Créer et exécuter des pipelines Machine Learning à l’aide de composants avec Azure Machine Learning Studio
S’APPLIQUE À :  Extension ml Azure CLI v2 (actuelle)
Extension ml Azure CLI v2 (actuelle)
Dans cet article, vous allez apprendre à créer et exécuter un pipeline Machine Learning à l’aide du studio Azure Machine Learning et des composants. Vous pouvez créer des pipelines sans utiliser de composants, mais les composants offrent le plus de flexibilité et de possibilités de réutilisation. Vous pouvez définir des pipelines Azure Machine Learning en YAML et les exécuter à partir de l'interface CLI, les créer dans Python ou les composer dans le concepteur Azure Machine Learning studio avec une interface utilisateur par glisser-déplacer. Ce document se concentre sur l’interface utilisateur du concepteur Azure Machine Learning studio.
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Un espace de travail Azure Machine Learning Créer des ressources d'espace de travail.
Installer et configurer l’extension Azure CLI pour Machine Learning.
Clonez le référentiel d’exemples :
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Notes
Le concepteur prend en charge deux types de composants, les composants prédéfinis classiques (v1) et les composants personnalisés (v2). Ces deux types de composants ne sont PAS compatibles.
Les composants prédéfinis classiques fournissent principalement des composants prédéfinis utilisés pour le traitement des données et les tâches de Machine Learning traditionnelles telles que la régression et la classification. Les composants prédéfinis classiques continuent d’être pris en charge, mais aucun nouveau composant ne leur sera ajouté. En outre, le déploiement de composants prédéfinis classiques (v1) ne prend pas en charge les points de terminaison en ligne managés (v2).
Les composants personnalisés vous permettent d’encapsuler votre propre code en tant que composant. Ils vous permettent de partager des composants dans des espaces de travail et de créer en toute transparence dans des interfaces Studio, CLI v2 et le Kit de développement logiciel (SDK) v2.
Pour de nouveaux projets, nous vous suggérons vivement d’utiliser un composant personnalisé et compatible avec AzureML V2 qui va continuer à recevoir de nouvelles mises à jour.
Cet article s’applique aux composants personnalisés.
Inscrire un composant dans votre espace de travail
Pour générer un pipeline à l’aide de composants dans l’interface utilisateur, vous devez d’abord inscrire des composants dans votre espace de travail. Vous pouvez utiliser l’interface utilisateur, l’interface CLI ou le SDK pour inscrire des composants dans votre espace de travail afin de pouvoir les partager et les réutiliser dans l’espace de travail. Les composants enregistrés prennent en charge la gestion automatique des versions afin que vous puissiez mettre à jour le composant tout en vous assurant que les pipelines qui nécessitent une version plus ancienne continuent de fonctionner.
L'exemple suivant utilise l'interface utilisateur pour enregistrer les composants, et les fichiers sources des composants se trouvent dans le répertoire cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components du référentiel azureml-examples. Vous devez d’abord cloner le dépôt au niveau local.
- Dans votre espace de travail Azure Machine Learning, accédez à la page Composants et sélectionnez Nouveau composant (l'une des deux pages de style s'affiche).


Cet exemple utilise train.yml dans le répertoire. Le fichier YAML définit le nom, le type, l’interface, notamment les entrées et sorties, le code, l’environnement et la commande de ce composant. Le code de ce composant train.py se trouve dans le dossier ./train_src, qui décrit la logique d’exécution de ce composant. Pour en savoir plus sur le schéma du composant, consultez les informations de référence sur le schéma YAML du composant de commande.
Notes
Lors de l’inscription de composants dans l’interface utilisateur, le code défini dans le fichier YAML du composant ne peut pointer que vers le dossier actif où se trouve le fichier YAML ou les sous-dossiers, ce qui signifie que vous ne pouvez pas spécifier ../ pour code car l’interface utilisateur ne peut pas reconnaître le répertoire parent.
additional_includes peut uniquement pointer vers le dossier actuel ou le sous-dossier.
L’interface utilisateur ne prend actuellement en charge que l’inscription des composants avec le type command.
- Sélectionnez le chargement à partir d’un Dossier, puis sélectionnez le dossier
1b_e2e_registered_componentsà charger. Sélectionneztrain.ymldans la liste déroulante.

