Préparer la migration d’exécution de test
Cet article se concentre sur la préparation de l’équipe et la génération de fichiers requises par l’outil de migration de données.

Prérequis
Terminez la phase De validation avant de commencer à préparer la migration d’exécution de test.
Générer des paramètres de migration
Procédez comme suit pour générer la spécification de migration et les fichiers associés pour mettre en file d’attente la migration de votre base de données de collection.
Exécutez la commande préparer l’outil de migration de données avec les paramètres suivants :
/collection:http://localhost:8080/tfs/DefaultCollection/ tenantDomainName:contoso.com /Region:CUS- L’option nom de domaine du locataire est le nom du locataire Microsoft Entra ID de votre entreprise.
- La commande de préparation nécessite un accès à Internet. Si votre serveur Azure DevOps ne dispose pas d’une connectivité Internet, exécutez la commande à partir d’un autre ordinateur.
- Le terme « région d’organisation » fait référence à l’emplacement où vous envisagez de migrer votre collection vers Azure DevOps Services. Vous avez précédemment sélectionné une région et enregistré son code abrégé. Utilisez ce code dans la commande de préparation.
Connectez-vous à l’aide d’un utilisateur du locataire autorisé à lire des informations sur tous les utilisateurs du locataire Microsoft Entra ID.
Configurer le fichier de spécification de migration
Le fichier de spécification de migration est un fichier JSON qui indique à l’outil de migration de données comment effectuer les actions suivantes.
- Configurer votre organisation migrée
- Spécifier les emplacements sources
- Personnaliser la migration
La plupart des champs sont renseignés automatiquement pendant l’étape de préparation, mais vous devez configurer les champs suivants :
- Nom de l’organisation : nom de l’organisation que vous souhaitez créer pour la migration de vos données.
- Emplacement : sauvegarde de vos fichiers de base de données et de migration à charger dans un conteneur de stockage Azure. Ce champ spécifie la clé SAP utilisée par l’outil de migration pour se connecter et lire en toute sécurité les fichiers sources à partir du conteneur de stockage Azure. La création du conteneur de stockage est couverte plus tard dans la phase 5 et la génération d’une clé SAP est couverte à la phase 6 avant de mettre en file d’attente une nouvelle migration.
- DACPAC : fichier qui empaquette la base de données SQL de votre collection.
- Type de migration : type de migration : exécution de test ou exécution de production.
Chaque fichier de spécification de migration est destiné à une collection unique. Si vous essayez d’utiliser un fichier de spécification de migration généré pour une autre collection, la migration ne démarre pas. Vous devez préparer une exécution de test pour chaque collection que vous souhaitez migrer et utiliser le fichier de spécification de migration généré pour mettre en file d’attente la migration.
Passer en revue le fichier journal de mappage d’identité
Le journal des cartes d’identité est crucial, aussi important que les données réelles que vous migrez. Lorsque vous examinez le fichier journal, comprenez comment les fonctions de migration d’identité et les résultats potentiels. Lorsque vous migrez une identité, elle peut être active ou historique. Les identités actives peuvent se connecter à Azure DevOps Services, tandis que les identités historiques ne peuvent pas. Le service décide du type utilisé.
Remarque
Une fois qu’une identité a été migrée en tant qu’identité historique, il n’existe aucun moyen de la convertir en une identité active.
Identités actives
Les identités actives font référence aux identités utilisateur dans Azure DevOps Services après la migration. Dans Azure DevOps Services, ces identités sont concédées sous licence et sont affichées en tant qu’utilisateurs dans le organization. Les identités sont marquées comme actives dans la colonne État de l’importation attendue dans le fichier journal de mappage d’identité.
Identités historiques
Les identités historiques sont mappées en tant que telles dans la colonne État d’importation attendu du fichier journal de la carte d’identité. Les identités sans entrée de ligne dans le fichier deviennent également historiques. Un employé qui ne travaille plus dans une entreprise peut être un exemple d’identité sans entrée de ligne.
Contrairement aux identités actives, les identités historiques :
- N’avez pas accès à un organization après la migration.
- Vous n’avez pas de licences.
- Ne vous affichez pas en tant qu’utilisateurs dans le organization. Tout ce qui persiste, c’est la notion de nom de cette identité dans le organization, afin que son historique puisse être recherché plus tard. Nous vous recommandons d’utiliser des identités historiques pour les utilisateurs qui ne travaillent plus au sein de l’entreprise ou qui n’ont pas besoin d’un accès supplémentaire à l’organisation.
