Entraîner le composant de modèle
Cet article décrit un composant dans le concepteur Azure Machine Learning.
Utilisez ce composant pour effectuer l’apprentissage d’un modèle de classification ou de régression. La formation a lieu une fois que vous avez défini un modèle et ses paramètres et nécessite des données avec balises. Vous pouvez également utiliser le module Train Model (Entraîner le modèle) pour effectuer l’apprentissage d’un modèle existant avec de nouvelles données.
Fonctionnement du processus de formation
Dans Azure Machine Learning, la création et l’utilisation d’un modèle Machine Learning s’effectuent généralement en trois étapes.
Vous configurez un modèle en choisissant un type d’algorithme particulier et en définissant ses paramètres ou hyperparamètres. Choisissez l’un des types de modèles suivants :
- Modèles de classification, basée sur les réseaux neuronaux, arbres de décision, forêts de décision et autres algorithmes
- Modèles de régression, qui peuvent inclure une régression linéaire standard ou qui utilisent d’autres algorithmes, notamment les réseaux neuronaux et la régression bayésienne
Fournissez un jeu de données doté d’une étiquette et dont les données sont compatibles avec l’algorithme. Connectez les données et le modèle au module Train Model (Entraîner le modèle).
La formation produit un format binaire spécifique, l’iLearner, qui encapsule les modèles statistiques appris à partir des données. Vous ne pouvez pas modifier ou lire ce format directement. Toutefois, les autres composants peuvent utiliser ce modèle formé.
Vous pouvez également afficher les propriétés du modèle. Pour plus d’informations, consultez la section Résultats.
Au terme de la formation, utilisez le modèle formé avec l’un des composants de scoring pour effectuer des prédictions sur de nouvelles données.
Comment utiliser le module Effectuer l’apprentissage du modèle
Ajoutez le composant Effectuer l’apprentissage du modèle au pipeline. Ce composant figure dans la catégorie Machine Learning. Développez la section Effectuer l’apprentissage, puis faites glisser le composant Effectuer l’apprentissage du modèle dans votre pipeline.
Sous l’entrée de gauche, joignez le modèle non formé. Joignez le jeu de données d’apprentissage à l’entrée droite du module Train Model (Entraîner le modèle).
Le jeu de données d’apprentissage doit contenir une colonne d’étiquette. Toutes les lignes sans étiquette sont ignorées.
Pour Étiqueter la colonne, cliquez sur Modifier la colonne dans le volet droit du composant, puis choisissez une seule colonne contenant les résultats que le modèle peut utiliser pour la formation.
Pour les problèmes de classification, la colonne d’étiquette doit contenir des valeurs catégorielles ou discrètes. Il peut s’agir, par exemple, d’une évaluation oui/non, d’un code ou nom de classification de maladie ou d’un groupe de revenus. Si vous choisissez une colonne non catégorielle, le composant renverra une erreur pendant la formation.
Pour les problèmes de régression, la colonne d’étiquette doit contenir des données numériques qui représentent la variable de réponse. Dans l’idéal, les données numériques représentent une échelle continue.
Il peut s’agir, par exemple, de l’évaluation du risque de crédit, du temps entre deux pannes escompté pour un disque dur ou du nombre prévu d’appels à un centre d’appels sur une journée ou à une heure donnée. Si vous ne choisissez pas une colonne numérique, une erreur peut se produire.
- Si vous ne spécifiez pas la colonne d’étiquette à utiliser, Azure Machine Learning tente de déduire la colonne appropriée en utilisant les métadonnées du jeu de données. S’il choisit la mauvaise colonne, utilisez le sélecteur de colonne pour résoudre ce problème.
Conseil
Si vous avez des difficultés à utiliser le sélecteur de colonne, consultez l’article Sélectionner des colonnes dans le jeu de données pour obtenir des conseils. Il décrit quelques scénarios courants et fournit des conseils pour utiliser les options WITH RULES (Avec règles) et BY NAME (Par nom).