Sélectionnez Suivant dans la partie inférieure, puis confirmez les détails de ce composant. Après avoir confirmé, sélectionnez Créer pour terminer le processus d’inscription.
Répétez les étapes précédentes pour enregistrer les composants Score et Eval en utilisant également
score.ymleteval.yml.Une fois les trois composants inscrits, ceux-ci apparaissent dans l’interface utilisateur de studio.

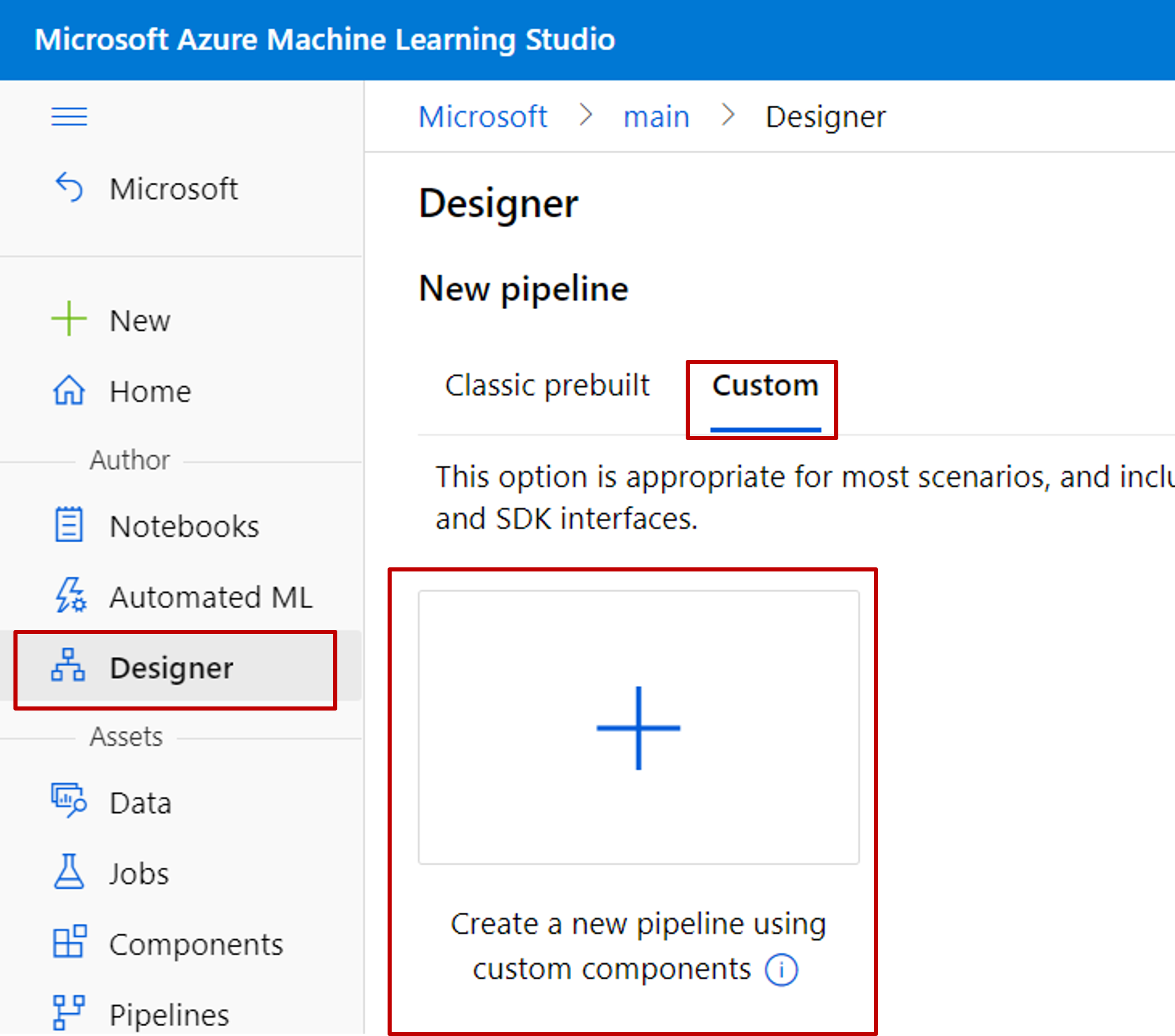
Créer un pipeline à l’aide d’un composant inscrit
Créez un pipeline dans le concepteur. N'oubliez pas de sélectionner l'option Personnalisé.
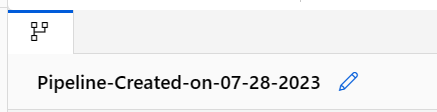
