Créer une branche de façon stratégique
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2019
Le code source est une ressource importante dans votre travail de développement. Il peut cependant être difficile de gérer et de faire évoluer efficacement les fichiers sources quand plusieurs développeurs travaillent simultanément sur les mises à jour des fichiers. Vous pouvez utiliser un système de contrôle de version pour stocker le code source dans des référentiels partagés, de façon à isoler le travail de développement effectué en parallèle, à intégrer les modifications du code et à récupérer les versions antérieures des fichiers. Dans le contrôle de version, la création de branches constitue un élément clé, car elle permet les développements simultanés. Si vous créez des branches de façon stratégique, vous pouvez maintenir l'ordre et la cohérence de plusieurs versions de votre logiciel.
Team Foundation fournit un système de contrôle de version flexible et fiable. Vous pouvez utiliser la gestion de version Team Foundation pour gérer plusieurs révisions au cours du développement du code source, des documents, des éléments de travail et d’autres informations critiques traitées par votre équipe.
Comment votre équipe gère-t-elle le code tout en introduisant plusieurs modifications simultanément dans plusieurs versions d'un projet ?
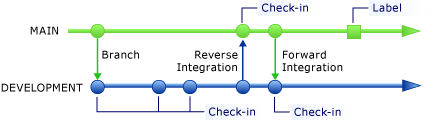
Quand vous travaillez avec un système de contrôle de version, vous devez considérer comment configurer une structure de branches. Vous pouvez créer une branche en créant une copie miroir du fichier de code source. Vous pouvez ensuite modifier la branche sans affecter la source. Par exemple, comme le montre la structure de branches de l'illustration suivante, la branche PRINCIPALE contient des fonctionnalités terminées qui ont réussi les tests d'intégration, tandis que la branche DÉVELOPPEMENT contient le code qui est en cours d'élaboration. Quand une nouvelle fonctionnalité de la branche DÉVELOPPEMENT est terminée et est à même de réussir les tests d’intégration, vous pouvez promouvoir le code de la branche DÉVELOPPEMENT vers la branche PRINCIPALE. Ce processus est connu sous le nom d'intégration inverse. À l’opposé, si vous fusionnez le code de la branche PRINCIPALE dans la branche DÉVELOPPEMENT, le processus est connu sous le nom d’intégration en amont.
Pour plus d’informations sur la création et la fusion de branches de code, consultez la page suivante sur le site web CodePlex : Guide de la création de branches dans Team Foundation Server 2.0.
La création et la fusion de branches impliquent les principes suivants :
Chaque branche doit avoir une stratégie définie quant à la façon d'y intégrer du code. Par exemple, dans la structure de branches de l’illustration précédente, vous pouvez affecter un membre de l’équipe en tant que propriétaire et gestionnaire de la branche PRINCIPALE. Ce membre est chargé d’effectuer l’opération initiale de création d’une branche, de l’intégration inverse des modifications de la branche DÉVELOPPEMENT vers la branche PRINCIPALE et de l’intégration en amont des modifications de la branche PRINCIPALE vers la branche DÉVELOPPEMENT. L’intégration en amont est importante quand la branche PRINCIPALE intègre également des modifications provenant d’autres branches.
La branche PRINCIPALE doit contenir du code qui a réussi les tests d’intégration, de façon à ce qu’il soit toujours prêt pour une version.
La branche DÉVELOPPEMENT (ou de travail) évolue en permanence, car les membres de l'équipe y archivent régulièrement des modifications.
Les étiquettes sont des instantanés des fichiers d'une branche à un moment donné.
Pour plus d’informations, consultez Utiliser des étiquettes pour prendre un instantané de vos fichiers.
Team Foundation Build vous permet de choisir parmi plusieurs types de builds pour vos branches : manuelle, en continu, contrôlée, enchaînée et planifiée. Nous recommandons que la branche PRINCIPALE ait un type de build d'archivage contrôlé. Cela signifie que la branche DÉVELOPPEMENT doit satisfaire à toutes les exigences de la branche PRINCIPALE pour que vous puissiez valider une intégration inverse. La branche DÉVELOPPEMENT doit avoir un type de build en continu, car votre équipe doit être informée dès que possible quand un nouvel archivage affecte la branche DÉVELOPPEMENT.
À quelle fréquence votre équipe doit-elle effectuer les intégrations inverses et les intégrations en amont ?
Comme le montre l'illustration suivante, l'intégration inverse et l'intégration en amont doivent se produire au moins quand vous terminez un récit utilisateur. Bien que chaque équipe puisse définir différemment la notion de complétude, la fin d’un récit utilisateur signifie généralement que vous avez terminé à la fois les fonctionnalités et les tests unitaires correspondants. Vous pouvez effectuer une intégration inverse vers la branche PRINCIPALE seulement après que les tests unitaires ont vérifié la stabilité de la branche DÉVELOPPEMENT.
