Utiliser les fonctionnalités étendues du serveur d’historique Apache Spark pour déboguer et diagnostiquer des applications Spark
Cet article vous montre comment utiliser les fonctionnalités étendues du serveur d’historique Apache Spark étendu pour déboguer et diagnostiquer des applications Spark terminées ou en cours d’exécution. L’extension comprend les onglets Data, Graph et Diagnosis. Sous l’onglet Data, vous pouvez vérifier les données d’entrée et de sortie du travail Spark. Sous l’onglet Graph, vous pouvez vérifier le flux de données et lire à nouveau le graphe des travaux. Sous l’onglet Diagnosis, vous pouvez voir les fonctionnalités d’asymétrie des données, d’asymétrie temporelle et d’analyse de l’utilisation des exécuteurs.
Accéder au serveur d’historique Spark
Le serveur d’historique Spark est l’interface utilisateur web pour les applications Spark terminées et en cours d’exécution. Vous pouvez l’ouvrir à partir du portail Azure ou d’une URL.
Ouvrir l’interface utilisateur web du serveur d’historique Spark à partir du portail Azure
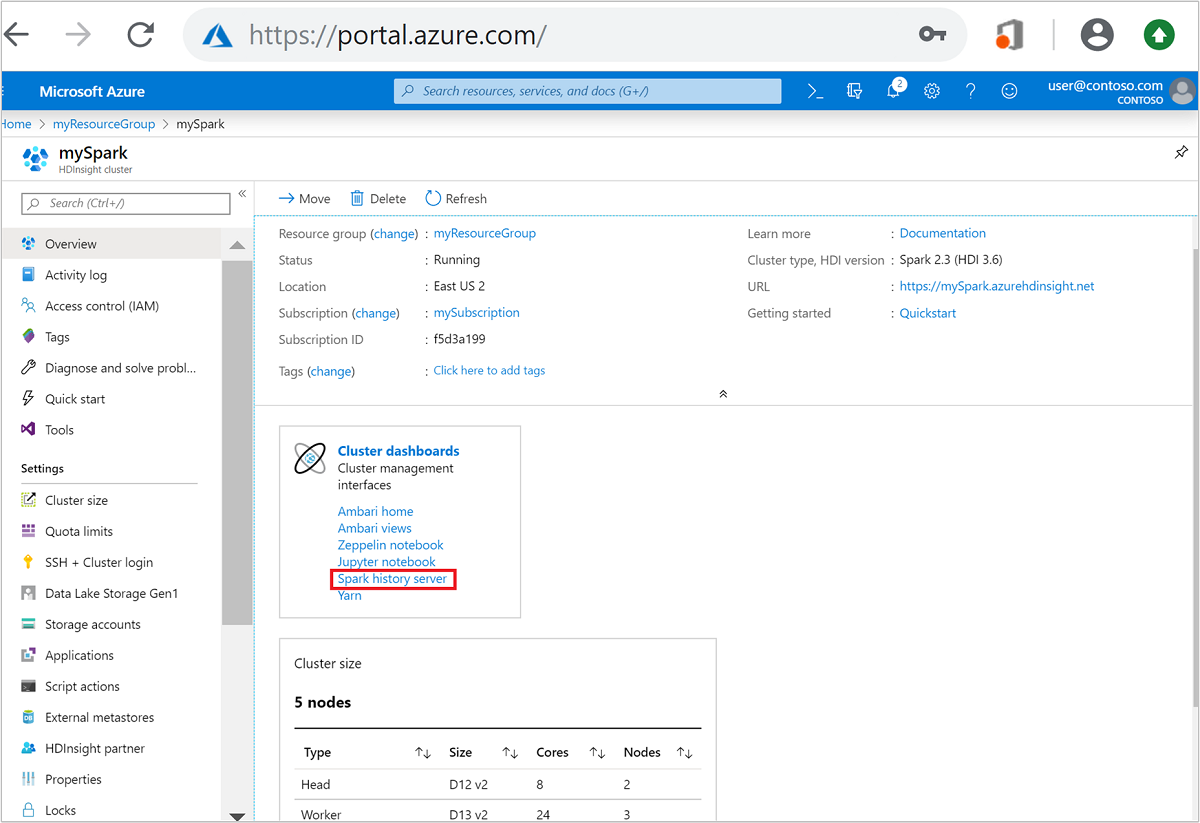
À partir du portail Azure, ouvrez le cluster Spark. Pour plus d’informations, voir Énumération et affichage des clusters.
Dans Tableaux de bord du cluster, sélectionnez Serveur d’historique Spark. Lorsque vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster Spark.
 portail Azure." border="true":::
portail Azure." border="true":::
Ouvrir l’interface utilisateur web du serveur d’historique Spark au moyen d’une URL
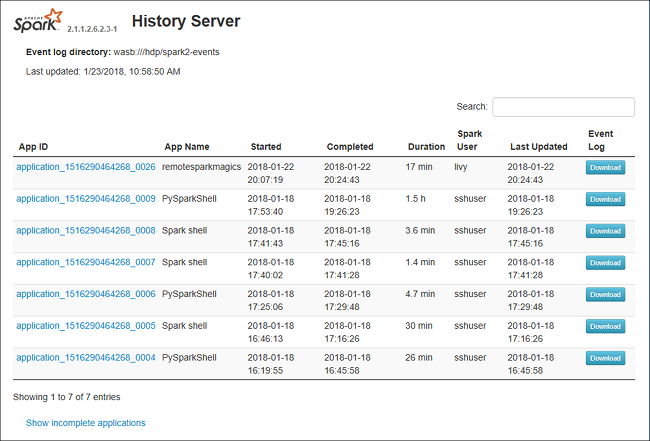
Ouvrez le serveur d’historique Spark en accédant à https://CLUSTERNAME.azurehdinsight.net/sparkhistory, où CLUSTERNAME est le nom de votre cluster Spark.
L’interface utilisateur web du serveur d’historique Spark peut être similaire à l’image suivante :
Utiliser l’onglet Data du serveur d’historique Spark
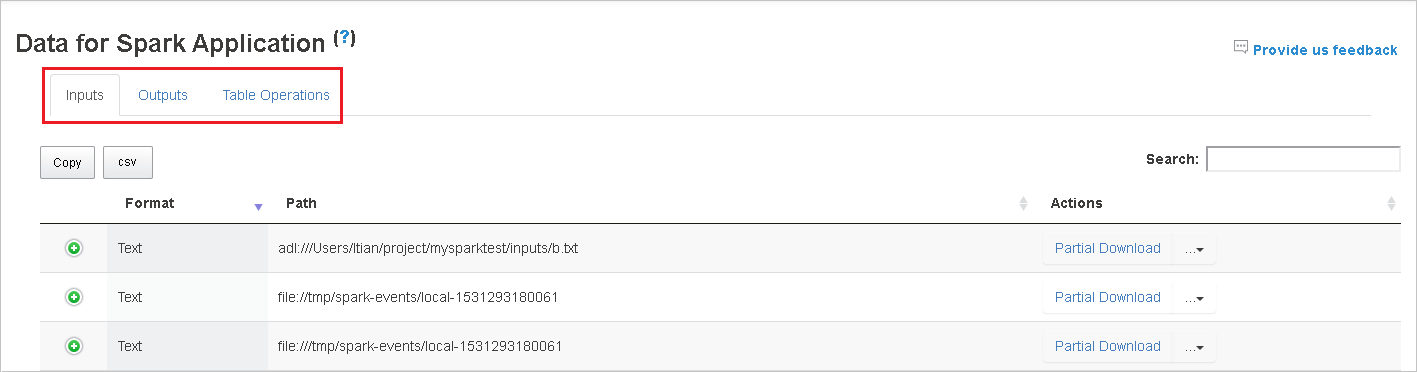
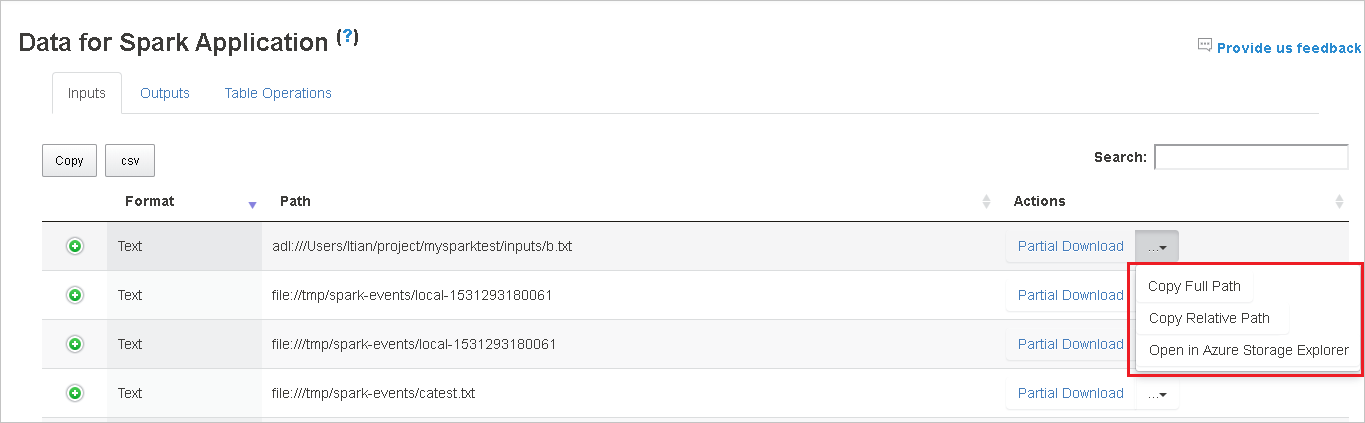
Sélectionnez l’ID du travail, puis sélectionnez Data dans le menu des outils pour afficher la vue des données.