Donnez au pipeline un nom significatif en sélectionnant l'icône en forme de crayon à côté du nom généré automatiquement.
Dans la bibliothèque de ressources du concepteur, vous pouvez voir les onglets Données, Modèle et Composants. Passez à l'onglet Composants, vous pouvez voir les composants enregistrés de la section précédente. S'il y a trop de composants, vous pouvez rechercher avec le nom du composant.
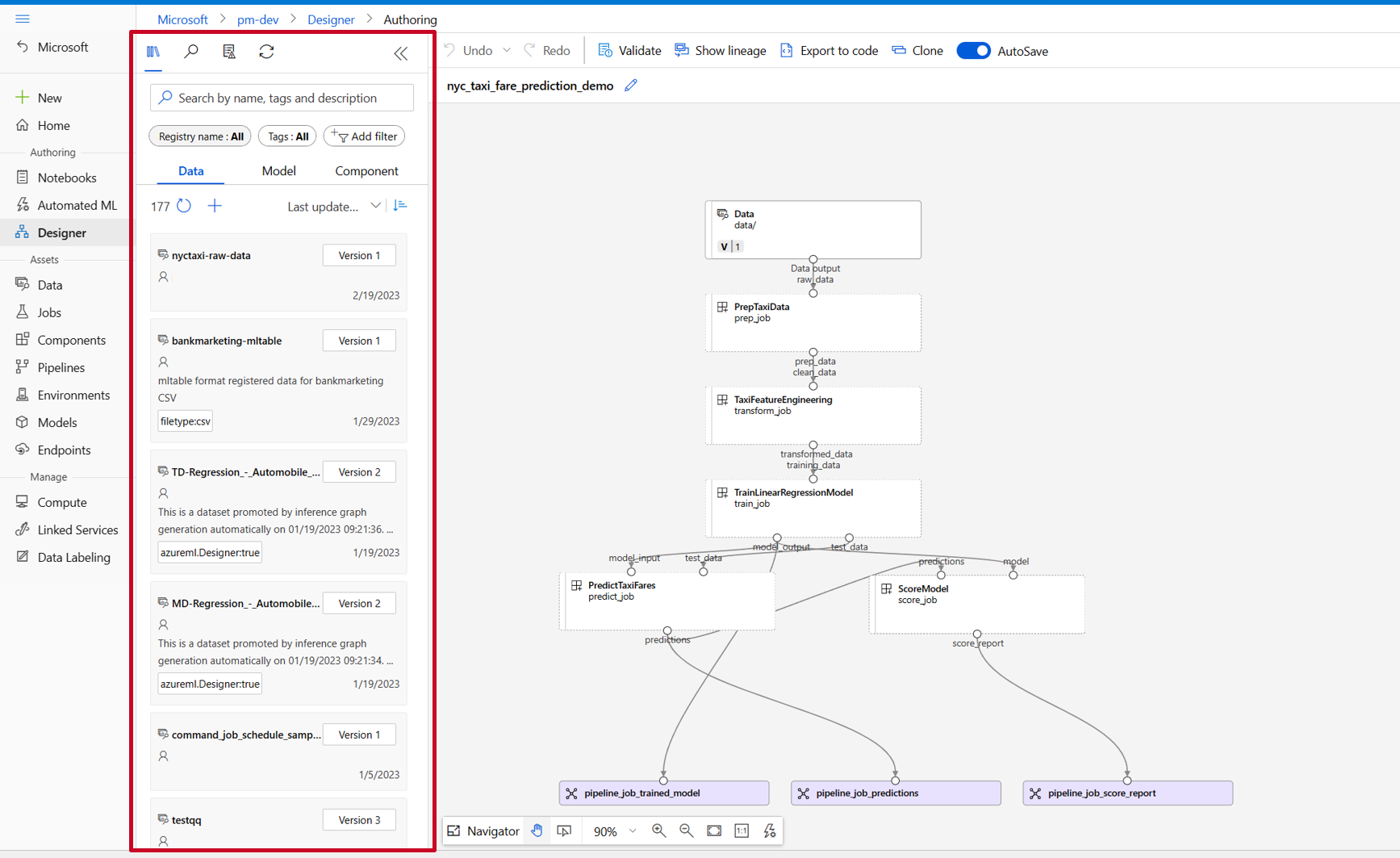
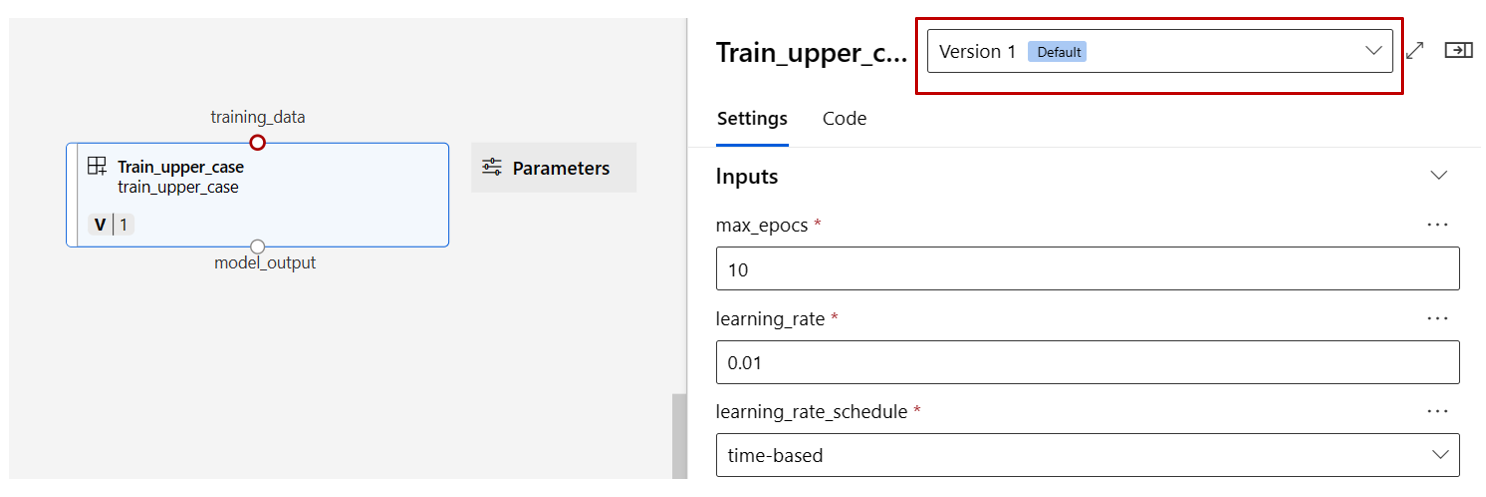
Trouvez les composants train, score et eval enregistrés dans la section précédente, puis faites-les glisser et déposez-les sur le canevas. Par défaut, il utilise la version par défaut du composant et vous pouvez passer à une version spécifique dans le volet droit du composant. Le volet droit du composant est appelé par un double-clic sur le composant.
Dans cet exemple, nous utiliserons les exemples de données sous ce chemin. Enregistrez les données dans votre espace de travail en sélectionnant l'icône d'ajout dans la bibliothèque de ressources du concepteur -> onglet données, définissez Type = Dossier(uri_dossier) puis suivez l'assistant pour enregistrer les données. Le type de données doit être uri_folder pour s'aligner sur la définition du composant de train.

