Packages de modèles pour le déploiement (préversion)
Après avoir entraîné un modèle Machine Learning, vous devez le déployer afin que d’autres utilisateurs puissent se servir de ses prédictions. Toutefois, le déploiement d’un modèle nécessite plus que les poids ou les artefacts du modèle. Les packages de modèle sont une fonctionnalité dans Azure Machine Learning qui vous permet de collecter toutes les dépendances requises pour déployer un modèle Machine Learning sur une plateforme de service. Vous pouvez déplacer des packages entre des espaces de travail et même en dehors d’Azure Machine Learning.
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Qu’est-ce qu’un package de modèle ?
En tant que meilleure pratique avant de déployer un modèle, toutes les dépendances requises par le modèle pour s’exécuter correctement doivent être collectées et résolues afin que vous puissiez déployer le modèle selon une approche reproductible et robuste.

En règle générale, les dépendances d’un modèle sont les suivantes :
- Image de base ou environnement dans lequel votre modèle est exécuté.
- Liste des packages et dépendances Python dont dépend le modèle pour fonctionner correctement.
- Des ressources supplémentaires dont votre modèle peut avoir besoin pour générer l’inférence. Ces ressources peuvent inclure les mappages d’étiquettes et les paramètres de prétraitement.
- Logiciel requis pour que le serveur d’inférence traite les demandes ; par exemple, le serveur flask ou le service TensorFlow.
- Routine d’inférence (si nécessaire).
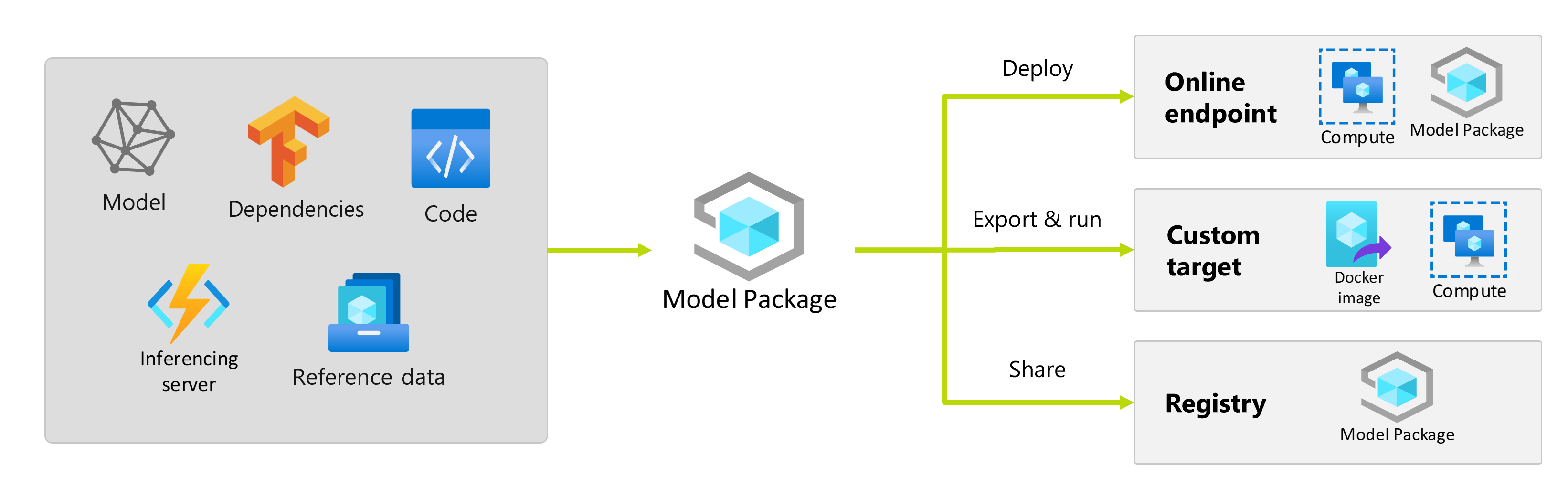
Tous ces éléments doivent être collectés pour être ensuite déployés dans l’infrastructure de service. La ressource résultante générée après avoir collecté toutes les dépendances est appelée package de modèle.
