Tutoriel : Utiliser Apache Spark Structured Streaming avec Apache Kafka sur HDInsight
Ce tutoriel montre comment utiliser Apache Spark Structured Streaming pour lire et écrire des données avec Apache Kafka sur Azure HDInsight.
Spark Structured Streaming est un moteur de traitement de flux basé sur Spark SQL. Il vous permet d’exprimer des calculs de diffusion en continu de la même façon que pour les calculs de lot sur les données statiques.
Dans ce tutoriel, vous allez apprendre à :
- Utilisez un modèle Azure Resource Manager pour créer des clusters.
- Utiliser Spark Structured Streaming avec Kafka
Quand vous avez terminé les étapes décrites dans ce document, n’oubliez pas de supprimer les clusters pour éviter des frais supplémentaires.
Prérequis
jq, processeur JSON en ligne de commande. Consultez https://stedolan.github.io/jq/.
Connaissances sur l’utilisation des blocs-notes Jupyter Notebook avec Spark sur HDInsight. Pour plus d’informations, consultez le document Charger des données et exécuter des requêtes sur un cluster Apache Spark dans Azure HDInsight.
Connaissance du langage de programmation Scala. Le code utilisé dans ce didacticiel est écrit dans Scala.
Connaissances sur la création des rubriques Kafka. Pour plus d’informations, consultez le document Démarrage rapide : Créer un cluster Apache Kafka sur HDInsight.
Important
Les étapes décrites dans ce document nécessitent un groupe de ressources Azure contenant à la fois un Spark sur HDInsight et un Kafka sur un cluster HDInsight. Ces clusters sont tous deux situés dans un réseau virtuel Azure, ce qui permet au cluster Spark de communiquer directement avec le cluster Kafka.
Pour des raisons pratiques, ce document renvoie à un modèle permettant de créer toutes les ressources Azure requises.
Pour plus d’informations sur l’utilisation de HDInsight dans un réseau virtuel, consultez le document Planifier un réseau virtuel pour HDInsight.
Structured Streaming avec Apache Kafka
Spark Structured Streaming est un moteur de traitement de flux basé sur le moteur Spark SQL. Lorsque vous utilisez Structured Streaming, vous pouvez écrire les requêtes de streaming de la même façon que vous écrivez les requêtes par lots.
Les extraits de code suivants illustrent la lecture à partir de Kafka et le stockage dans le fichier. Le premier est une opération de traitement par lot, tandis que le second est une opération de diffusion en continu :
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
Dans les deux extraits de code, les données sont lues à partir de Kafka et écrites dans le fichier. Voici les différences qui séparent les exemples :
| Batch | Diffusion en continu |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
L’opération de streaming utilise également awaitTermination(30000), ce qui bloque le flux après 30 000 ms.
Pour utiliser Structured Streaming avec Kafka, votre projet doit avoir une dépendance sur le package org.apache.spark : spark-sql-kafka-0-10_2.11. La version de ce package doit correspondre à la version de Spark sur HDInsight. Pour Spark 2.4 (disponible dans HDInsight 4.0), vous trouverez les informations sur les dépendances pour différents types de projet dans https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Pour le notebook Jupyter qui est utilisé dans ce tutoriel, la cellule suivante charge cette dépendance de package :
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Création des clusters
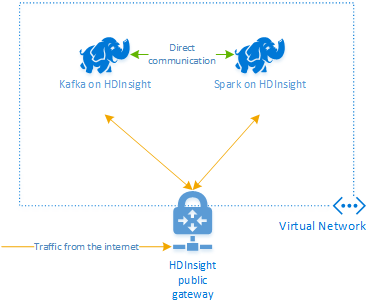
Apache Kafka sur HDInsight ne donne pas accès aux répartiteurs Kafka sur l’Internet public. Tout ce qui utilise Kafka doit se trouver sur le même réseau virtuel Azure. Dans ce didacticiel, les clusters Kafka et Spark se trouvent dans le même réseau virtuel Azure.
