Utiliser les outils Spark et Hive pour Visual Studio Code
Découvrez comment utiliser les outils Spark et Hive Apache pour Visual Studio Code. Utilisez les outils pour créer et envoyer des travaux Apache Hive de traitement par lots, des requêtes Hive interactives et des scripts PySpark pour Apache Spark. Tout d’abord, nous décrirons comment installer les outils Spark et Hive dans Visual Studio Code. Ensuite, nous verrons comment envoyer des travaux aux outils Spark et Hive.
Les outils Spark et Hive peuvent être installée sur les plateformes prises en charge par Visual Studio Code. Les différentes plateformes ont les prérequis suivants.
Prérequis
Les éléments suivants sont requis pour effectuer les étapes décrites dans cet article :
- Un cluster Azure HDInsight. Pour créer un cluster, consultez Prise en main de HDInsight. Vous pouvez également utiliser un cluster Spark et Hive qui prend en charge un point de terminaison Apache Livy.
- Visual Studio Code.
- Mono. Mono est nécessaire uniquement pour les plateformes Linux et MacOS.
- Un environnement interactif PySpark pour Visual Studio Code.
- Un répertoire local. Cet article utilise
C:\HD\HDexample.
Installer l’extension Spark & Hive Tools
Une fois que vous disposez de tous les éléments prérequis, vous pouvez installer les outils Spark et Hive pour Visual Studio Code en procédant comme suit :
Ouvrez Visual Studio Code.
Dans la barre de menus, accédez à Afficher>Extensions.
Dans la zone de recherche, entrez Spark & Hive.
Sélectionnez Outils Spark et Hive dans les résultats de la recherche, puis sélectionnez Installer :
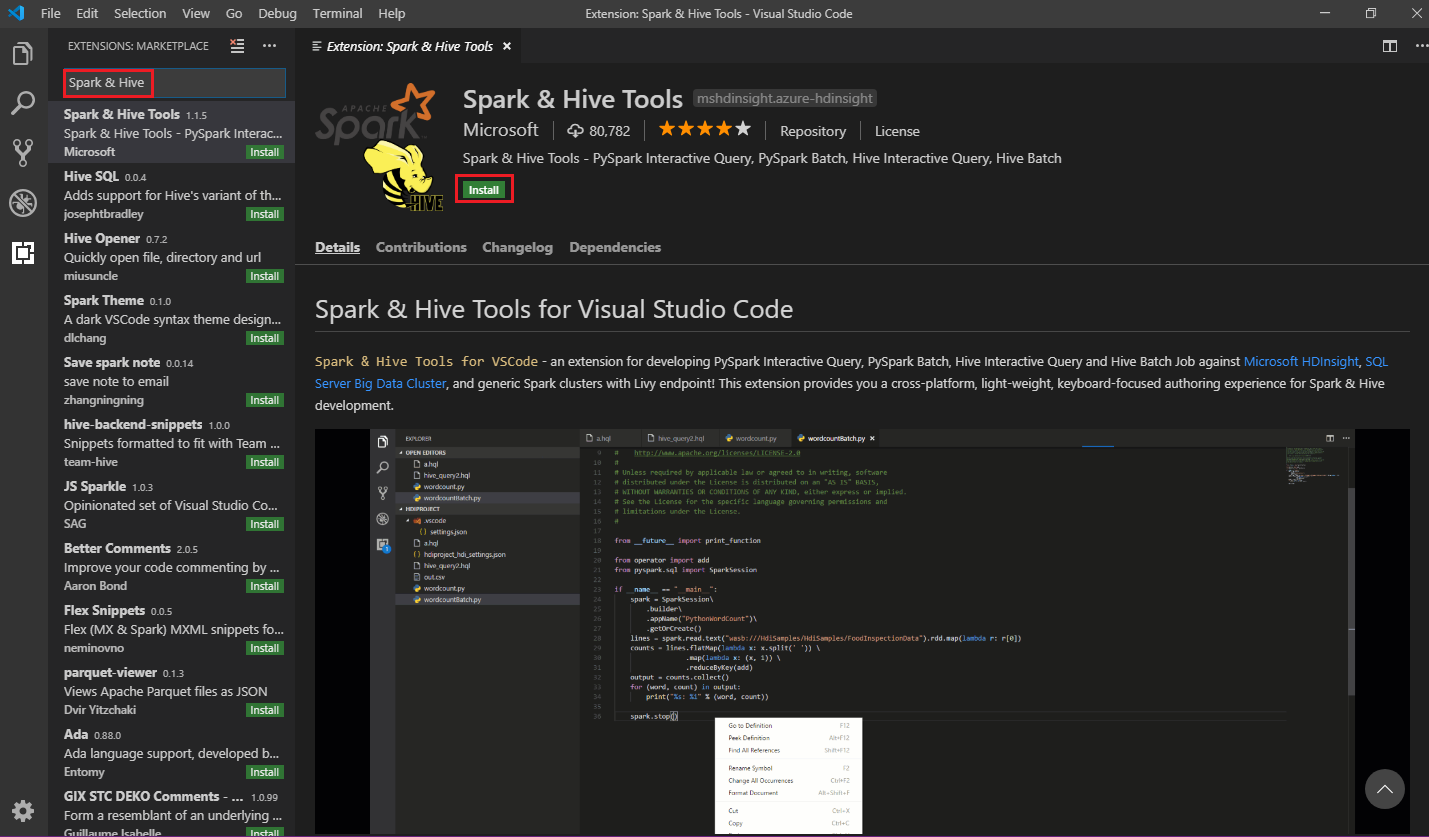
Sélectionnez Recharger si nécessaire.
Ouvrir un dossier de travail
Pour ouvrir un dossier de travail et créer un fichier dans Visual Studio Code, procédez comme suit :
Dans la barre de menus, accédez à Fichier>Ouvrir le dossier...>
C:\HD\HDexample, puis sélectionnez le bouton Sélectionner un dossier. Le dossier s’affiche dans l’affichage Explorateur sur la gauche.Dans Explorateur, sélectionnez le dossier
HDexample, puis sélectionnez l’icône Nouveau fichier en regard du dossier de travail :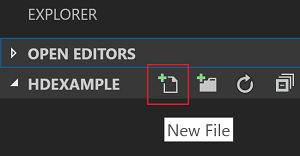
Nommez le nouveau fichier avec l’extension de fichier
.hql(requêtes Hive) ou.py(script Spark). Cet exemple utilise HelloWorld.hql.
Configurer l’environnement Azure
Pour un utilisateur de cloud national, suivez ces étapes pour configurer l’environnement Azure, puis utilisez la commande Azure: Sign In pour vous connecter à Azure :
Accédez à Fichier>Préférences>Paramètres.
Recherchez la chaîne suivante : Azure : Cloud.