Remarque
Une fois qu’une identité est migrée comme historique, vous ne pouvez pas la rendre active.
Licences
Pendant la migration, les licences sont attribuées automatiquement pour tous les utilisateurs affichés comme étant « actifs » dans la colonne État d’importation attendue du journal de mappage d’identité. Si l’attribution automatique de licence est incorrecte, vous pouvez la modifier en modifiant le « niveau d’accès » d’un ou plusieurs utilisateurs une fois la migration terminée.
L’affectation n’est peut-être pas toujours parfaite. Vous avez donc jusqu’au premier du mois suivant pour réaffecter les licences si nécessaire. Si, au début du mois suivant, vous ne liez pas d’abonnement à votre organisation et que vous avez acheté le nombre correct de licences, toutes vos licences de période de grâce sont révoquées. Sinon, si l’affectation automatique a attribué plus de licences que vous avez achetées pour le mois suivant, nous ne vous facturons pas pour les licences supplémentaires, mais nous révoquez toutes les licences non payées.
Pour éviter de perdre l’accès, nous vous recommandons de lier un abonnement et d’acheter des licences nécessaires avant le premier du mois, à mesure que la facturation s’exécute mensuellement. Pour toutes les exécutions de test, les licences sont gratuites tant que l’organisation est active.
Abonnements Azure DevOps
Abonnements Visual Studio ne sont pas affectées par défaut pour les migrations. Au lieu de cela, les utilisateurs disposant de Abonnements Visual Studio sont automatiquement mis à niveau pour utiliser cette licence. Si l’organisation professionnelle d’un utilisateur est liée correctement, Azure DevOps Services applique automatiquement ses avantages d’abonnement Visual Studio lors de sa première connexion après la migration.
Vous n’avez pas besoin de répéter une migration d’exécution de test si les utilisateurs ne sont pas automatiquement mis à niveau pour utiliser leur abonnement Visual Studio dans Azure DevOps Services. La liaison d’abonnement Visual Studio est un élément qui se produit en dehors de l’étendue d’une migration. Si l’organisation professionnelle est correctement liée avant ou après la migration, l’utilisateur dispose automatiquement de sa licence mise à niveau lors de la prochaine connexion. Une fois qu’ils sont mis à niveau, la prochaine fois que vous migrez l’utilisateur est automatiquement mis à niveau lors de la connexion initiale à l’organisation.
Restreindre l’accès aux adresses IP Azure DevOps Services uniquement
Limitez l’accès à votre compte Stockage Azure aux adresses IP d’Azure DevOps Services uniquement. Vous pouvez restreindre l’accès en autorisant uniquement les connexions à partir d’adresses IP Azure DevOps Services impliquées dans le processus de migration de base de données de collecte. Les adresses IP qui doivent être autorisées à accéder à votre compte de stockage dépendent de la région vers laquelle vous effectuez la migration.
Option 1 : Utiliser des étiquettes de service
Vous pouvez facilement autoriser les connexions à partir de toutes les régions Azure DevOps Services en ajoutant la azuredevops balise de service à vos groupes de sécurité réseau ou pare-feu via le portail ou par programme.
Option 2 : Utiliser la liste IP
Utilisez la IpList commande pour obtenir la liste des adresses IP qui doivent être accordées pour autoriser les connexions à partir d’une région Azure DevOps Services spécifique.
La documentation d’aide contient des instructions et des exemples d’exécution de Migrator à partir du Azure DevOps Server instance lui-même et d’un ordinateur distant. Si vous exécutez la commande à partir de l’un des niveaux Application de l’Azure DevOps Server instance, votre commande doit avoir la structure suivante :
Migrator IpList /collection:{CollectionURI} /tenantDomainName:{name} /region:{region}
Vous pouvez ajouter la liste des adresses IP à vos groupes de sécurité réseau ou pare-feu via le portail ou par programme.
Configurer des exceptions de pare-feu IP pour SQL Azure
Cette section s’applique uniquement à la configuration des exceptions de pare-feu pour SQL Azure. Pour les migrations DACPAC, consultez Configurer Stockage Azure pare-feu et réseaux virtuels.
L’outil de migration de données nécessite que les adresses IP Azure DevOps Services soient configurées pour les connexions entrantes uniquement sur le port 1433.
