Configurer MLOps avec Azure DevOps
S’APPLIQUE À : Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Azure Machine Learning vous permet d’intégrer le pipeline Azure DevOps pour automatiser le cycle de vie du Machine Learning. Certaines des opérations que vous pouvez automatiser sont les suivantes :
- Déploiement de l’infrastructure Azure Machine Learning
- Préparation des données (opérations d’extraction, de transformation et de chargement)
- Formation de modèles Machine Learning avec scale-out et scale-up à la demande
- Déploiement de modèles Machine Learning en tant que services web publics ou privés
- Surveillance des modèles Machine Learning déployés (par exemple, pour l’analyse des performances)
Dans cet article, vous allez découvrir comment utiliser Azure Machine Learning pour configurer un pipeline MLOps de bout en bout qui exécute une régression linéaire pour prédire les tarifs des taxis à New York. Le pipeline est composé de composants, chacun servant des fonctions différentes, qui peuvent être inscrits auprès de l’espace de travail, versionnés et réutilisés avec différentes entrées et sorties. vous allez utiliser l’architecture Azure recommandée pour MLOps et l’accélérateur de solution Azure MLOps (v2) pour configurer rapidement un projet MLOps dans Azure Machine Learning.
Conseil
Nous vous recommandons de comprendre certaines des architectures Azure recommandées pour MLOps avant d’implémenter une solution. Vous devez choisir la meilleure architecture pour votre projet Machine Learning donné.
Prérequis
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
- Un espace de travail Azure Machine Learning.
- Git en cours d’exécution sur votre ordinateur local.
- Une organisation dans Azure DevOps.
- Projet Azure DevOps qui hébergera les référentiels et pipelines sources.
- L’extension Terraform pour Azure DevOps si vous utilisez Azure DevOps + Terraform pour lancer l’infrastructure
Notes
Git version 2.27 ou ultérieure est obligatoire. Pour plus d’informations sur l’installation de la commande Git, consultez https://git-scm.com/downloads et sélectionnez votre système d’exploitation
Important
Les commandes CLI de cet article ont été testées à l’aide de Bash. Si vous utilisez un autre interpréteur de commandes, vous pouvez rencontrer des erreurs.
Configurer l’authentification avec Azure et DevOps
Avant de pouvoir configurer un projet MLOps avec Azure Machine Learning, vous devez configurer l’authentification pour Azure DevOps.
Créer un principal du service
Pour l’utilisation de la démonstration, la création d’un ou deux principes de service est requise, selon le nombre d’environnements sur lesquels vous souhaitez travailler (Dev ou Prod ou les deux). Ces principes peuvent être créés à l’aide de l’une des méthodes suivantes :
Lancez Azure Cloud Shell.
Conseil
La première fois que vous avez lancé le Cloud Shell, vous êtes invité à créer un compte de stockage pour le Cloud Shell.
Si vous y êtes invité, choisissez Bash comme environnement utilisé dans le Cloud Shell. Vous pouvez également modifier les environnements dans la liste déroulante de la barre de navigation supérieure
Copiez les commandes bash suivantes sur votre ordinateur et mettez à jour les variables projectName, subscriptionId et environment avec les valeurs de votre projet. Si vous créez à la fois un environnement Dev et Prod, vous devez exécuter ce script une fois pour chaque environnement, en créant un principal de service pour chacun d’eux. Cette commande accorde également le rôle Contributeur au principal de service dans l’abonnement fourni. Cela est nécessaire pour qu’Azure DevOps utilise correctement les ressources de cet abonnement.
projectName="<your project name>" roleName="Contributor" subscriptionId="<subscription Id>" environment="<Dev|Prod>" #First letter should be capitalized servicePrincipalName="Azure-ARM-${environment}-${projectName}" # Verify the ID of the active subscription echo "Using subscription ID $subscriptionID" echo "Creating SP for RBAC with name $servicePrincipalName, with role $roleName and in scopes /subscriptions/$subscriptionId" az ad sp create-for-rbac --name $servicePrincipalName --role $roleName --scopes /subscriptions/$subscriptionId echo "Please ensure that the information created here is properly save for future use."Copiez vos commandes modifiées dans Azure Shell et exécutez-les (Ctrl + Maj + v).
Après avoir exécuté ces commandes, des informations relatives au principal de service vous sont présentées. Enregistrez ces informations dans un emplacement sûr. Elles seront utilisées plus loin dans la démonstration pour configurer Azure DevOps.
{ "appId": "<application id>", "displayName": "Azure-ARM-dev-Sample_Project_Name", "password": "<password>", "tenant": "<tenant id>" }Répétez l’étape 3 si vous créez des principaux de service pour les environnements Dev et Prod. Pour cette démonstration, nous allons créer un seul environnement (Prod).
Fermez le Cloud Shell une fois les principaux de service créés.
Configurer Azure DevOps
Accédez à Azure DevOps.
Sélectionnez Créer un projet (Nommez le projet
mlopsv2pour ce tutoriel).
Dans le projet sous Paramètres du projet (en bas à gauche de la page du projet), sélectionnez Connexions de service.
Sélectionnez Créer une connexion de service.
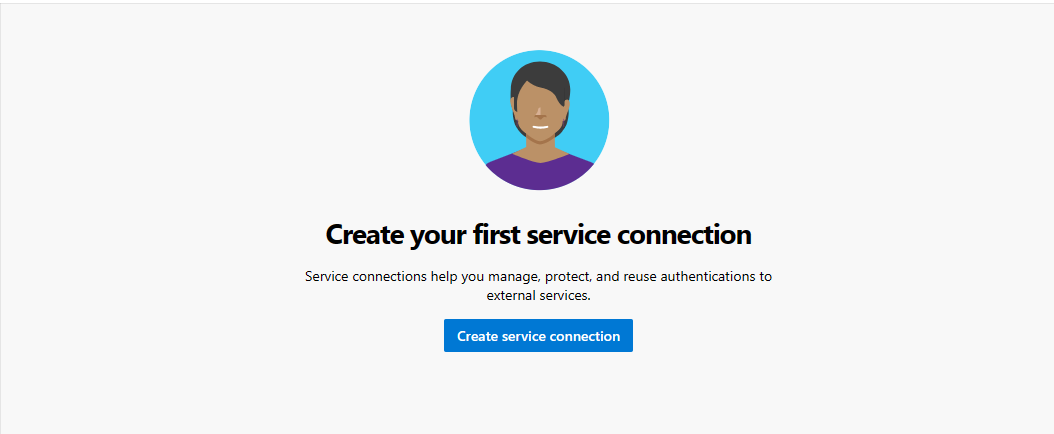
Sélectionnez Azure Resource Manager, sélectionnezSuivant, sélectionnezPrincipal de service (manuel), sélectionnez Suivant puis sélectionnezAbonnementau niveau de l’étendue.
- Nom de l’abonnement : utilisez le nom de l’abonnement dans lequel votre principal de service est stocké.
- ID d’abonnement : utilisez le
subscriptionIdque vous avez utilisé à l’étape 1 entrée comme ID d’abonnement - ID de principal de service : utilisez la
appIdsortie de l’étape 1 comme ID de principal de service - Clé de principal de service : utilisez la
passwordsortie de l’étape 1 comme clé de principal de service - ID de locataire : utilisez la
tenantsortie de l’étape 1 comme ID de locataire
Nommez la connexion de service Azure-ARM-Prod.
Sélectionnez Accorder l’autorisation d’accès à tous les pipelines, puis sélectionnez Vérifier et enregistrer.
L’installation d’Azure DevOps est terminée.