Sélectionnez le cloud national dans la liste :
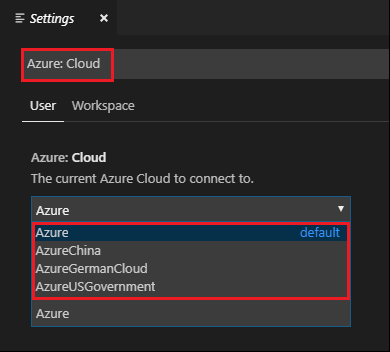
Se connecter à un compte Azure
Pour que vous puissiez envoyer des scripts à vos clusters à partir de Visual Studio Code, l’utilisateur a la possibilité de se connecter à un abonnement Azure ou de lier un cluster HDInsight. Utilisez le nom d’utilisateur/mot de passe Ambari ou les informations d’identification jointes au domaine de votre cluster ESP pour vous connecter à votre cluster HDInsight. Suivez ces étapes pour vous connecter à Azure :
À partir de la barre de menus, accédez à Afficher>Palette de commandes... , puis entrez Azure : Sign In :
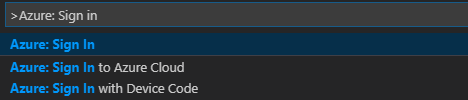
Suivez les instructions de connexion pour vous connecter à Azure. Une fois que vous êtes connecté, le nom de votre compte Azure apparaît dans la barre d’état, en bas de la fenêtre Visual Studio Code.
Lier un cluster
Lien : Azure HDInsight
Vous pouvez lier un cluster normal à l’aide d’un nom d’utilisateur Apache Ambari managé ou lier un cluster de sécurité Hadoop de Pack Sécurité Entreprise à l’aide d’un nom d’utilisateur de domaine (par exemple : user1@contoso.com).
À partir de la barre de menus, accédez à Afficher>Palette de commandes... , puis entrez Spark/Hive : Link a Cluster (Spark / Hive : lier un cluster).

Sélectionnez le type de cluster lié Azure HDInsight.
Entrez l’URL du cluster HDInsight.
Entrez votre nom d’utilisateur Ambari (admin par défaut).
Entrez votre mot de passe Ambari.
Sélectionnez le type de cluster.
Définissez le nom d’affichage du cluster (facultatif).
Examinez l’affichage OUTPUT (SORTIE).
Notes
Le nom d’utilisateur lié et le mot de passe sont utilisés si le cluster est à la fois connecté à l’abonnement Azure et lié à un cluster.
Lien : point de terminaison Livy générique
À partir de la barre de menus, accédez à Afficher>Palette de commandes... , puis entrez Spark/Hive : Link a Cluster (Spark / Hive : lier un cluster).
Sélectionnez le type de cluster lié Generic Livy Endpoint.
Entrez le point de terminaison Livy générique. Par exemple : http://10.172.41.42:18080.
Sélectionnez le type d’autorisation De base ou Aucune. Si vous sélectionnez De base :
Entrez votre nom d’utilisateur Ambari (admin par défaut).
Entrez votre mot de passe Ambari.
Examinez l’affichage OUTPUT (SORTIE).
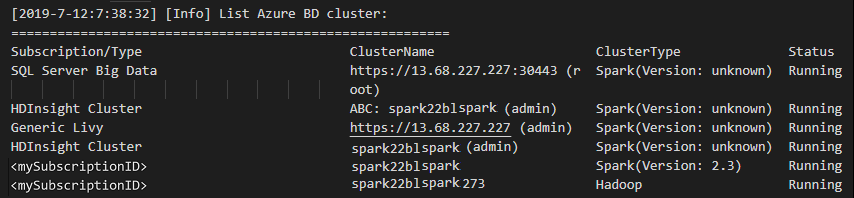
Lister les clusters
À partir de la barre de menus, accédez à Afficher>Palette de commandes... , puis entrez Spark/Hive : List Cluster.
Sélectionnez l’abonnement souhaité.
Examinez l’affichage OUTPUT (SORTIE). Cet affichage montre le ou les clusters liés et tous les clusters de votre abonnement Azure :
Définir le cluster par défaut
Rouvrez le dossier
HDexamplequi a été abordé antérieurement, s’il est fermé.Sélectionnez le fichier HelloWorld.hql créé précédemment. Il s’ouvre dans l’éditeur de script.
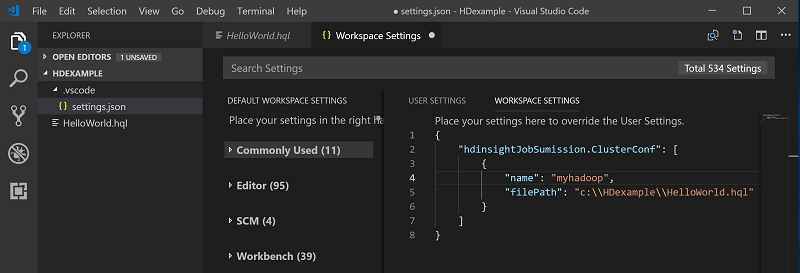
Cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez Spark / Hive: Set Default Cluster (Spark / Hive : définir le cluster par défaut).
Connectez-vous à votre compte Azure ou liez un cluster si ce n’est déjà fait.
Sélectionnez un cluster comme cluster par défaut pour le fichier de script actuel. Les outils mettent automatiquement à jour le fichier de configuration .VSCode\settings.json :
Envoyer des requêtes Hive interactives et des scripts de commandes par lot Hive
Avec les outils Spark et Hive pour Visual Studio Code, vous pouvez envoyer des requêtes Hive interactives et des scripts de commandes par lot Hive à vos clusters.
Rouvrez le dossier
HDexamplequi a été abordé antérieurement, s’il est fermé.Sélectionnez le fichier HelloWorld.hql créé précédemment. Il s’ouvre dans l’éditeur de script.
Copiez le code suivant et collez-le dans votre fichier Hive, puis enregistrez-le :
SELECT * FROM hivesampletable;Connectez-vous à votre compte Azure ou liez un cluster si ce n’est déjà fait.
Cliquez avec le bouton droit sur l’éditeur de script et sélectionnez Hive: Interactive pour envoyer la requête, ou utilisez le raccourci clavier Ctrl+Alt+I. Sélectionnez Hive : Batch pour envoyer le script, ou utilisez le raccourci clavier Ctrl+Alt+H.
Si vous n’avez pas spécifié de cluster par défaut, sélectionnez un cluster. Les outils vous permettent également d’envoyer un bloc de code au lieu du fichier de script entier à partir du menu contextuel. Peu après, les résultats de la requête s’affichent dans un nouvel onglet :
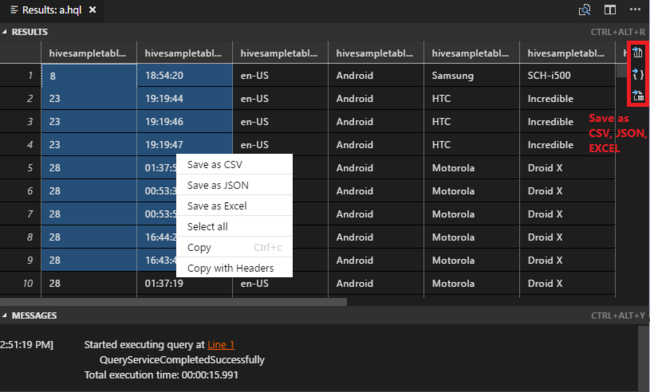
Volet RÉSULTATS : Vous pouvez enregistrer le résultat complet dans un fichier CSV, JSON ou Excel dans un chemin local ou enregistrer seulement certaines lignes du résultat.
Volet MESSAGES : Cliquez sur un numéro de ligne pour accéder à la première ligne du script en cours d’exécution.
Envoyer des requêtes PySpark interactives
Prérequis pour Pyspark interactive
Notez ici que la version de l’extension Jupyter (ms-jupyter) : v2022.1.1001614873 et la version de l’extension Python (ms-python) ! v2021.12.1559732655, python 3.6.x et 3.7.x sont requis pour les requêtes PySpark interactives HDInsight.
