Accéder aux données à partir du stockage cloud Azure pendant le développement interactif
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Un projet Machine Learning démarre généralement avec l’analyse exploratoire des données (EDA), le prétraitement des données (nettoyage, ingénierie des caractéristiques) et comprend la création de prototypes de modèles ML pour valider les hypothèses. La phase de prototypage du projet est de nature hautement interactive, et se prête au développement dans un notebook Jupyter ou un IDE avec une console interactive Python. Cet article porte sur les points suivants :
- Accédez aux données à partir d’un URI de magasin de données Azure Machine Learning comme s’il s’agissait d’un système de fichiers.
- Matérialisez des données dans Pandas à l’aide de la bibliothèque Python
mltable. - Matérialisez des ressources de données Azure Machine Learning dans Pandas à l’aide de la bibliothèque Python
mltable. - Matérialisez des données par le biais d’un téléchargement explicite avec l’utilitaire
azcopy.
Prérequis
- Un espace de travail Azure Machine Learning. Pour plus d’informations Gérer les espaces de travail Azure Machine Learning dans le portail ou avec le SDK Python (v2).
- Un magasin de données Azure Machine Learning. Pour plus d’informations, consultez Créer des magasins de données.
Conseil
Les conseils de cet article décrivent l’accès aux données pendant le développement interactif. Il s’applique à n’importe quel hôte qui peut exécuter une session Python. Cela peut comprendre votre ordinateur local, une machine virtuelle cloud, un codespace GitHub, etc. Nous recommandons d’utiliser une instance de calcul Azure Machine Learning, une station de travail préconfigurée complètement managée. Pour plus d’informations, consultez Créer une instance de calcul Azure Machine Learning.
Important
Vérifiez que les bibliothèques Python azure-fsspec et mltable les plus récentes sont installées dans votre environnement Python :
pip install -U azureml-fsspec mltable
Accéder aux données à partir d’un URI de magasin de données, comme un système de fichiers
Un magasin de données Azure Machine Learning est une référence à un compte de stockage Azure existant. Voici les avantages de la création et de l’utilisation d’un magasin de données :
- Une API commune et facile à utiliser pour interagir avec différents types de stockage (Blob/Fichiers/ADLS).
- Découverte facile des magasins de données utiles dans les opérations d’équipe.
- Prise en charge de l’accès basé à la fois sur des informations d’identification (par exemple, un jeton SAP) et sur des identités (Microsoft Entra ID ou identité managée) pour accéder aux données.
- Pour l’accès basé sur les informations d’identification, les informations de connexion sont sécurisées pour éliminer l’exposition des clés dans les scripts.
- Parcourez les données et copiez-collez des URI de magasin de données dans l’interface utilisateur de Studio.
Un URI de magasin de données est un identificateur de ressource uniforme, qui est une référence à un emplacement de stockage (chemin) sur votre compte de stockage Azure. Un URI de magasin de données a le format suivant :
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Ces URI de magasin de données sont une implémentation connue de la spécification de système de fichiers (fsspec) : une interface Python unifiée pour les systèmes de fichiers locaux, distants et incorporés et le stockage d’octets.
Vous pouvez utiliser la commande pip install pour le package azureml-fsspec et son package de dépendances azureml-dataprep. Vous pouvez ensuite utiliser l’implémentation fsspec du magasin de données Azure Machine Learning.
L’implémentation fsspec du magasin de données Azure Machine Learning gère automatiquement le transfert d’informations d’identification/d’identité utilisées par le magasin de données Azure Machine Learning. Vous pouvez éviter l’exposition de la clé de compte dans vos scripts et les procédures de connexion supplémentaires sur une instance de calcul.
