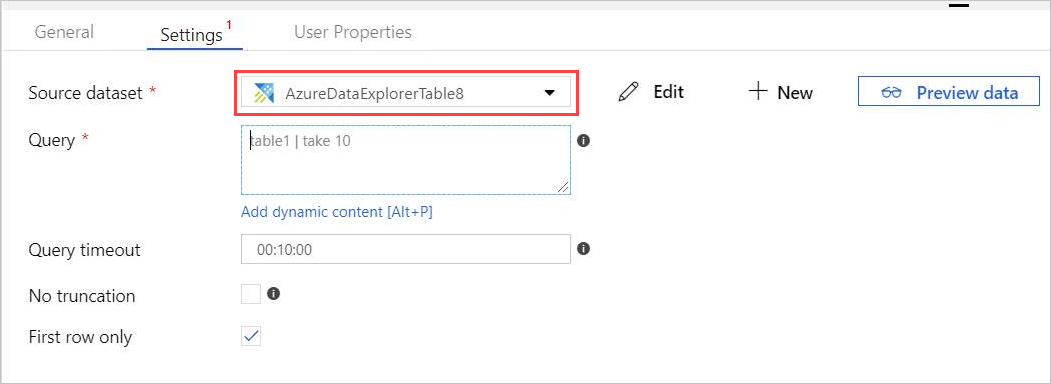
Le nouvel onglet AzureDataExplorerTable s’ouvre dans le canevas principal.
- Sélectionnez Général, puis modifiez le nom du jeu de données.
- Sélectionnez Connection pour modifier les propriétés du jeu de données.
- Sélectionnez le service lié (Linked service) dans la liste déroulante, ou sélectionnez + New pour créer un service lié.
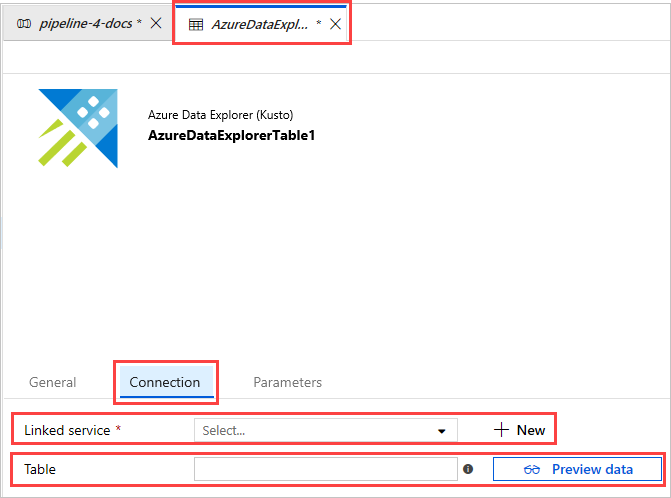
Lors de la création d’un service lié, la page New Linked Service (Azure Data Explorer) (Nouveau service lié (Azure Data Explorer)) s’ouvre :
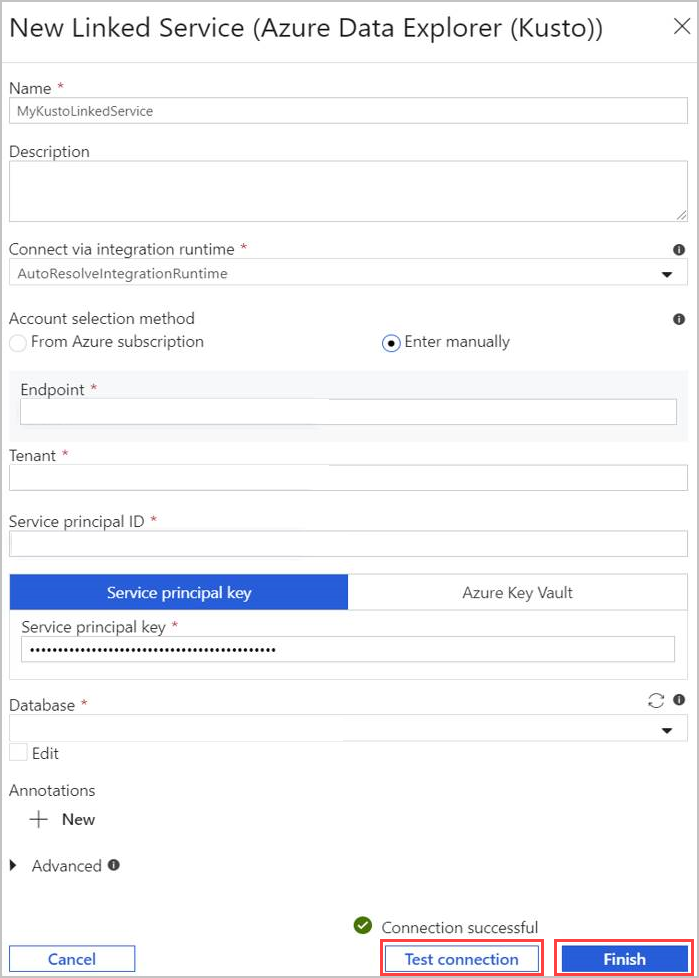
- Sélectionnez un Name (Nom) pour le service lié Azure Data Explorer. Ajoutez une Description, si nécessaire.
