Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans cet article, vous allez découvrir quelles options sont disponibles pour écrire des demandes de requête pour les modèles de base et comment les envoyer à votre point de terminaison de service de modèle. Vous pouvez interroger des modèles de base hébergés par Databricks et des modèles de base hébergés en dehors de Databricks.
Pour les requêtes portant sur des modèles Machine Learning ou Python traditionnels, consultez Mise en service de points de terminaison des requêtes pour les modèles personnalisés.
Mosaïque AI Model Service prend en charge les API Foundation Models et les modèles externes pour accéder aux modèles de base. Model Serving utilise une API compatible avec OpenAI unifiée et un SDK pour les interroger. Cela permet d’expérimenter et de personnaliser des modèles de base pour la production dans les clouds et fournisseurs pris en charge.
Options de requête
Mosaïque AI Model Service fournit les options suivantes pour envoyer des demandes de requête aux points de terminaison qui servent des modèles de base :
| Méthode | Détails |
|---|---|
| Client OpenAI | Interrogez un modèle hébergé par un point de terminaison de service de modèles Mosaic AI en utilisant le client OpenAI. Spécifiez le nom du point de terminaison de mise en service de modèle comme entrée du model. Pris en charge pour les modèles de conversation, d’incorporation et de complétion rendus disponibles par des API de modèle de fondation ou des modèles externes. |
| Fonctions IA | Appelez l’inférence de modèle directement à partir de SQL à l’aide de la fonction SQL ai_query. Consultez Exemple : Interroger un modèle de base. |
| Interface utilisateur de mise en service | Sélectionner Point de terminaison de requête dans la page Point de terminaison de service. Insérez les données d’entrée du modèle au format JSON, puis cliquez sur Envoyer la requête. Si le modèle a un exemple d’entrée enregistré, utilisez Afficher l’exemple pour le charger. |
| API REST | Appelez et interrogez le modèle en utilisant l’API REST. Pour plus de détails, consultez POST /serving-endpoints/{name}/invocations. Pour les requêtes de scoring adressées aux points de terminaison servant plusieurs modèles, consultez Interroger des modèles individuels derrière un point de terminaison. |
| Kit de développement logiciel (SDK) de déploiements MLflow | Utilisez la fonction predict() du Kit de développement logiciel (SDK) MLflow Deployments pour interroger le modèle. |
| Kit de développement logiciel (SDK) Databricks Python | Kit de développement logiciel (SDK) Databricks Python est une couche sur l’API REST. Il gère les détails de bas niveau, tels que l’authentification, ce qui facilite l’interaction avec les modèles. |
Exigences
- Un point de terminaison de mise en service de modèles.
- Un espace de travail Databricks dans une région prise en charge.
- Pour envoyer une demande de scoring via le client OpenAI, l’API REST ou le Kit de développement logiciel (SDK) de déploiement MLflow, vous devez disposer d’un jeton d’API Databricks.
Importante
À titre de meilleure pratique de sécurité pour les scénarios de production, Databricks vous recommande d’utiliser des jetons OAuth machine à machine pour l’authentification en production.
Pour les tests et le développement, Databricks recommande d’utiliser un jeton d’accès personnel appartenant à des principaux de service et non pas à des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Installer des packages
Après avoir sélectionné une méthode d’interrogation, vous devez d’abord installer le package approprié sur votre cluster.
Client OpenAI
Pour utiliser le client OpenAI, le package databricks-openai doit être installé sur votre cluster. Ce package fournit un client OpenAI avec une autorisation automatiquement configurée pour interroger des modèles IA génératifs. Exécutez la commande suivante dans votre Notebook ou dans votre terminal local :
pip install -U databricks-openai
Les éléments suivants ne sont nécessaires que lors de l’installation du package sur un Notebook Databricks
dbutils.library.restartPython()
API REST
L'accès à l'API REST de distribution est disponible dans Databricks Runtime pour le Machine Learning.
Kit de développement logiciel (SDK) de déploiements MLflow
!pip install mlflow
Les éléments suivants ne sont nécessaires que lors de l’installation du package sur un Notebook Databricks
dbutils.library.restartPython()
Kit de développement logiciel (SDK) Databricks Python
Le kit de développement logiciel (SDK) Databricks pour Python est déjà installé sur tous les clusters Azure Databricks qui utilisent Databricks Runtime 13.3 LTS ou une version ultérieure. Pour les clusters Azure Databricks qui utilisent Databricks Runtime 12.2 LTS et les versions antérieures, vous devez d’abord installer le kit de développement logiciel (SDK) Databricks pour Python. Consultez le Kit de développement logiciel (SDK) Databricks pour Python.
Types de modèles de base
Le tableau suivant récapitule les modèles de base pris en charge en fonction du type de tâche.
