Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Le calcul serverless pour les flux de travail vous permet d’exécuter votre travail sans configurer et déployer l’infrastructure. Avec le calcul serverless, vous vous concentrez sur l’implémentation de vos pipelines de traitement et d’analyse des données, et Azure Databricks gère efficacement les ressources de calcul, notamment l’optimisation et la mise à l’échelle du calcul pour vos charges de travail. La mise à l’échelle automatique et Photon sont automatiquement activés pour les ressources de calcul qui exécutent votre travail.
Le calcul serverless pour les flux de travail optimise automatiquement et en permanence l’infrastructure, comme les types d’instances, la mémoire et les moteurs de traitement, pour garantir les meilleures performances en fonction des besoins de traitement spécifiques de vos charges de travail.
Databricks met automatiquement à niveau la version de Databricks Runtime pour prendre en charge les améliorations et les mises à niveau vers la plateforme tout en garantissant la stabilité de vos travaux. Pour voir la version actuelle de Databricks Runtime utilisée par le calcul serverless pour des workflows, consultez les Notes de publication du calcul serverless.
Étant donné que l’autorisation de création de cluster n’est pas nécessaire, tous les utilisateurs de l’espace de travail peuvent utiliser le calcul serverless pour exécuter leurs flux de travail.
Cet article décrit l’utilisation de l’interface utilisateur des travaux Lakeflow pour créer et exécuter des travaux qui utilisent le calcul serverless. Vous pouvez également automatiser la création et l’exécution de travaux qui utilisent le calcul serverless avec l’API Travaux, les Packs de ressources Databricks et le Kit de développement logiciel (SDK) Databricks pour Python.
- Pour en savoir plus sur l’utilisation de l’API Travaux pour créer et exécuter des travaux qui utilisent le calcul serverless, consultez Travaux dans la référence de l’API REST.
- Pour en savoir plus sur l’utilisation des bundles de ressources Databricks pour créer et exécuter des travaux qui utilisent le calcul serverless, consultez Développer un travail avec databricks Asset Bundles.
- Pour en savoir plus sur l’utilisation du Kit de développement logiciel (SDK) Databricks pour Python afin de créer et d’exécuter des travaux qui utilisent le calcul serverless, consultez l’article Kit de développement logiciel (SDK) Databricks pour Python.
Spécifications
- Votre espace de travail Azure Databricks doit avoir Unity Catalog activé.
- Étant donné que le calcul serverless pour les flux de travail utilise le mode d’accès standard, vos charges de travail doivent prendre en charge ce mode d’accès.
- Votre espace de travail Databricks doit se trouver dans une région prise en charge. Consultez Fonctionnalités avec une disponibilité régionale limitée.
- Le calcul serverless doit être activé sur votre compte Azure Databricks. Consultez Activer le calcul serverless.
Créer une tâche avec le calcul sans serveur
Remarque
Étant donné que le calcul serverless pour les flux de travail garantit que des ressources suffisantes sont approvisionnées pour exécuter vos charges de travail, vous pouvez rencontrer des temps de démarrage accrus lors de l’exécution d’un travail nécessitant de grandes quantités de mémoire ou incluant de nombreuses tâches.
Le calcul serverless est pris en charge avec les types de tâches de notebook, de script Python, dbt et de fichier wheel Python. Par défaut, le calcul serverless est sélectionné comme type de calcul lorsque vous créez un travail et ajoutez l’un des types de tâches pris en charge.
Databricks recommande d’utiliser le calcul serverless pour toutes les tâches de travail. Vous pouvez également spécifier différents types de calcul pour les tâches d’un travail, ce qui peut être nécessaire si un type de tâche n’est pas pris en charge par le calcul serverless pour les flux de travail.
Pour gérer les connexions réseau sortantes pour vos tâches, consultez Qu’est-ce que le contrôle de sortie sans serveur ?
Configurer un travail existant pour utiliser le calcul serverless
Vous pouvez modifier un travail existant pour utiliser le calcul serverless pour les types de tâches pris en charge lorsque vous modifiez le travail. Pour basculer vers le calcul serverless, effectuez l’une des opérations suivantes :
- Dans le volet latéral Détails du travail, cliquez sur Changer sous Calcul, puis Nouveau, entrez ou mettez à jour les paramètres, puis cliquez sur Mettre à jour.
- Cliquez sur
 dans le menu déroulant Calcul et sélectionnez Serverless.
dans le menu déroulant Calcul et sélectionnez Serverless.

Planifier un notebook en utilisant un calcul serverless
Outre l’utilisation de l’interface utilisateur Travaux pour créer et planifier un travail à l’aide du calcul serverless, vous pouvez créer et exécuter un travail qui utilise le calcul serverless directement à partir d’un notebook Databricks. Consultez Créer et gérer des tâches de notebooks planifiées.
Sélectionnez une politique budgétaire serverless pour votre utilisation sans serveur
Important
Cette fonctionnalité est disponible en préversion publique.
Les politiques de budget sans serveur permettent à votre organisation d’appliquer des étiquettes personnalisées sur l’utilisation sans serveur pour une attribution détaillée des coûts.
Si votre espace de travail utilise des politiques de budget serverless pour attribuer l'utilisation serverless, vous pouvez sélectionner la politique de budget serverless de votre tâche à l'aide du paramètre Politique de budget dans l'interface des détails de la tâche. Si vous n’êtes affecté qu’à une stratégie de budget sans serveur, la stratégie est automatiquement sélectionnée pour vos nouvelles tâches.
Remarque
Une fois que vous avez reçu une politique de budget serverless, vos travaux existants ne sont pas automatiquement étiquetés avec votre politique. Vous devez mettre à jour manuellement les tâches existantes si vous souhaitez y attacher une stratégie.
Pour plus d’informations sur les politiques de budget serverless, consultez Utilisation des attributs avec les politiques de budget serverless.
Sélectionner un mode de performances
Vous pouvez choisir la vitesse à laquelle les tâches serverless de votre travail s’exécutent à l’aide du paramètre Optimisé pour les performances dans la page des détails du travail.
Lorsque l’optimisation des performances est désactivée, le travail utilise le mode de performances standard. Ce mode est conçu pour réduire les coûts des charges de travail où une latence de lancement légèrement plus élevée est acceptable. Les travaux peuvent prendre 4 à 6 minutes pour démarrer, en fonction de la disponibilité du calcul et de la planification optimisée.
Lorsque l’optimisation des performances est activée, le travail démarre et s’exécute plus rapidement. Ce mode est conçu pour les charges de travail sensibles au temps.
Pour configurer le paramètre Optimisé pour les performances dans l’interface utilisateur, un job doit comporter au moins une tâche serverless. Ce paramètre affecte uniquement les tâches serverless au sein du travail.
définir des paramètres de configuration Spark
Pour automatiser la configuration de Spark sur le calcul serverless, Databricks autorise uniquement la définition de paramètres de configuration Spark spécifiques. Pour obtenir la liste des paramètres autorisés, consultez Paramètres de configuration Spark pris en charge.
Vous pouvez définir des paramètres de configuration Spark au niveau de la session uniquement. Pour ce faire, définissez-les dans un bloc-notes et ajoutez le bloc-notes à une tâche incluse dans le même travail que celui qui utilise les paramètres. Consultez Obtenir et définir les propriétés de configuration d’Apache Spark dans un notebook.
Configurer des environnements et des dépendances
Pour savoir comment installer des bibliothèques et des dépendances à l’aide du calcul serverless, consultez Configurer l’environnement serverless.
Configurer une mémoire élevée pour les tâches d'ordinateurs portables
Important
Cette fonctionnalité est disponible en préversion publique.
Vous pouvez configurer des tâches de notebook pour utiliser une taille de mémoire supérieure. Pour ce faire, configurez le paramètre Mémoire dans le panneau latéral Environnement du notebook. Consultez Utiliser un calcul serverless à mémoire élevée.