Examinez les entrées, les sorties et les opérations de table en sélectionnant les onglets individuels.
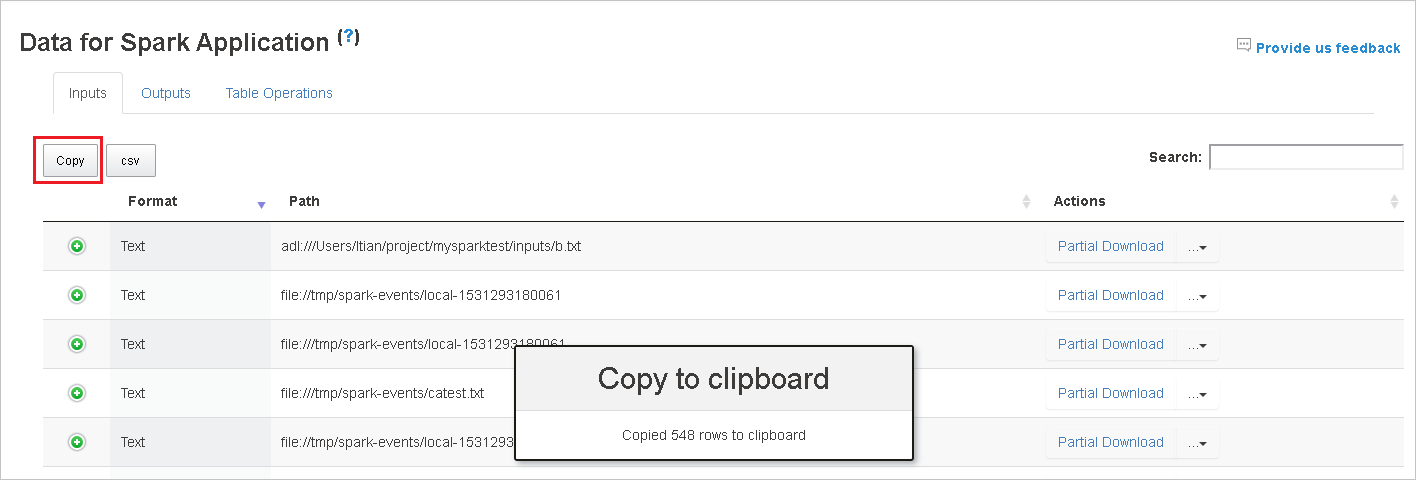
Copiez toutes les lignes en sélectionnant le bouton Copy.
Enregistrez toutes les données sous la forme d’un fichier CSV en sélectionnant le bouton csv.
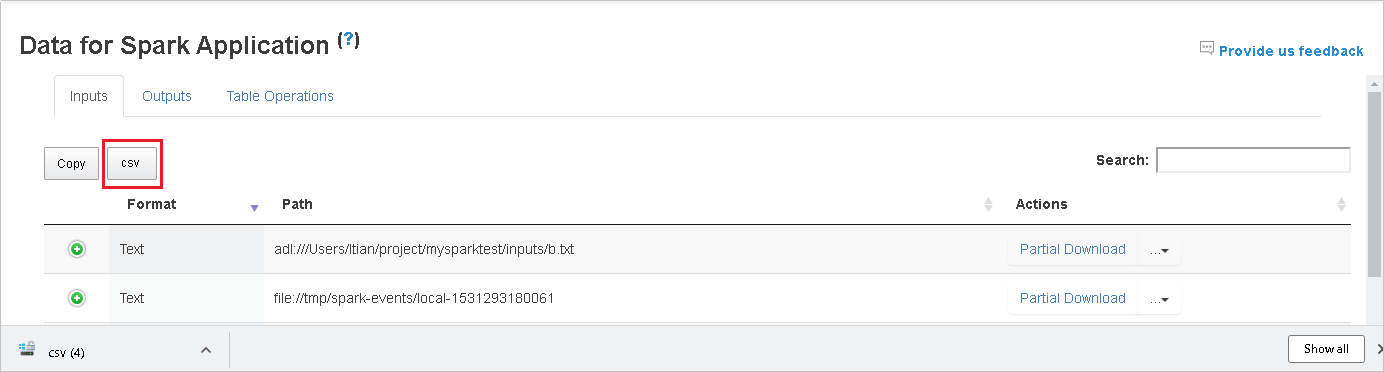
Effectuez des recherches dans les données en entrant des mots clés dans le champ Search. Les résultats de recherche sont affichés immédiatement.
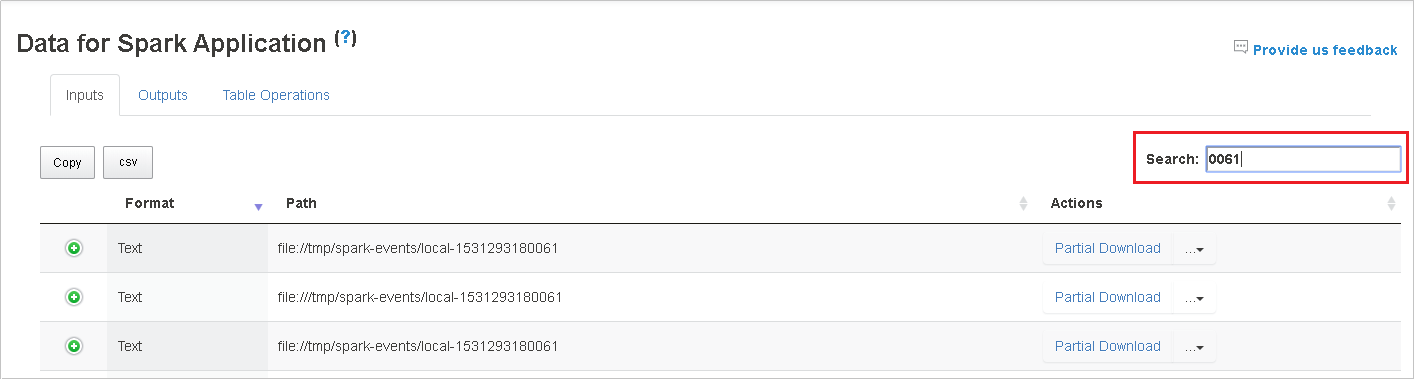
Sélectionnez l’en-tête de colonne pour trier la table. Sélectionnez le signe plus (+) pour développer une ligne et afficher plus de détails. Sélectionnez le signe moins (-) pour réduire une ligne.