- Dans Connect via integration runtime (Connexion via un runtime d’intégration), changez les paramètres actuels, si nécessaire.
- Dans la méthode de sélection de compte, sélectionnez votre cluster à l’aide de l’une des deux méthodes suivantes :
- Sélectionnez la case d’option From Azure subscription (À partir d’un abonnement Azure), puis sélectionnez le compte de vitre abonnement Azure. Ensuite, sélectionnez votre Cluster. Notez que la liste déroulante ne répertorie que les clusters appartenant à l’utilisateur.
- Vous pouvez également sélectionner la case d’option Enter manually (Entrer manuellement), puis entrer votre point de terminaison (Endpoint) (URL du cluster).
- Spécifiez le Tenant (Locataire).
- Entrez le Service principal ID (ID du principal du service). Cette valeur se trouve dans le Portail Azure sous l’ID d’application Vue d’ensemble>des inscriptions>d’applications (client). Le principal doit disposer des autorisations adéquates, en fonction du niveau d’autorisation requis par la commande utilisée.
- Sélectionnez le bouton Service principal key (Clé du principal du service), puis entrez la clé du principal du service.
- Sélectionnez votre Database (Base de données) dans le menu déroulant. Vous pouvez également activer la case à cocher Edit (Modifier) et entrer le nom de votre base de données.
- Sélectionnez Test Connection (Tester la connexion) pour tester la connexion au service lié que vous avez créée. Si vous pouvez vous connecter à votre configuration, une coche verte Connection successful (Connexion réussie) s’affiche.
- Sélectionnez Finish (Terminer) pour achever la création du service lié.
Une fois que vous avez configuré un service lié, dans AzureDataExplorerTable>Connection, ajoutez le nom de la Table. Sélectionnez Preview data (Aperçu des données) pour vérifier que les données s’affichent correctement.
Votre jeu de données est maintenant prêt, et vous pouvez continuer à modifier votre pipeline.
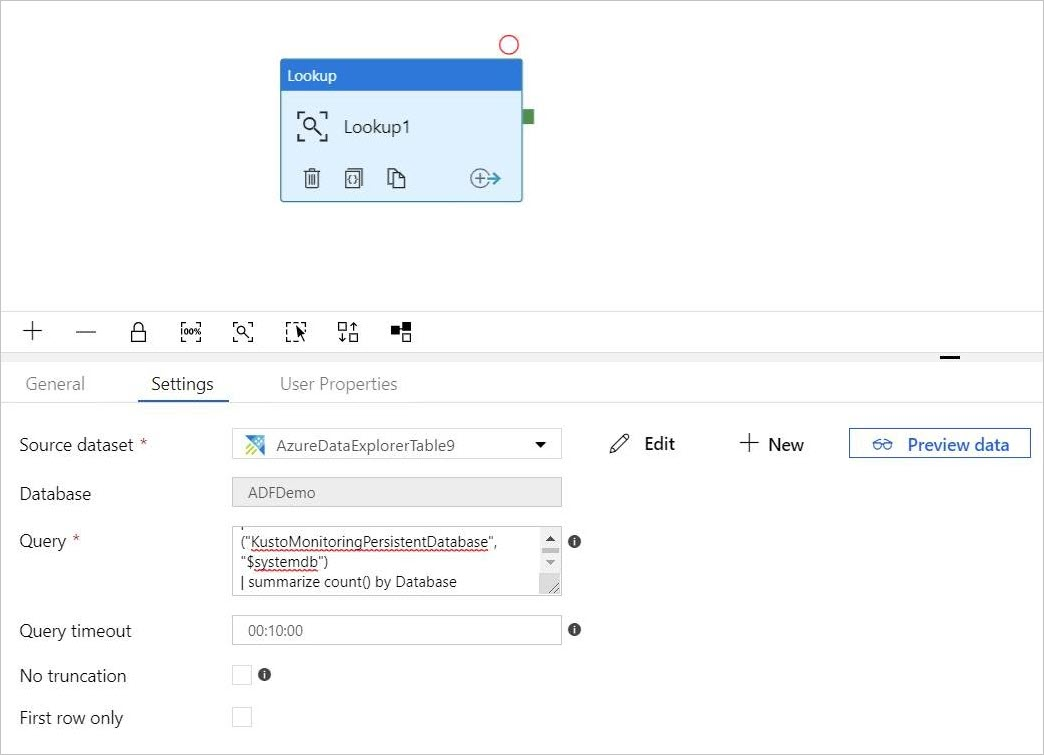
Ajouter une requête à votre activité de recherche
Dans pipeline-4-docs>Settings, ajoutez une requête dans la zone de texte Query (Requête), par exemple :
ClusterQueries | where Database !in ("KustoMonitoringPersistentDatabase", "$systemdb") | summarize count() by DatabaseChangez les propriétés Query timeout (Délai d’expiration de la requête) ou No truncation (Pas de troncation) et First row only (Première ligne uniquement), si nécessaire. Dans ce flux, nous conservons le délai d’expiration de la requête (Query timeout) et décochons les cases.
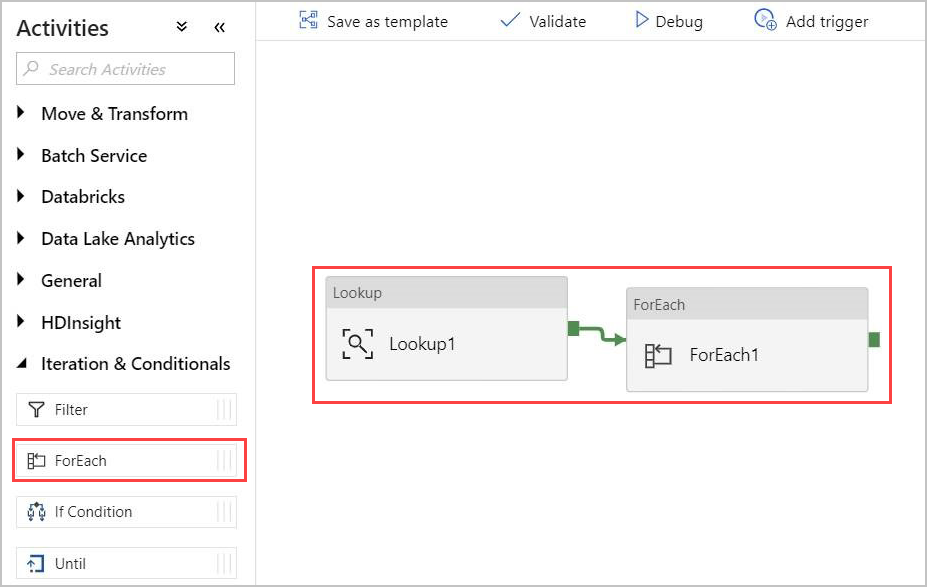
Créer une activité For-Each
L’activité For-Each permet d’effectuer une itération sur une collection et d’exécuter des activités spécifiées dans une boucle.
Maintenant, vous ajoutez une activité For-Each au pipeline. Cette activité traite les données retournées par l’activité Lookup.
Dans le volet Activities, sous Iteration & Conditionals (Itération & Conditions), sélectionnez l’activité ForEach, puis faites-la glisser et déposez-la dans le canevas.
Dessinez une ligne entre la sortie de l’activité Lookup et l’entrée de l’activité ForEach dans le canevas pour les connecter.