Faites ensuite glisser et déposez les données dans le canevas. L'apparence de votre pipeline devrait maintenant ressembler à la capture d'écran suivante.
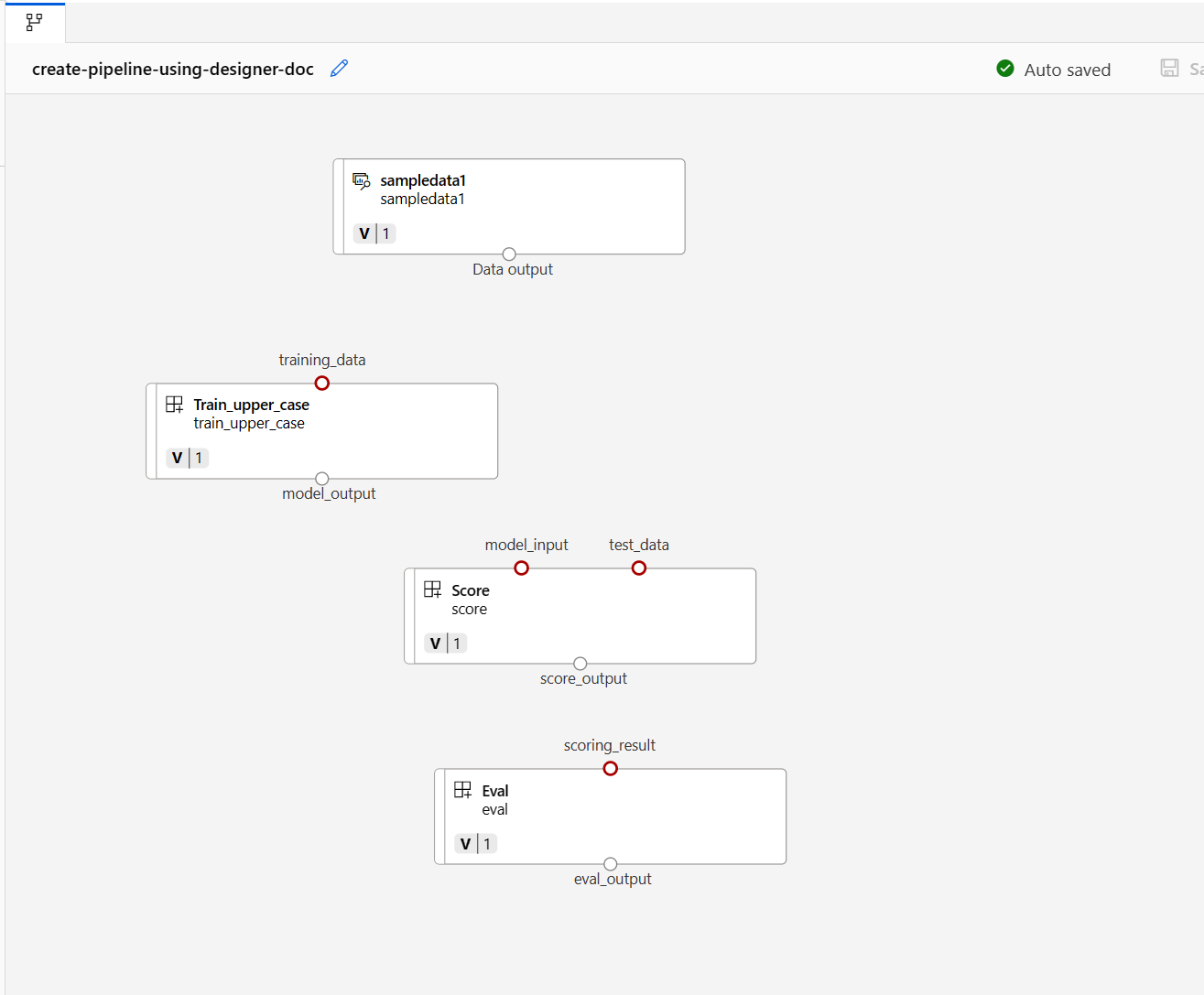
Connectez les données et les composants en faisant glisser les connexions dans le canevas.