Envoyez le pipeline. Si vous avez une grande quantité de données, cela peut prendre un certain temps.
Important
Si vous avez une colonne d’ID qui correspond à l’ID de chaque ligne, ou une colonne de texte, qui contient trop de valeurs uniques, le module Entraîner le modèle peut retourner une erreur telle que « Le nombre de valeurs uniques dans la colonne : « {nom_colonne} » est supérieur à la valeur autorisée ».
Cela est dû au fait que la colonne a atteint le seuil de valeurs uniques, ce qui peut entraîner une insuffisance de mémoire. Vous pouvez utiliser Modifier les métadonnées pour marquer cette colonne comme Effacer la caractéristique afin qu’elle ne soit pas utilisée durant l’entraînement, ou le composant d’extraction des caractéristiques de N-grammes du texte pour prétraiter la colonne de texte. Pour plus d’informations sur l’erreur, consultez Codes d’erreur pour le concepteur.
Interprétabilité du modèle
L’interprétabilité du modèle permet de comprendre le modèle ML et de présenter la base sous-jacente de la prise de décision d’une manière compréhensible pour les humains.
Actuellement, le composant Effectuer l’apprentissage du modèle prend en charge l’utilisation du package d’interprétabilité pour expliquer les modèles ML. Les algorithmes intégrés suivants sont pris en charge :
- Régression linéaire
- Régression de réseau neuronal
- Régression d’arbre de décision optimisé
- Régression de forêt d’arbres décisionnels
- Régression de Poisson
- Régression logistique à deux classes
- Machine à vecteurs de support à deux classes
- Arbre de décision optimisé à deux classes
- Forêt d’arbres décisionnels à deux classes
- Forêt d’arbres de décision multiclasse
- Régression logistique multiclasse
- Réseau neuronal multiclasse
Pour générer des explications de modèle, vous pouvez sélectionner Vrai dans la liste déroulante de l’option Explication de modèle dans le composant Effectuer l’apprentissage du modèle. Par défaut, elle est définie sur False dans le composant Effectuer l’apprentissage du modèle. Notez que la génération d’explications nécessite un coût de calcul supplémentaire.
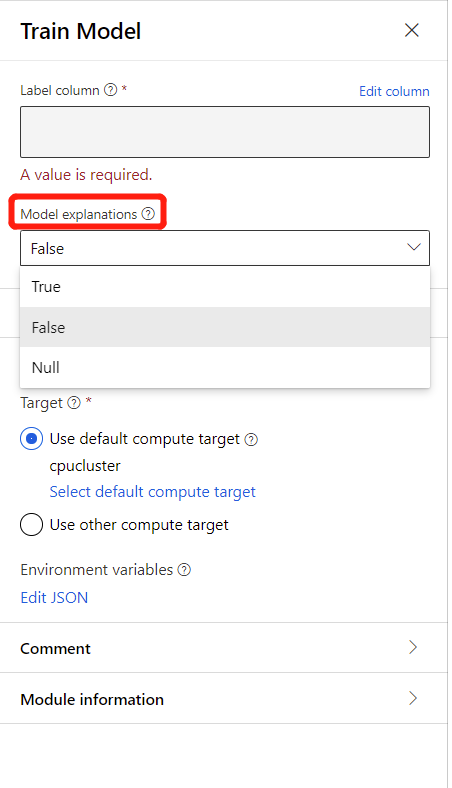
Une fois l’exécution du pipeline terminée, vous pouvez consulter l’onglet Explications dans le volet droit du composant Effectuer l’apprentissage du modèle et explorer les performances du modèle, le jeu de données et l’importance des fonctionnalités.