Par exemple, vous pouvez utiliser directement des URI de magasin de données dans Pandas. Cet exemple montre comment lire un fichier CSV :
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Conseil
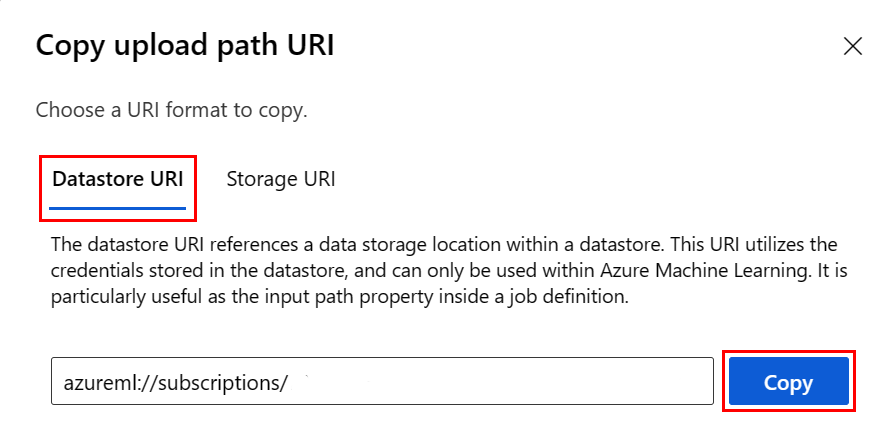
Au lieu de devoir mémoriser le format d’URI du magasin de données, vous pouvez copier-coller l’URI du magasin de données à partir de l’interface utilisateur de Studio en suivant ces étapes :
- Sélectionnez Données dans le menu de gauche, puis l’onglet Magasins de données.
- Sélectionnez le nom de votre magasin de données, puis Parcourir.
- Recherchez le fichier/dossier que vous voulez lire dans Pandas, puis sélectionnez l’ellipse (...) en regard de celui-ci. Sélectionnez Copier l’URI dans le menu. Vous pouvez sélectionner l’URI du magasin de données à copier dans votre notebook/script.
Vous pouvez également instancier un système de fichiers Azure Machine Learning, afin de traiter les commandes de type système de fichiers telles que ls, glob, exists, open.
- La méthode
ls()répertorie les fichiers dans un répertoire spécifique. Vous pouvez utiliser ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) pour répertorier les fichiers. Nous prenons en charge « . » et « .. » dans les chemins d’accès relatifs. - La méthode
glob()prend en charge le globbing « * » et « ** ». - La méthode
exists()retourne une valeur booléenne qui indique si un fichier spécifié existe dans le répertoire racine actuel. - La méthode
open()renvoie un objet de type fichier qui peut être passé à n’importe quelle autre bibliothèque qui s’attend à travailler avec des fichiers Python. Votre code peut également utiliser cet objet, comme s’il s’agissait d’un objet fichier Python normal. Ces objets de type fichier respectent l’utilisation de contexteswith, comme indiqué dans cet exemple :
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Charger des fichiers via AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath est le chemin d’accès local et rpath est le chemin d’accès distant.
Si les dossiers spécifiés dans rpath n’existent pas encore, nous allons créer les dossiers pour vous.
Nous prenons en charge trois modes de « remplacement » :
- APPEND : s’il existe déjà un fichier portant le même nom dans le chemin d’accès de destination, cette option conserve le fichier d’origine
- FAIL_ON_FILE_CONFLICT : s’il existe déjà un fichier portant le même nom dans le chemin d’accès de destination, cette option génère une erreur
- MERGE_WITH_OVERWRITE : si un fichier portant le même nom existe dans le chemin d’accès de destination, cette option remplace ce fichier existant par le nouveau fichier
Télécharger des fichiers via AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Exemples
Ces exemples illustrent l’utilisation des spécifications du système de fichiers dans des scénarios courants.
Lire un seul fichier CSV dans Pandas
Vous pouvez lire un seul fichier CSV dans Pandas comme indiqué :
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Lire un dossier de fichiers CSV dans Pandas
La méthode Pandas read_csv() ne prend pas en charge la lecture d’un dossier de fichiers CSV. Vous devez regrouper les chemins csv et les concaténer dans une trame de données à l’aide de la méthode Pandas concat(). Le code suivant montre comment effectuer cette concaténation avec le système de fichiers Azure Machine Learning :
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Lecture de fichiers CSV dans Dask
Cet exemple montre comment lire un fichier CSV dans une trame de données Dask :
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Lire un dossier de fichiers Parquet dans Pandas
Dans le cadre d’un processus ETL, les fichiers Parquet sont généralement écrits dans un dossier, qui peut émettre des fichiers pertinents à l’ETL comme la progression, les validations, etc. Cet exemple montre des fichiers créés à partir d’un processus ETL (fichiers commençant par _) qui produit ensuite un fichier Parquet de données.