Avantages de l’empaquetage des modèles
L’empaquetage des modèles avant le déploiement présente les avantages suivants :
- Reproductibilité : toutes les dépendances sont collectées au moment de l’empaquetage, plutôt que dans le temps de déploiement. Une fois les dépendances résolues, vous pouvez déployer le package autant de fois que nécessaire tout en garantissant que les dépendances ont déjà été résolues.
- Résolution plus rapide des conflits : Azure Machine Learning détecte les configurations incorrectes liées aux dépendances, comme un package Python manquant, tout en empaquetant le modèle. Vous n’avez pas besoin de déployer le modèle pour détecter de tels problèmes.
- Intégration plus facile au serveur d’inférence : étant donné que le serveur d’inférence que vous utilisez peut avoir besoin de configurations logicielles spécifiques (par exemple, le package Torch Serve), ce logiciel peut générer des conflits avec les dépendances de votre modèle. Les packages de modèle dans Azure Machine Learning injectent les dépendances requises par le serveur d’inférence pour vous aider à détecter les conflits avant de déployer un modèle.
- Portabilité : vous pouvez déplacer des packages de modèles Azure Machine Learning d’un espace de travail vers un autre, à l’aide de registres. Vous pouvez également générer des packages qui peuvent être déployés en dehors d’Azure Machine Learning.
- Prise en charge de MLflow avec des réseaux privés : pour les modèles MLflow, Azure Machine Learning nécessite une connexion Internet pour pouvoir installer dynamiquement les packages Python nécessaires pour que les modèles s’exécutent. En empaquetant des modèles MLflow, ces packages Python sont résolus pendant l’opération d’empaquetage de modèle, afin que le package de modèle MLflow ne nécessite pas de connexion Internet à déployer.
Conseil
L’empaquetage d’un modèle MLflow avant le déploiement est fortement recommandé et même nécessaire pour les points de terminaison qui n’ont pas de connectivité réseau sortante. Un modèle MLflow indique ses dépendances dans le modèle lui-même, nécessitant ainsi une installation dynamique des packages. Lorsqu’un modèle MLflow est empaqueté, cette installation dynamique est effectuée au moment de l’empaquetage plutôt qu’au moment du déploiement.
Déploiement de packages de modèle
Vous pouvez fournir des packages de modèle en tant qu’entrées aux points de terminaison en ligne. L’utilisation de packages de modèle permet de rationaliser vos flux de travail MLOps en réduisant les risques d’erreurs au moment du déploiement, car toutes les dépendances auraient été collectées pendant l’opération d’empaquetage. Vous pouvez également configurer le package de modèle pour générer des images Docker que vous pourrez déployer n’importe où en dehors d’Azure Machine Learning, localement ou dans le cloud.
Empaqueter avant le déploiement
La façon la plus simple de déployer à l’aide d’un package de modèle consiste à spécifier à Azure Machine Learning de déployer un package de modèle, avant d’exécuter le déploiement. Lorsque vous utilisez Azure CLI, le kit de développement logiciel (SDK) Azure Machine Learning ou Azure Machine Learning Studio pour créer un déploiement dans un point de terminaison en ligne, vous pouvez spécifier l’utilisation de l’empaquetage de modèles comme suit :
Utilisez l’indicateur --with-package lors de la création d’un déploiement :
az ml online-deployment create --with-package -f model-deployment.yml -e $ENDPOINT_NAME

Azure Machine Learning empaquette d’abord le modèle, puis exécute le déploiement.
Remarque
Lorsque vous utilisez des packages, si vous indiquez un environnement de base avec des dépendances conda ou pip, vous n’avez pas besoin d’inclure les dépendances du serveur d’inférence (azureml-inference-server-http). Au lieu de cela, ces dépendances sont automatiquement ajoutées pour vous.
Déployer un modèle empaqueté
Vous pouvez déployer un modèle qui a été empaqueté directement sur un point de terminaison en ligne. Cette pratique garantit la reproductibilité des résultats et est recommandée. Consultez Empaqueter et déployer des modèles sur des points de terminaison en ligne.
Si vous souhaitez déployer le package en dehors d’Azure Machine Learning, consultez Empaqueter et déployer des modèles en dehors d’Azure Machine Learning.