Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
Le schéma lakeflow était précédemment appelé workflow. Le contenu des deux schémas est identique.
Cet article est une référence relative aux tables système lakeflow qui enregistrent l’activité des travaux dans votre compte. Ces tables incluent des enregistrements de tous les espaces de travail de votre compte déployés dans la même région cloud. Pour afficher les enregistrements d’une autre région, vous devez afficher les tables d’un espace de travail déployé dans cette région.
Exigences
- Pour accéder à ces tables système, les utilisateurs doivent :
- Être à la fois un administrateur de metastore et un administrateur de compte, ou
- Disposer des autorisations
USEetSELECTsur les schémas système. Consultez Octroyer un accès aux tables système.
Tables de travaux disponibles
Toutes les tables système liées au travail résident dans le schéma system.lakeflow. Actuellement, le schéma héberge quatre tables :
| Tableau | Descriptif | Prend en charge la diffusion en continu | Période de rétention gratuite | Inclut des données globales ou régionales |
|---|---|---|---|---|
| travaux (préversion publique) | Effectue le suivi de tous les travaux créés dans le compte | Oui | 365 jours | Régional |
| job_tasks (préversion publique) | Effectue le suivi de toutes les tâches de travail qui s’exécutent dans le compte | Oui | 365 jours | Régional |
| job_run_timeline (préversion publique) | Effectue le suivi des exécutions du travail et des métadonnées associées | Oui | 365 jours | Régional |
| job_task_run_timeline (préversion publique) | Effectue le suivi des exécutions des tâches de travail et des métadonnées associées | Oui | 365 jours | Régional |
| pipelines (préversion publique) | Effectue le suivi de tous les pipelines créés dans le compte | Oui | 365 jours | Régional |
Informations de référence détaillées sur le schéma
Les sections suivantes fournissent des références de schéma pour chacune des tables système liées aux travaux.
schéma de la table des travaux
La table jobs est une table de dimension à variation lente (SCD2). Lorsqu’une ligne change, une nouvelle ligne est émise, en remplaçant logiquement la ligne précédente.
Chemin d’accès de la table : system.lakeflow.jobs
| Nom de la colonne | Type de données | Descriptif | Remarques |
|---|---|---|---|
account_id |
ficelle | ID du compte auquel appartient ce travail | |
workspace_id |
ficelle | ID de l’espace de travail auquel appartient ce travail | |
job_id |
ficelle | ID du travail | Unique au sein d’un seul espace de travail |
name |
ficelle | Nom du travail fourni par l’utilisateur | |
description |
ficelle | Description fournie par l’utilisateur du travail | Ce champ est vide si vous avez clés gérées par le client configurées. Non renseigné pour les lignes émises avant fin août 2024 |
creator_id |
ficelle | ID du principal qui a créé le travail | |
tags |
carte | Balises personnalisées fournies par l’utilisateur associées à ce travail | |
change_time |
horodatage | Heure de la dernière modification du travail | Fuseau horaire enregistré en tant que +00:00 (UTC) |
delete_time |
horodatage | Heure à laquelle le travail a été supprimé par l’utilisateur | Fuseau horaire enregistré en tant que +00:00 (UTC) |
run_as |
ficelle | ID de l’utilisateur ou du principal de service dont les autorisations sont utilisées pour l’exécution du travail |
Exemple de requête
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Schéma de la table des tâches
La table tâches de travail est une table de dimensions à variation lente (SCD2). Lorsqu’une ligne change, une nouvelle ligne est émise, en remplaçant logiquement la ligne précédente.
Chemin d’accès de la table : system.lakeflow.job_tasks
| Nom de la colonne | Type de données | Descriptif | Remarques |
|---|---|---|---|
account_id |
ficelle | ID du compte auquel appartient ce travail | |
workspace_id |
ficelle | ID de l’espace de travail auquel appartient ce travail | |
job_id |
ficelle | ID du travail | Unique au sein d’un seul espace de travail |
task_key |
ficelle | Clé de référence pour une tâche dans un travail | Unique au sein d'une seule mission |
depends_on_keys |
tableau | Clés des tâches de toutes les dépendances en amont de cette tâche | |
change_time |
horodatage | Heure de la dernière modification de la tâche | Fuseau horaire enregistré en tant que +00:00 (UTC) |
delete_time |
horodatage | Heure à laquelle une tâche a été supprimée par l’utilisateur | Fuseau horaire enregistré en tant que +00:00 (UTC) |
Exemple de requête
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
Schéma de la table de chronologie d’exécution de travail
La table de chronologie de l’exécution du travail est immuable et terminée au moment où elle est produite.