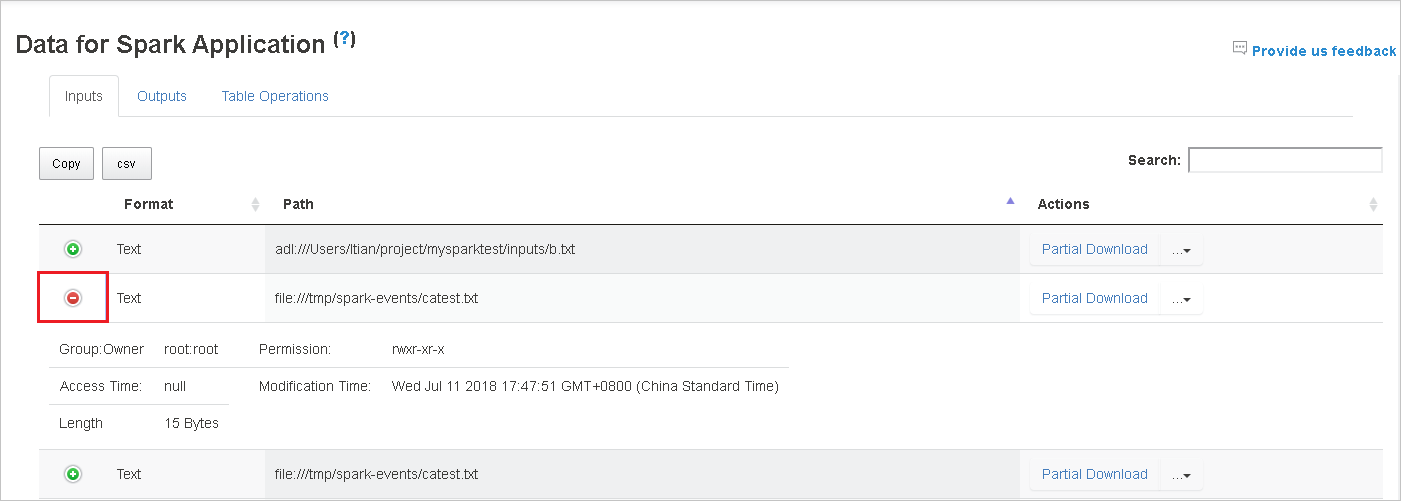
Téléchargez un fichier unique en sélectionnant le bouton Partial Download (Téléchargement partiel) à droite. Le fichier sélectionné est téléchargé localement. Si le fichier n’existe plus, un nouvel onglet s’ouvre pour afficher les messages d’erreur.
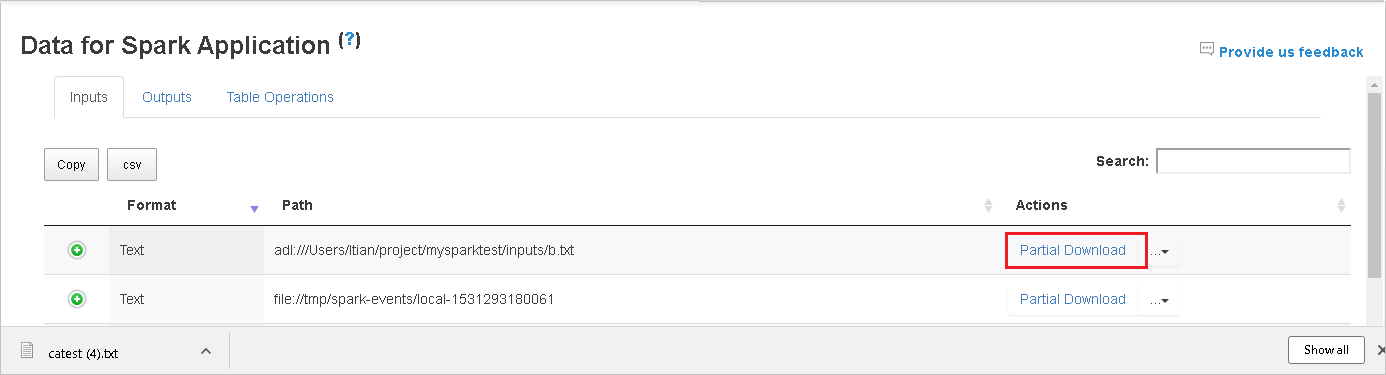
Copiez un chemin complet ou un chemin relatif en sélectionnant l’option Copy Full Path (Copier le chemin complet) ou l’option Copy Relative Path (Copier le chemin relatif), qui étendent le menu de téléchargement. Pour les fichiers Azure Data Lake Storage, sélectionnez Open in Azure Storage Explorer (Ouvrir dans l’Explorateur Stockage Azure) pour lancer l’Explorateur Stockage Azure et localiser le dossier après la connexion.
Si le nombre de lignes à afficher sur une seule page est trop important, sélectionnez les numéros de page en bas de la table pour naviguer.

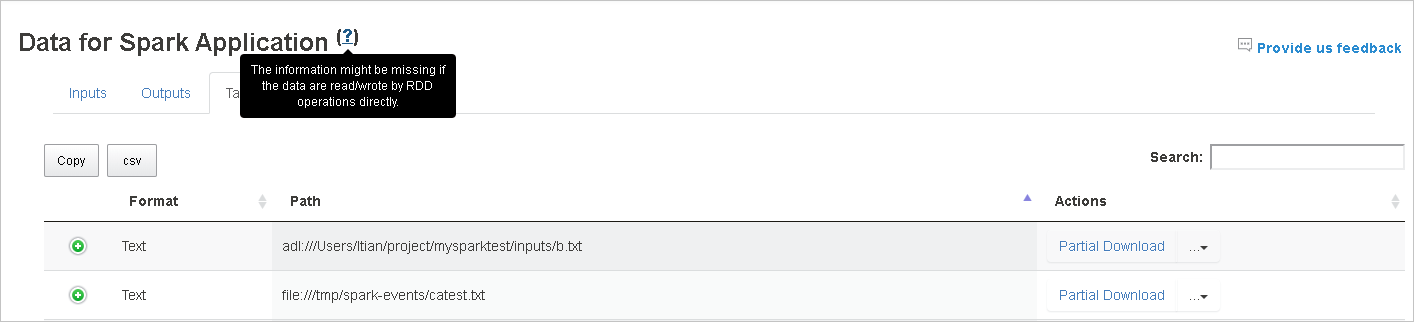
Pour plus d’informations, pointez sur le point d’interrogation en regard de Data for Spark Application, ou sélectionnez-le, pour afficher l’info-bulle.
Pour envoyer des commentaires sur les problèmes, sélectionnez Provide us feedback (Envoyez-nous vos commentaires).
Utiliser l’onglet Graph du serveur d’historique Spark
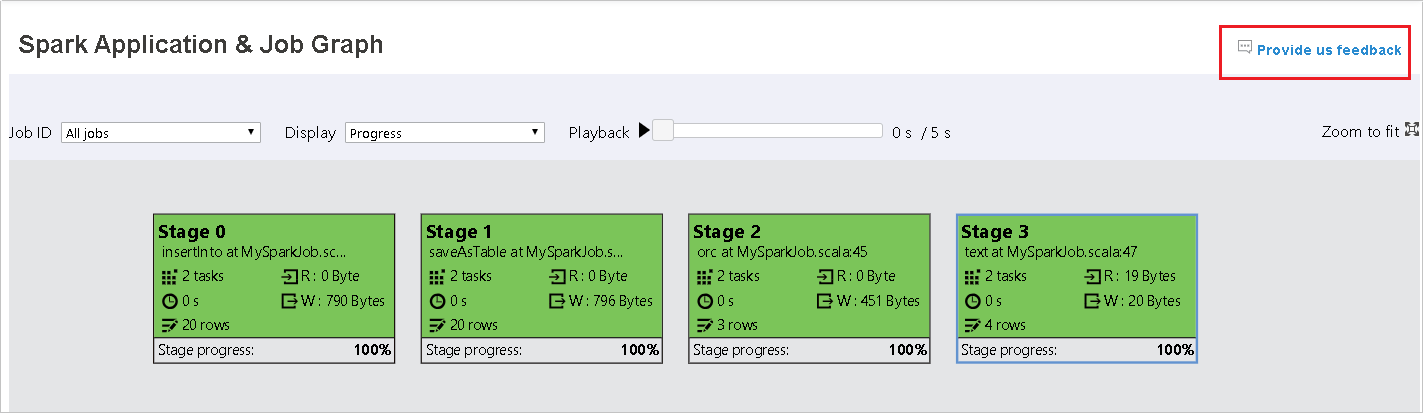
Sélectionnez l’ID de travail, puis sélectionnez Graph dans le menu des outils pour afficher le graphe de travail. Par défaut, le graphe affiche tous les travaux. Filtrez les résultats à l’aide du menu déroulant Job ID (ID de travail).