Importante
Meta-Llama-3.1-405B-Instruct sera mis hors service,
- À compter du 15 février 2026 pour les charges de travail payées par jeton.
- À compter du 15 mai 2026 pour les charges de travail à débit provisionné.
Consultez les modèles supprimés pour le modèle de remplacement recommandé et pour obtenir des conseils sur la migration pendant la dépréciation.
| Type de tâche | Descriptif | Modèles pris en charge | Quand l’utiliser ? Cas d’usage recommandés |
|---|---|---|---|
| Usage général | Modèles conçus pour comprendre et participer à des conversations naturelles à plusieurs tours. Elles sont affinées sur de grands jeux de données de dialogue humain, ce qui leur permet de générer des réponses contextuellement pertinentes, de suivre l’historique des conversations et de fournir des interactions cohérentes et humaines sur différents sujets. | Les modèles de base hébergés par Databricks sont les suivants :
Voici les modèles externes pris en charge :
|
Recommandé pour les scénarios nécessitant un dialogue naturel à plusieurs tours et une compréhension contextuelle :
|
| Embeddings | Les modèles d’incorporation sont des systèmes Machine Learning qui transforment des données complexes, telles que du texte, des images ou de l’audio, en vecteurs numériques compacts appelés incorporations. Ces vecteurs capturent les fonctionnalités et relations essentielles au sein des données, ce qui permet une comparaison efficace, un clustering et une recherche sémantique. | Les modèles de base hébergés par Databricks sont les suivants : Voici les modèles externes pris en charge :
|
Recommandé pour les applications où la compréhension sémantique, la comparaison de similarité et la récupération efficace ou le clustering de données complexes sont essentielles :
|
| Vision | Modèles conçus pour traiter, interpréter et analyser des données visuelles, telles que des images et des vidéos afin que les machines puissent « voir » et comprendre le monde visuel. | Les modèles de base hébergés par Databricks sont les suivants :
Voici les modèles externes pris en charge :
|
Recommandé partout où l’analyse automatisée, précise et évolutive des informations visuelles est nécessaire :
|
| Raisonnement | Systèmes IA avancés conçus pour simuler une pensée logique semblable à l’homme. Les modèles de raisonnement intègrent des techniques telles que la logique symbolique, le raisonnement probabiliste et les réseaux neuronaux pour analyser le contexte, décomposer les tâches et expliquer leur prise de décision. | Les modèles de base hébergés par Databricks sont les suivants :
Voici les modèles externes pris en charge :
|
Recommandé partout où l’analyse automatisée, précise et évolutive des informations visuelles est nécessaire :
|
Appeler une fonction
L’appel de fonction Databricks compatible avec OpenAI n’est disponible que pendant le service de modèles dans le cadre des API Foundation Model et des points de terminaison de mise en service qui servent des modèles externes. Pour plus d’informations, consultez l’appel de fonction sur Azure Databricks.
Sorties structurées
Les sorties structurées sont compatibles avec OpenAI et sont disponibles uniquement lors de l'exécution du modèle dans le cadre des API du modèle de base. Pour plus d’informations, consultez Les sorties structurées sur Azure Databricks.
Mise en cache de commande
La mise en cache des requêtes est prise en charge pour les modèles Claude hébergés par Databricks dans le cadre des API des modèles fondamentaux.
Vous pouvez spécifier le cache_control paramètre dans vos demandes de requête pour mettre en cache les éléments suivants :
- Messages de contenu texte dans le
messages.contenttableau. - Réflexion du contenu des messages dans le
messages.contenttableau. - Blocs de contenu d'images dans le tableau
messages.content. - Utilisation de l’outil, résultats et définitions dans le
toolstableau.
Consulter Référence de l’API REST du modèle de base.
TextContent
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's the date today?",
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
ReasonContent
{
"messages": [
{
"role": "assistant",
"content": [
{
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "Thinking...",
"signature": "[optional]"
},
{
"type": "summary_encrypted_text",
"data": "[encrypted text]"
}
]
}
]
}
]
}
ImageContent
Le contenu du message image doit utiliser les données encodées comme source. Les URL ne sont pas prises en charge.