Les utilisateurs peuvent exécuter PySpark de manière interactive de plusieurs façons.
Commande interactive PySpark dans le fichier PY
En utilisant la commande interactive PySpark pour envoyer les requêtes, suivez la procédure ci-dessous :
Rouvrez le dossier
HDexamplequi a été abordé antérieurement, s’il est fermé.Créez un fichier HelloWorld.py en suivant les étapes précédentes.
Copiez le code suivant et collez-le dans le fichier de script :
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])L’invite d’installation du noyau PySpark/Synapse Pyspark s’affiche en bas à droite de la fenêtre. Vous pouvez cliquer sur le bouton Installer pour continuer l’installation de PySpark/Synapse Pyspark, ou sur le bouton Ignorer pour ignorer cette étape.
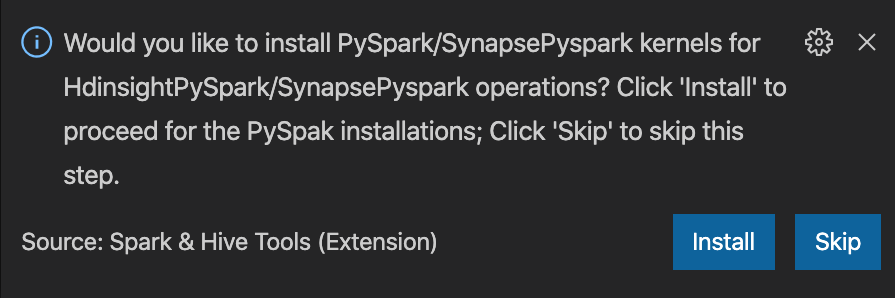
Si vous avez besoin de l’installer ultérieurement, vous pouvez accéder à Fichier>Préférence>Paramètres, puis décocher HDInsight : Activer Ignorer l’installation de PySpark dans les paramètres.
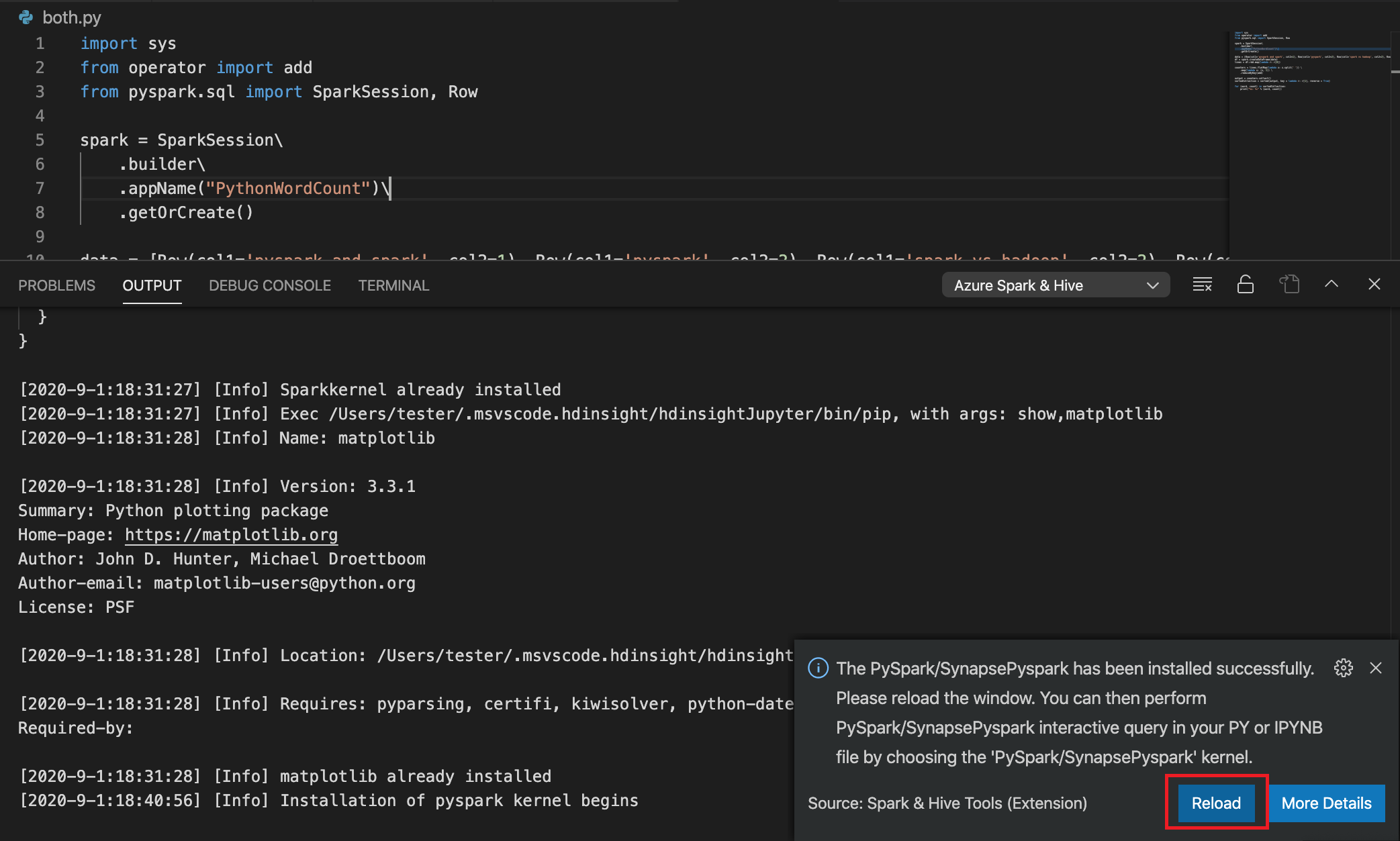
Si l’installation réussit à l’étape 4, la zone de message « PySpark a été installé » s’affiche en bas à droite de la fenêtre. Cliquez sur le bouton Recharger pour recharger la fenêtre.
Dans la barre de menus, accédez à Afficher>Palette de commandes... ou utilisez le raccourci Maj + Ctrl + P, puis entrez Python : Sélectionnez Interpréteur pour démarrer le serveur Jupyter.

Sélectionnez l’option Python ci-dessous.

Dans la barre de menus, accédez à Afficher>Palette de commandes... ou utilisez le raccourci Maj + Ctrl + P, puis entrez Développeur : Recharger la fenêtre.

Connectez-vous à votre compte Azure ou liez un cluster si ce n’est déjà fait.
Sélectionnez l’ensemble du code, cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez Spark: PySpark Interactive/Synapse : PySpark Interactive pour envoyer la requête.