Chemin d’accès de la table : system.lakeflow.job_run_timeline
| Nom de la colonne | Type de données | Descriptif | Remarques |
|---|---|---|---|
account_id |
ficelle | ID du compte auquel appartient ce travail | |
workspace_id |
ficelle | ID de l’espace de travail auquel appartient ce travail | |
job_id |
ficelle | ID du travail | Cette clé n’est unique qu’au sein d’un seul espace de travail |
run_id |
ficelle | ID de l’exécution du travail | |
period_start_time |
horodatage | Heure de début de l’exécution ou de la période | Les informations de fuseau horaire sont enregistrées à la fin de la valeur avec +00:00 représentant UTC |
period_end_time |
horodatage | Heure de fin de l’exécution d'un programme ou de la période | Les informations de fuseau horaire sont enregistrées à la fin de la valeur avec +00:00 représentant UTC |
trigger_type |
ficelle | Type de déclencheur pouvant déclencher une exécution | Pour connaître les valeurs possibles, consultez Valeurs du type de déclencheur |
run_type |
ficelle | Type d’exécution du travail | Pour connaître les valeurs possibles, consultez Valeurs de type d’exécution |
run_name |
ficelle | Nom d’exécution fourni par l’utilisateur associé à cette exécution de travail | |
compute_ids |
tableau | Tableau contenant les ID de calcul du travail pour l’exécution du travail parent. | À utiliser pour identifier le cluster de travaux utilisé par les types d’exécutions WORKFLOW_RUN. Pour d’autres informations de calcul, reportez-vous à la job_task_run_timeline table.Non renseigné pour les lignes émises avant fin août 2024 |
result_state |
ficelle | Résultat de l’exécution du travail | Pour connaître les valeurs possibles, consultez Valeurs d’état des résultats. |
termination_code |
ficelle | Code de terminaison de l'exécution de la tâche | Pour connaître les valeurs possibles, consultez Valeurs de code d’arrêt. Non renseigné pour les lignes émises avant fin août 2024 |
job_parameters |
carte | Paramètres au niveau du travail utilisés dans l’exécution du travail | Les paramètres déconseillés de notebook_params ne sont pas inclus dans ce champ. Non renseigné pour les lignes émises avant fin août 2024 |
Exemple de requête
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Schéma de la table de chronologie exécutant la tâche de travail
La table de chronologie de la tâche de travail est immuable et terminée au moment où elle est produite.
Chemin d’accès de la table : system.lakeflow.job_task_run_timeline
| Nom de la colonne | Type de données | Descriptif | Remarques |
|---|---|---|---|
account_id |
ficelle | ID du compte auquel appartient ce travail | |
workspace_id |
ficelle | ID de l’espace de travail auquel appartient ce travail | |
job_id |
ficelle | ID du travail | Unique au sein d’un seul espace de travail |
run_id |
ficelle | ID de l’exécution de la tâche | |
job_run_id |
ficelle | ID de l’exécution du travail | Non renseigné pour les lignes émises avant fin août 2024 |
parent_run_id |
ficelle | ID de l’exécution parente | Non renseigné pour les lignes émises avant fin août 2024 |
period_start_time |
horodatage | Heure de début de la tâche ou de la période | Les informations de fuseau horaire sont enregistrées à la fin de la valeur avec +00:00 représentant UTC |
period_end_time |
horodatage | Heure de fin de la tâche ou de la période | Les informations de fuseau horaire sont enregistrées à la fin de la valeur avec +00:00 représentant UTC |
task_key |
ficelle | Clé de référence pour une tâche dans un travail | Cette clé n’est unique qu’au sein d’un seul travail |
compute_ids |
tableau | Le tableau compute_ids contient des ID de clusters de travaux, de clusters interactifs et d’entrepôts SQL utilisés par la tâche de travail | |
result_state |
ficelle | Résultat de l’exécution de la tâche de travail | Pour connaître les valeurs possibles, consultez Valeurs d’état des résultats. |
termination_code |
ficelle | Code d’arrêt de l’exécution de la tâche | Pour connaître les valeurs possibles, consultez Valeurs de code d’arrêt. Non renseigné pour les lignes émises avant fin août 2024 |
Schéma de la table des pipelines
La table pipelines est une table de dimension à variation lente (SCD2). Lorsqu’une ligne change, une nouvelle ligne est émise, en remplaçant logiquement la ligne précédente.
Chemin d’accès de la table : system.lakeflow.pipelines
| Nom de la colonne | Type de données | Descriptif | Remarques |
|---|---|---|---|
account_id |
ficelle | ID du compte auquel appartient ce pipeline | |
workspace_id |
ficelle | L'ID de l’espace de travail auquel appartient ce pipeline | |
pipeline_id |
ficelle | L'ID du pipeline | Unique au sein d’un seul espace de travail |
pipeline_type |
ficelle | Type du pipeline | Pour connaître les valeurs possibles, consultez valeurs de type de pipeline |
name |
ficelle | Nom fourni par l’utilisateur du pipeline | |
created_by |
ficelle | E-mail de l’utilisateur ou de l’ID du principal de service qui a créé le pipeline | |
run_as |
ficelle | E-mail de l’utilisateur ou de l’ID du principal de service dont les autorisations sont utilisées pour l’exécution du pipeline | |
tags |
carte | Balises personnalisées fournies par l’utilisateur associées à ce travail | |
settings |
Struct | Les paramètres du pipeline | Afficher les paramètres du pipeline |
configuration |
carte | Configuration fournie par l’utilisateur du pipeline | |
change_time |
horodatage | Heure de la dernière modification du pipeline | Fuseau horaire enregistré en tant que +00:00 (UTC) |
delete_time |
horodatage | Heure à laquelle le pipeline a été supprimé par l’utilisateur | Fuseau horaire enregistré en tant que +00:00 (UTC) |
Exemple de requête
-- Get the most recent version of a pipeline
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
-- Enrich billing logs with pipeline metadata
with latest_pipelines AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
)
SELECT
usage.*,
pipelines.*
FROM system.billing.usage
LEFT JOIN latest_pipelines
ON (usage.workspace_id = pipelines.workspace_id
AND usage.usage_metadata.dlt_pipeline_id = pipelines.pipeline_id)
WHERE
usage.usage_metadata.dlt_pipeline_id IS NOT NULL
modèles de jointure courants
Les sections suivantes fournissent des exemples de requêtes qui mettent en évidence les modèles de jointure couramment utilisés pour les tables système de travaux.
Joindre les tables des travaux et des chronologies d’exécution des travaux
Enrichir l’exécution d’un travail avec un nom de travail
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Joindre les tables de chronologie d’exécution des travaux et d’utilisation
Enrichir chaque journal de facturation avec les métadonnées d’exécution du travail
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Calculer le coût par exécution du travail
Cette requête se joint à la table système billing.usage pour calculer un coût par exécution de tâche.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Obtenir les journaux d’utilisation d’un travail SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Joindre les tables de chronologie d’exécution de tâches de travaux et de clusters
Enrichir les exécutions de tâches avec les métadonnées des clusters
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Rechercher les travaux en cours d’exécution sur le calcul à usage général
Cette requête s’associe à la compute.clusters table système pour renvoyer les travaux récents exécutés sur le calcul à usage général au lieu du calcul des travaux.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Tableau de bord de surveillance des emplois
Le tableau de bord ci-après utilise des tables système pour vous aider à débuter la surveillance de vos travaux et de la santé opérationnelle. Il inclut des cas d’usage courants tels que le suivi des performances des travaux, la surveillance des défaillances et l’utilisation des ressources.
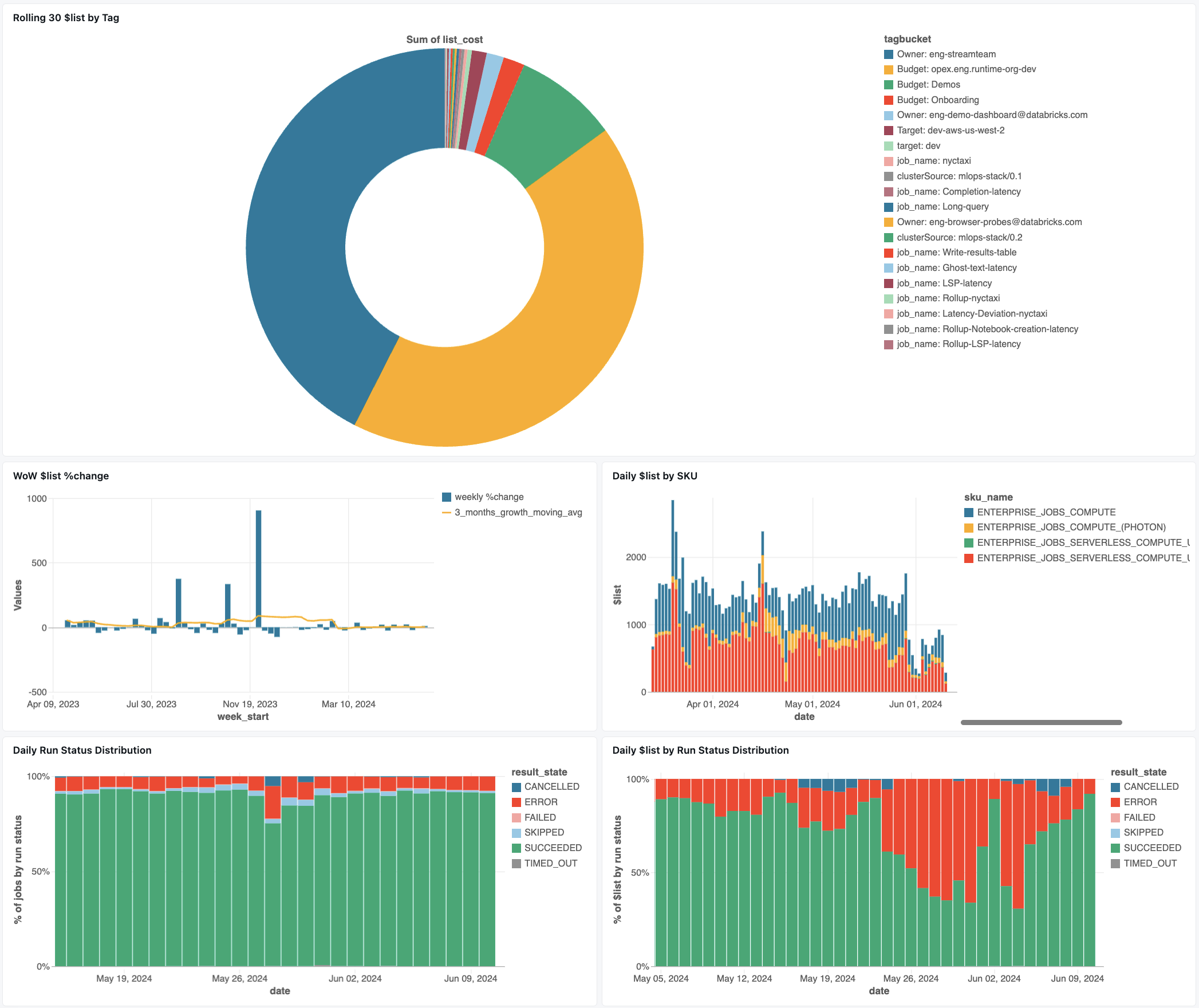
Pour plus d’informations sur le téléchargement du tableau de bord, consultez Surveiller les coûts et les performances des travaux avec les tables système.
Résolution des problèmes
La tâche n'est pas consignée dans la table lakeflow.jobs
Si un travail n’est pas visible dans les tables système :
- Le travail n’a pas été modifié au cours des 365 derniers jours
- Modifiez les champs de l'emploi présents dans le schéma afin d'émettre un nouvel enregistrement.
- Le travail a été créé dans une autre région
- Création récente d’emploi (décalage dans les données)
Impossible de trouver un travail affiché dans la job_run_timeline table
Toutes les exécutions des travaux ne sont pas visibles partout. Bien que les entrées JOB_RUN apparaissent dans toutes les tables liées aux travaux, les WORKFLOW_RUN (exécutions de workflows de notebooks) sont enregistrées seulement dans job_run_timeline et les SUBMIT_RUN (exécutions soumises une seule fois) sont enregistrées seulement dans les deux tables de chronologie. Ces exécutions ne sont pas renseignées dans d’autres tables système des travaux, comme jobs ou job_tasks.
Consultez le tableau Types d’exécution ci-dessous pour obtenir une répartition détaillée des emplacements où chaque type d’exécution est visible et accessible.
Exécution de travail non visible dans la table billing.usage
Dans system.billing.usage, le usage_metadata.job_id est renseigné seulement pour les tâches qui s’exécutent sur le calcul des travaux ou sur le calcul serverless.
En outre, les travaux WORKFLOW_RUN n’ont pas leur propre attribution de usage_metadata.job_id ou de usage_metadata.job_run_id dans system.billing.usage.
Au lieu de cela, leur utilisation des ressources de calcul est attribuée au bloc-notes parent qui l'a déclenchée.
Cela signifie que lorsqu’un bloc-notes lance une exécution de flux de travail, tous les coûts de calcul apparaissent sous l’utilisation du bloc-notes parent, et non en tant que travail de flux de travail distinct.
Pour plus d’informations, consultez la référence d'utilisation des métadonnées .
Calculer le coût d’un travail s'exécutant sur un calculateur polyvalent
Le calcul précis des coûts pour les travaux exécutés sur un calcul dédié n’est pas possible avec une précision de 100 %. Lorsqu’un travail s’exécute sur un calcul interactif (à usage unique), plusieurs charges de travail telles que des notebooks, des requêtes SQL ou d’autres travaux s’exécutent souvent simultanément sur cette même ressource de calcul. Étant donné que les ressources de cluster sont partagées, il n’existe aucun mappage direct 1:1 entre les coûts de calcul et les exécutions de travaux individuelles.
Pour un suivi précis des coûts des travaux, Databricks recommande d’exécuter les travaux sur des calculs de travaux dédiés ou sur un calcul serverless, où le usage_metadata.job_id et le usage_metadata.job_run_id permettent une attribution précise des coûts.
Si vous devez utiliser le calcul à usage unique, vous pouvez :
- Surveillez l’utilisation globale du cluster et les coûts dans
system.billing.usageen fonction deusage_metadata.cluster_id. - Suivez séparément les métriques de temps d'exécution des tâches.
- Considérez que toute estimation des coûts sera approximative en raison des ressources partagées.
Consultez la référence de la métadonnée d'utilisation pour obtenir plus d'informations sur l’attribution des coûts.
Valeurs de référence
La section suivante inclut des références pour sélectionner des colonnes dans des tables liées aux travaux.
Valeurs du type de déclencheur
Dans le job_run_timeline tableau, les valeurs possibles pour la trigger_type colonne sont les suivantes :
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Valeurs du type d’exécution
Dans le job_run_timeline tableau, les valeurs possibles pour la run_type colonne sont les suivantes :
| Catégorie | Descriptif | Emplacement de l’interface utilisateur | Point de terminaison d’API | Tables système |
|---|---|---|---|---|
JOB_RUN |
Exécution de travaux standard | Interface utilisateur des travaux et des exécutions des travaux | Points de terminaison /jobs et /jobs/runs | emplois, tâches_de_travail, calendrier_d_exécution_du_travail, calendrier_d_exécution_des_tâches_de_travail |
SUBMIT_RUN |
Exécution unique via POST /jobs/runs/submit | Interface utilisateur des exécutions de travaux uniquement | Points de terminaison /jobs/runs uniquement | chronologie_du_démarrage_de_travail, chronologie_de_l'exécution_de_la_tâche_de_travail |
WORKFLOW_RUN |
Exécution lancée à partir d’un flux de travail de bloc-notes | Non visible | Non accessible | chronologie de l'exécution de tâche |
Valeurs d’état de résultat
Dans les tables job_task_run_timeline et job_run_timeline, les valeurs possibles pour la colonne result_state sont les suivantes :
| État | Descriptif |
|---|---|
SUCCEEDED |
L’exécution s’est terminée correctement. |
FAILED |
L’exécution s’est terminée avec une erreur. |
SKIPPED |
L’exécution n’a pas eu lieu car une condition n’était pas remplie. |
CANCELLED |
L’exécution a été annulée à la demande de l’utilisateur |
TIMED_OUT |
L’exécution a été arrêtée après avoir atteint le délai d’expiration. |
ERROR |
L’exécution s’est terminée avec une erreur. |
BLOCKED |
L’exécution a été bloquée sur une dépendance en amont. |
Valeurs de code d’arrêt
Dans les tables job_task_run_timeline et job_run_timeline, les valeurs possibles pour la colonne termination_code sont les suivantes :
| Code de terminaison | Descriptif |
|---|---|
SUCCESS |
L’exécution s’est terminée correctement. |
CANCELLED |
L’exécution a été annulée pendant l’exécution par la plateforme Databricks ; par exemple, si la durée maximale d’exécution a été dépassée |
SKIPPED |
L’exécution n’a jamais eu lieu, par exemple si l’exécution de la tâche en amont a échoué, que la condition de type de dépendance n’a pas été remplie ou qu’il n’y avait aucune tâche concrète à exécuter. |
DRIVER_ERROR |
L’exécution a rencontré une erreur lors de la communication avec le pilote Spark. |
CLUSTER_ERROR |
Échec de l’exécution en raison d’une erreur de cluster |
REPOSITORY_CHECKOUT_FAILED |
Échec de la finalisation du paiement en raison d’une erreur lors de la communication avec le service tiers |
INVALID_CLUSTER_REQUEST |
L’exécution a échoué, car elle a émis une demande non valide pour démarrer le cluster |
WORKSPACE_RUN_LIMIT_EXCEEDED |
L’espace de travail a atteint le quota pour le nombre maximal d’exécutions actives simultanées. Envisagez de planifier les exécutions sur une période plus longue. |
FEATURE_DISABLED |
L’exécution a échoué, car elle a essayé d’accéder à une fonctionnalité indisponible pour l’espace de travail |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Le nombre de demandes de création, de démarrage et de montée en puissance du cluster a dépassé la limite de débit allouée. Il est conseillé de répartir l’exécution de l'opération sur une période plus longue. |
STORAGE_ACCESS_ERROR |
L’exécution a échoué en raison d’une erreur lors de l’accès au stockage d’objets blob du client |
RUN_EXECUTION_ERROR |
L’exécution s’est terminée avec des défaillances de la tâche. |
UNAUTHORIZED_ERROR |
L’exécution a échoué en raison d’un problème d’autorisation lors de l’accès à une ressource |
LIBRARY_INSTALLATION_ERROR |
L’exécution a échoué lors de l’installation de la bibliothèque demandée par l’utilisateur. Les causes peuvent inclure, mais ne sont pas limitées à : la bibliothèque fournie n’est pas valide, il existe des autorisations insuffisantes pour installer la bibliothèque, etc. |
MAX_CONCURRENT_RUNS_EXCEEDED |
L’exécution planifiée dépasse la limite de nombre maximal d’exécutions simultanées définies pour le travail |
MAX_SPARK_CONTEXTS_EXCEEDED |
L’exécution est planifiée sur un cluster qui a déjà atteint le nombre maximal de contextes qu’il est configuré pour créer |
RESOURCE_NOT_FOUND |
Une ressource nécessaire pour l’exécution n’existe pas |
INVALID_RUN_CONFIGURATION |
L’exécution a échoué en raison d’une configuration non valide |
CLOUD_FAILURE |
L’exécution a échoué en raison d’un problème de fournisseur de cloud |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
L’exécution a été ignorée, car la limite de taille de la file d’attente au niveau du travail a été atteinte. |
Valeurs de type de pipeline
Dans le pipelines tableau, les valeurs possibles pour la pipeline_type colonne sont les suivantes :
| Type de pipeline | Descriptif |
|---|---|
ETL_PIPELINE |
Pipeline standard |
MATERIALIZED_VIEW |
Vues matérialisées dans Databricks SQL |
STREAMING_TABLE |
Tables de streaming dans Databricks SQL |
INGESTION_PIPELINE |
Ingestion Lakeflow Connect |
INGESTION_GATEWAY |
Ingesteur de la passerelle Lakeflow Connect |
Informations de référence sur les paramètres du pipeline
Dans le pipelines tableau, les valeurs possibles pour la settings colonne sont les suivantes :
| Valeur | Descriptif |
|---|---|
photon |
Indicateur indiquant s’il faut utiliser Photon pour exécuter le pipeline |
development |
Indicateur indiquant s’il faut exécuter le pipeline en mode de développement ou de production |
continuous |
Indicateur indiquant s’il faut exécuter le pipeline en continu |
serverless |
Indicateur indiquant s’il faut exécuter le pipeline sur un cluster serverless |
edition |
Édition de produit pour l'exécution du pipeline |
channel |
Version du runtime de pipeline à utiliser |