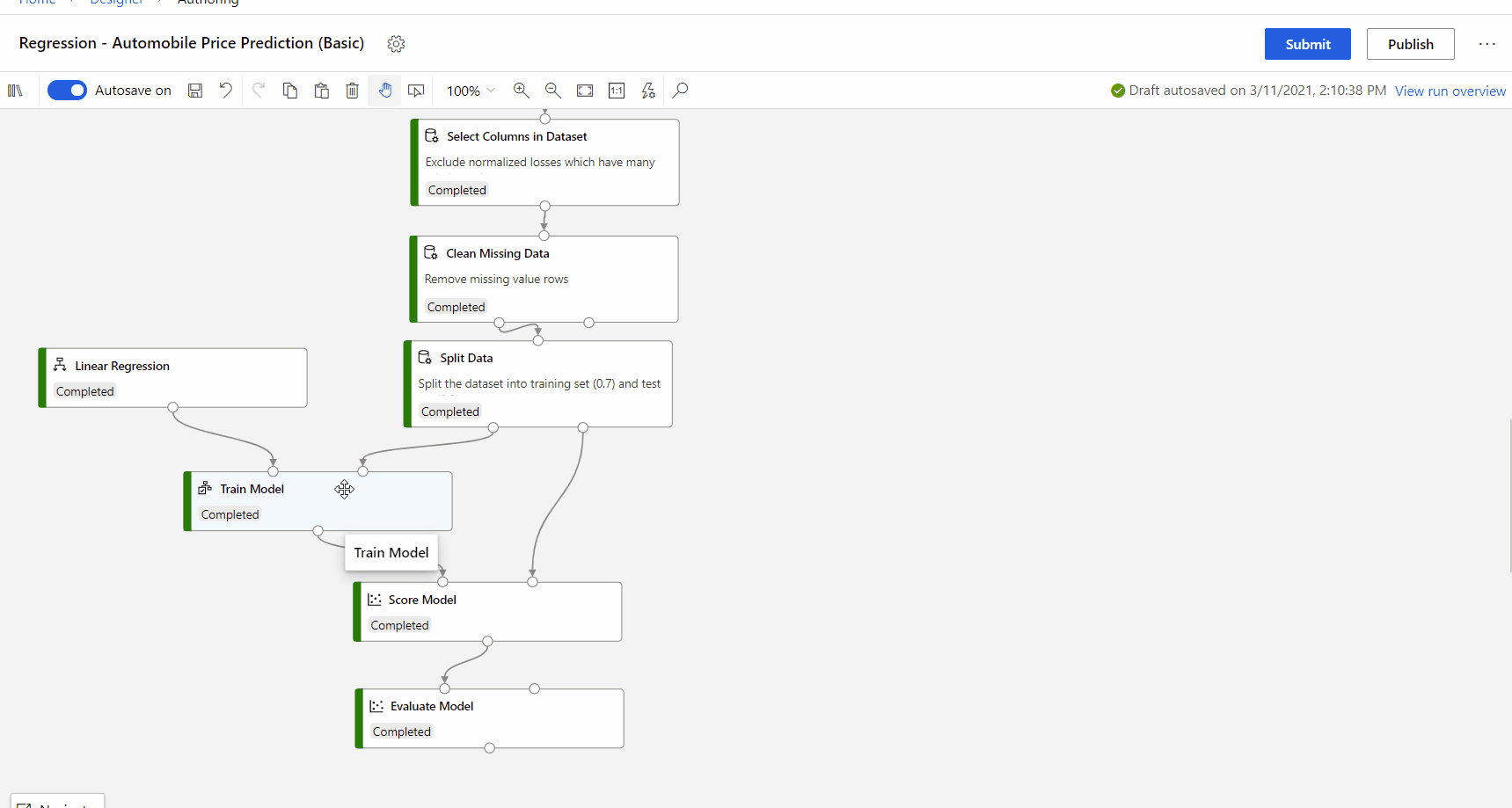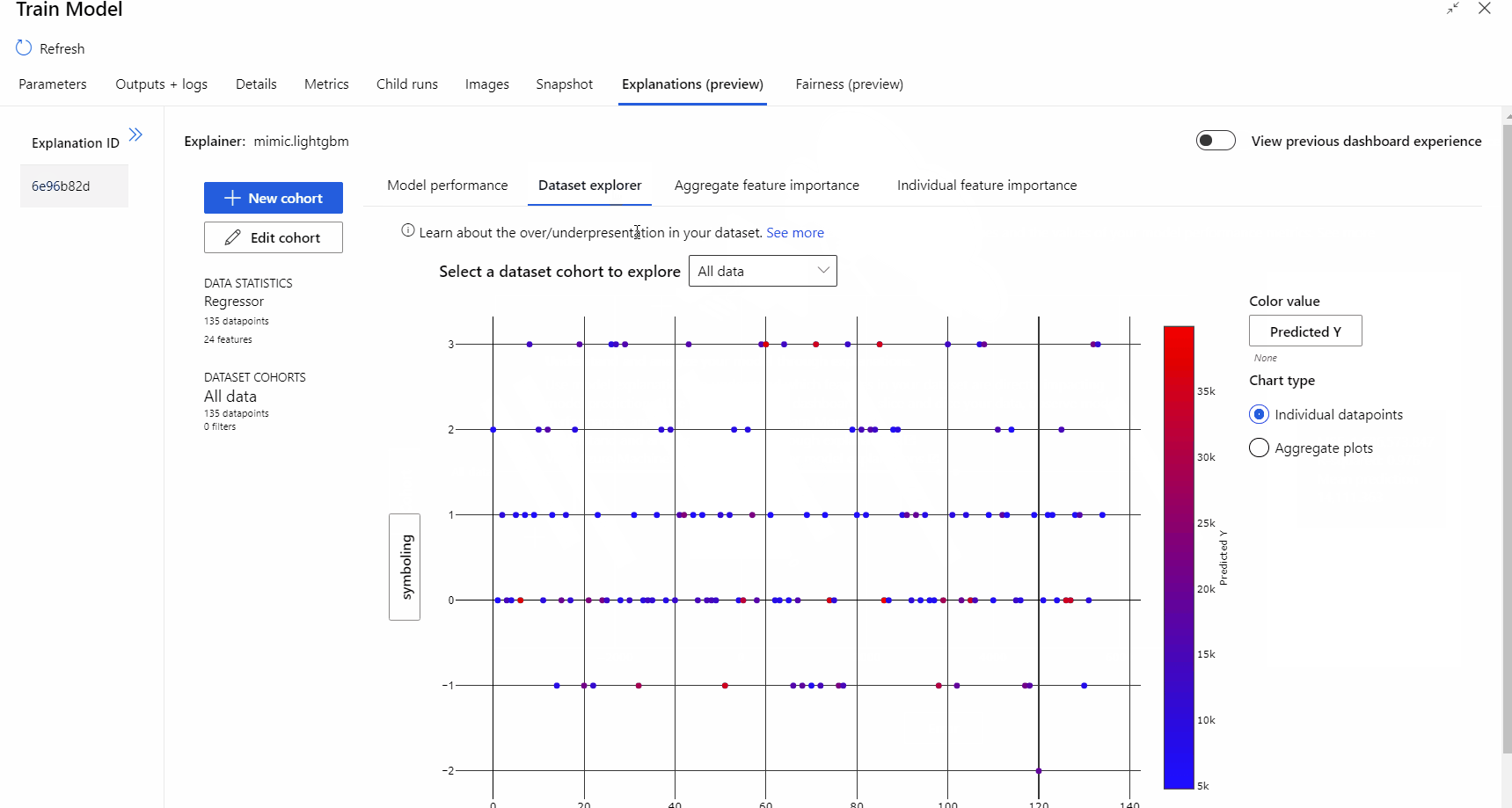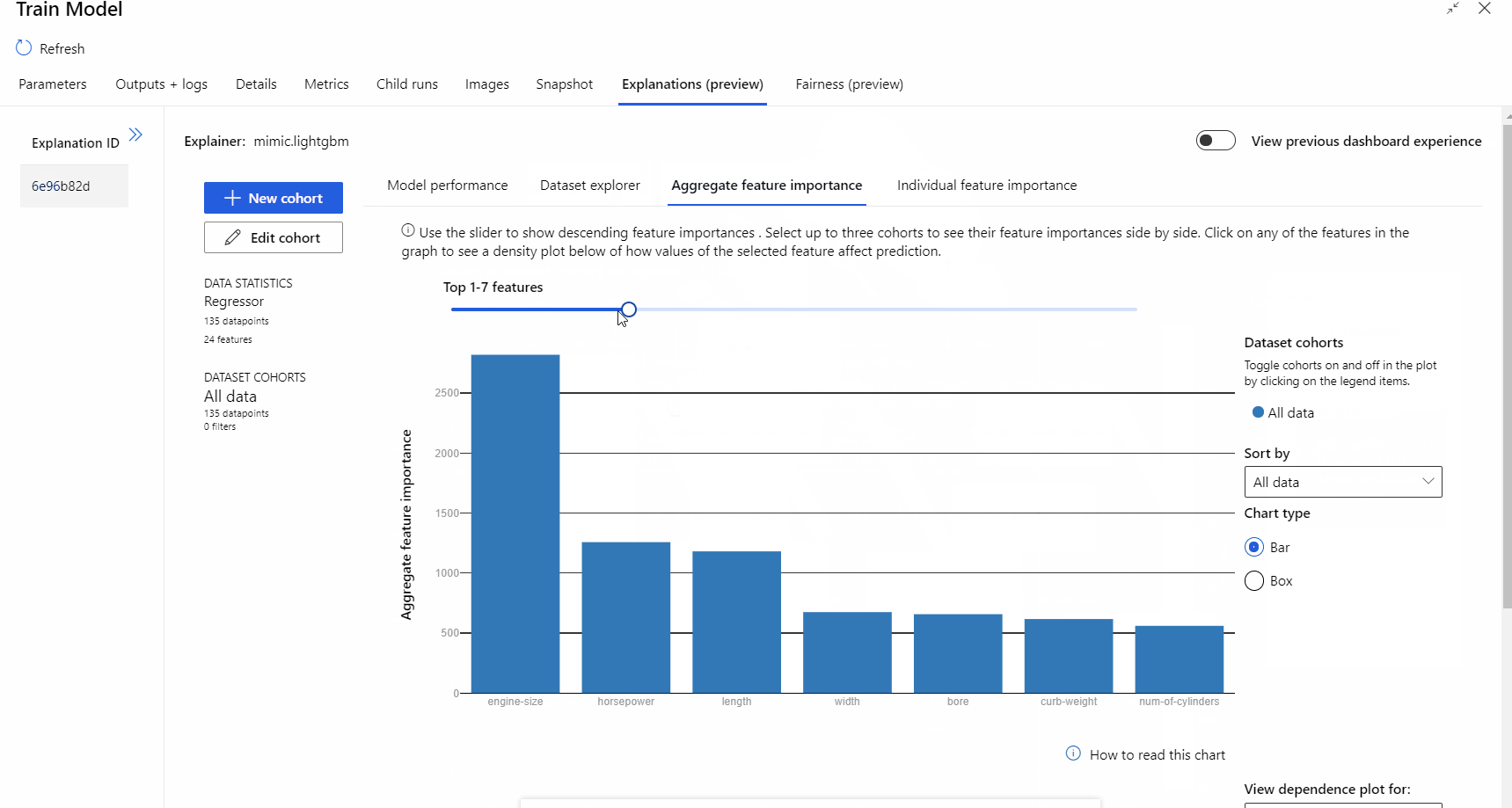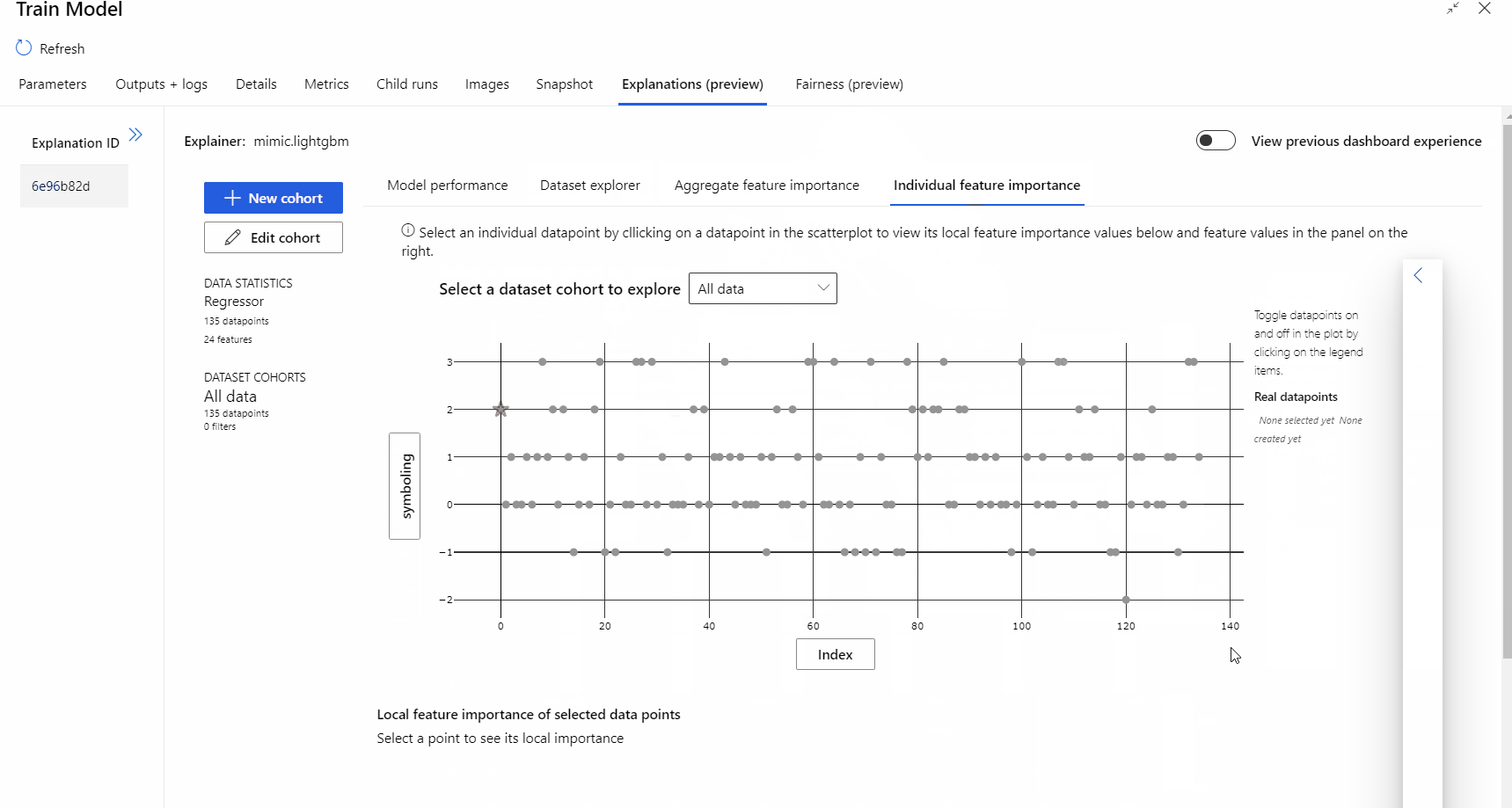
Pour en savoir plus sur l’utilisation des explications de modèle dans Azure Machine Learning, consultez le guide pratique relatif à l’interprétation des modèles ML.
Résultats
Une fois le modèle formé :
Pour utiliser le modèle dans d’autres pipelines, sélectionnez le composant et l’icône Inscrire le jeu de données sous l’onglet Sorties dans le panneau droit. Vous pouvez accéder aux modèles enregistrés dans la palette de composants sous Jeux de données.
Afin d’utiliser le modèle pour la prédiction de nouvelles valeurs, connectez-le au composant Score Model (Noter le modèle) avec les nouvelles données d’entrée.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.