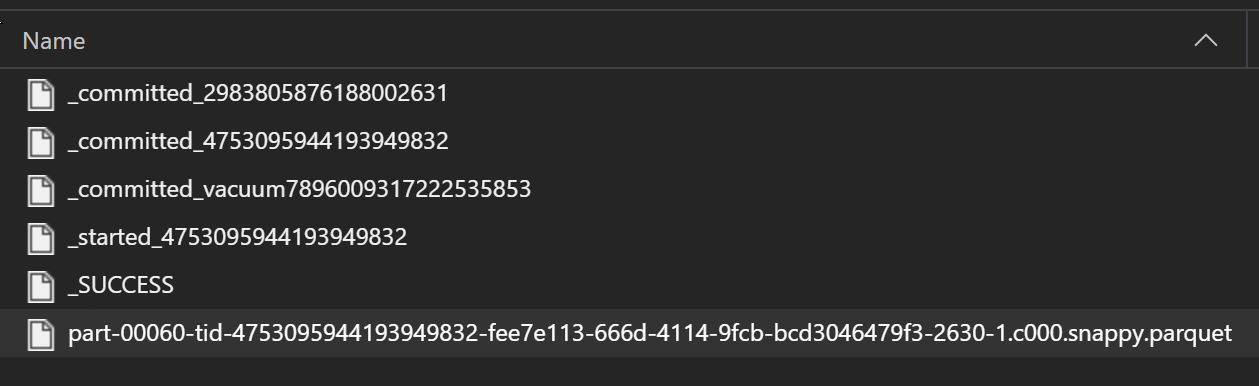
Dans ces scénarios, vous lisez uniquement les fichiers Parquet dans le dossier et ignorez les fichiers de processus ETL. Cet exemple de code montre comment les modèles Glob lisent les fichiers Parquet dans un dossier :
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Accès aux données à partir de votre système de fichiers Azure Databricks (dbfs)
La spécification du système de fichiers (fsspec) a un ensemble d’implémentations connues, comprenant le système de fichiers Databricks (dbfs).
Pour accéder aux données à partir de dbfs, vous avez besoin des éléments suivants :
- Nom de l’instance, sous la forme
adb-<some-number>.<two digits>.azuredatabricks.net. Vous pouvez trouver cette valeur à partir de l’URL de votre espace de travail Azure Databricks. - Pour plus d’informations sur la création d’un jeton d’accès personnel (PAT), consultez Authentification à l’aide de jetons d’accès personnels Azure Databricks
Avec ces valeurs, vous devez créer une variable d’environnement sur votre instance de calcul pour le jeton PAT :
export ADB_PAT=<pat_token>
Vous pouvez ensuite accéder aux données dans Pandas, comme illustré dans cet exemple :
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Lecture d’images avec pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Exemple de jeu de données personnalisé PyTorch
Dans cet exemple, vous créez un jeu de données personnalisé PyTorch pour le traitement d’images. Nous supposons qu’un fichier d’annotations (au format CSV) existe, avec cette structure globale :
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Les sous-dossiers stockent ces images, en fonction de leurs étiquettes :
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Une classe de jeu de données PyTorch personnalisée doit implémenter les trois fonctions __init__, __len__ et __getitem__, comme illustré ici :
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Vous pouvez ensuite instancier le jeu de données comme illustré ici :
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Matérialiser des données dans Pandas en utilisant la bibliothèque mltable
La bibliothèque mltable peut également aider à accéder aux données dans le stockage cloud. La lecture des données dans Pandas avec mltable a ce format général :
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Chemins pris en charge
La bibliothèque mltable prend en charge la lecture des données tabulaires dans différents types de chemins :
| Emplacement | Exemples |
|---|---|
| Chemin sur votre ordinateur local | ./home/username/data/my_data |
| Chemin sur un serveur http(s) public | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Chemin dans Stockage Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Un magasin de données Azure Machine Learning long | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Notes
mltable transmet les informations d’identification utilisateur pour les chemins d’accès sur le Stockage Azure et les magasins de données Azure Machine Learning. Si vous n’avez pas l’autorisation d’accéder aux données sur le stockage sous-jacent, vous ne pouvez pas accéder aux données.