Double-cliquez sur un composant, vous verrez un volet droit où vous pouvez configurer le composant.

Pour les composants avec des entrées de type primitif comme un nombre, un entier, une chaîne et un booléen, vous pouvez modifier les valeurs de ces entrées dans le volet détaillé du composant, sous la section Entrées.
Vous pouvez également modifier les paramètres de sortie (où stocker la sortie du composant) et les paramètres d'exécution (cible de calcul pour exécuter ce composant) dans le volet de droite.
Maintenant, promouvons l'entrée max_epocs du composant train en entrée au niveau du pipeline. Ce faisant, vous pouvez attribuer une valeur différente à cette entrée à chaque fois avant de soumettre le pipeline.
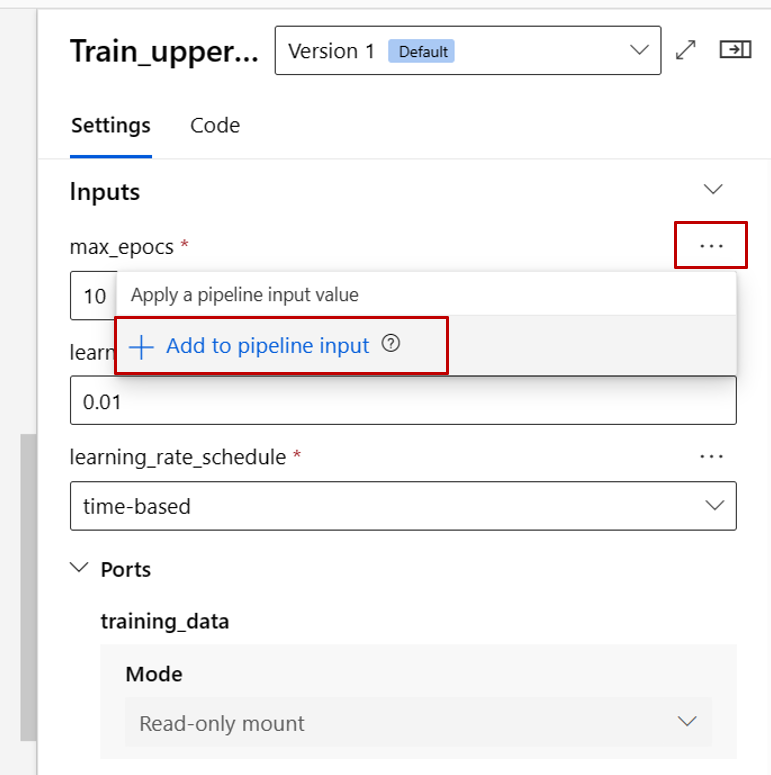









Notes
Les composants personnalisés et les composants prédéfinis classiques du concepteur ne peuvent pas être utilisés ensemble.
Envoyer le pipeline
Sélectionnez Configurer et envoyer dans le coin supérieur droit pour soumettre le pipeline.

Ensuite, vous verrez un assistant étape par étape, suivez l'assistant pour soumettre le travail de pipeline.

À l'étape Bases, vous pouvez configurer l'expérience, le nom d'affichage de la tâche, la description de la tâche, etc.
Dans l’étape Entrées et sorties, vous pouvez configurer les entrées/sorties qui sont promues au niveau du pipeline. À l'étape précédente, nous avons promu le composant max_epocs du train à l'entrée du pipeline, vous devriez donc pouvoir voir et attribuer une valeur à max_epocs ici.
Dans Paramètres d'exécution, vous pouvez configurer le magasin de données par défaut et le calcul par défaut du pipeline. Il s'agit du magasin de données/calcul par défaut pour tous les composants du pipeline. Mais notez que si vous définissez explicitement un calcul ou un magasin de données différent pour un composant, le système respecte le paramètre au niveau du composant. Sinon, il utilise la valeur par défaut du pipeline.
L'étape Review + Submit est la dernière étape pour examiner toutes les configurations avant de les soumettre. L'assistant se souvient de votre dernière configuration si jamais vous soumettez le pipeline.
Après avoir soumis la tâche de pipeline, un message apparaîtra en haut avec un lien vers les détails de la tâche. Vous pouvez sélectionner ce lien pour examiner les détails du travail.

Spécifier l’identité dans le travail de pipeline
Lors de l’envoi d’un travail de pipeline, vous pouvez spécifier l’identité pour accéder aux données sous Run settings. L’identité par défaut est AMLToken, qui n’a pas utilisé d’identité. Nous prenons en charge UserIdentity et Managed. Pour UserIdentity, l’identité de l’expéditeur de travail est utilisée pour accéder aux données d’entrée et écrire le résultat dans le dossier de sortie. Si vous spécifiez Managed, le système utilise l’identité managée pour accéder aux données d’entrée et écrire le résultat dans le dossier de sortie.

Étapes suivantes
- Utilisez ces notebooks Jupyter sur GitHub pour explorer plus en détail les pipelines Machine Learning
- Découvrez comment utiliser CLI v2 pour créer un pipeline à l’aide de composants.
- Découvrez comment utiliser le Kit de développement logiciel (SDK) v2 pour créer un pipeline à l’aide de composants.