Configurer un dépôt source avec Azure DevOps
Ouvrez le projet que vous avez créé dans Azure DevOps
Ouvrez la section Repos et sélectionnez Importer le référentiel
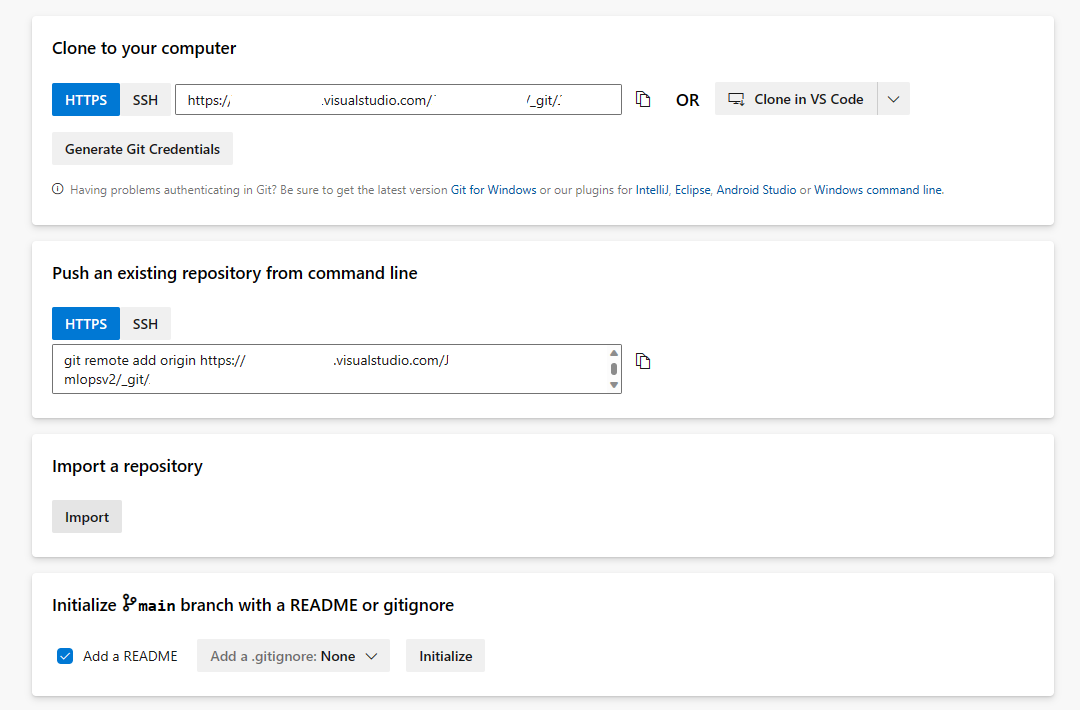
Entrez https://github.com/Azure/mlops-v2-ado-demo dans le champ URL de clone. Sélectionnez Importer au bas de la page.
Ouvrez les paramètres du projet en bas du volet de navigation gauche
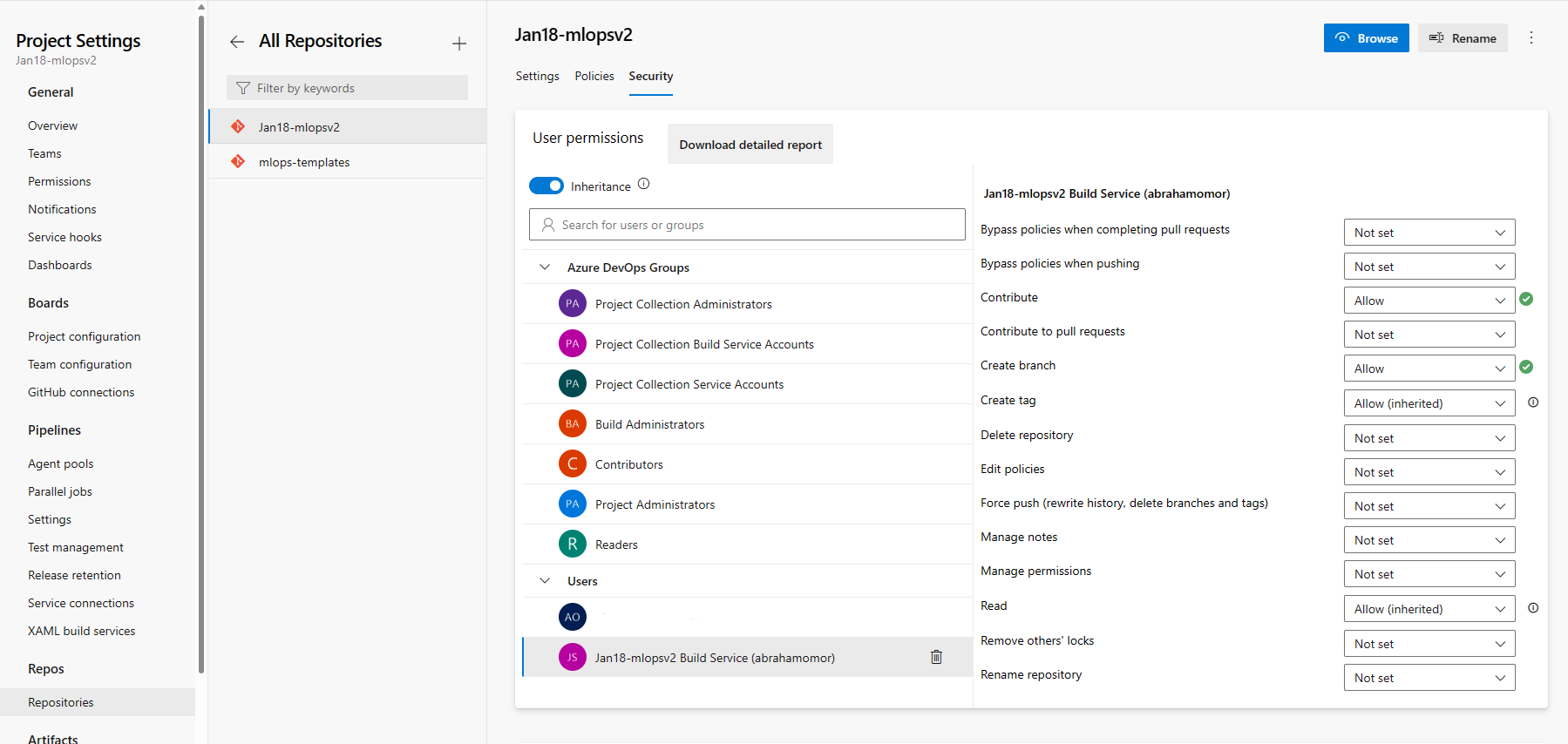
Sous la section Repos, sélectionnez Dépôts. Sélectionnez le dépôt créé à l’étape précédente. Sélectionnez l’onglet Sécurité
Dans la section Autorisations de l’utilisateur, sélectionnez l’utilisateur mlopsv2 Build Service . Modifiez l’autorisation Contribuer par Autoriser et l’autorisation Créer une branche sur Autoriser.
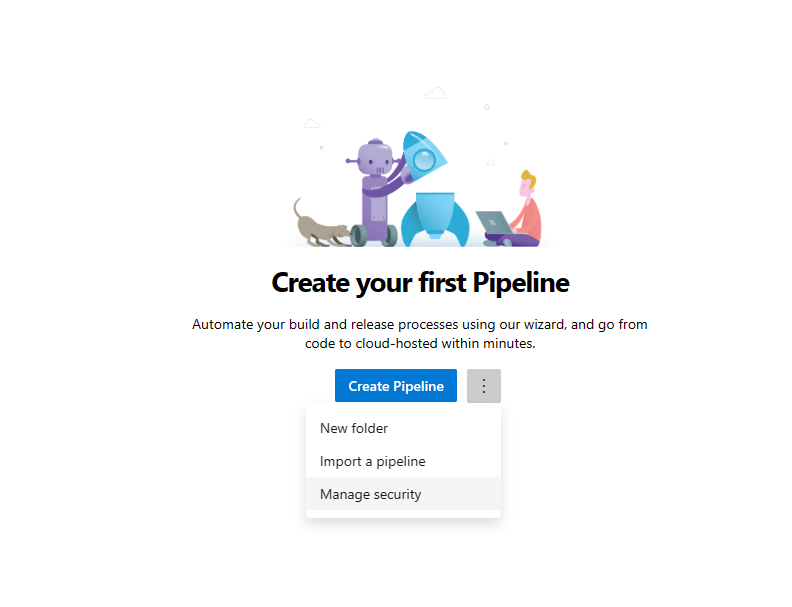
Ouvrez la section Pipelines dans le volet de navigation gauche et sélectionnez les 3 points verticaux en regard du bouton Créer des pipelines. Sélectionnez Gérer la sécurité
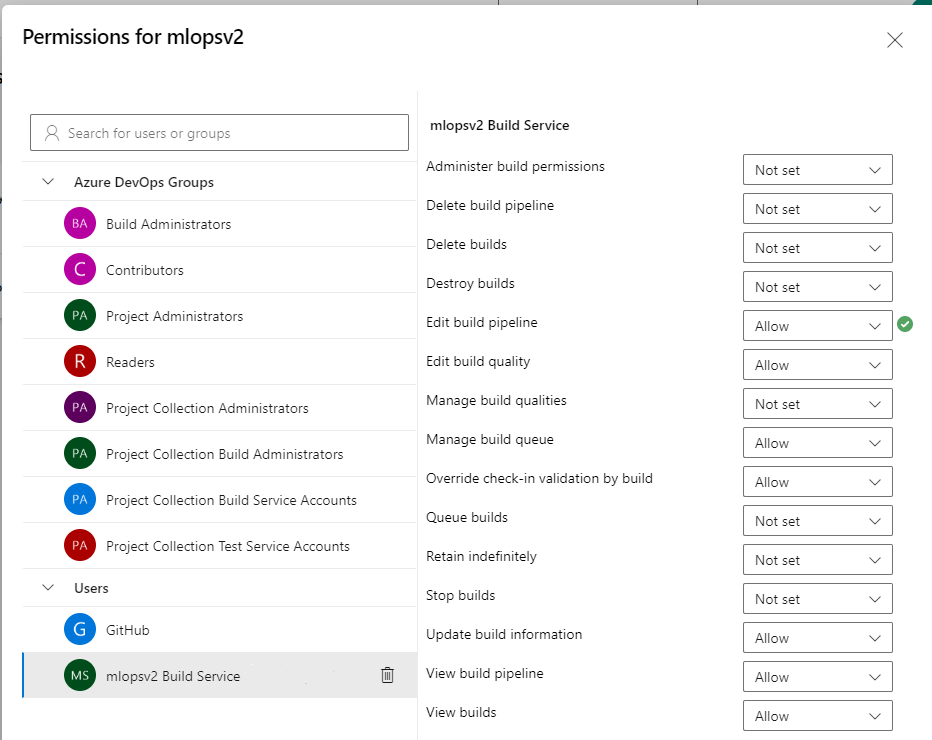
Sélectionnez le compte mlopsv2 Build Service pour votre projet sous la section Utilisateurs. Modifier le pipeline de build sur Autoriser l’autorisation Modifier le pipeline de build
Remarque
Cette opération termine la section prérequis et le déploiement de l’accélérateur de solution peut se produire en conséquence.
Déploiement de l’infrastructure via Azure DevOps
Cette étape déploie le pipeline d’entraînement dans l’espace de travail Azure Machine Learning créé aux étapes précédentes.
Conseil
Assurez-vous de bien comprendre les modèles architecturaux de l’accélérateur de solution avant d’extraire le référentiel MLOps v2 et de déployer l’infrastructure. Dans des exemples, vous allez utiliser le type de projet ML classique.
Exécuter un pipeline d’infrastructure Azure
Accédez à votre dépôt,
mlops-v2-ado-demo, puis sélectionnez le fichier config-infra-prod.yml.Important
Vérifiez que vous avez sélectionné la branche main du dépôt.
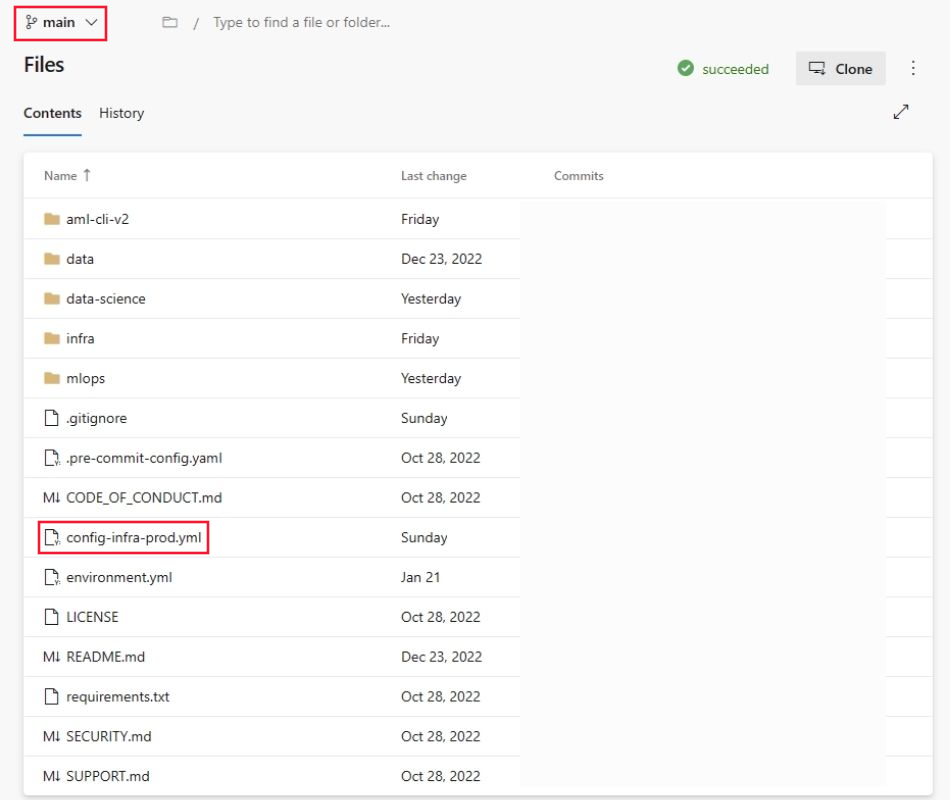
Ce fichier de configuration utilise les valeurs namespace et postfix des noms des artefacts pour assurer l'unicité. Mettez à jour la section suivante de la configuration à votre convenance.
namespace: [5 max random new letters] postfix: [4 max random new digits] location: eastusNotes
Si vous exécutez une charge de travail Deep Learning telle que CV ou NLP, assurez-vous que votre calcul GPU est disponible dans votre zone de déploiement.