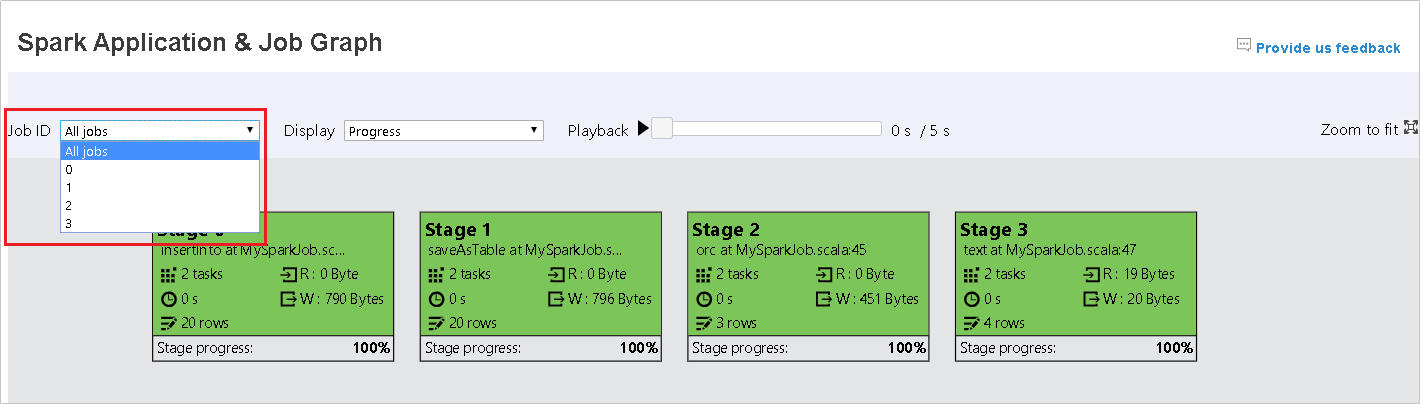
L’option Progress est sélectionnée par défaut. Vérifiez le flux de données en sélectionnant Read (Données lues) ou Written (Données écrites) dans le menu déroulant Display (Affichage).
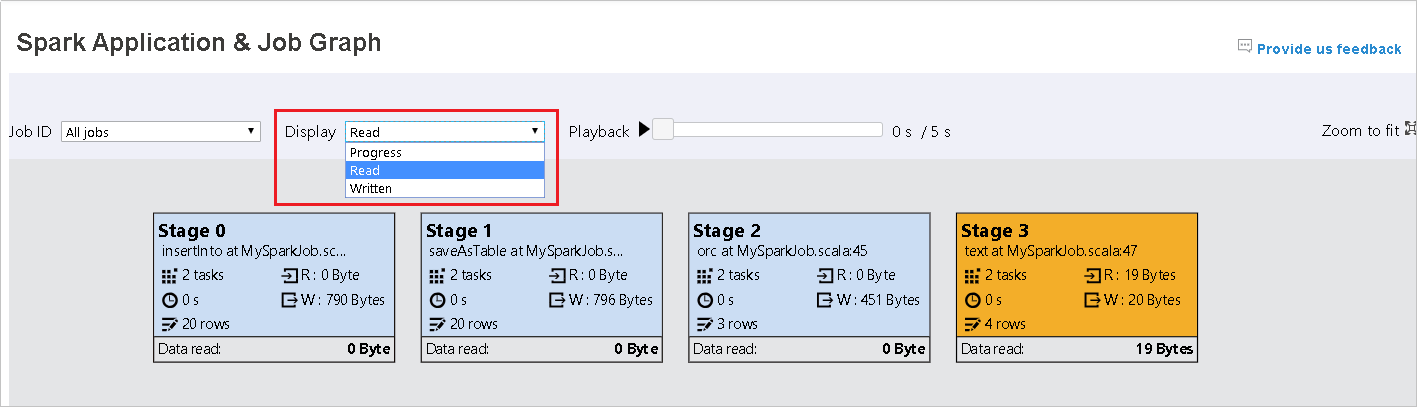
La couleur d’arrière-plan de chaque tâche correspond à une carte thermique.

Couleur Description Vert le travail s’est correctement effectué. Orange La tâche a échoué, mais cela n’affecte pas le résultat final du travail. Ces tâches comportent des instances dupliquées ou renouvelées qui peuvent réussir ultérieurement. Bleu la tâche est en cours d’exécution. White la tâche est en attente d’exécution, ou la phase a été ignorée. Rouge la tâche a échoué. 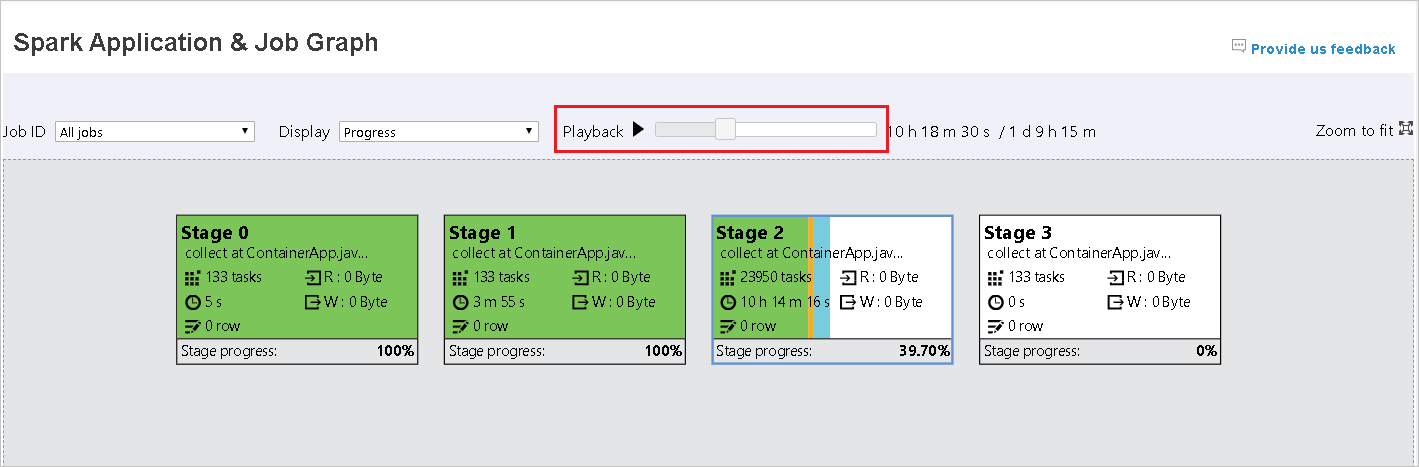
Les phases ignorées s’affichent en blanc.
Remarque
La lecture est disponible pour les travaux terminés. Sélectionnez le bouton Playback (Lecture) pour relire le travail. Arrêtez le travail à tout moment en sélectionnant le bouton d’arrêt. Lorsqu’un travail est relu, chaque tâche affiche son état à l’aide d’une couleur. La lecture n’est pas prise en charge pour des travaux incomplets.