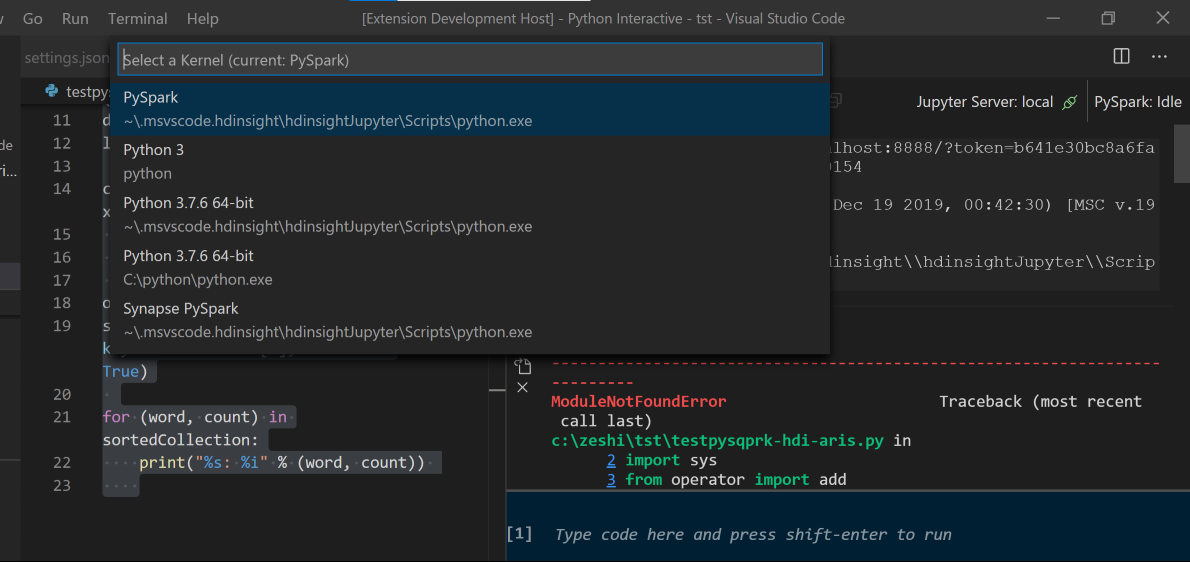
Si vous n’avez pas spécifié de cluster par défaut, sélectionnez le cluster. Après quelques instants, les résultats Python Interactive s’affichent sous un nouvel onglet. Cliquez sur PySpark pour choisir le noyau PySpark/Synapse Pyspark. Le code s’exécute sans erreur. Si vous souhaitez basculer vers le noyau Synapse Pyspark, il est recommandé de désactiver la configuration automatique dans le portail Azure. Dans le cas contraire, la relance du cluster et la définition du noyau de Synapse peuvent prendre un certain temps lors de la première utilisation. Les outils vous permettent également d’envoyer un bloc de code au lieu du fichier de script entier à partir du menu contextuel :
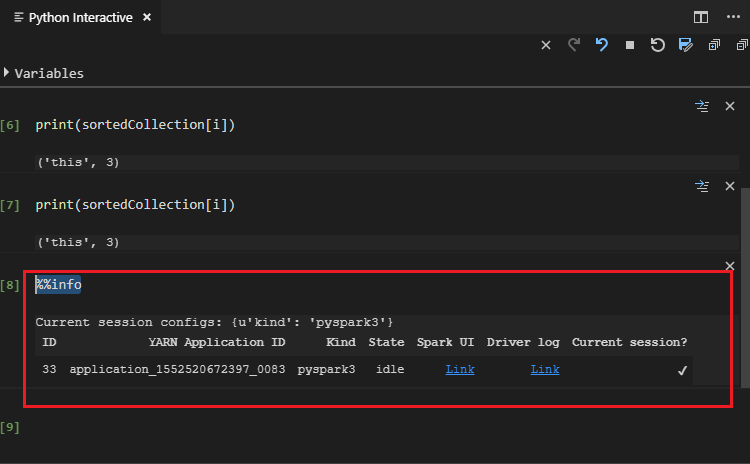
Entrez %%info, puis appuyez sur Maj+Entrée pour afficher les informations sur le travail (facultatif) :
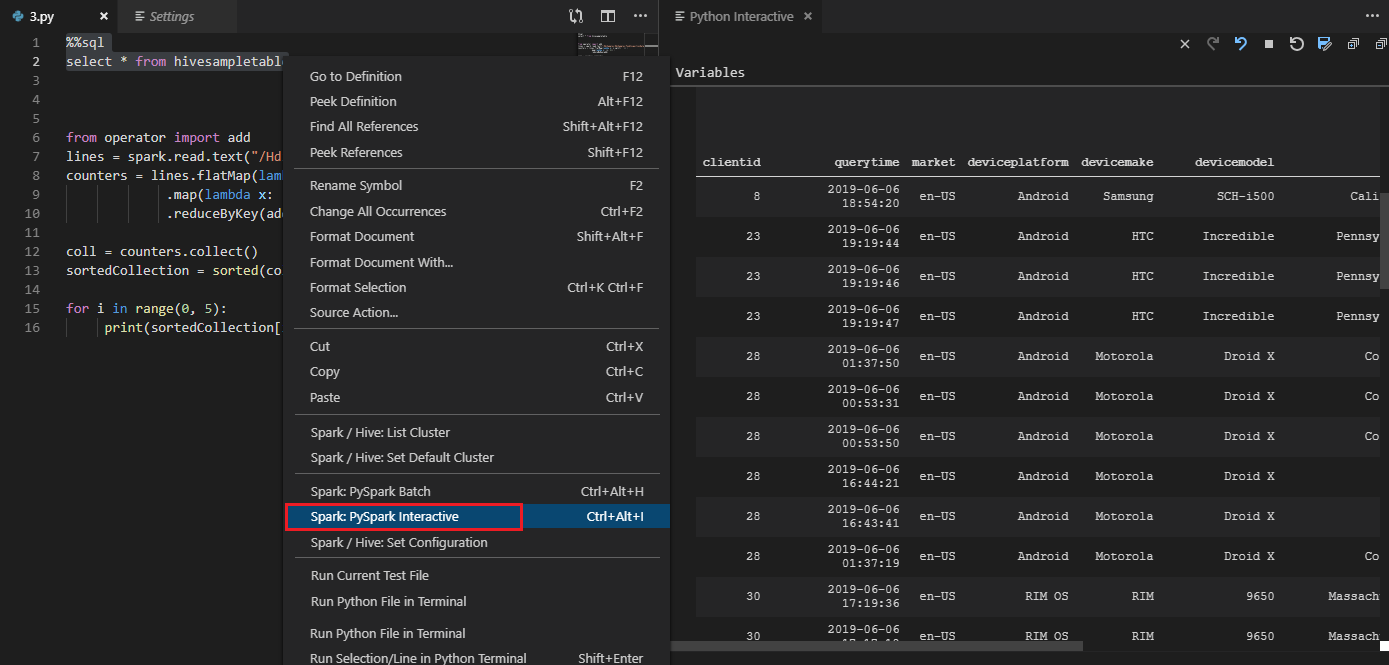
L’outil prend également en charge la requête Spark SQL :
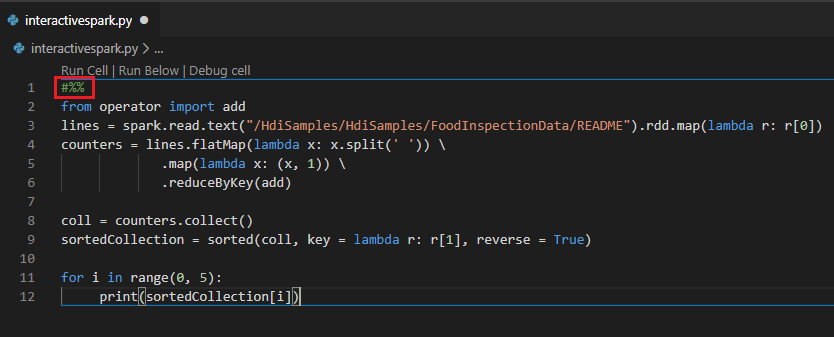
Requête interactive dans le fichier PY à l’aide d’un commentaire #%%
Ajoutez #%% avant le code Py pour bénéficier de l’expérience de notebook.