Procédez comme suit pour accorder des exceptions pour les adresses IP nécessaires gérées au niveau de la couche réseau Azure pour votre machine virtuelle SQL Azure.
- Connectez-vous au portail Azure.
- Accédez à votre machine virtuelle SQL Azure.
- Sous Paramètres, sélectionnez Mise en réseau.
- Sélectionnez Ajouter une règle de port d’entrée.

- Sélectionnez Avancé pour configurer une règle de port de trafic entrant pour une adresse IP spécifique.
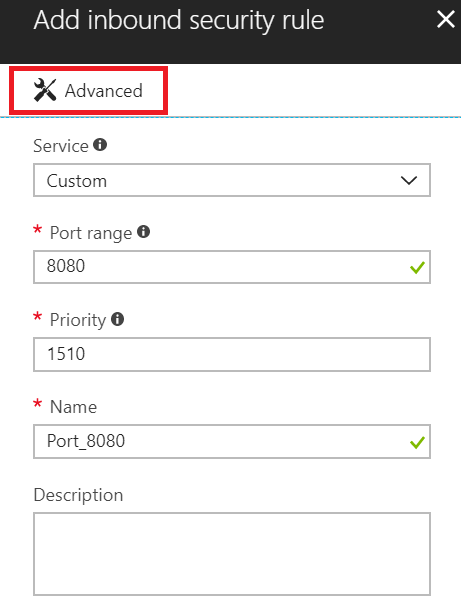
- Dans la liste déroulante Source , sélectionnez Adresses IP, entrez une adresse IP qui doit être accordée à une exception, définissez la plage de ports de destination et
1433, dans la zone Nom , entrez un nom qui décrit le mieux l’exception que vous configurez.
En fonction d’autres règles de port entrant configurées, vous devrez peut-être modifier la priorité par défaut pour les exceptions Azure DevOps Services afin qu’elles ne soient pas ignorées. Par exemple, si vous avez une règle « Refuser sur toutes les connexions entrantes à 1433 » avec une priorité supérieure à vos exceptions Azure DevOps Services, l’outil de migration de données peut ne pas pouvoir établir une connexion réussie à votre base de données.
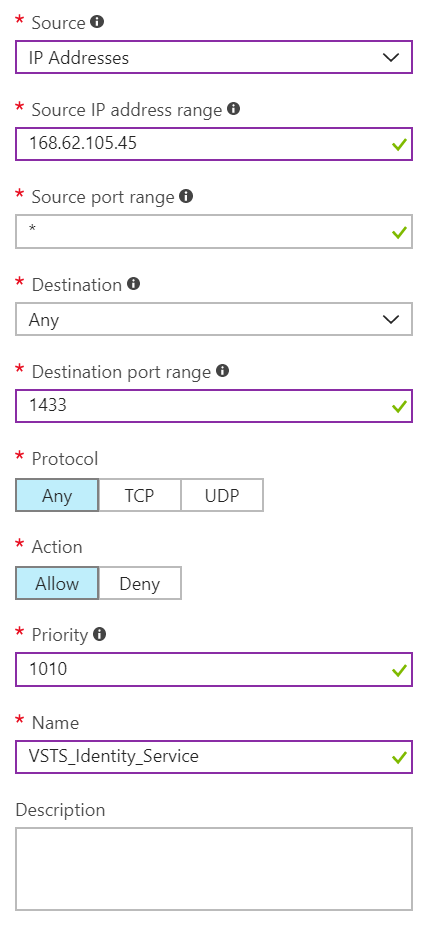
Répétez l’ajout de règles de port entrant jusqu’à ce que toutes les adresses IP Azure DevOps Services nécessaires soient accordées à une exception. L’absence d’une adresse IP peut entraîner l’échec du démarrage de votre migration.
Migrer des collections volumineuses
Pour les bases de données que l’outil de migration de données avertit sont trop volumineuses, une approche différente de l’empaquetage des données est nécessaire pour migrer vers Azure DevOps Services. Si vous ne savez pas si votre collection dépasse le seuil de taille, vous devez exécuter une validation de l’outil de migration de données sur la collection. La validation vous permet de savoir si vous devez utiliser la méthode de machine virtuelle SQL Azure pour la migration.
Déterminer si vous pouvez réduire la taille de la collection
Vérifiez si vous pouvez nettoyer les anciennes données. Au fil du temps, les regroupements peuvent générer de grands volumes de données. Cette croissance est une partie naturelle du processus DevOps, mais vous n’avez peut-être pas besoin de conserver toutes les données. Certains exemples courants de données non pertinentes sont les espaces de travail plus anciens et les résultats de génération.