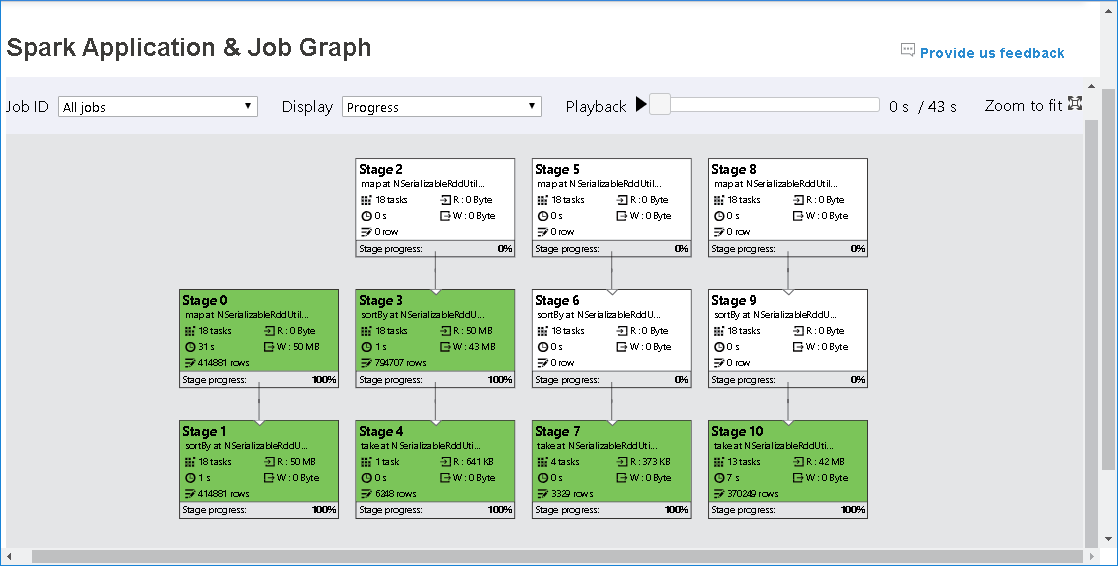
Faites défiler pour effectuer un zoom avant/arrière du graphe de travail, ou sélectionnez Zoom to fit (Zoom d’ajustement) pour l’ajuster à l’écran.
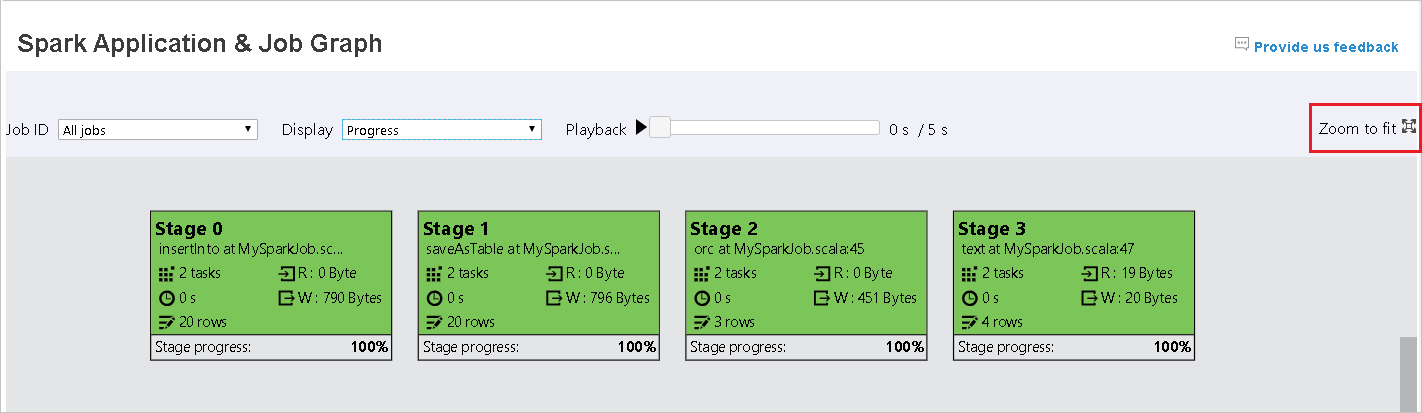
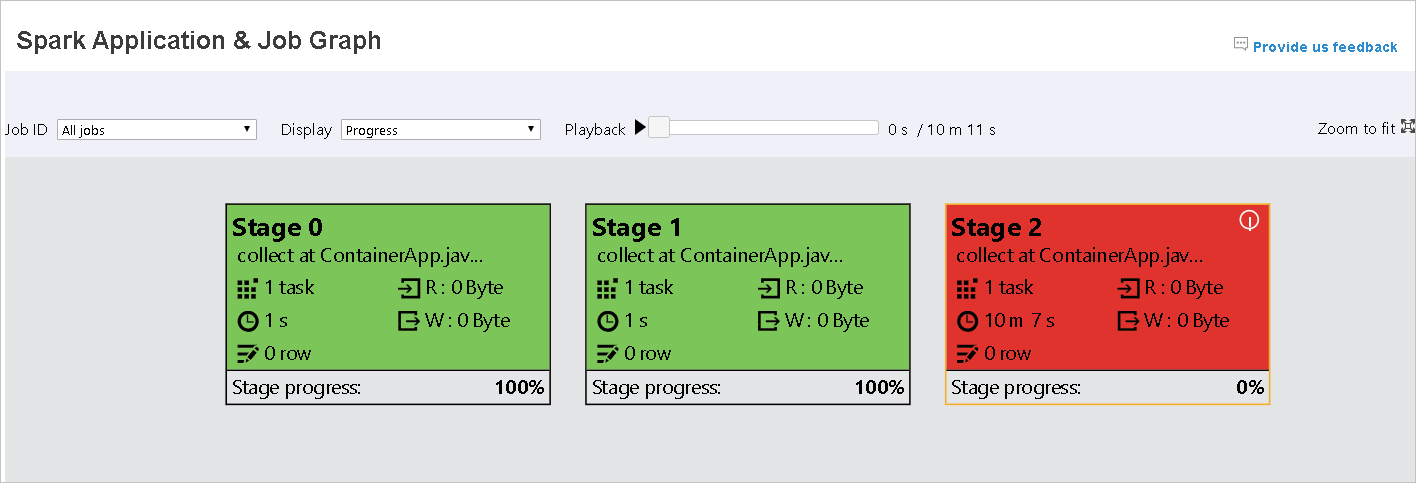
Lorsque des tâches échouent, pointez sur le nœud du graphe pour afficher l’info-bulle, puis sélectionnez la phase pour l’ouvrir dans une nouvelle page.
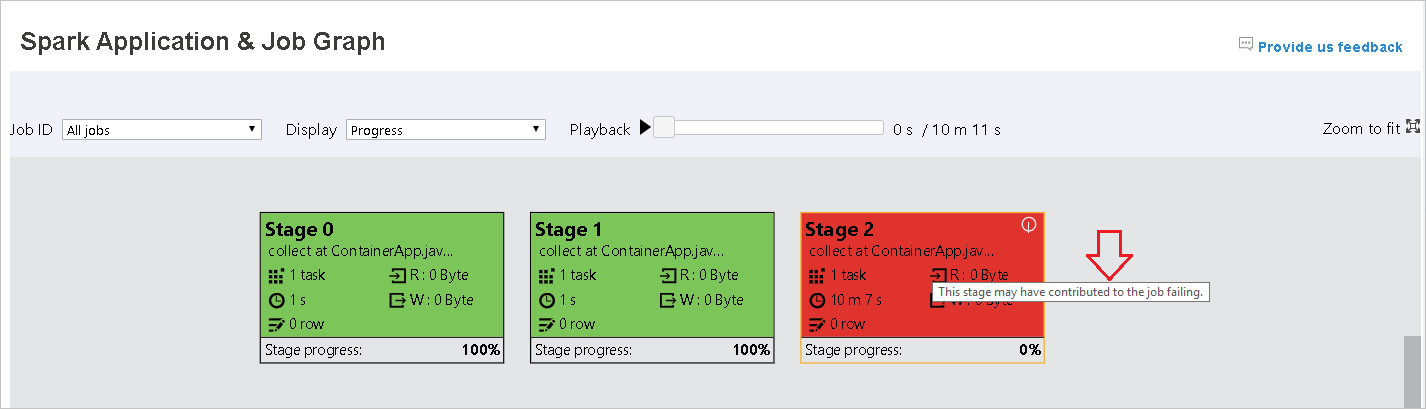
Dans la page Spark Application & Job Graph, les phases affichent des info-bulles et de petites icônes si les tâches remplissent les conditions suivantes :
Asymétrie des données : taille de lecture des données > taille moyenne de lecture des données de toutes les tâches à l’intérieur de cette phase * 2 et taille de lecture des données > 10 Mo.
Asymétrie temporelle : durée d’exécution > durée d’exécution moyenne de toutes les tâches à l’intérieur de cette phase * 2 et durée d’exécution > 2 minutes.