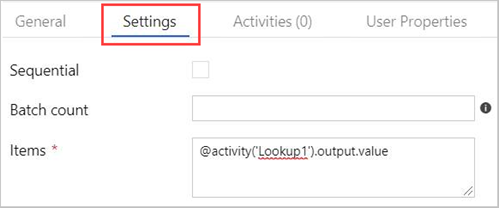
Sélectionnez l’activité ForEach dans le canevas. Sous l’onglet Settings au-dessous :
Cochez la case Sequential pour un effectuer traitement séquentiel des résultats de la recherche, ou laissez-la décochée pour créer un traitement parallèle.
Définissez Batch count (Nombre de lots).
Dans Items (Éléments), fournissez la référence suivante à la valeur de sortie : @activity('Lookup1').output.value
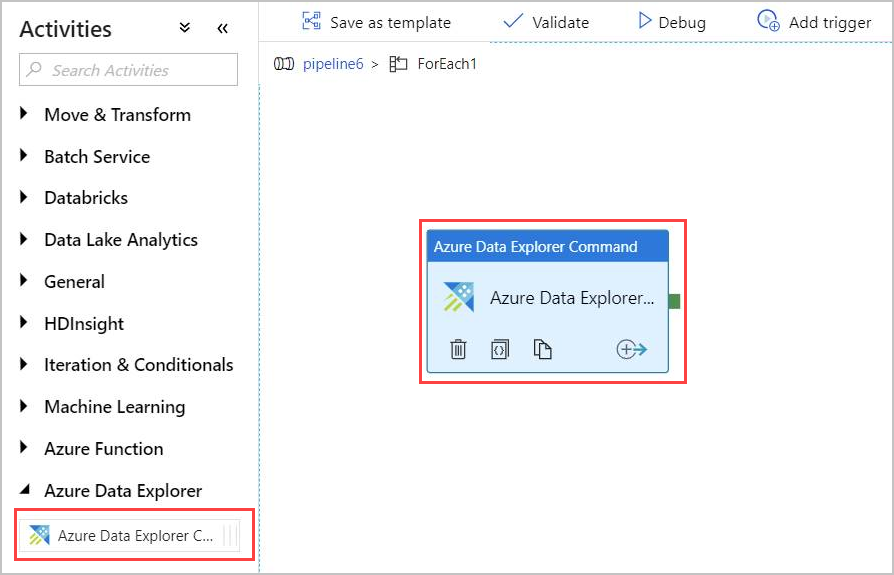
Créer une activité Azure Data Explorer Command dans l’activité ForEach
Double-cliquez sur l’activité ForEach dans le canevas pour l’ouvrir dans un nouveau canevas afin de spécifier les activités dans ForEach.
Dans le volet Activities, sous Azure Data Explorer, sélectionnez l’activité Azure Data Explorer Command, puis faites-la glisser et déposez-la dans le canevas.
Sous l’onglet Connection, sélectionnez le même service lié créé précédemment.
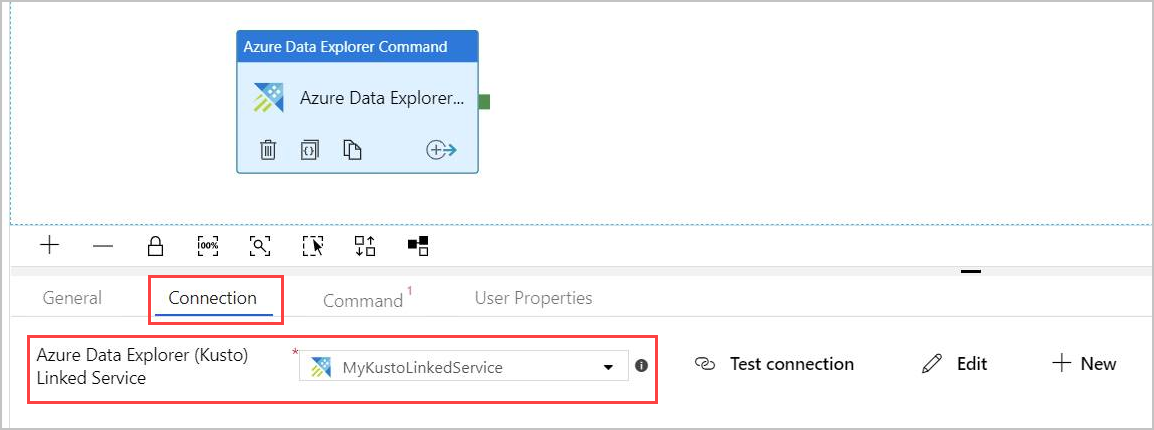
Sous l’onglet Command, fournissez la commande suivante :
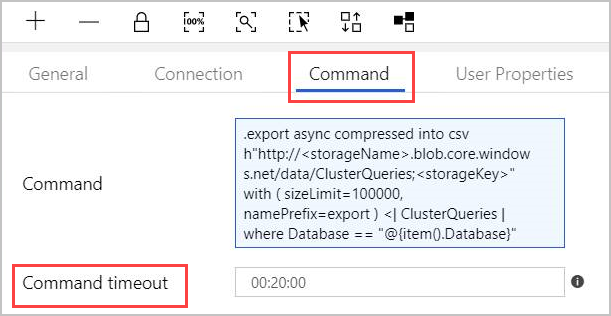
.export async compressed into csv h"http://<storageName>.blob.core.windows.net/data/ClusterQueries;<storageKey>" with ( sizeLimit=100000, namePrefix=export ) <| ClusterQueries | where Database == "@{item().Database}"La Command indique à Azure Data Explorer d’exporter les résultats d’une requête donnée dans un stockage d’objets blob, dans un format compressé. Elle s’exécute de façon asynchrone (à l’aide du modificateur asynchrone). La requête traite la colonne de base de données de chaque ligne dans le résultat de l’activité Lookup. Vous pouvez conserver la valeur du paramètre Command timeout (Délai d’expiration de la commande).
Remarque
L’activité de commande a les limites suivantes :
- Limite de taille : taille de réponse de 1 Mo
- Limite de temps : 20 minutes (valeur par défaut), 1 heure (maximum).
- Si nécessaire, vous pouvez ajouter une requête au résultat à l’aide de la commande AdminThenQuery, afin de réduire la taille/le temps résultant.