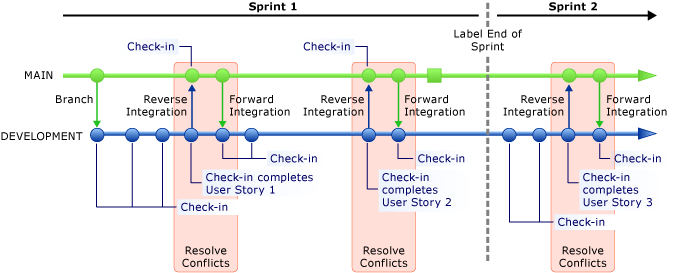
Si vous avez plusieurs branches de travail (DÉVELOPPEMENT), l’intégration en amont vers toutes les branches de travail doit être effectuée dès qu’une branche est intégrée dans la branche PRINCIPALE. Comme la branche PRINCIPALE reste stable, l’intégration en amont est une opération sûre. Des conflits ou des échecs au niveau des branches de travail peuvent se produire, car vous ne pouvez pas garantir que les branches de travail sont stables.
Il est important de résoudre tous les conflits dès que possible. En utilisant un archivage contrôlé pour la branche PRINCIPALE, vous facilitez grandement l’intégration inverse, car les contrôles de qualité permettent d’éviter les conflits ou les erreurs dans la branche PRINCIPALE. Pour plus d’informations, consultez Archiver dans un dossier contrôlé par un processus de création d’archivage contrôlé.
Comment votre équipe gère-t-elle les sources qui implémentent des récits utilisateur différents ?
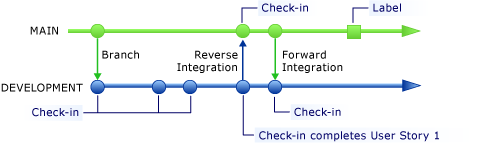
Comme le montre l’illustration suivante, vous pouvez archiver régulièrement les modifications apportées à une branche de travail pour réaliser un récit utilisateur. Vous pouvez implémenter plusieurs récits utilisateur dans la même branche en même temps. Cependant, vous pouvez effectuer une intégration inverse dans la branche PRINCIPALE seulement après avoir achevé tout le travail en cours. Il est recommandé de regrouper les récits utilisateur par taille similaire, car il n'est pas souhaitable qu'un grand récit utilisateur bloque l'intégration de plusieurs petits récits. Vous pouvez diviser les deux ensembles de récits utilisateur en deux branches.
Quand l’équipe doit-elle ajouter une branche ?
Vous devez créer des branches dans les situations suivantes :
Quand vous devez publier du code selon une planification ou un cycle différent de celui des branches existantes.
Quand votre code requiert une stratégie de branche différente. Si vous créez une nouvelle branche avec la nouvelle stratégie, vous pouvez ajouter une valeur stratégique à votre projet.
Quand des fonctionnalités sont publiées auprès d'un client et que votre équipe prévoit d'apporter des modifications qui n'affectent pas le cycle de publication planifié.
Vous ne devez pas créer une branche pour chaque récit utilisateur, car cela génère des coûts d’intégration élevés. Bien que TFCV rende facile la création de branches, la charge engendrée par la gestion des branches peut devenir importante si vous avez beaucoup de branches.
Comment l’équipe gère-t-elle les versions publiées du point de vue du contrôle de version ?
Votre équipe doit être en mesure de publier le code à la fin de chaque sprint. À l’aide de Team Foundation Server, vous pouvez étiqueter une branche pour prendre un instantané du code à un moment donné. Comme le montre l'illustration suivante, vous pouvez étiqueter la branche PRINCIPALE pour une publication. Ceci vous permet de rétablir la branche à l’état correspondant à ce moment spécifique.
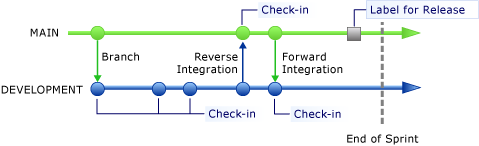
Comme vous devez implémenter des mises à jour sur les mises en production, la création d’une branche pour une mise en production permet à votre équipe de continuer à travailler indépendamment sur le sprint suivant sans créer de conflits avec les mises en productions ultérieures. L'illustration suivante montre une branche qui contient du code pour une mise à jour et qui fait l'objet d'une intégration inverse dans la branche PRINCIPALE après une version publiée à la fin du deuxième sprint.
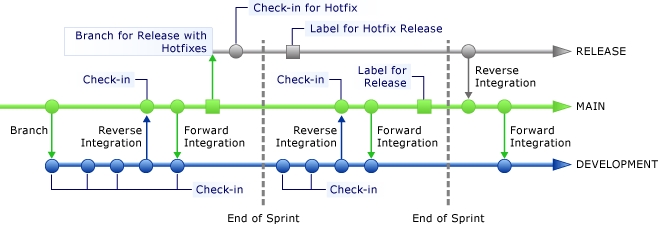
Quand vous créez une branche pour une version publiée, vous devez la créer à partir de la branche PRINCIPALE, qui est la plus stable. Si vous créez une branche pour une version à partir d’une branche de travail, cela peut provoquer des difficultés d’intégration, car la stabilité des branches de travail n’est pas garantie.