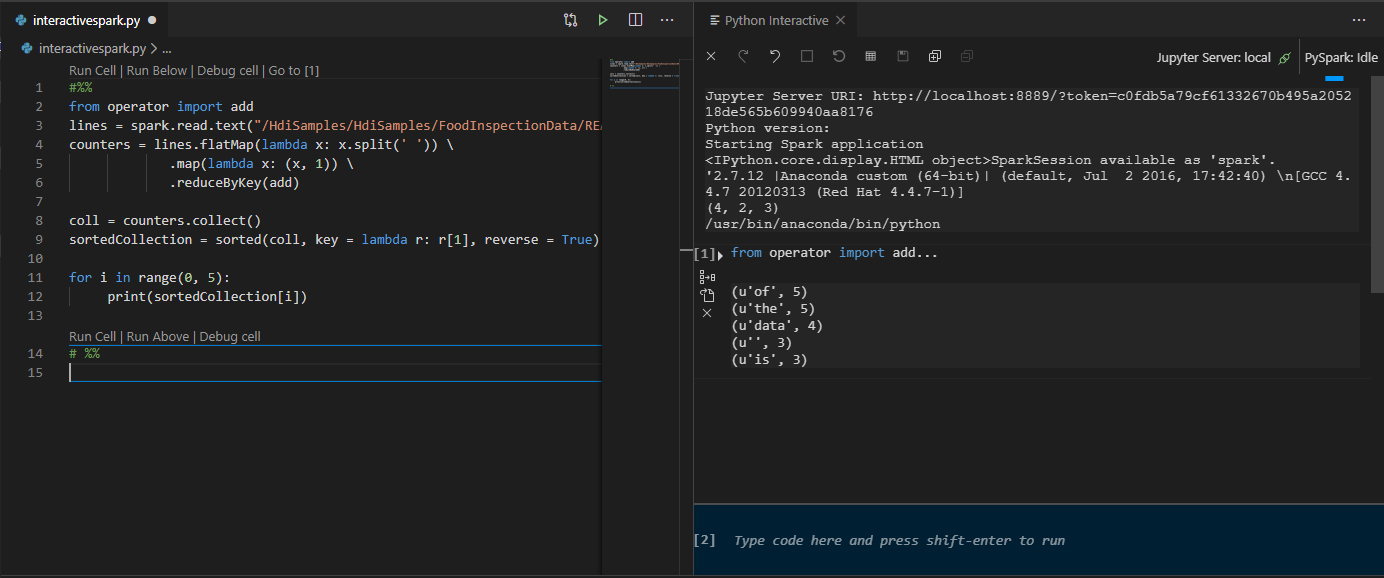
Cliquer sur Exécuter la cellule. Au bout de quelques instants, les résultats Python Interactive s’affichent dans un nouvel onglet. Cliquez sur PySpark pour faire basculer le noyau vers PySpark/Synapse PySpark, puis cliquez à nouveau sur Exécuter la cellule pour que le code s’exécute correctement.
Prise en charge IPYNB de l’extension Python
Vous pouvez créer un notebook Jupyter par commande à partir de la palette de commandes ou en créant un
.ipynbfichier dans votre espace de travail. Pour plus d’informations, consultez Utilisation de Jupyter Notebook dans Visual Studio Code.Cliquez sur le bouton Exécuter la cellule, suivez les invites pour Définir le pool Spark par défaut (nous suggérons de définir un cluster/pool par défaut à chaque ouverture d’un notebook), puis Recharger la fenêtre.
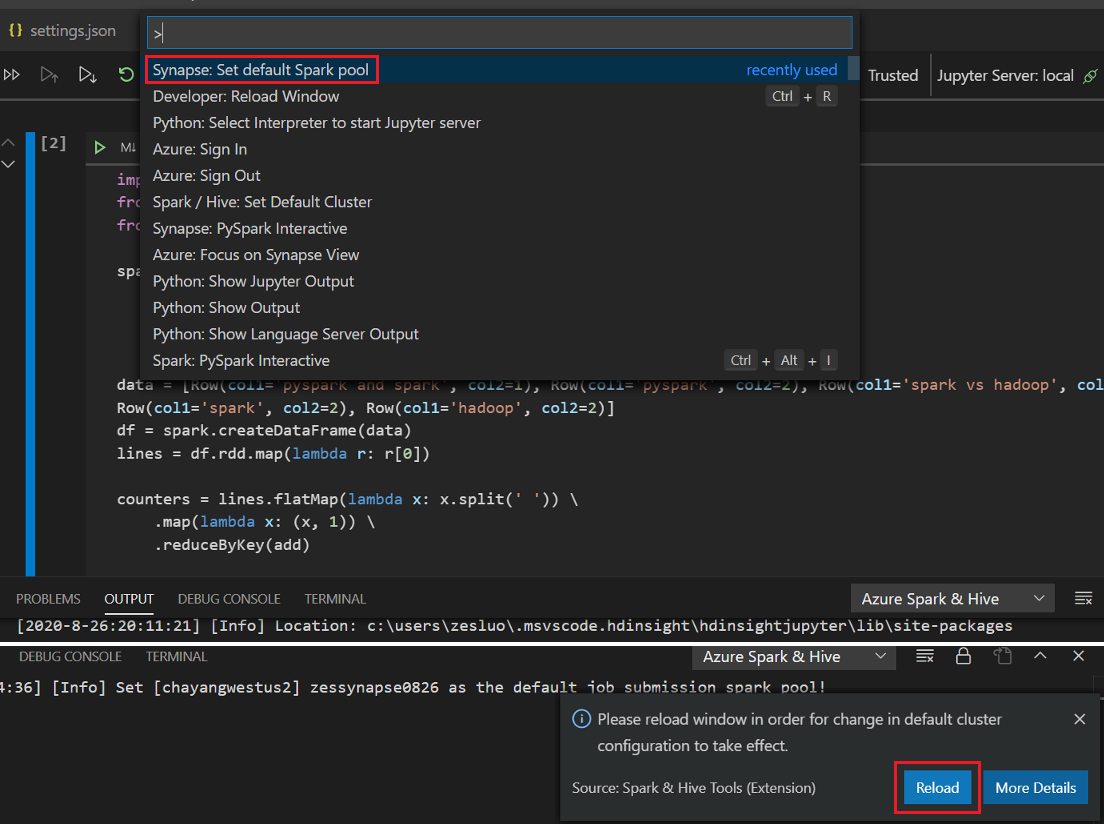
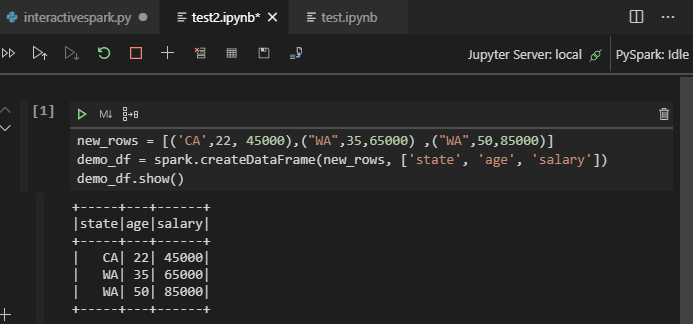
Cliquez sur PySpark pour choisir le noyau PySpark/Synapse PySpark, puis cliquez sur Exécuter la cellule. Au bout d’un certain temps, le résultat s’affiche.
Remarque
Dans le cas d’une erreur d’installation de Synapse PySpark, puisque sa dépendance n’est plus assurée par une autre équipe, cette opération ne le sera plus non plus. Si vous essayez d’utiliser Synapse Pyspark interactive, préférez l’utilisation d’Azure Synapse Analytics. De plus, c’est un changement à long terme.
Envoyer le travail de traitement par lots PySpark
Rouvrez le dossier
HDexampleque vous avez abordé antérieurement, s’il est fermé.Créez un fichier BatchFile.py en suivant les étapes précédentes.
Copiez le code suivant et collez-le dans le fichier de script :
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Connectez-vous à votre compte Azure ou liez un cluster si ce n’est déjà fait.
Cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez Spark: PySpark Batch ou Synapse: PySpark Batch*.
Sélectionnez un cluster ou un pool Spark auquel envoyer le travail PySpark :
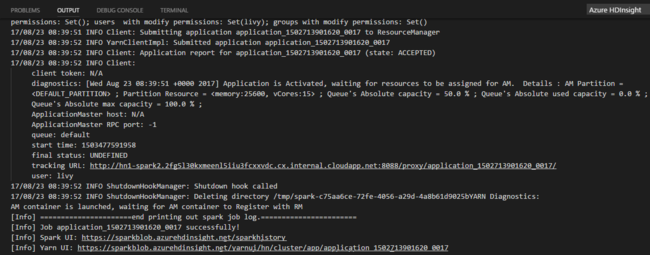
Une fois que vous avez envoyé un travail Python, les journaux d’envoi s’affichent dans la fenêtre OUTPUT (SORTIE) de Visual Studio Code. Les URL des interfaces utilisateur Spark et Yarn s’affichent également. Si vous soumettez le programme de traitement par lots à un pool Apache Spark, l’URL de l’interface utilisateur de l’historique Spark et l’URL de l’interface utilisateur de l’application de travail Spark sont également affichées. Vous pouvez ouvrir l’URL dans un navigateur web pour suivre l’état du travail.
Effectuer l’intégration au broker d’ID HDInsight
Se connecter à votre cluster HDInsight ESP avec le broker d’ID
Vous pouvez suivre les étapes habituelles pour vous connecter à l’abonnement Azure afin de vous connecter à votre cluster HDInsight ESP avec le broker d’ID. Après vous être connecté, vous verrez la liste des clusters dans Azure Explorer. Pour plus d’instructions, consultez Se connecter à votre cluster HDInsight.
Exécution d’un travail Hive/PySpark sur un cluster HDInsight ESP avec broker d’ID (HIB)
Pour exécuter un travail Hive, vous pouvez suivre la procédure habituelle d’envoi d’un travail à un cluster HDInsight ESP avec le broker d’ID (HIB). Pour plus d’instructions, consultez Envoi de requêtes Hive interactives et de scripts de commandes par lot Hive.
Pour exécuter un travail PySpark interactif, vous pouvez suivre la procédure habituelle d’envoi d’un travail à un cluster HDInsight ESP avec le Broker d’ID (HIB). Consultez Envoyer des requêtes PySpark interactives.
Pour exécuter un programme de traitement par lots PySpark, vous pouvez suivre la procédure habituelle d’envoi d’un travail à un cluster HDInsight ESP avec le broker d’ID (HIB). Pour plus d’instructions, consultez Envoi d’un programme de traitement par lots PySpark.
Configuration d’Apache Livy
La configuration Apache Livy est prise en charge. Vous pouvez effectuer la configuration dans le fichier .VSCode\settings.json situé dans le dossier de l’espace de travail. Actuellement, la configuration Livy prend uniquement en charge le script Python. Pour plus d’informations, consultez LISEZ-MOI Livy.
Comment déclencher une configuration Livy
Méthode 1
- Dans la barre de menus, accédez à Fichier>Préférences>Paramètres.
- Dans la zone Paramètres de recherche, entrez Envoi de travail HDInsight : Livy Conf (Envoi de travail HDInsight : configuration de Livy).
- Sélectionnez Modifier dans settings.json pour le résultat de recherche approprié.
Méthode 2
Envoyez un fichier. Vous constatez que le dossier .vscode est ajouté automatiquement au dossier de travail. Vous pouvez voir la configuration Livy en sélectionnant .vscode\settings.json.
Paramètres du projet :
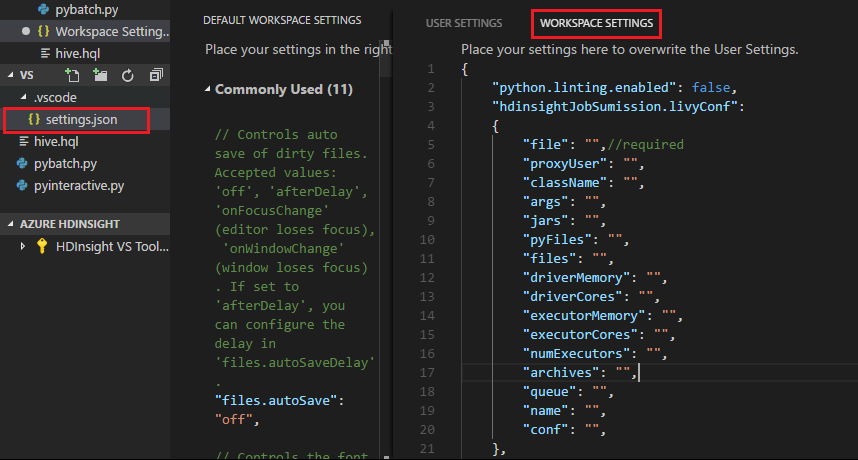
Remarque
Pour les paramètres driverMemory et executorMemory, définissez la valeur et l’unité. Par exemple : 1 g ou 1 024 m.
Configurations Livy prises en charge :
POST /batches
Corps de la demande
name description type fichier Fichier contenant l’application à exécuter Chemin (obligatoire) proxyUser Utilisateur dont l’identité doit être empruntée lors de l’exécution du travail String ClassName Classe principale Java/Spark de l’application String args Arguments de ligne de commande pour l’application Liste de chaînes jars Fichiers JAR à utiliser dans cette session Liste de chaînes pyFiles Fichiers Python à utiliser dans cette session Liste de chaînes files Fichiers à utiliser dans cette session Liste de chaînes driverMemory Quantité de mémoire à utiliser pour le processus du pilote String driverCores Nombre de cœurs à utiliser pour le processus du pilote Int executorMemory Quantité de mémoire à utiliser par processus d’exécuteur String executorCores Nombre de cœurs à utiliser pour chaque exécuteur Int numExecutors Nombre d’exécuteurs à lancer pour cette session Int archives Archives à utiliser dans cette session Liste de chaînes queue Nom de la file d’attente YARN vers laquelle effectuer l’envoi String name Nom de cette session String conf Propriétés de configuration de Spark Mappage clé=valeur Corps de la réponse : l’objet Batch créé
name description type id ID de la session Int appId ID d’application de cette session String appInfo Informations détaillées sur l’application Mappage clé=valeur log Lignes du journal Liste de chaînes state État du lot String Notes
La configuration Livy attribuée s’affiche dans le volet de sortie quand vous envoyez le script.
Intégrer avec Azure HDInsight à partir de l’Explorateur
Vous pouvez voir un aperçu de la table Hive directement dans vos clusters à l’aide de l’explorateur Azure HDInsight :
Connectez-vous à votre compte Azure, si ce n’est déjà fait.
Cliquez sur l’icône Azure dans la colonne la plus à gauche.
Dans le volet gauche, développez AZURE : HDINSIGHT. Les clusters et les abonnements disponibles y sont listés.
Développez le cluster pour afficher le schéma de table et la base de données de métadonnées Hive.
Cliquez avec le bouton droit sur la table Hive. Par exemple : hivesampletable. Sélectionnez Aperçu.
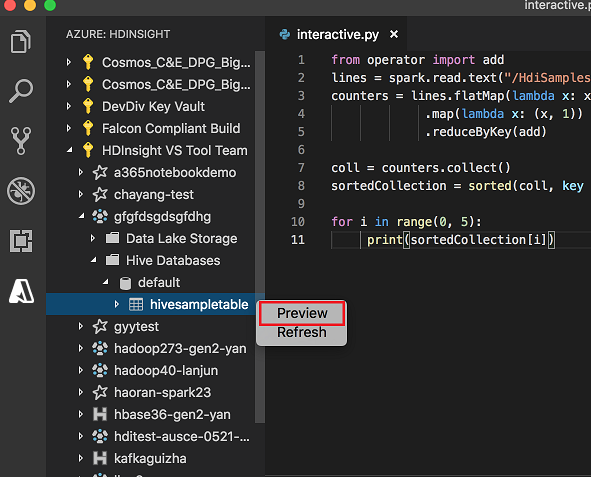
La fenêtre Aperçu des résultats s’ouvre :
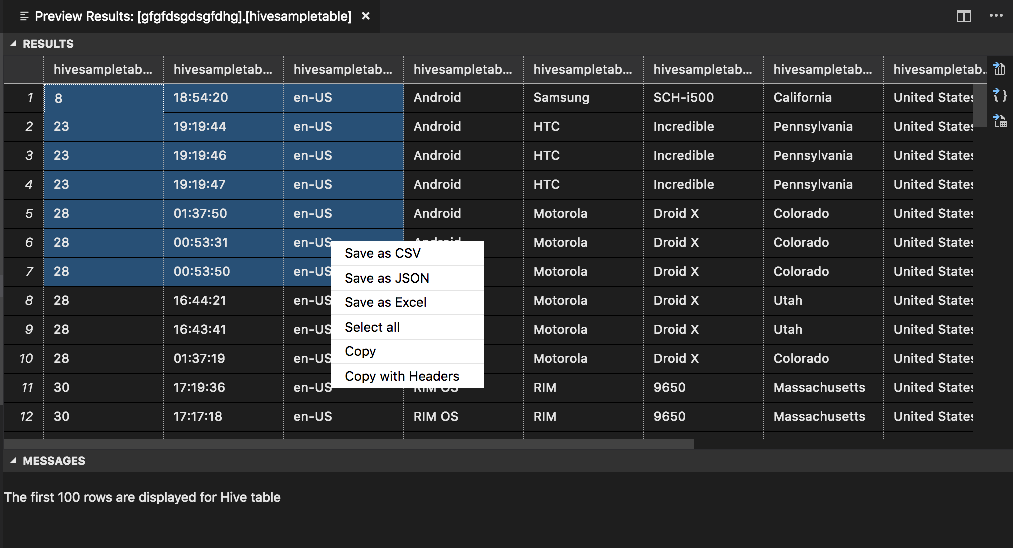
Volet RÉSULTATS
Vous pouvez enregistrer le résultat complet dans un fichier CSV, JSON ou Excel dans un chemin local ou enregistrer seulement certaines lignes du résultat.
Volet MESSAGES
Quand le nombre de lignes dans la table est supérieur à 100, le message suivant s’affiche : « Les 100 premières lignes sont affichées dans la table Hive ».
Quand le nombre de lignes dans la table est inférieur ou égal à 100, le message suivant s’affiche : « 60 lignes sont affichées dans la table Hive ».
Quand la table est vide, le message suivant s’affiche : «
0 rows are displayed for Hive table.»Notes
Sous Linux, installez xclip pour autoriser la copie des données de table.
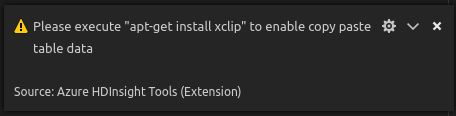
Fonctionnalités supplémentaires
Les fonctionnalités suivantes sont également prises en charge par Spark et Hive pour Visual Studio Code :
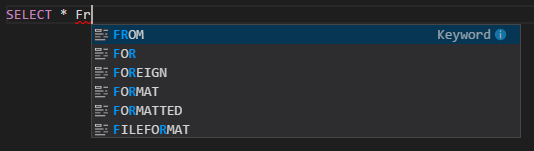
Saisie semi-automatique IntelliSense. Des suggestions de mots clés, de méthodes, de variables et d’autres éléments de programmation s’affichent. Les différentes icônes représentent les différents types d’objets :
Marqueur d’erreur IntelliSense. Le service de langage souligne les erreurs de saisie dans le script Hive.
Coloration syntaxique. Le service de langage utilise plusieurs couleurs pour différencier les variables, les mots clés, le type des données, les fonctions et les autres éléments de programmation :
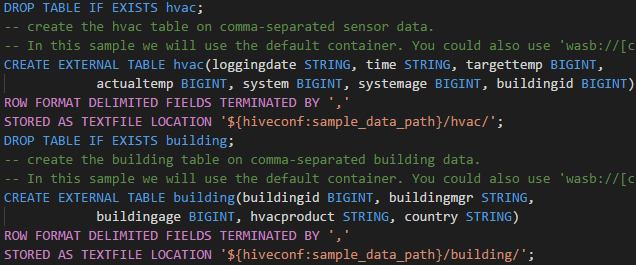
Rôle Lecteur seul
Les utilisateurs auxquels le rôle de lecteur uniquement a été attribué pour le cluster ne peuvent pas envoyer de travaux au cluster HDInsight, ni visualiser la base de données Hive. Vous devez contacter l’administrateur du cluster afin de mettre à niveau votre rôle pour être opérateur de cluster HDInsight dans le portail Azure. Si vous disposez d’informations d’identification Ambari valides, vous pouvez lier manuellement le cluster en suivant les instructions ci-après.
Parcourir le cluster HDInsight
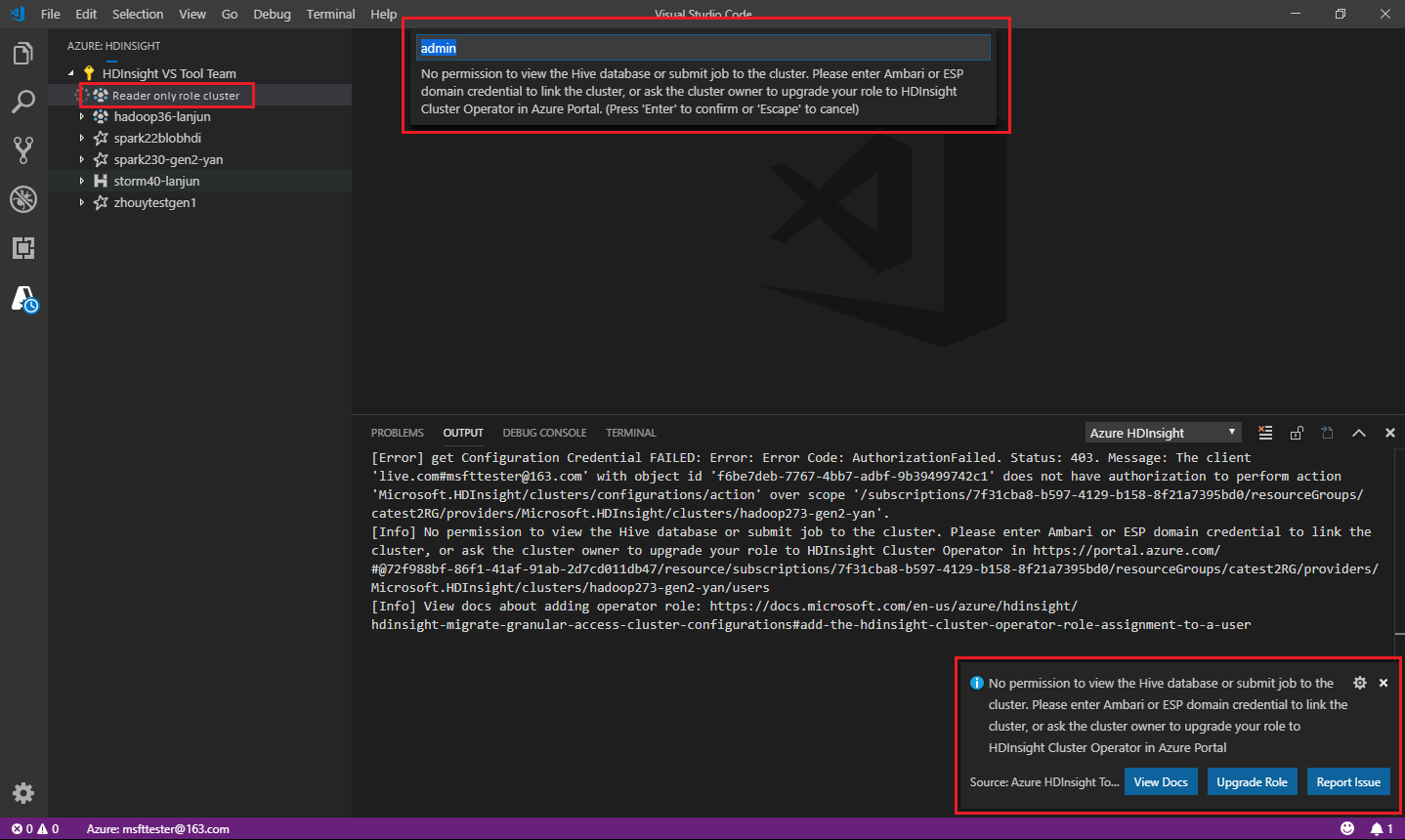
Quand vous sélectionnez l’explorateur Azure HDInsight pour développer un cluster HDInsight, vous êtes invité à lier le cluster si vous disposez du rôle de lecteur uniquement sur le cluster. Utilisez la méthode suivante pour établir une liaison au cluster à l’aide de vos informations d’identification Ambari.
Envoyer le travail au cluster HDInsight
Quand vous envoyez un travail à un cluster HDInsight, vous êtes invité à lier le cluster si vous disposez du rôle de lecteur uniquement sur le cluster. Utilisez la procédure suivante pour établir une liaison au cluster à l’aide d’informations d’identification Ambari.
Établir une liaison au cluster
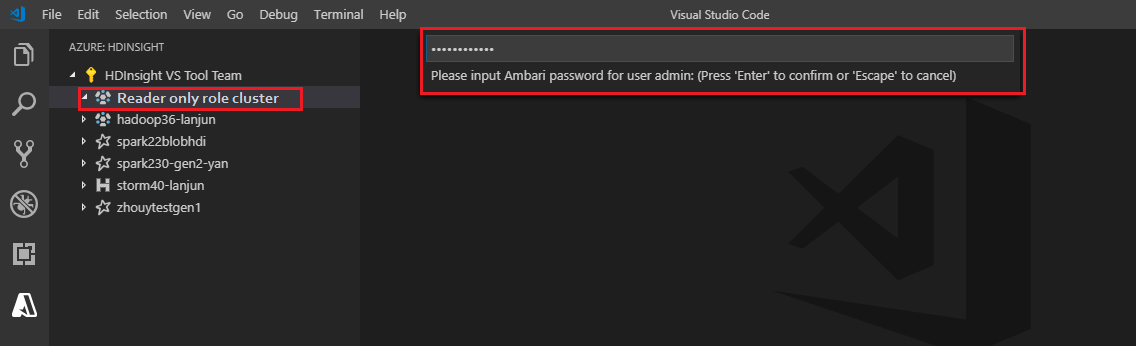
Entrez un nom d’utilisateur Ambari valide.
Entrez un mot de passe valide.
Remarque
Vous pouvez utiliser
Spark / Hive: List Clusterpour vérifier le cluster lié :
Azure Data Lake Storage Gen2
Parcourir un compte Data Lake Storage Gen2
Sélectionnez l’explorateur Azure HDInsight pour développer un compte Data Lake Storage Gen2. Vous êtes invité à entrer la clé d’accès de stockage si votre compte Azure n’a pas accès au stockage Gen2. Une fois la clé d’accès validée, le compte Data Lake Storage Gen2 est développé automatiquement.
Envoyer des travaux à un cluster HDInsight avec Data Lake Storage Gen2
Envoyez un travail à un cluster HDInsight à l’aide de Data Lake Storage Gen2. Vous êtes invité à entrer la clé d’accès de stockage si votre compte Azure n’a pas accès en écriture au stockage Gen2. Le travail est envoyé avec succès une fois que la clé d’accès est validée.

Remarque
Vous pouvez obtenir la clé d’accès du compte de stockage sur le portail Azure. Pour plus d’informations, consultez Gérer les clés d’accès au compte de stockage.
Dissocier le cluster
À partir de la barre de menus, accédez à Afficher>Palette de commandes, puis entrez Spark / Hive: Unlink a Cluster (Dissocier un cluster).
Sélectionnez le cluster pour lequel supprimer le lien.
Passez en revue la vue SORTIE à des fins de vérification.
Se déconnecter
À partir de la barre de menus, accédez à Afficher>Palette de commandes, puis entrez Azure: Se déconnecter.
Problèmes connus
Erreur d’installation de Synapse PySpark.
Pour l’erreur d’installation de Synapse PySpark, puisque sa dépendance n’est plus assurée par une autre équipe, elle ne sera plus assurée du tout. Si vous essayez d’utiliser Synapse Pyspark interactive, préférez l’utilisation d’Azure Synapse Analytics. De plus, c’est un changement à long terme.
Étapes suivantes
Pour voir une vidéo de démonstration sur l’utilisation de Spark et Hive pour Visual Studio Code, consultez Spark et Hive pour Visual Studio Code.