L’outil de migration de données analyse votre collection et le compare aux limites mentionnées précédemment. Il indique ensuite si votre collection est éligible à la méthode de migration DACPAC ou SQL. En général, l’idée est que si votre collection est suffisamment petite pour s’adapter aux limites DACPAC, vous pouvez utiliser l’approche DACPAC plus rapide et plus simple. Toutefois, si votre collection est trop volumineuse, vous devez utiliser la méthode de migration SQL, ce qui implique la configuration d’une machine virtuelle SQL Azure et la migration manuelle de la base de données.
Limites de tailles
Les limites actuelles sont :
- Taille totale de la base de données de 150 Go (métadonnées de base de données + objets blob) pour DACPAC, si vous dépassez cette limite, vous devez effectuer la méthode de migration SQL.
- Taille de table individuelle de 30 Go (métadonnées de base de données + objets blob) pour DACPAC, si une table unique dépasse cette limite, vous devez effectuer la méthode de migration SQL.
- Taille des métadonnées de base de données de 1 536 Go pour la méthode de migration SQL. Le dépassement de cette limite émet un avertissement, nous vous conseillons de conserver sous cette taille pour avoir une migration réussie.
- Taille des métadonnées de base de données de 2 048 Go pour la méthode de migration SQL. Le dépassement de cette limite entraîne une erreur. Vous ne pouvez donc pas effectuer de migration.
- Aucune limite pour les tailles d’objets blob pour la méthode de migration SQL.
Lorsque vous nettoyez des artefacts plus anciens et non pertinents, il peut supprimer beaucoup plus d’espace que prévu, et il peut déterminer si vous utilisez la méthode de migration DACPAC ou une machine virtuelle SQL Azure.
Important
Une fois que vous avez supprimé des données plus anciennes, vous ne pouvez pas la récupérer, sauf si vous restaurez une sauvegarde antérieure de la collection.
Si vous êtes sous le seuil DACPAC, suivez les instructions pour générer un DACPAC pour la migration. Si vous ne pouvez toujours pas obtenir la base de données sous le seuil DACPAC, vous devez configurer une machine virtuelle AZURE SQL pour migrer vers Azure DevOps Services.
Configurer une machine virtuelle SQL Azure pour migrer vers Azure DevOps Services
Procédez comme suit pour configurer une machine virtuelle SQL Azure à migrer vers Azure DevOps Services.
- Configurer une machine virtuelle SQL Azure
- Configurer des exceptions de pare-feu IP
- Restaurer votre base de données sur la machine virtuelle
- [Configurer votre collection pour la migration
- Configurer le fichier de spécification de migration pour cibler la machine virtuelle
Configurer une machine virtuelle SQL Azure
Vous pouvez configurer rapidement une machine virtuelle SQL Azure à partir du Portail Azure. Pour plus d’informations, consultez Utiliser le Portail Azure pour approvisionner une machine virtuelle Windows avec SQL Server.
Les performances de votre machine virtuelle SQL Azure et des disques de données attachés ont un impact significatif sur les performances de la migration. Pour cette raison, nous vous recommandons vivement d’effectuer les tâches suivantes :
- Sélectionnez une taille de machine virtuelle au niveau supérieur
D8s_v5_*ou supérieur. - Utiliser des disques managés.
- Consultez les performances des machines virtuelles et des disques. Vérifiez que votre infrastructure est configurée afin que les E/S par seconde de la machine virtuelle (entrée/sortie) et les E/S par seconde de stockage ne deviennent pas un goulot d’étranglement sur les performances de la migration. Par exemple, vérifiez que le nombre de disques de données attachés à votre machine virtuelle est suffisant pour prendre en charge les E/S par seconde de la machine virtuelle.
Azure DevOps Services est disponible dans plusieurs régions Azure dans le monde entier. Pour vous assurer que la migration démarre correctement, il est essentiel de placer vos données dans la région appropriée. Si vous configurez votre machine virtuelle SQL Azure à un emplacement incorrect, la migration ne démarre pas.
Important
La machine virtuelle Azure nécessite une adresse IP publique.