Fichiers, dossiers et globs
mltable prend en charge la lecture à partir de :
- fichier(s), par exemple :
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - dossier(s), par exemple
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - modèle(s) Glob, par exemple
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - une combinaison de fichiers, de dossiers et/ou de modèles Glob
La flexibilité de mltable permet la matérialisation des données dans un même dataframe à partir d’une combinaison de ressources de stockage local et cloud et de combinaisons de fichiers/dossiers/globs. Par exemple :
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Formats de fichiers pris en charge
mltable prend en charge les formats de fichier suivants :
- Texte délimité (par exemple : fichiers CSV) :
mltable.from_delimited_files(paths=[path]) - Parquet :
mltable.from_parquet_files(paths=[path]) - Delta :
mltable.from_delta_lake(paths=[path]) - Format de lignes JSON :
mltable.from_json_lines_files(paths=[path])
Exemples
Lire un fichier CSV
Mettez à jour les espaces réservés (<>) dans cet extrait de code avec vos détails spécifiques :
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lire des fichiers Parquet dans un dossier
Cet exemple montre comment mltable peut utiliser des modèles Glob, tels que les caractères génériques, pour garantir que seuls les fichiers Parquet sont lus.
Mettez à jour les espaces réservés (<>) dans cet extrait de code avec vos détails spécifiques :
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lecture des ressources de données
Cette section montre comment accéder à vos ressources de données Azure Machine Learning dans Pandas.
Ressource de table
Si vous avez déjà créé une ressource de table dans Azure Machine Learning (une mltable ou une TabularDataset V1), vous pouvez charger cette ressource de table dans Pandas à l’aide de ce code :
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Ressource de fichier
Si vous avez inscrit une ressource de fichier (un fichier CSV, par exemple), vous pouvez lire cette ressource dans une trame de données Pandas avec ce code :
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Ressource de dossier
Si vous avez inscrit une ressource de dossier (uri_folder ou FileDataset V1), par exemple un dossier contenant un fichier CSV, vous pouvez lire cette ressource dans une trame de données Pandas avec ce code :
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Remarque sur la lecture et le traitement de grands volumes de données avec Pandas
Conseil
Pandas n’est pas conçu pour gérer des jeux de données volumineux. Pandas peut uniquement traiter des données qui peuvent tenir dans la mémoire de l’instance de calcul.
Pour les jeux de données volumineux, nous vous recommandons d’utiliser Spark managé par Azure Machine Learning. Cela fournit l’API PySpark Pandas.
Vous souhaiterez peut-être effectuer une itération rapide sur un sous-ensemble plus petit d’un jeu de données volumineux avant d’effectuer un scale-up vers un travail asynchrone distant. mltable fournit des fonctionnalités intégrées pour obtenir des échantillons de données volumineux à l’aide de la méthode take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Vous pouvez également prendre des sous-ensembles de données volumineuses à l’aide de ces opérations :
Téléchargement de données à l’aide de l’utilitaire azcopy
Utilisez l’utilitaire azcopy pour télécharger les données sur le disque SSD local de votre hôte (machine locale, machine virtuelle cloud, instance de calcul Azure Machine Learning) dans le système de fichiers local. L’utilitaire azcopy, qui est préinstallé sur une instance de calcul Azure Machine Learning, traitera cette opération. Si vous n’utilisez pas une instance de calcul Azure Machine Learning ou une machine DSVM (Data Science Virtual Machine), vous devrez peut-être installer azcopy. Pour plus d’informations, consultez azcopy.
Attention
Nous vous déconseillons de télécharger des données à l’emplacement /home/azureuser/cloudfiles/code d’un instance de calcul. Cet emplacement est conçu pour stocker des artefacts de notebook et de code, et non des données. La lecture de données à partir de cet emplacement entraîne une surcharge de performances importante lors de l’apprentissage. Au lieu de cela, nous vous recommandons de stocker vos données dans home/azureuser, qui est le disque SSD local du nœud de calcul.
Ouvrez un terminal et créez un répertoire, par exemple :
mkdir /home/azureuser/data
Connectez-vous à azcopy avec :
azcopy login
Ensuite, vous pouvez copier des données à l’aide d’un URI de stockage
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST