Exigences de connectivité et de routeur d’inférence Azure Machine Learning
Le routeur d’inférence Azure Machine Learning est un composant essentiel pour l’inférence en temps réel avec un cluster Kubernetes. Cet article porte sur les points suivants :
- Définition du routeur d’inférence Azure Machine Learning
- Fonctionnement de la mise à l’échelle automatique
- Comment configurer et atteindre le niveau de performance des demandes d’inférence (nombre de demandes par seconde et latence)
- Exigences de connectivité pour le cluster d’inférence AKS
Définition du routeur d’inférence Azure Machine Learning
Le routeur d’inférence Azure Machine Learning est le composant front-end (azureml-fe) déployé sur un cluster AKS ou Arc Kubernetes au moment du déploiement de l’extension Azure Machine Learning. Il a les fonctions suivantes :
- Route les demandes d’inférence entrantes de l’équilibreur de charge ou du contrôleur d’entrée du cluster vers les pods de modèle correspondants.
- Équilibrez la charge de toutes les demandes d’inférence entrantes avec un routage coordonné intelligent.
- Gère la mise à l’échelle automatique des pods de modèle.
- Fonctionnalité de tolérance de panne et de basculement, garantissant que les demandes d’inférence sont toujours traitées pour les applications métier critiques.
Les étapes suivantes décrivent le traitement des demandes par le front-end :
- Le client envoie une demande à l’équilibreur de charge.
- L’équilibreur de charge l’envoie à l’un des front-ends.
- Le front-end localise le routeur de service (l’instance front-end agissant comme coordinateur) pour le service.
- Le routeur de service sélectionne un back-end et le retourne au front-end.
- Le front-end transfère la demande au back-end.
- Une fois la demande traitée, le back-end envoie une réponse au composant front-end.
- Le front-end propage la réponse au client.
- Le front-end informe le routeur de service que le back-end a terminé le traitement et est disponible pour d’autres demandes.
Le diagramme suivant illustre ce flux :
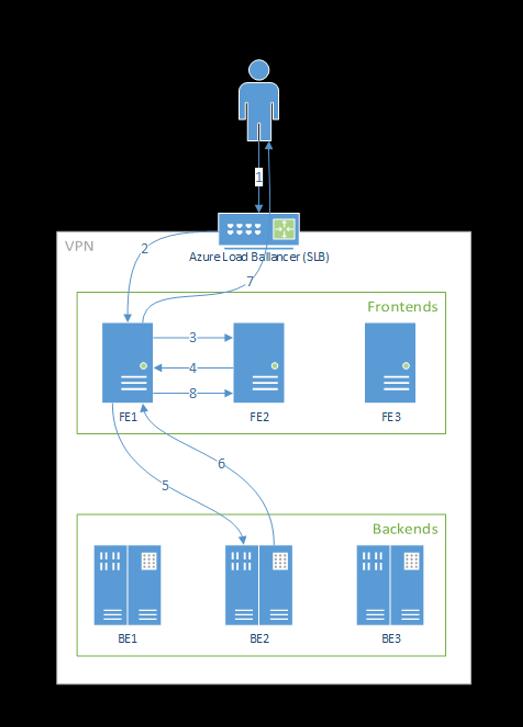
Comme vous pouvez le voir dans le diagramme ci-dessus, par défaut, 3 instances azureml-fe sont créées lors du déploiement de l’extension Azure Machine Learning, une instance fait office de rôle de coordination et les autres instances servent les demandes d’inférence entrantes. L’instance de coordination, qui dispose de toutes les informations sur les pods de modèle, choisit celui qui doit traiter la demande entrante, tandis que les instances azureml-fe de service sont responsables du routage de la demande vers le pod de modèle sélectionné et propagent la réponse à l’utilisateur d’origine.
Mise à l’échelle automatique
Le routeur d’inférence Azure Machine Learning gère la mise à l’échelle automatique pour tous les modèles de déploiement sur le cluster Kubernetes. Étant donné que toutes les demandes d’inférence passent par lui, il possède les données nécessaires pour mettre à l’échelle automatiquement les modèles déployés.
Important
N’activez pas l’Autoscaler de pods horizontaux (HPA) Kubernetes pour les déploiements de modèles. Cela mettrait en concurrence les deux composants de mise à l’échelle automatique. Azureml-fe est conçu pour mettre à l’échelle automatiquement les modèles déployés par Azure Machine Learning, dans lesquels HPA devrait deviner ou estimer l’utilisation du modèle à partir d’une mesure générique telle que l’utilisation du processeur ou une configuration de métrique personnalisée.
Azureml-fe ne met pas à l’échelle le nombre de nœuds d’un cluster AKS, car cela pourrait entraîner une augmentation inattendue du coût. Au lieu de cela, il met à l’échelle le nombre de réplicas du modèle dans les limites du cluster physique. Si vous devez mettre à l’échelle le nombre de nœuds au sein du cluster, vous pouvez mettre à l’échelle le cluster manuellement ou configurer le programme de mise à l’échelle automatique du cluster AKS.
La mise à l’échelle automatique peut être contrôlée par la propriété scale_settings dans le YAML de déploiement. L’exemple suivant montre comment activer la mise à l’échelle automatique :
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
La décision d’effectuer un scale-up ou un scale-down est basée sur utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Si ce nombre dépasse target_utilization_percentage, d’autres réplicas sont créés. S’il est inférieur, des réplicas sont supprimés. Par défaut, le pourcentage d’utilisation ciblé est 70 %.
La décision d’ajouter des réplicas est hâtive et rapide (environ 1 seconde). La décision de supprimer des réplicas est prudente (environ 1 minute).
Supposons que vous souhaitiez déployer un service de modèle et connaître le nombre d’instances (pods/réplicas) à configurer pour les demandes cibles par seconde et le temps de réponse cible. Vous pouvez calculer le nombre de réplicas nécessaires à l’aide du code suivant :
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Performances d’azureml-fe
azureml-fe peut atteindre 5 000 requêtes par seconde (QPS) avec une bonne latence, avec une surcharge ne dépassant pas 3 ms en moyenne et 15 ms au 99e centile.
Remarque
Si plus de 10 000 demandes par seconde (RPS) doivent être prises en charge, réfléchissez aux options suivantes :
- Augmentez les demandes/limites de ressources pour les pods
azureml-fe, qui sont par défaut de 2 processeurs virtuels et de 1,2 Go pour la limite de ressource mémoire. - Augmentez le nombre d’instances de
azureml-fe. Par défaut, Azure Machine Learning crée 1 ou 3 instances deazureml-fepar cluster.- Ce nombre d’instances dépend de votre configuration du
inferenceRouterHAde l’extension Azure Machine Learning. - L’augmentation du nombre d’instances ne peut pas être conservée de manière persistante, car elle est remplacée par la valeur configurée une fois l’extension mise à niveau.
- Ce nombre d’instances dépend de votre configuration du
- Contactez les experts Microsoft pour obtenir de l’aide.
Comprendre les exigences de connectivité pour le cluster d’inférence AKS
Le cluster AKS est déployé avec un des deux modèles de réseau suivants :
- Mise en réseau Kubenet : les ressources réseau sont généralement créées et configurées quand le cluster AKS est déployé.
- Mise en réseau Azure CNI (Container Networking Interface) : le cluster AKS est connecté à des configurations et à une ressource de réseau virtuel existantes.
Pour la mise en réseau Kubenet, le réseau est créé et configuré correctement pour Azure Machine Learning service. Pour la mise en réseau CNI, vous devez comprendre les besoins de connectivité et garantir la résolution DNS et la connectivité sortante pour l’inférence AKS. Par exemple, vous pouvez exiger des étapes supplémentaires si vous utilisez un pare-feu pour bloquer le trafic réseau.
Le diagramme suivant montre les besoins de connectivité pour l’inférence AKS. Les flèches noires représentent la communication réelle et les flèches bleues représentent les noms de domaine. Vous devrez peut-être ajouter des entrées pour ces hôtes à votre pare-feu ou à votre serveur DNS personnalisé.