Si vous utilisez cette méthode de migration, créez votre machine virtuelle dans une région prise en charge. Bien qu’Azure DevOps Services soit disponible dans plusieurs régions dans la États-Unis (ÉTATS-Unis), seule la région centre États-Unis accepte de nouvelles organisations. Vous ne pouvez pas migrer vos données vers d’autres régions Azure américaines maintenant.
Remarque
Les clients DACPAC doivent consulter la table de région dans la section « Étape 3 : Charger le fichier DACPAC](migration-test-run.md#) ». Les instructions précédentes concernent uniquement les machines virtuelles SQL Azure. Si vous êtes un client DACPAC, consultez les régions Azure prises en charge pour la migration.
Utilisez les configurations de machine virtuelle SQL Azure suivantes :
- Configurez la base de données temporaire SQL pour utiliser un lecteur autre que le lecteur C. Idéalement, le lecteur doit avoir suffisamment d’espace libre ; au moins équivalent à la plus grande table de votre base de données.
- Si votre base de données source est toujours supérieure à 1 téraoctet (To) après avoir réduit sa taille, vous devez attacher plus de disques de 1 To et les combiner dans une seule partition pour restaurer votre base de données sur la machine virtuelle.
- Si vos bases de données de collection sont de plus de 1 To de taille, envisagez d’utiliser un DISQUE SSD (disques durs ssd) pour la base de données temporaire et la base de données de collecte. Envisagez également d’utiliser des machines virtuelles plus volumineuses avec 16 processeurs virtuels (processeurs virtuels) et 128 Go (gigaoctets) de RAM (mémoire d’accès aléatoire).
Restaurer votre base de données sur la machine virtuelle
Après avoir configuré et configuré une machine virtuelle Azure, vous devez effectuer votre sauvegarde détachée de votre instance de Azure DevOps Server sur votre machine virtuelle Azure. La base de données de collection doit être restaurée sur votre instance SQL et ne nécessite pas l’installation de Azure DevOps Server sur la machine virtuelle.
Configurer votre collection pour la migration
Une fois votre base de données de collecte rétablie sur votre machine virtuelle Azure, configurez une connexion SQL pour permettre à Azure DevOps Services de se connecter à la base de données pour migrer les données. Cette connexion autorise uniquement l’accès en lecture à une base de données unique.
Ouvrez SQL Server Management Studio sur la machine virtuelle, puis ouvrez une nouvelle fenêtre de requête sur la base de données à migrer.
Définissez la récupération de la base de données sur simple :
ALTER DATABASE [<Database name>] SET RECOVERY SIMPLE;Créez une connexion SQL pour la base de données et affectez cette connexion à « TFSEXECROLE », comme dans l’exemple suivant.
USE [<database name>] CREATE LOGIN <pick a username> WITH PASSWORD = '<pick a password>' CREATE USER <username> FOR LOGIN <username> WITH DEFAULT_SCHEMA=[dbo] EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='<username>'
Consultez l’exemple suivant de la commande SQL :
ALTER DATABASE [Foo] SET RECOVERY SIMPLE;
USE [Foo]
CREATE LOGIN fabrikam WITH PASSWORD = 'fabrikampassword'
CREATE USER fabrikam FOR LOGIN fabrikam WITH DEFAULT_SCHEMA=[dbo]
EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='fabrikam'
Important
Activez SQL Server et Authentification Windows mode dans SQL Server Management Studio sur la machine virtuelle. Si vous n’activez pas le mode d’authentification, la migration échoue.
Configurer le fichier de spécification de migration pour cibler la machine virtuelle
Mettez à jour le fichier de spécification de migration pour inclure des informations sur la connexion à l’instance SQL Server. Ouvrez votre fichier de spécification de migration et effectuez les mises à jour suivantes :
Supprimez le paramètre DACPAC de l’objet fichiers sources. La spécification de migration avant la modification ressemble à l’exemple de code suivant.

La spécification de migration après la modification ressemble à l’exemple de code suivant.

Entrez les paramètres requis et ajoutez l’objet de propriétés suivant dans votre objet source dans le fichier de spécification.
"Properties": { "ConnectionString": "Data Source={SQL Azure VM Public IP};Initial Catalog={Database Name};Integrated Security=False;User ID={SQL Login Username};Password={SQL Login Password};Encrypt=True;TrustServerCertificate=True" }
Après avoir appliqué les modifications, la spécification de migration ressemble à l’exemple suivant.