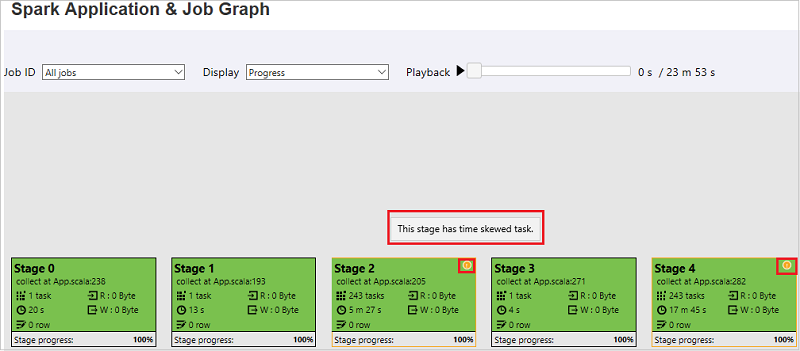
Le nœud du graphe de travail affiche les informations suivantes sur chaque phase :
id
Nom ou description
Nombre total de tâches
Lecture de données : somme de la taille d’entrée et de la taille de lecture aléatoire
Écriture de données : somme de la taille de sortie et de la taille d’écriture aléatoire
Durée d’exécution : durée entre l’heure de début de la première tentative et l’heure de fin de la dernière tentative
Nombre de lignes : somme des enregistrements d’entrée, des enregistrements de sortie, des enregistrements de lecture aléatoire et des enregistrements d’écriture aléatoire
Progress
Notes
Par défaut, le nœud de graphe de travail affiche les informations de la dernière tentative de chaque phase (à l’exception de la durée d’exécution de la phase). Toutefois, pendant la lecture, le nœud de graphe de travail affiche des informations sur chaque tentative.
Notes
Pour les tailles de lecture et d’écriture de données, nous utilisons 1 Mo = 1 000 Ko = 1 000 * 1 000 octets.
Envoyez des commentaires sur les problèmes en sélectionnant Provide us feedback (Envoyez-nous vos commentaires).
Utiliser l’onglet Diagnosis du serveur d’historique Spark
Sélectionnez l’ID de travail, puis sélectionnez Diagnosis dans le menu des outils pour afficher la vue de diagnostic de travail. L’onglet Diagnosis comprend Data Skew (Asymétrie des données), Time Skew (Asymétrie temporelle) et Executor Usage Analysis (Analyse de l’utilisation des exécuteurs).
Examinez l’Asymétrie des données, l’asymétrie temporelle et l’Analyse de l’utilisation de l’exécuteur en sélectionnant respectivement chaque onglet.
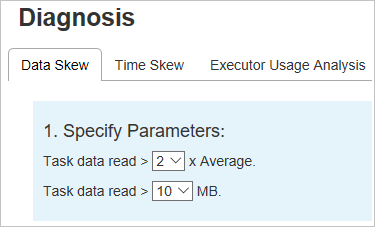
Asymétrie des données
Sélectionnez l’onglet Data Skew (Asymétrie des données). Les tâches asymétriques correspondantes s’affichent en fonction des paramètres spécifiés.
Spécifier les paramètres
La section Specify Parameters (Spécifier les paramètres) affiche les paramètres qui sont utilisés pour détecter l’asymétrie des données. La règle par défaut est : Les données lues de tâche sont supérieures au triple de la moyenne des données lues de tâche, et les données lues de tâche sont supérieures à 10 Mo. Si vous souhaitez définir votre propre règle pour les tâches asymétriques, vous pouvez choisir vos paramètres. Les sections Phase asymétrique et Graphique d’asymétrie sont mises à jour en conséquence.
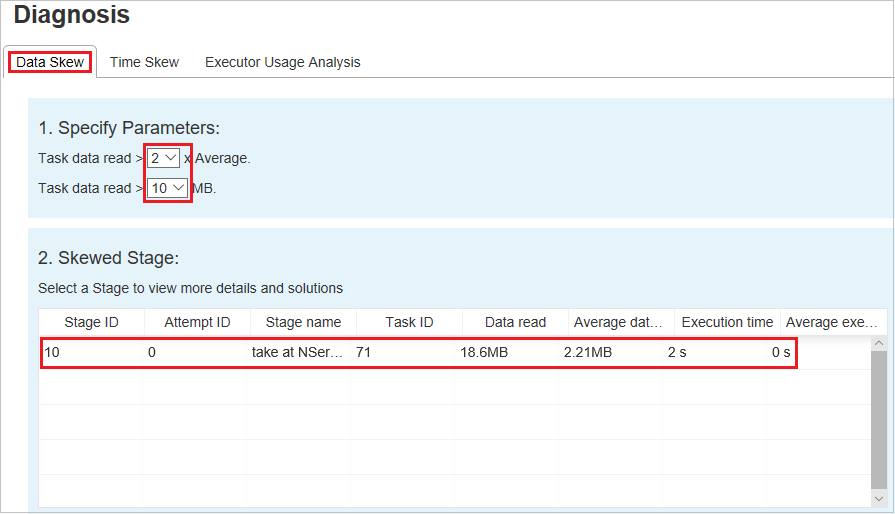
Phase asymétrique
La section Skewed Stage (Phase asymétrique) affiche les phases comportant des tâches asymétriques qui répondent aux critères spécifiés. Si plusieurs tâches asymétriques figurent dans une phase, la section Skewed Stage (Phase asymétrique) affiche uniquement la tâche la plus décalée (à savoir, le plus important volume de données pour l’asymétrie des données).
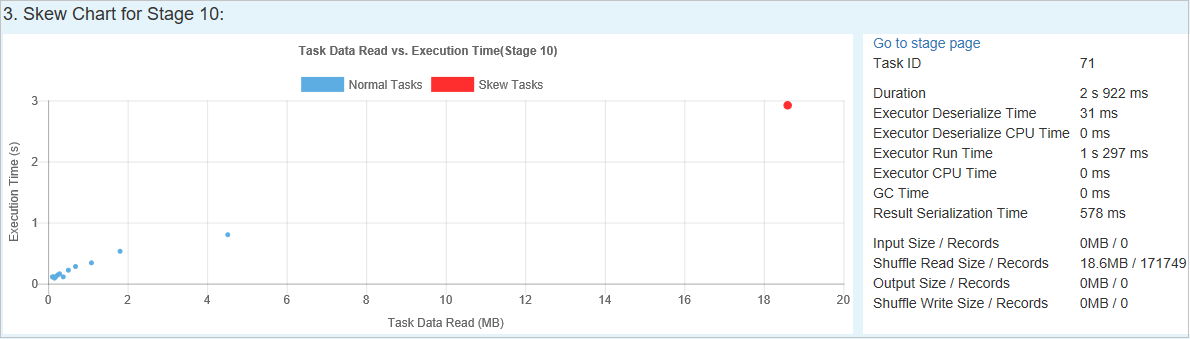
Graphique d’asymétrie
Lorsque vous sélectionnez une ligne de la table Skew Stage (Phase asymétrique), le graphique d’asymétrie affiche plus de détails sur les distributions des tâches en fonction des données lues et de la durée d’exécution. Les tâches asymétriques sont marquées en rouge et les tâches normales sont marquées en bleu. Pour des considérations liées aux performances, le graphique affiche jusqu’à 100 exemples de tâches. Les détails des tâches s’affichent dans le volet inférieur droit.
Asymétrie temporelle
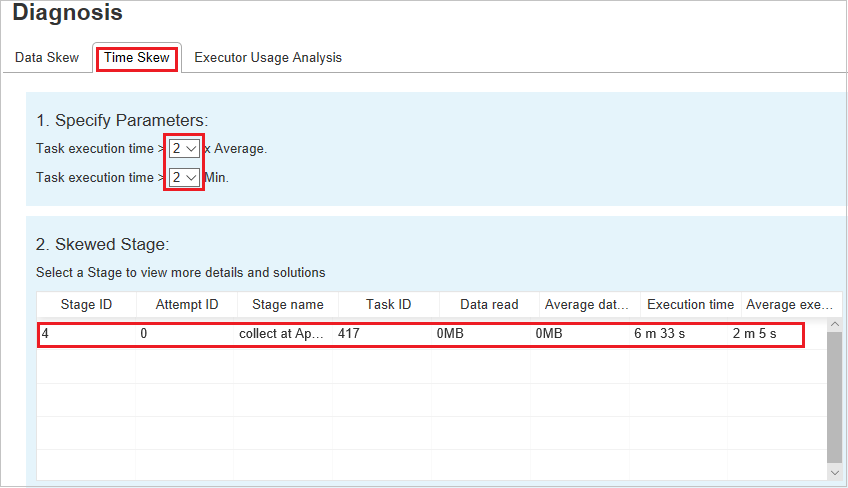
L’onglet Time Skew affiche les tâches asymétriques en fonction de la durée d’exécution des tâches.