Sélectionnez Commiter et envoyez (push) le code pour transmettre ces valeurs au pipeline.
Accéder à la section Pipelines
Sélectionnez Créer un pipeline.
Sélectionnez Azure Repos Git.
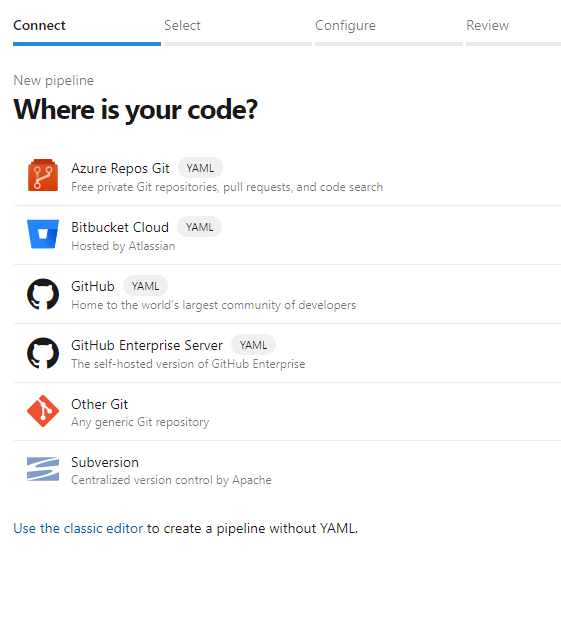
Sélectionnez le dépôt dans lequel vous avez cloné dans la section précédente
mlops-v2-ado-demoSélectionnez Fichier YAML Azure Pipelines existant
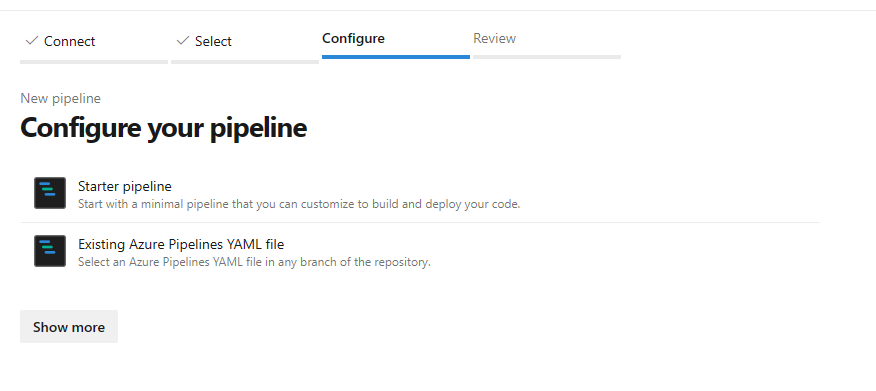
Sélectionnez la branche
mainet choisissezmlops/devops-pipelines/cli-ado-deploy-infra.yml, puis sélectionnez Continuer.Exécutez le pipeline ; il faudra quelques minutes pour se terminer. Le pipeline doit créer les artefacts suivants :
- Groupe de ressources pour votre espace de travail, y compris le compte de stockage, Container Registry, Application Insights, Keyvault et l’espace de travail Azure Machine Learning lui-même.