Le diagramme suivant illustre les flux de communication entre Spark et Kafka :
Remarque
Le service Kafka est limité à la communication au sein du réseau virtuel. L’accès aux autres services sur le cluster, tels que SSH et Ambari, se fait via Internet. Pour plus d’informations sur les ports publics disponibles avec HDInsight, consultez Ports et URI utilisés par HDInsight.
Pour créer un réseau virtuel Azure puis les clusters Kafka et Spark qu’il contient, procédez comme suit :
Utilisez le bouton suivant pour vous connecter à Azure et ouvrir le modèle dans le portail Azure.

Le modèle Azure Resource Manager se trouve dans https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json .
Ce modèle crée les ressources suivantes :
Un cluster Kafka sur HDInsight 4.0 ou 5.0.
Un cluster Spark 2.4 ou 3.1 sur HDInsight 4.0 ou 5.0.
Un réseau virtuel Azure, qui contient les clusters HDInsight.
Important
Le notebook de streaming structuré utilisé dans ce tutoriel nécessite Spark 2.4 ou 3.1 sur HDInsight 4.0 ou 5.0. Si vous utilisez une version antérieure de Spark sur HDInsight, vous recevez des erreurs lors de l’utilisation du bloc-notes.
Utilisez les informations suivantes pour renseigner les entrées dans la section Modèle personnalisé :
Paramètre Valeur Abonnement Votre abonnement Azure Resource group Le groupe de ressources qui contient les ressources. Emplacement La région Azure dans laquelle sont créées les ressources. Nom du cluster Spark Le nom du cluster Spark. Les six premiers caractères doivent être différents du nom de cluster Kafka. Nom du cluster Kafka Le nom du cluster Kafka. Les six premiers caractères doivent être différents du nom de cluster Spark. Nom d’utilisateur de connexion au cluster Le nom d’utilisateur administrateur pour l’accès aux clusters. Mot de passe de connexion au cluster Le mot de passe d’utilisateur administrateur pour l’accès aux clusters. Nom d’utilisateur SSH L’utilisateur SSH à créer pour l’accès aux clusters. Mot de passe SSH Le mot de passe de l’utilisateur SSH. 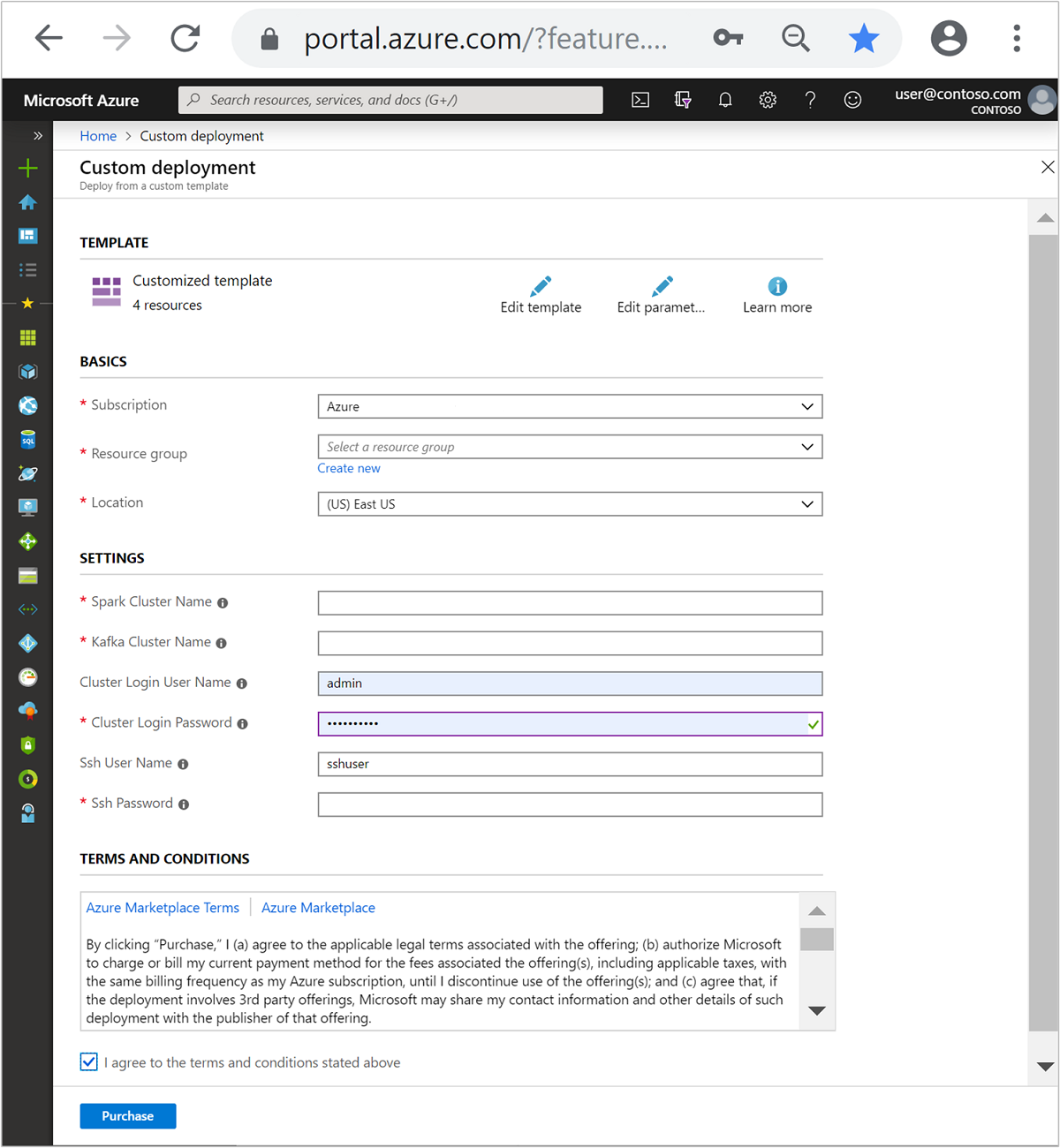