Spécifier les paramètres
La section Specify Parameters (Spécifier les paramètres) affiche les paramètres qui sont utilisés pour détecter l’asymétrie temporelle. La règle par défaut est : La durée d’exécution des tâches est plus de trois fois supérieure à la durée d’exécution moyenne et supérieure à 30 secondes. Vous pouvez changer les paramètres en fonction de vos besoins. Les sections Skewed Stage (Phase asymétrique) et Skew Chart (Graphique d’asymétrie) affichent les phases correspondantes et les informations de tâche, tout comme dans l’onglet Data Skew (Asymétrie des données).
Lorsque vous sélectionnez Time Skew (Asymétrie temporelle), le résultat filtré s’affiche dans la section Skewed Stage (Phase asymétrique), en fonction des paramètres définis dans la section Specify Parameters (Spécifier les paramètres). Lorsque vous sélectionnez un élément dans la section Skewed Stage (Phase asymétrique), le graphique correspondant est illustré dans la troisième section et les détails des tâches sont affichés dans le volet inférieur droit.
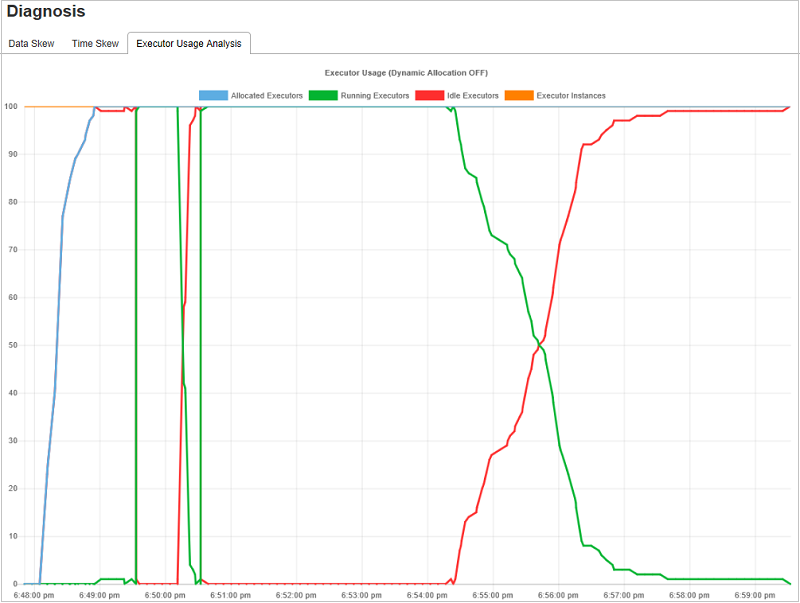
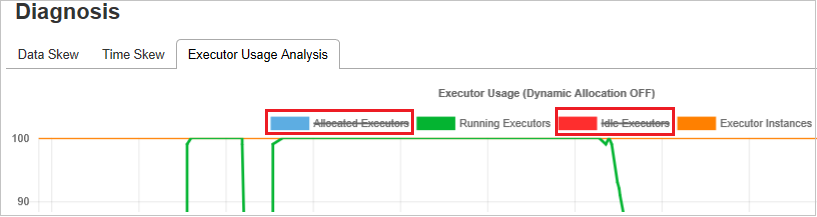
Graphes d’analyse de l’utilisation des exécuteurs
Le graphe de l’utilisation des exécuteurs affiche l’allocation réelle des exécuteurs du travail et leur état d’exécution.
Lorsque vous sélectionnez Executor Usage Analysis (Analyse de l’utilisation des exécuteurs), quatre courbes différentes relatives à l’utilisation des exécuteurs sont tracées : Allocated Executors (Exécuteurs alloués), Running Executors (Exécuteurs en cours d’exécution), Idle Executors (Exécuteurs inactifs) et Max Executor Instances (Nombre maximal d’instances d’exécuteur). Chaque événement d’ajout d’exécuteur ou de suppression d’exécuteur augmente ou diminue le nombre d’exécuteurs alloués. Vous pouvez consulter la chronologie des événements dans l’onglet Jobs (Travaux) pour effectuer d’autres comparaisons.
Sélectionnez l’icône de couleur pour sélectionner ou désélectionner le contenu correspondant dans tous les brouillons.
FAQ
Comment revenir à la version de la communauté ?
Pour revenir à la version de la communauté, suivez les étapes ci-dessous :
Ouvrez le cluster dans Ambari.
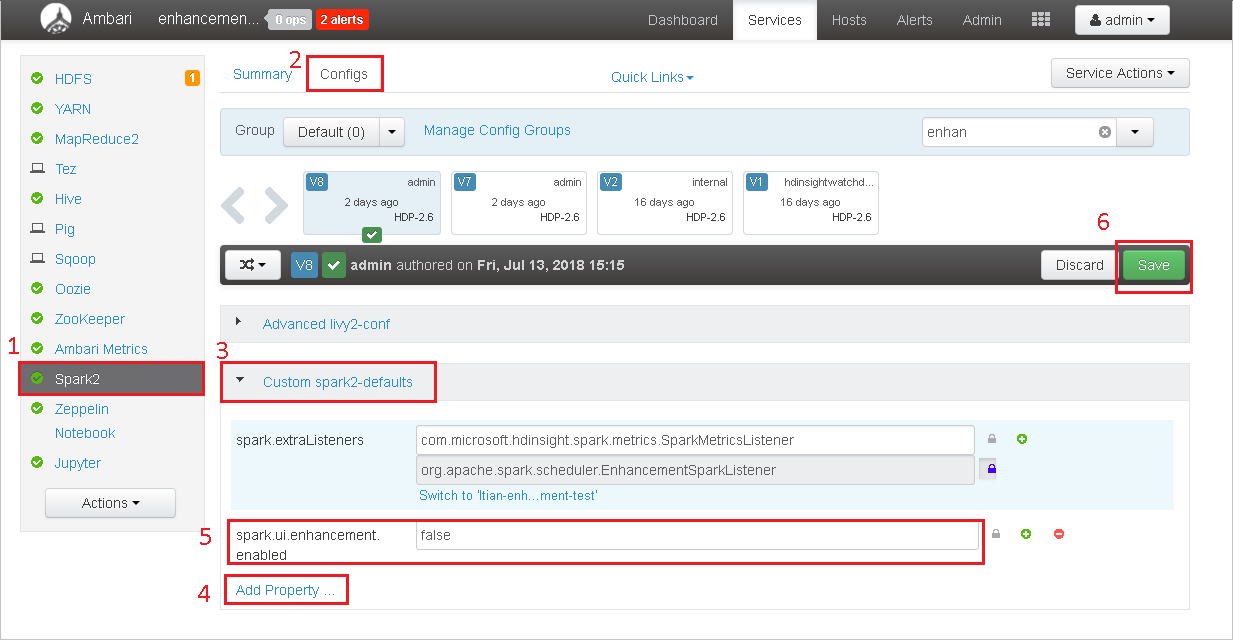
Accédez à Spark2>Configs.
Sélectionnez Custom spark2-defaults (Valeurs spark2-defaults personnalisées).
Sélectionnez Add Property ... (Ajouter une propriété).
Ajoutez spark.ui.enhancement.enabled=false et enregistrez-le.
La propriété est maintenant définie sur false.
Sélectionnez Enregistrer pour enregistrer la configuration.
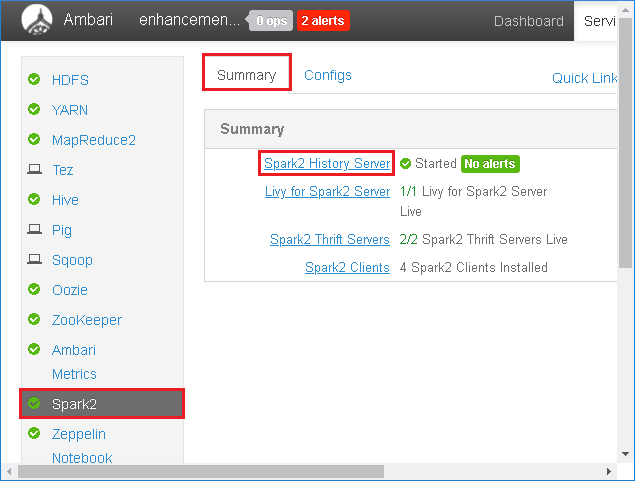
Sélectionnez Spark2 dans le volet gauche. Ensuite, sous l’onglet Summary (Résumé), sélectionnez Spark2 History Server (Serveur d’historique Spark2).