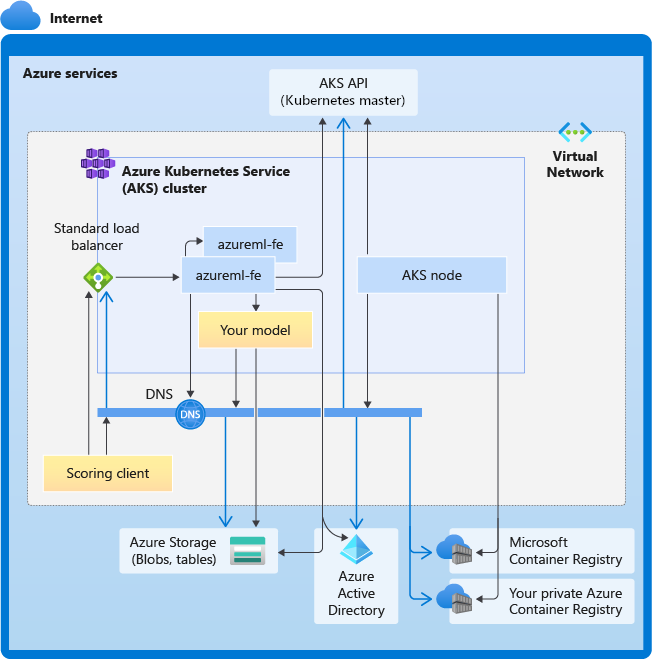
Pour connaître les besoins de connectivité AKS, consultez Contrôler le trafic de sortie pour les nœuds de cluster dans Azure Kubernetes Service.
Pour accéder aux services Azure Machine Learning derrière un pare-feu, consultez Configurer le trafic réseau entrant et sortant.
Exigences globales de la résolution DNS
La résolution DNS au sein d’un réseau virtuel existant est sous votre contrôle. Par exemple, un pare-feu ou un serveur DNS personnalisé. Les hôtes suivants doivent être accessibles :
| Nom de l’hôte | Utilisée par |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Serveur d’API AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Votre ACR (Azure Container Registry) |
<account>.blob.core.windows.net |
Compte Stockage Azure (stockage Blob) |
api.azureml.ms |
Authentification Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Point de terminaison Kusto pour le chargement des données de télémétrie |
Exigences de connectivité dans l’ordre chronologique : de la création du cluster au déploiement du modèle
Juste après le déploiement d’azureml-fe, il tentera de démarrer et cela nécessite les opérations suivantes :
- Résoudre le DNS pour le serveur d’API AKS
- Interroger le serveur d’API AKS pour découvrir d’autres instances de lui-même (il s’agit d’un service à plusieurs pods)
- Se connecter à d’autres instances de soi-même
Une fois azureml-fe démarré, il nécessite la connectivité suivante pour fonctionner correctement :
- Se connecter à Stockage Azure pour télécharger la configuration dynamique
- Résoudre le DNS pour le serveur d’authentification Microsoft Entra api.azureml.ms et communiquer avec celui-ci lorsque le service déployé utilise l’authentification Microsoft Entra
- Interroger le serveur d’API AKS pour découvrir les modèles déployés
- Communiquer avec les pods du modèle déployé
Au moment du déploiement du modèle, pour que le déploiement du modèle soit réussi, le nœud AKS doit être en mesure d’effectuer les opérations suivantes :
- Résoudre le DNS pour l’ACR du client
- Télécharger des images à partir de l’ACR du client
- Résoudre le DNS pour les Blobs Azure sur lesquels le modèle est stocké
- Télécharger des modèles à partir de Blobs Azure
Après le déploiement du modèle et le démarrage du service, azureml-fe le découvrira automatiquement grâce à l’API AKS et sera prêt à acheminer la demande vers celui-ci. Il doit pouvoir communiquer avec les pods du modèle.
Notes
Si le modèle déployé requiert une connectivité (par exemple, pour l’interrogation d’une base de données externe ou d’un autre service REST, le téléchargement d’un Blob, etc.), la résolution DNS et la communication sortante pour ces services doivent être activées.