Points de terminaison batch
Azure Machine Learning vous permet d’implémenter des points de terminaison et des déploiements par lots pour effectuer une inférence asynchrone de longue durée avec des modèles et des pipelines Machine Learning. Lorsque vous entraînez un modèle ou un pipeline Machine Learning, vous devez le déployer pour que d’autres puissent l’utiliser avec de nouvelles données d’entrée pour générer des prédictions. Ce processus de génération de prédictions avec le modèle ou le pipeline est appelé inférence.
Les points de terminaison de traitement de lots reçoivent des pointeurs vers les données et exécutent les tâches de façon asynchrone pour traiter les données en parallèle sur les clusters de calcul. Les points de terminaison de traitement de lots stockent les sorties dans un magasin de données en vue d’une analyse plus approfondie. Utilisez des points de terminaison de traitement par lots dans les cas suivants :
- Vous disposez de modèles ou de pipelines coûteux qui nécessitent un temps d’exécution plus long.
- Vous souhaitez rendre opérationnels les pipelines Machine Learning et réutiliser les composants.
- Vous devez effectuer une inférence sur de grandes quantités de données, distribuées dans plusieurs fichiers.
- Vous n’avez pas d’exigences de faible latence.
- Les entrées de votre modèle sont stockées dans un compte de stockage ou dans une ressource de données Azure Machine Learning.
- Vous pouvez tirer parti de la parallélisation.
Déploiements par lots
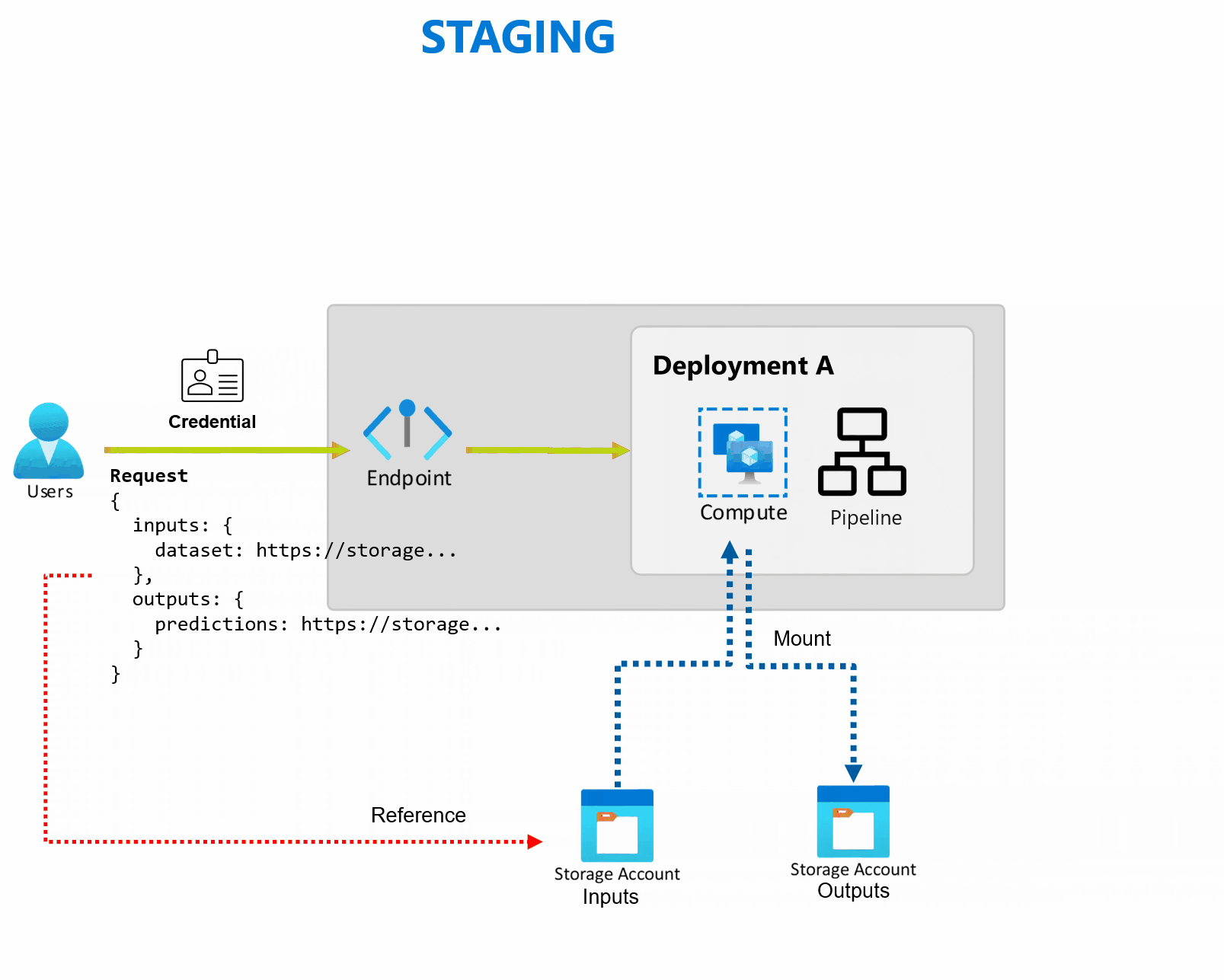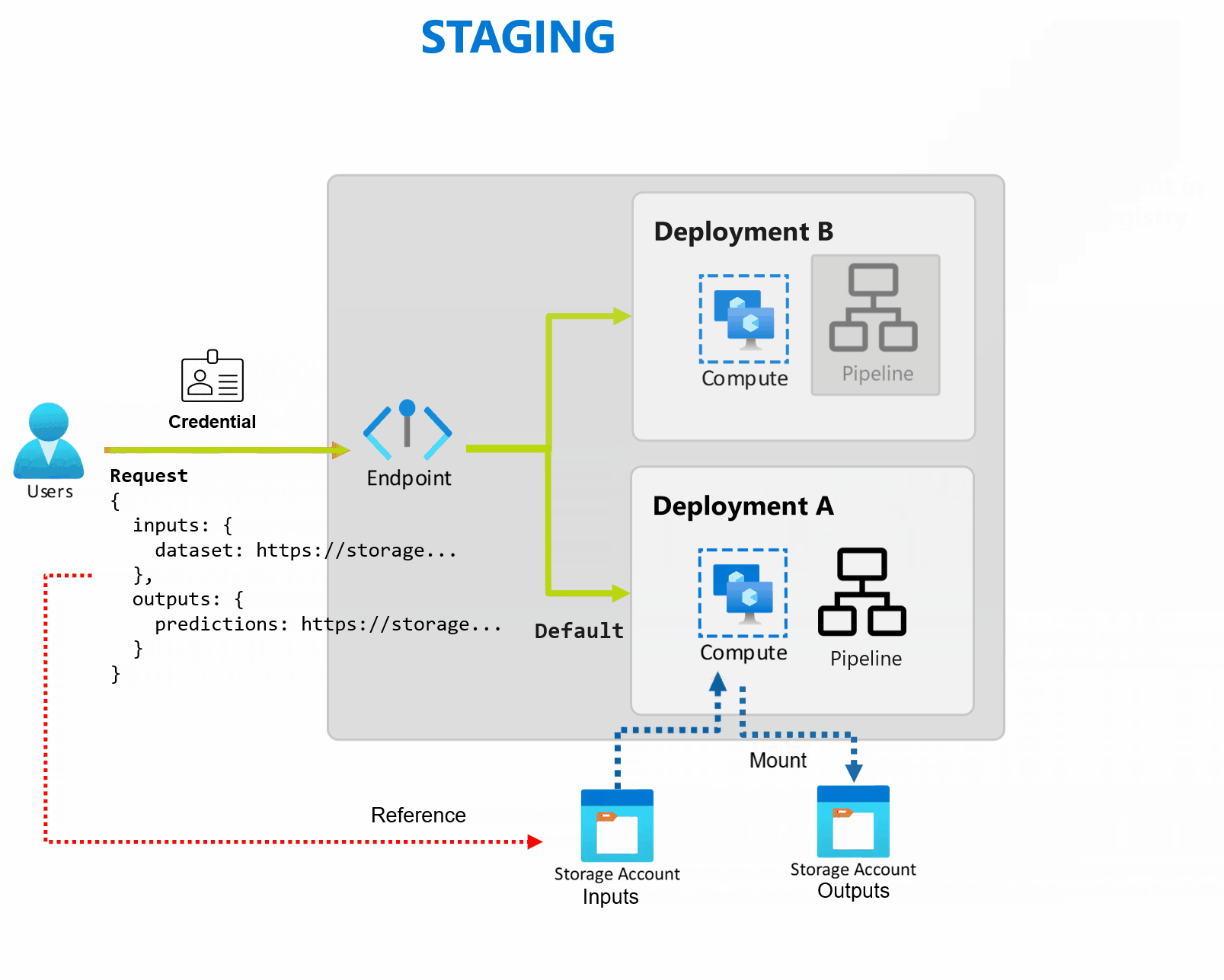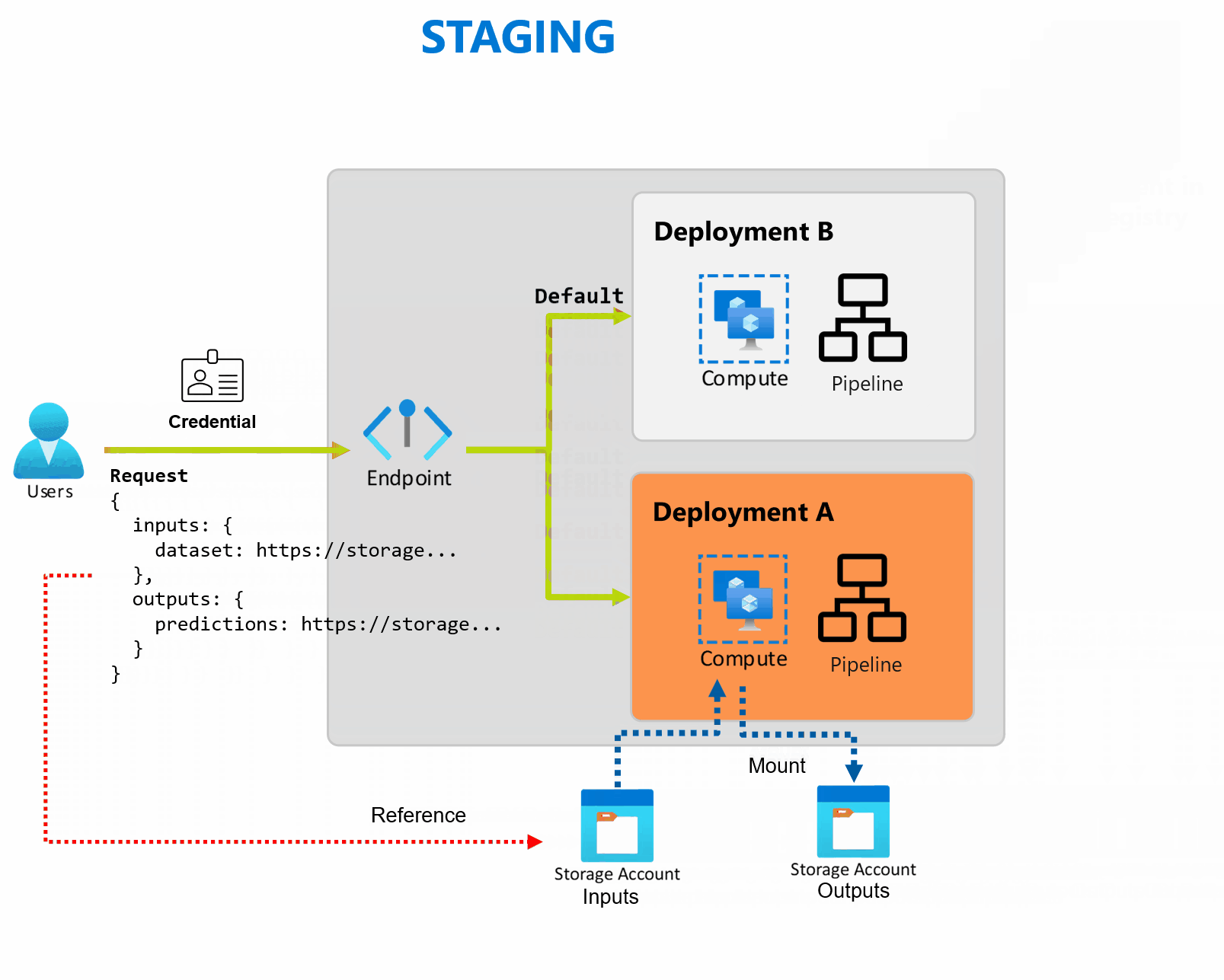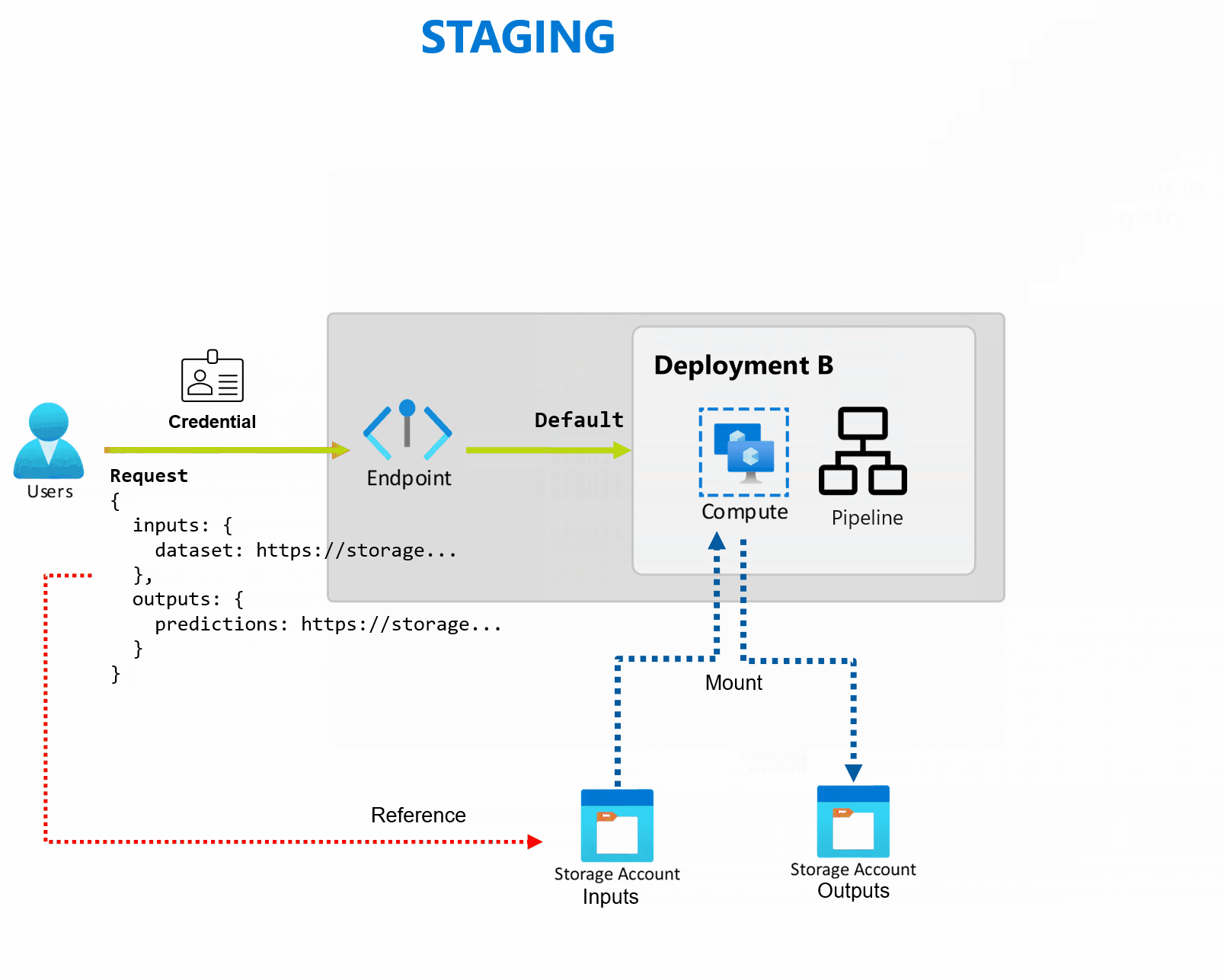
Un déploiement est un ensemble de ressources et de calculs requis pour implémenter la fonctionnalité fournie par le point de terminaison. Chaque point de terminaison peut héberger plusieurs déploiements avec des configurations différente, et cette fonctionnalité permet de dissocier l’interface du point de terminaison des détails d'implémentation définis par le déploiement. Lorsqu’un point de terminaison par lots est appelé, il achemine automatiquement le client vers son déploiement par défaut. Ce déploiement par défaut peut être configuré et modifié à tout moment.