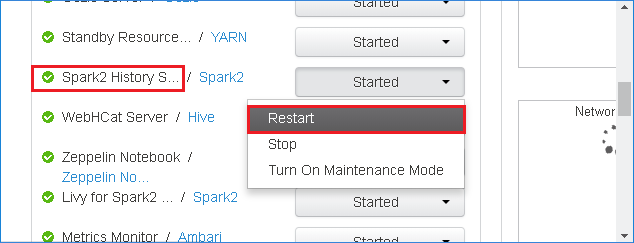
Pour redémarrer le serveur d’historique Spark, sélectionnez le bouton Started (Démarré) à droite de Spark2 History Server (Serveur d’historique Spark2), puis sélectionnez Restart (Redémarrer) dans le menu déroulant.
Actualisez l’interface utilisateur web du serveur d’historique Spark. Il revient à la version de la communauté.
Comment charger un événement de serveur d’historique Spark pour le signaler en tant que problème ?
Si vous rencontrez une erreur au niveau du serveur d’historique Spark, procédez comme suit pour signaler l’événement.
Téléchargez l’événement en sélectionnant Download dans l’interface utilisateur web du serveur d’historique Spark.
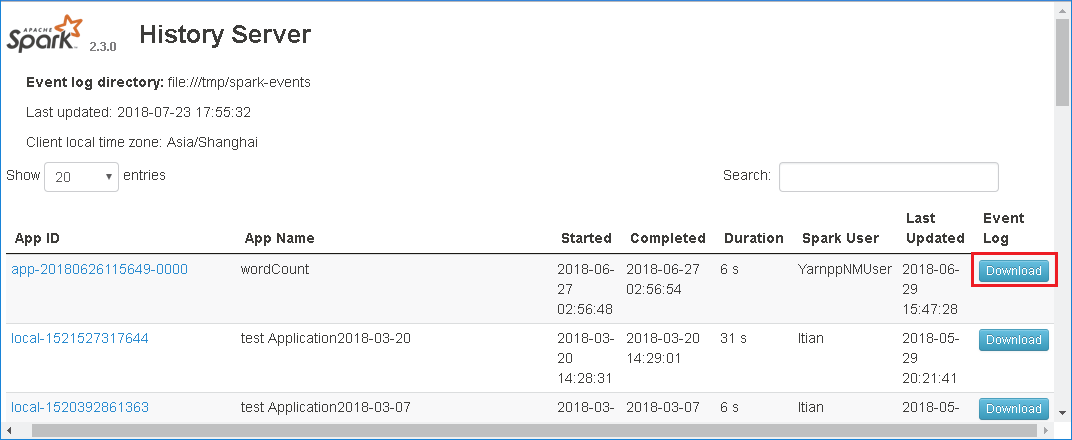
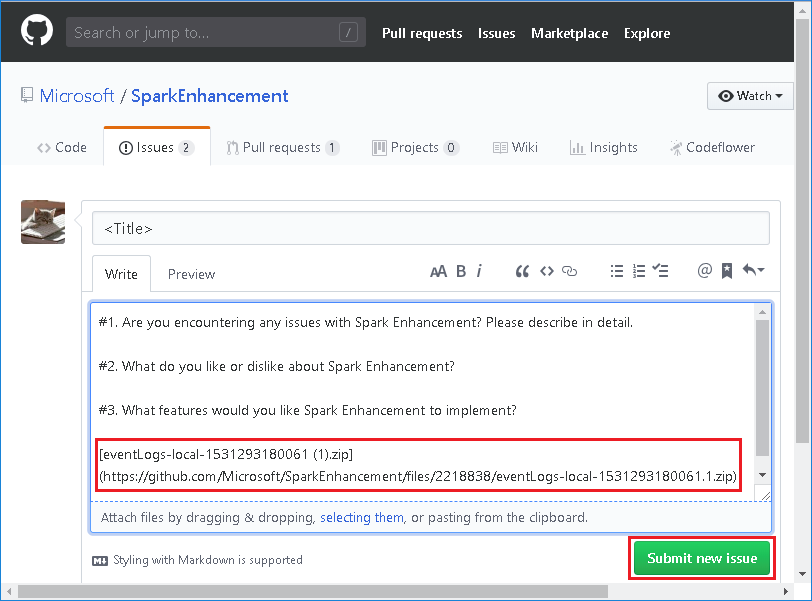
Sélectionnez Provide us feedback (Envoyez-nous vos commentaires) à partir de la page Spark Application & Job Graph (Application Spark et graphe de travail).
Fournissez le titre et une description de l’erreur. Ensuite, faites glisser le fichier .zip vers le champ d’édition et sélectionnez Submit new issue (Envoyer nouveau problème).
Comment mettre à niveau un fichier .jar dans un scénario de correctif logiciel ?
Si vous souhaitez effectuer une mise à niveau avec un correctif logiciel, utilisez le script suivant pour mettre à niveau spark-enhancement.jar*.
upgrade_spark_enhancement.sh :
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Usage
upgrade_spark_enhancement.sh https://${jar_path}
Exemple
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Utiliser le fichier Bash à partir du Portail Azure
Lancez le Portail Azure, puis sélectionnez votre cluster.
Exécutez une action de script avec les paramètres ci-dessous.
Propriété Valeur Type de script - Personnalisé Nom UpgradeJar URI de script bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shType(s) de nœud Head, Worker Paramètres https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar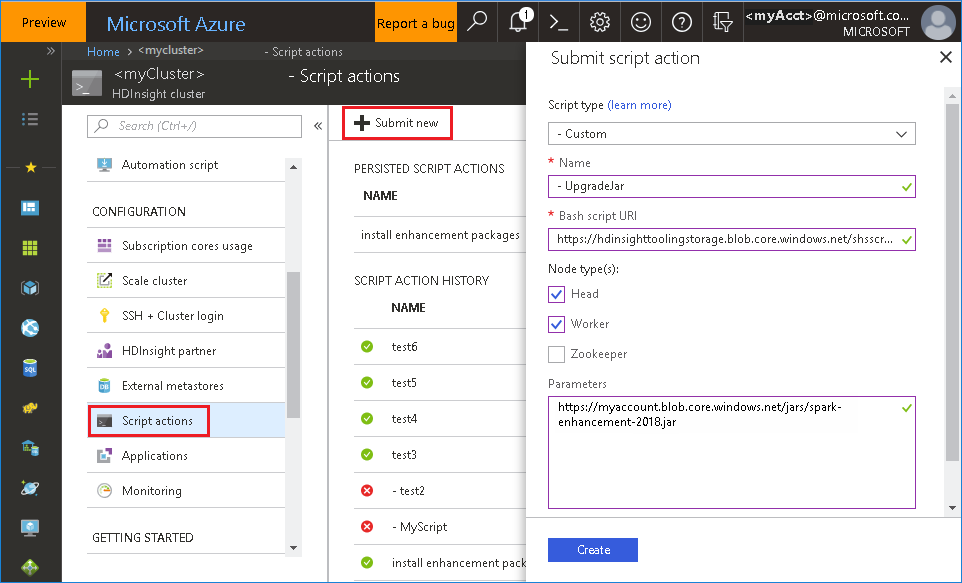
Problèmes connus
Actuellement, le serveur d’historique Spark fonctionne uniquement pour Spark 2.3 et 2.4.
Les données d’entrée et de sortie qui utilisent RDD ne s’affichent pas sous l’onglet Data.
Étapes suivantes
- Gérer les ressources d’un cluster Apache Spark sur HDInsight
- Configurer les paramètres d’Apache Spark
Suggestions
Si vous avez des commentaires ou rencontrez des problèmes lors de l’utilisation de cet outil, envoyez un e-mail à (hdivstool@microsoft.com).