Le pipeline est maintenant prêt. Vous pouvez revenir à la vue principale du pipeline en cliquant sur le nom de ce dernier.

Sélectionnez Debug ()Déboguer avant de publier le pipeline. La progression du pipeline peut être supervisée sous l’onglet Output (Sortie).
Vous pouvez publier tout (Publish All), puis ajouter un déclencheur (Add trigger) pour exécuter le pipeline.
Sorties de commande de gestion
La structure de la sortie de l’activité de commande est détaillée ci-dessous. Cette sortie peut être utilisée par l’activité suivante dans le pipeline.
Valeur retournée d’une commande de gestion non asynchrone
Dans une commande de gestion non asynchrone, la structure de la valeur retournée est similaire à la structure du résultat de l’activité de recherche. Le champ count indique le nombre d’enregistrements retournés. Un champ de tableau fixe value contient une liste d’enregistrements.
{
"count": "2",
"value": [
{
"ExtentId": "1b9977fe-e6cf-4cda-84f3-4a7c61f28ecd",
"ExtentSize": 1214.0,
"CompressedSize": 520.0
},
{
"ExtentId": "b897f5a3-62b0-441d-95ca-bf7a88952974",
"ExtentSize": 1114.0,
"CompressedSize": 504.0
}
]
}
Valeur retournée d’une commande de gestion asynchrone
Dans une commande de gestion asynchrone, l’activité interroge la table des opérations en arrière-plan jusqu’à ce que l’opération asynchrone soit terminée ou expire. Par conséquent, la valeur retournée contient le résultat de .show operations OperationId cette propriété OperationId donnée. Vérifiez les valeurs des propriétés State et Status, afin de vérifier que l’opération s’est déroulée normalement.
{
"count": "1",
"value": [
{
"OperationId": "910deeae-dd79-44a4-a3a2-087a90d4bb42",
"Operation": "TableSetOrAppend",
"NodeId": "",
"StartedOn": "2019-06-23T10:12:44.0371419Z",
"LastUpdatedOn": "2019-06-23T10:12:46.7871468Z",
"Duration": "00:00:02.7500049",
"State": "Completed",
"Status": "",
"RootActivityId": "f7c5aaaf-197b-4593-8ba0-e864c94c3c6f",
"ShouldRetry": false,
"Database": "MyDatabase",
"Principal": "<some principal id>",
"User": "<some User id>"
}
]
}