Deux types de déploiements sont possibles dans les points de terminaison par lots Azure Machine Learning :
Déploiement de modèle
Le modèle de déploiement permet l’opérationnalisation de l’inférence de modèle à grande échelle, ce qui vous permet de traiter de grandes quantités de données de manière asynchrone et à faible latence. Azure Machine Learning instrumente automatiquement la scalabilité en fournissant une parallélisation des processus d’inférence sur plusieurs nœuds d’un cluster de calcul.
Utilisez un modèle de déploiement dans les cas suivants :
- Vous disposez de modèles coûteux qui nécessitent plus de temps pour exécuter l’inférence.
- Vous devez effectuer une inférence sur de grandes quantités de données, distribuées dans plusieurs fichiers.
- Vous n’avez pas d’exigences de faible latence.
- Vous pouvez tirer parti de la parallélisation.
L’avantage principal des modèles de déploiements est que vous pouvez utiliser les mêmes ressources que celles déployées pour l’inférence en temps réel sur des points de terminaison en ligne, mais maintenant, vous pouvez les exécuter à grande échelle par lots. Si votre modèle nécessite un prétraitement ou un post-traitement simple, vous pouvez créer un script de scoring qui effectue les transformations de données requises.
Pour créer un modèle de déploiement dans un point de terminaison de lot, vous devez spécifier les éléments suivants :
- Modèle
- Cluster de calcul
- Script de scoring (facultatif pour les modèles MLflow)
- Environnement (facultatif pour les modèles MLflow)
Déploiement de composant de pipeline
Le déploiement de composants de pipeline permet l’opérationnalisation de graphiques de traitement entiers (ou pipelines) pour effectuer l'inférence par lots de manière asynchrone et à faible latence.
Utilisez les déploiements de composants de pipeline dans les cas suivants :
- Vous devez rendre opérationnels des graphiques de calcul complets qui peuvent être décomposés en plusieurs étapes.
- Vous devez réutiliser les composants des pipelines d'entraînement dans votre pipeline d'inférence.
- Vous n’avez pas d’exigences de faible latence.
L'avantage majeur des déploiements de composants de pipelines est la possibilité de réutilisation de composants déjà existants dans votre plateforme et la possibilité d'opérationnaliser des routines d’inférence complexes.
Pour créer un déploiement de composants de pipeline dans un point de terminaison par lot, vous devez spécifier les éléments suivants :
- Composant de pipeline
- Configuration de clusters de calcul
Les points de terminaison par lots vous permettent également de créer des déploiements de composants de pipelines depuis un travail de pipeline existant. Lors de cette action, Azure Machine Learning crée automatiquement un composant de pipeline depuis le travail. Cela simplifie l'utilisation de ces types de déploiements. Toutefois, nous vous recommandons de toujours créer explicitement des composants de pipelines pour simplifier votre pratique MLOps.