- Dans l’espace de travail, un cluster de calcul est également créé.
À présent, l’infrastructure de votre projet MLOps est déployée.
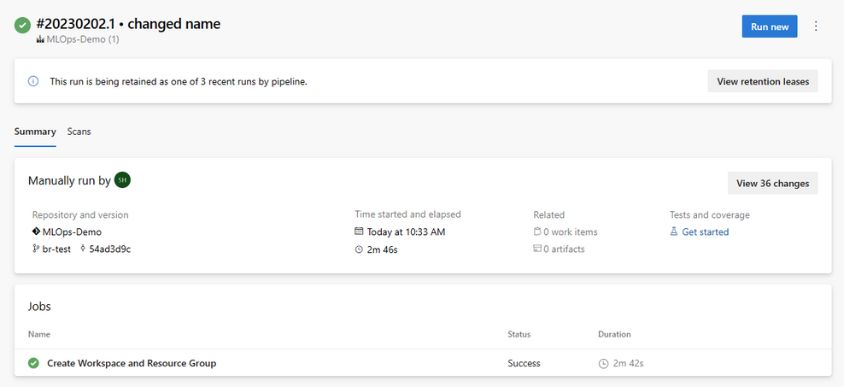
Remarque
Les avertissements Impossible de déplacer et de réutiliser le référentiel existant vers l’emplacement requis peuvent être ignorés.
Exemple de scénario de formation et de déploiement
L’accélérateur de solution comprend du code et des données pour un échantillon de pipeline Machine Learning de bout en bout qui exécute une régression linéaire pour prédire les tarifs des taxis à NYC. Le pipeline est composé de composants, chacun servant des fonctions différentes, qui peuvent être inscrits auprès de l’espace de travail, versionnés et réutilisés avec différentes entrées et sorties. Les échantillons de pipelines et de flux de travail pour les scénarios Vision par ordinateur et NLP auront différentes étapes et étapes de déploiement.
Ce pipeline d’entraînement contient les étapes suivantes :
Préparer les données
- Ce composant prend plusieurs jeux de données de taxi (jaune et vert) et fusionne/filtre les données, et prépare les jeux de données train/val et d’évaluation.
- Entrée : Données locales sous ./data/ (plusieurs fichiers .csv)
- Sortie : jeu de données préparé unique (.csv) et jeux de données train/val/test.
Former le modèle
- Ce composant entraîne un régresseur linéaire avec le jeu d’entraînement.
- Entrée : jeu de données d’entraînement
- Sortie : Modèle entraîné (format pickle)
Évaluer le modèle
- Ce composant utilise le modèle entraîné pour prédire les tarifs des taxis sur le jeu de test.
- Entrée : modèle ML et jeu de données de test
- Sortie : performances du modèle et d’un indicateur de déploiement s’il faut déployer ou non.
- Ce composant compare les performances du modèle avec tous les modèles déployés précédemment sur le nouveau jeu de données de test et décide s’il faut promouvoir ou non le modèle en production. La promotion du modèle en production s’effectue en inscrivant le modèle dans l’espace de travail AML.
Inscription du modèle
- Ce composant évalue le modèle en fonction de la précision des prédictions dans le jeu de tests.
- Entrée : modèle entraîné et indicateur de déploiement.
- Sortie : modèle inscrit dans Azure Machine Learning.
Déploiement du pipeline d’apprentissage du modèle
Accéder aux pipelines ADO
Sélectionnez Nouveau pipeline.

Sélectionnez Azure Repos Git.