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,[content]"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
ToolCallContent
{
"messages": [
{
"role": "assistant",
"content": "Ok, let’s get the weather in New York.",
"tool_calls": [
{
"type": "function",
"id": "123",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"New York, NY\"}"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
Note
L’API REST Databricks est compatible OpenAI et diffère de l’API anthropice. Ces différences ont également un impact sur les objets de réponse comme suit :
- La sortie est renvoyée dans le champ
choices. - Format de segment de diffusion en continu. Tous les blocs suivent le même format, dans lequel
choicescontient la réponsedeltaet l’utilisation est retournée dans chaque bloc. - La raison d’arrêt est retournée dans le
finish_reasonchamp.- Utilisations anthropices :
end_turn,stop_sequence,max_tokens, ettool_use - Respectivement, Databricks utilise :
stop,stop,length, ettool_calls
- Utilisations anthropices :
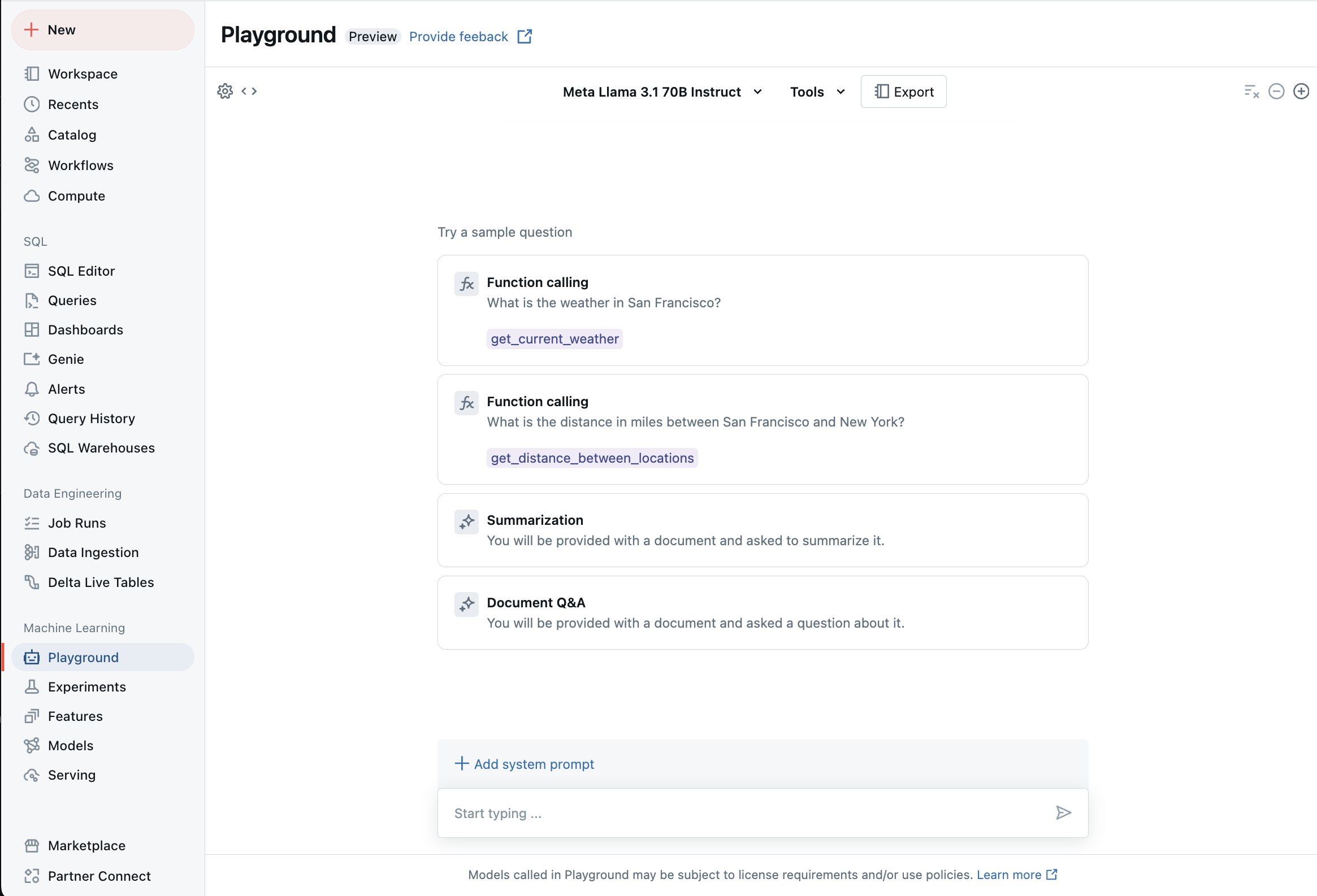
Conversation avec des LLM pris en charge en utilisant AI Playground
Vous pouvez interagir avec des grands modèles de langage pris en charge en utilisant AI Playground. Le terrain de jeu de l’IA est un environnement de type conversation dans lequel vous pouvez tester, inviter et comparer des LLM à partir de votre espace de travail Azure Databricks.
Ressources supplémentaires
- Surveiller les modèles servis à l’aide des tables d’inférence compatibles avec Unity AI Gateway
- Déployer des pipelines d’inférence par lots
- APIs des modèles Foundation de Databricks
- Modèles externes dans le service de modèles Mosaic AI
- Tutoriel : Créer des points de terminaison de modèle externe pour interroger des modèles OpenAI
- Modèles de base hébergés par Databricks disponibles dans les API Foundation Model
- Référence de l’API REST Foundation Model