Passez en revue les termes et conditions, puis cochez la case J’accepte les termes et conditions mentionnés ci-dessus.
Sélectionnez Achat.
Notes
La création des clusters peut prendre jusqu’à 20 minutes.
Utiliser Spark Structured Streaming
Cet exemple montre comment utiliser Spark Structured Streaming avec Kafka sur HDInsight Il utilise des données concernant des courses de taxi, qui sont fournies par la ville de New York. Le jeu de données utilisé par ce notebook provient du site 2016 Green Taxi Trip Data.
Collectez les informations concernant l’hôte. Utilisez les commandes curl et jq ci-dessous pour obtenir les informations concernant les hôtes Kafka ZooKeeper et les hôtes de répartiteur. Ces commandes sont conçues pour être utilisées dans une invite de commandes Windows. Pour les autres environnements, de légères différences sont à prévoir. Remplacez
KafkaClusterpar le nom de votre cluster Kafka, et remplacezKafkaPasswordpar le mot de passe de connexion de votre cluster. Ensuite, remplacezC:\HDI\jq-win64.exepar le chemin de votre installation jq. Entrez les commandes dans une invite de commandes Windows, puis enregistrez la sortie en vue de l’utiliser ultérieurement.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/jupyter, oùCLUSTERNAMEest le nom de votre cluster. Lorsque vous y êtes invité, entrez l’identifiant de connexion (admin) et le mot de passe du cluster utilisés lors de la création du cluster.Sélectionnez Nouveau > Spark pour créer un notebook.
Le streaming Spark utilise le microtraitement par lots, ce qui signifie que les données sont fournies sous forme de lots et que des exécuteurs s’exécutent sur les lots de données. Si le délai d’inactivité de l’exécuteur est inférieur au temps nécessaire au traitement du lot, l’exécuteur est constamment ajouté puis supprimé. Si le délai d’inactivité de l’exécuteur est supérieur à la durée du lot, l’exécuteur n’est jamais supprimé. Par conséquent, nous vous recommandons de désactiver l’allocation dynamique en définissant spark.dynamicAllocation.enabled sur false lors de l’exécution d’applications de streaming.
Chargez les packages utilisés par le notebook en entrant les informations suivantes dans une cellule de notebook. Exécutez la commande à l’aide de CTRL + ENTRÉE.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Créez la rubrique Kafka. Modifiez la commande ci-dessous en remplaçant
YOUR_ZOOKEEPER_HOSTSpar les informations sur l’hôte Zookeeper qui ont été extraites lors de la première étape. Entrez la commande modifiée dans votre notebook Jupyter pour créer la rubriquetripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersRécupérez les données concernant les courses de taxi. Entrez la commande dans la cellule suivante pour charger les données sur les courses de taxi de New York. Les données sont chargées dans une trame de données qui est ensuite affichée comme sortie de la cellule.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Définissez les informations concernant les hôtes de répartiteur Kafka. Remplacez
YOUR_KAFKA_BROKER_HOSTSpar les informations concernant les hôtes de répartiteur que vous avez extraites à l’étape 1. Entrez la commande modifiée dans la cellule suivante du notebook Jupyter.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Envoyez les données vers Kafka. Dans la commande suivante, le champ
vendoridest utilisé comme la valeur de clé du message Kafka. La clé est utilisée par Kafka lors du partitionnement des données. Tous les champs sont stockés dans le message Kafka en tant que valeur de chaîne JSON. Entrez la commande suivante dans Jupyter pour enregistrer les données dans Kafka à l’aide d’une requête par lot.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Déclarez un schéma. La commande suivante montre comment utiliser un schéma lorsque vous lisez des données JSON dans Kafka. Entrez la commande dans la cellule Jupyter suivante.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Sélectionnez les données et démarrez le flux de données. La commande suivante montre comment récupérer des données à partir de Kafka à l’aide d’une requête par lots et écrire les résultats dans HDFS, sur le cluster Spark. Dans cet exemple,
selectrécupère le message (champ de valeur) à partir de Kafka et lui applique le schéma. Les données sont ensuite écrites dans HDFS (WASB ou ADL) au format parquet. Entrez la commande dans la cellule Jupyter suivante.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Vous pouvez vérifier que les fichiers ont été créés en entrant la commande dans la cellule Jupyter suivante. Celle-ci affiche la liste des fichiers qui se trouvent dans le répertoire
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataDans l’exemple précédent, nous avons utilisé une requête par lot. La commande suivante montre comment faire la même chose à l’aide d’une requête de streaming. Entrez la commande dans la cellule Jupyter suivante.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Exécutez la cellule suivante pour vérifier que les fichiers ont bien été écrits par la requête de streaming.
%%bash hdfs dfs -ls /example/streamingtripdata
Nettoyer les ressources
Pour supprimer les ressources créées par ce didacticiel, vous pouvez supprimer le groupe de ressources. La suppression du groupe de ressources efface également le cluster HDInsight associé et toutes les autres ressources liées au groupe de ressources.
Pour supprimer le groupe de ressources à l’aide du portail Azure :
- Sur le portail Azure, développez le menu de gauche pour ouvrir le menu des services, puis sélectionnez Groupes de ressources pour voir la liste de vos groupes de ressources.
- Recherchez le groupe de ressources à supprimer, puis faites un clic droit sur le bouton Plus (...) se trouvant à droite de la liste.
- Sélectionnez Supprimer le groupe de ressources et confirmez.
Avertissement
La facturation du cluster HDInsight démarre à la création du cluster et s’arrête à sa suppression. La facturation est effectuée au prorata des minutes écoulées. Par conséquent, vous devez toujours supprimer votre cluster lorsqu’il n’est plus utilisé.
La suppression d’un cluster Kafka sur HDInsight supprime toutes les données stockées dans Kafka.