La mémoire élevée est disponible uniquement pour les types de tâches d'ordinateurs portables.
Configurer l’optimisation automatique du calcul serverless pour interdire les nouvelles tentatives
L’optimisation automatique du calcul serverless pour les flux de travail optimise automatiquement le calcul utilisé pour exécuter vos travaux et réessaye les tâches ayant échoué. L’optimisation automatique est activée par défaut et Databricks recommande de la laisser activée pour garantir que les charges de travail critiques s’exécutent correctement au moins une fois. Toutefois, si vous avez des charges de travail qui doivent être exécutées au maximum une fois, par exemple des travaux qui ne sont pas idempotents, vous pouvez désactiver l’optimisation automatique lors de l’ajout ou de la modification d’une tâche :
- En regard de Nouvelles tentatives, cliquez sur Ajouter (ou
 si une stratégie de nouvelle tentative existe déjà).
si une stratégie de nouvelle tentative existe déjà). - Dans la boîte de dialogue Stratégie de réessais, décochez Activer l’optimisation automatique serverless (peut inclure des réessais supplémentaires).
- Cliquez sur Confirmer.
- Si vous ajoutez une tâche, cliquez sur Créer une tâche. Si vous modifiez une tâche, cliquez sur Enregistrer la tâche.
Surveiller le coût des travaux qui utilisent le calcul serverless pour les flux de travail
Vous pouvez surveiller le coût des travaux qui utilisent le calcul serverless pour des workflows en interrogeant la table système de l’utilisation facturable. Ce tableau est mis à jour pour inclure des attributs d'utilisateur et de charge de travail concernant les coûts des services sans serveur. Consultez Informations de référence sur la table système de l’utilisation facturable.
Pour plus d’informations sur les tarifs actuels et les promotions, consultez la page de tarification flux de travail.
Voir les détails des requêtes pour les exécutions de travaux
Vous pouvez afficher des informations d’exécution détaillées pour vos instructions Spark, telles que les métriques et les plans de requête.
Pour accéder aux détails de la requête à partir de l’interface utilisateur des travaux, procédez comme suit :
Dans la barre latérale de votre espace de travail Azure Databricks, cliquez sur Travaux & Pipelines.
Si vous le souhaitez, sélectionnez le filtre Travaux .
Cliquez sur le nom du travail à afficher.
Cliquez sur l’exécution spécifique à afficher.
Cliquez sur Chronologie pour afficher l’exécution sous forme de chronologie, fractionnée en tâches individuelles.
Cliquez sur la flèche en regard du nom de la tâche pour afficher les instructions de requête et leurs runtimes.
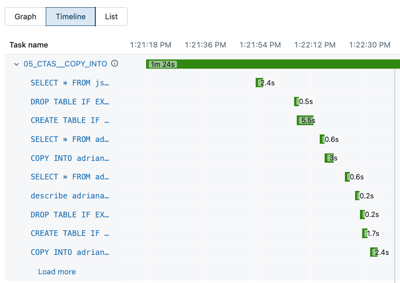
Cliquez sur une instruction pour ouvrir le panneau des détails de la requête. Consultez afficher les détails de la requête pour en savoir plus sur les informations disponibles dans ce panneau.
Pour afficher l’historique des requêtes d’une tâche :
- Dans la section Calcul du panneau latéral Exécution de la tâche, cliquez sur Historique des requêtes.
- Vous êtes redirigé vers l’Historique des requêtes, préfiltré sur l’ID d’exécution de la tâche dans laquelle vous étiez.
Pour plus d’informations sur l’utilisation de l’historique des requêtes, consultez l’accès à l’historique des requêtes pour les Lakeflow Declarative Pipelines et l’historique des requêtes.
Limites
Pour obtenir la liste des limitations du calcul serverless pour les workflows, consultez Limitations du calcul serverless dans les notes de publication du calcul serverless.