Résoudre les problèmes d’Apache Hadoop HDFS avec Azure HDInsight
Découvrez les principaux problèmes rencontrés lors de l’utilisation de charges utiles HDFS (Hadoop Distributed File System). Pour obtenir la liste complète des commandes, consultez le Guide des commandes HDFS et le Guide des commandes shell du système de fichiers.
Comment accéder au stockage HDFS local depuis un cluster ?
Problème
Accédez au stockage HDFS local à l’aide de la ligne de commande et du code d’application plutôt qu’à partir du Stockage Blob Azure ou d’Azure Data Lake Storage à partir du cluster HDInsight.
Étapes de résolution
Dans la ligne de commande, utilisez
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...littéralement, comme dans la commande suivante :hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userÀ partir du code source, utilisez l’URI
hdfs://mycluster/littéralement, comme dans l’exemple d’application suivant :import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Exécutez le fichier .jar compilé (par exemple un fichier nommé
java-unit-tests-1.0.jar) sur le cluster HDInsight à l’aide de la commande suivante :hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Exception de stockage pour l’écriture sur un objet blob
Problème
Quand vous utilisez la commande hadoop ou hdfs dfs pour écrire des fichiers supérieurs à ~12 Go sur un cluster HBase, vous pouvez rencontrer l’erreur suivante :
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Cause
Les clusters HBase sur HDInsight ont par défaut une taille de bloc de 256 Ko lors de l’écriture dans le stockage Azure. Bien que cela fonctionne pour les API HBase ou les API REST, cela génère une erreur quand vous utilisez les utilitaires en ligne de commande hadoop ou hdfs dfs.
Résolution
Utilisez fs.azure.write.request.size pour spécifier une plus grande taille de bloc. Vous pouvez faire cette modification sur une base par utilisation à l’aide du paramètre -D. La commande suivante illustre l’utilisation de ce paramètre avec la commande hadoop :
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
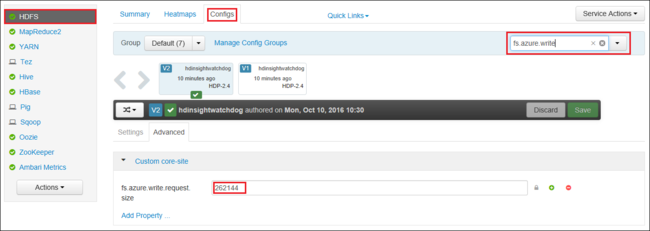
Vous pouvez également augmenter la valeur de fs.azure.write.request.size globalement à l’aide d’Apache Ambari. Vous pouvez utiliser les étapes suivantes pour modifier la valeur dans l’interface utilisateur Web d’Ambari :
Dans votre navigateur, accédez à l’interface utilisateur Web d’Ambari pour votre cluster. L’URL est
https://CLUSTERNAME.azurehdinsight.net, oùCLUSTERNAMEest le nom de votre cluster. Lorsque vous y êtes invité, entrez le nom et le mot de passe administrateur correspondant au cluster HDInsight.Sur le côté gauche de l’écran, sélectionnez HDFS, puis l’onglet Configurations.
Dans le champ Filtrer... , entrez
fs.azure.write.request.size.Modifiez la valeur 262144 (256 Ko) sur la nouvelle valeur. Par exemple, 4194304 (4 Mo).
Pour plus d’informations sur l’utilisation d’Ambari, voir Gestion des clusters HDInsight à l’aide de l’interface utilisateur Web d’Apache Ambari.
du
La commande -du affiche la taille des fichiers et des répertoires contenus dans le répertoire donné ou la longueur d’un fichier dans le cas d’un simple fichier.
L’option -s produit un résumé agrégé des longueurs de fichier affichées.
L’option -h met en forme les tailles de fichiers.
Exemple :
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
La commande -rm supprime les fichiers spécifiés en tant qu’arguments.
Exemple :
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Étapes suivantes
Si votre problème ne figure pas dans cet article ou si vous ne parvenez pas à le résoudre, utilisez un des canaux suivants pour obtenir de l’aide :
Obtenez des réponses de la part d’experts Azure en faisant appel au Support de la communauté Azure.
Connectez-vous à @AzureSupport, le compte Microsoft Azure officiel pour améliorer l’expérience client. Connexion de la communauté Azure aux ressources appropriées : réponses, support technique et experts.
Si vous avez besoin d’une aide supplémentaire, vous pouvez envoyer une requête de support à partir du Portail Microsoft Azure. Sélectionnez Support dans la barre de menus, ou ouvrez le hub Aide + Support. Pour plus d’informations, consultez Création d’une demande de support Azure. L’accès au support relatif à la gestion et à la facturation des abonnements est inclus avec votre abonnement Microsoft Azure. En outre, le support technique est fourni avec l’un des plans de support Azure.