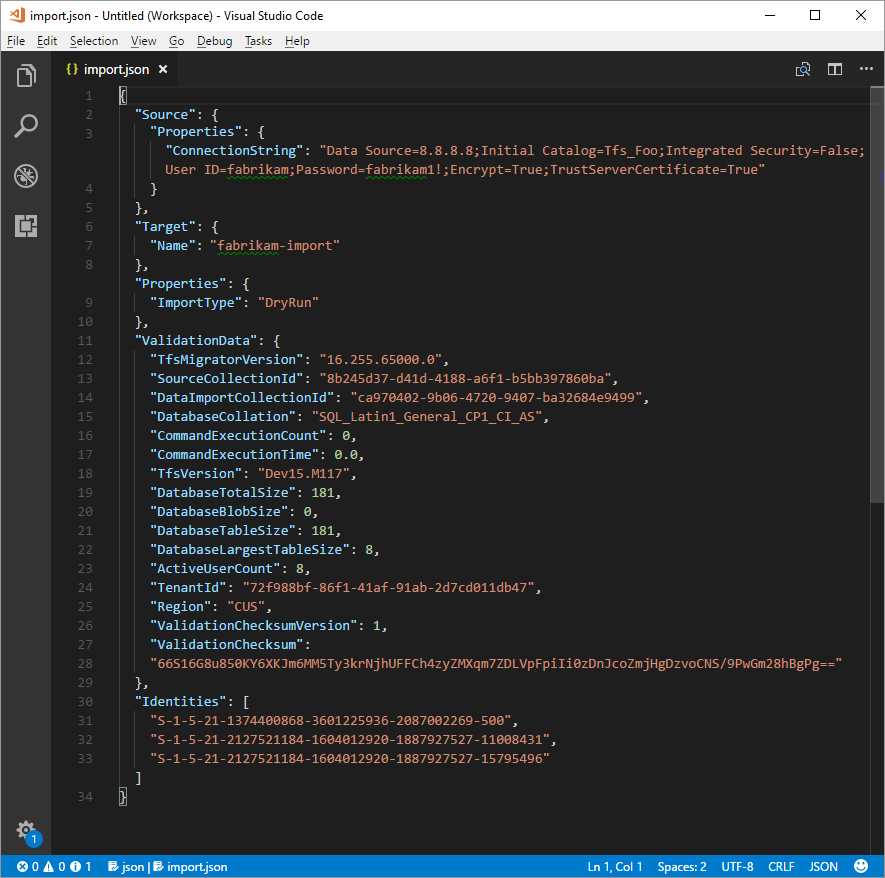
Votre spécification de migration est maintenant configurée pour utiliser une machine virtuelle SQL Azure pour la migration. Passez au reste des étapes de préparation pour la migration. Une fois la migration terminée, veillez à supprimer la connexion SQL ou à faire pivoter le mot de passe. Microsoft ne conserve pas les informations de connexion une fois la migration terminée.
Créer un conteneur Stockage Azure dans le centre de données choisi
L’utilisation de l’outil de migration de données pour Azure DevOps nécessite d’avoir un conteneur Stockage Azure dans le même centre de données Azure que la dernière organisation Azure DevOps Services. Par exemple, si vous envisagez de créer votre organisation Azure DevOps Services dans le centre de données central États-Unis, créez le conteneur Stockage Azure dans ce même centre de données. Cette action accélère considérablement le temps nécessaire pour migrer la base de données SQL, car le transfert se produit dans le même centre de données.
Pour plus d’informations, consultez la rubrique Création d’un compte de stockage.
Configurer la facturation
Une période de grâce est placée sur l’organisation Azure DevOps Services nouvellement migrée pour permettre à votre équipe de terminer les étapes dont elle a besoin et de corriger les attributions de licence. Si vous prévoyez que vous souhaiterez peut-être acheter d’autres plans utilisateur, de build ou de pipelines de déploiement, de services de build hébergés, de services de test de charge hébergés, par exemple, nous vous recommandons vivement de disposer d’un abonnement Azure prêt à être lié à votre organisation migrée. La période de grâce se termine le premier jour du mois suivant après avoir terminé votre migration.
Nous vous rappelons à nouveau dans la phase de post-migration(lien) lorsque vous devez effectuer la liaison. Cette étape de préparation consiste à vous assurer que vous connaissez l’abonnement Azure que vous utilisez dans cette étape ultérieure. Pour plus d’informations, consultez Configurer la facturation pour votre organisation.