Sélectionnez le dépôt dans lequel vous avez cloné dans la section précédente
mlopsv2Sélectionnez Fichier YAML Azure Pipelines existant
Sélectionnez
mainen tant que branche, choisissez/mlops/devops-pipelines/deploy-model-training-pipeline.yml, puis sélectionnez Continuer.Enregistrez et exécutez le pipeline
Notes
À ce stade, l’infrastructure est configurée et la boucle de prototypage de l’architecture MLOps est déployée. vous êtes prêt à passer à notre modèle entraîné en production.
Déploiement du modèle entraîné
Ce scénario inclut des flux de travail prédéfinis pour deux approches de déploiement d’un modèle entraîné, le scoring par lots ou le déploiement d’un modèle sur un point de terminaison pour un scoring en temps réel. Vous pouvez exécuter l’un ou l’autre de ces flux de travail pour tester les performances du modèle dans votre espace de travail Azure ML. Dans cet exemple, nous allons utiliser le scoring en temps réel.
Déployer le point de terminaison de modèle ML
Accéder aux pipelines ADO
Sélectionnez Nouveau pipeline.
Sélectionnez Azure Repos Git.
Sélectionnez le dépôt dans lequel vous avez cloné dans la section précédente
mlopsv2Sélectionnez Fichier YAML Azure Pipelines existant
Sélectionnez
maincomme branche et choisissez le point de terminaison en ligne managé/mlops/devops-pipelines/deploy-online-endpoint-pipeline.yml, puis sélectionnez Continuer.Les noms de point de terminaison en ligne devant être uniques, remplacez
taxi-online-$(namespace)$(postfix)$(environment)par un autre nom unique, puis sélectionnez Exécuter. Il est inutile de modifier la valeur par défaut si elle n’échoue pas.
Important
Si l’exécution échoue en raison d’un nom de point de terminaison en ligne existant, recréez le pipeline comme décrit précédemment et remplacez [nom de votre point de terminaison] par [nom de votre point de terminaison (nombre aléatoire)]
Une fois l’exécution terminée, vous verrez une sortie similaire à l’image suivante :
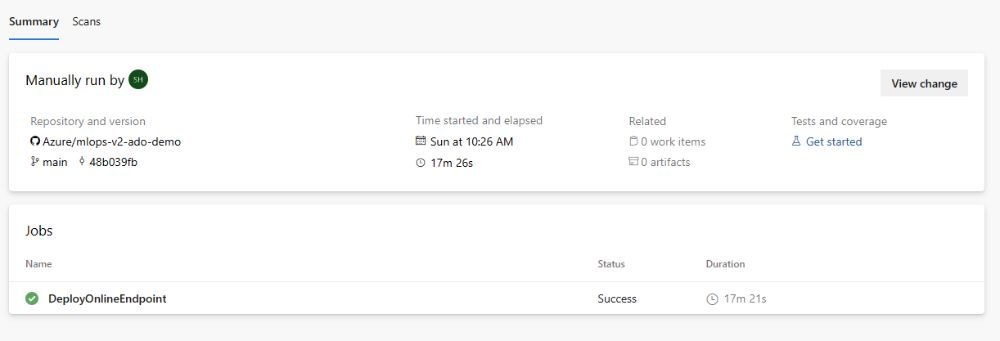
Pour tester ce déploiement, accédez à l’onglet Points de terminaison de votre espace de travail AzureML, sélectionnez le point de terminaison, puis cliquez sur l’onglet Test . Vous pouvez utiliser les échantillons de données d’entrée situées dans le référentiel cloné à
/data/taxi-request.jsonpour tester le point de terminaison.
Nettoyer les ressources
- Si vous ne prévoyez pas de continuer à utiliser votre pipeline, supprimez votre projet Azure DevOps.
- Dans le Portail Azure, supprimez votre groupe de ressources et votre instance Azure Machine Learning.
Étapes suivantes
- Installer et configurer le Kit de développement logiciel (SDK) Python v2
- Installer et configurer CLI Python v2
- Accélérateur de solution Azure MLOps (v2) sur GitHub
- Cours de formation sur MLOps avec Machine Learning
- En savoir plus sur Azure Pipelines avec Azure Machine Learning
- En savoir plus sur GitHub Actions avec Azure Machine Learning
- Déployer MLOps sur Azure en moins d’une heure - Vidéo de la communauté MLOps V2 Accelerator