Gestion des coûts
L’appel d’un point de terminaison de traitement de lots déclenche un travail d’inférence par lot asynchrone. Azure Machine Learning approvisionne automatiquement des ressources de calcul au démarrage du travail, puis les libère à la fin du travail. Ainsi, vous payez le calcul uniquement quand vous l’utilisez.
Conseil
Lors du déploiement de modèles, vous pouvez écraser les paramètres de ressource de calcul (comme le nombre d’instances) et les paramètres avancés (tels que la taille des mini-lots, le seuil d’erreur, et bien plus encore) pour chaque travail d’inférence par lots. En tirant parti de ces configurations spécifiques, vous pourrez sans doute accélérer l’exécution, puis réduire les coûts.
Les points de terminaison par lots peuvent également s’exécuter sur des machines virtuelles de basse priorité. Les points de terminaison par lot peuvent effectuer une récupération automatique à partir de machines virtuelles désallouées et reprendre le travail à partir du point où il s'est arrêté lors du déploiement de modèles pour l'inférence. Si vous souhaitez en savoir plus sur l’utilisation de machines virtuelles de basse priorité pour réduire le coût des charges de travail d’inférence par lots, veuillez consulter la rubrique Utiliser des machines virtuelles de faible priorité dans des points de terminaison par lots.
Enfin, Azure Machine Learning ne vous facture pas les points de terminaison par lots ou les déploiements par lots proprement dits. Vous pouvez donc organiser vos points de terminaison et vos déploiements en fonction de votre scénario. Les points de terminaison et les déploiements peuvent utiliser des clusters indépendants ou partagés, ce qui vous offre un contrôle précis du calcul que consomment les travaux. Utilisez la mise à l’échelle à zéro dans les clusters pour vérifier qu’aucune ressource n’est consommée quand ils sont inactifs.
Simplifier la pratique MLOps
Les points de terminaison de lot peuvent gérer plusieurs déploiements sous le même point de terminaison, ce qui vous permet de modifier l’implémentation du point de terminaison sans modifier l’URL que vos consommateurs utilisent pour l’appeler.
Vous pouvez ajouter, supprimer et mettre à jour des déploiements sans affecter le point de terminaison lui-même.
Sources de données et stockage flexibles
Les points de terminaison par lots lisent et écrivent directement les données dans le stockage. Vous pouvez spécifier des magasins de données Azure Machine Learning, une ressource de données Azure Machine Learning ou des comptes de stockage en tant qu’entrées. Si vous souhaitez en savoir plus sur les options d’entrées prises en charge et sur la façon de les spécifier, veuillez consulter la rubrique Créer des tâches et des données d’entrée dans des points de terminaison par lots.
Sécurité
Les points de terminaison par lot fournissent toutes les fonctionnalités requises pour exploiter les charges de travail de niveau production dans un environnement d'entreprise. Ils prennent en charge la mise en réseau privée sur les espaces de travail sécurisés et l’authentification Microsoft Entra, à l'aide d'un principal d'utilisateur (comme un compte d'utilisateur) ou d'un principal de service (comme une identité managée ou non managée). Les tâches générées par un point de terminaison par lots s’exécutent sous l’identité de l’appelant, ce qui vous permet d’implémenter n’importe quel scénario. Si vous souhaitez en savoir plus sur l’autorisation lors de l’utilisation de points de terminaison par lots, veuillez consulter la rubrique Comment s’authentifier sur les points de terminaison par lots.
Contenu connexe
- Déployer des modèles avec des points de terminaison par lot
- Déployer des pipelines avec des points de terminaison de lot
- Déployer des modèles MLFlow dans les déploiements par lot
- Créer des tâches et des données d'entrée dans des points de terminaison par lot
- Isolement réseau dans les points de terminaison par lot