Tutoriel : Développement de modèles sur une station de travail cloud
Découvrez comment développer un script d’entraînement avec un notebook sur une station de travail cloud Azure Machine Learning. Ce tutoriel aborde les principes de base à connaître avant de commencer :
- Installez et configurez la station de travail cloud. Votre station de travail cloud utilise une instance de calcul Azure Machine Learning, qui est préconfigurée avec des environnements pour répondre à vos différents besoins de développement de modèles.
- Utilisez des environnements de développement cloud.
- Utilisez MLflow pour suivre toutes les métriques de vos modèles depuis un notebook.
Prérequis
Pour utiliser Azure Machine Learning, vous avez d’abord besoin d’un espace de travail. Si vous n’en avez pas déjà un, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en apprendre davantage sur son utilisation.
Commencer avec les notebooks
La section Notebooks de votre espace de travail est un bon point de départ pour découvrir Azure Machine Learning et ses fonctionnalités. De là, vous pouvez vous connecter à des ressources de calcul, utiliser un terminal, modifier et exécuter des notebooks Jupyter et des scripts.
Connectez-vous à Azure Machine Learning Studio.
Sélectionnez votre espace de travail s’il n’est pas déjà ouvert.
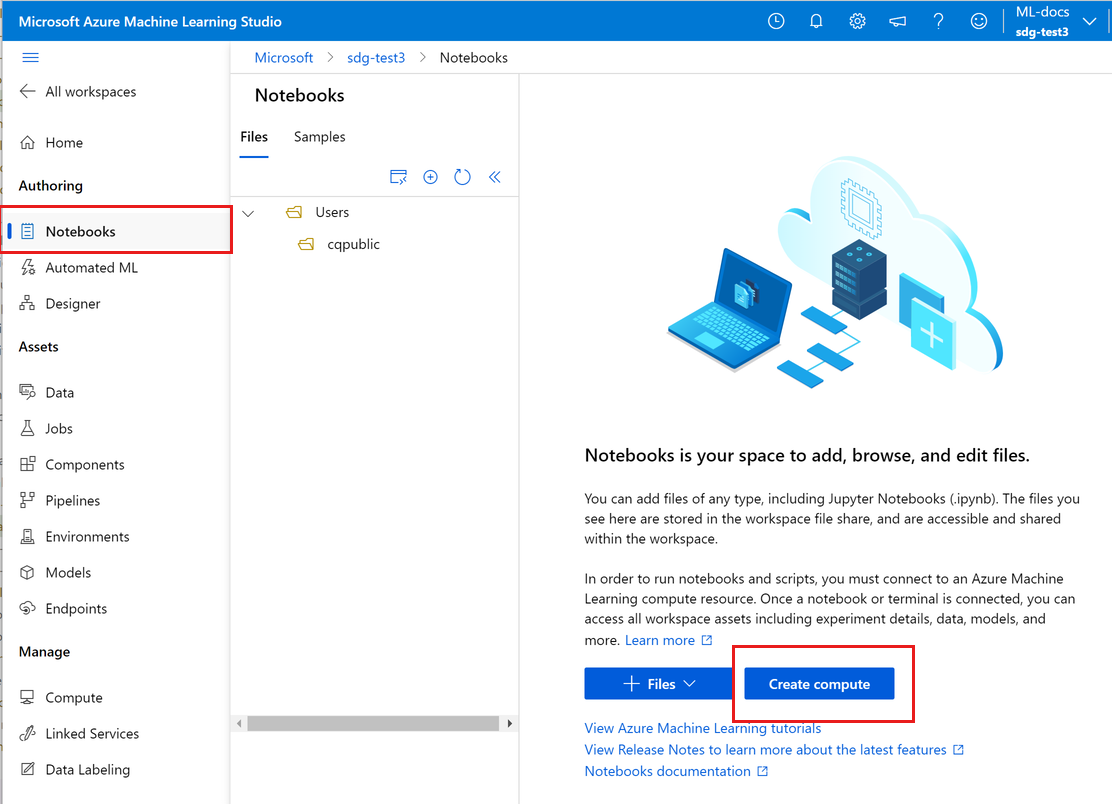
Dans le volet de navigation de gauche, sélectionnez Notebooks.
Si vous n’avez pas d’instance de calcul, l’option Créer une capacité de calcul est affichée au milieu de l’écran. Sélectionnez Créer une capacité de calcul et complétez le formulaire. Vous pouvez utiliser toutes les valeurs par défaut. (Si vous disposez déjà d’une instance de calcul, vous trouvez à cet endroit l’option Terminal. Vous utiliserez Terminal plus loin dans ce tutoriel.)
Configurer un nouvel environnement pour le prototypage (facultatif)
Pour que votre script s’exécute, vous devez travailler dans un environnement configuré avec les dépendances et les bibliothèques attendues par le code. Cette section vous aide à créer un environnement adapté à votre code. Pour créer le nouveau noyau Jupyter auquel votre notebook va se connecter, vous allez utiliser un fichier YAML qui définit les dépendances.
Chargez un fichier.
Les fichiers que vous chargez sont stockés dans un partage de fichiers Azure ; ces fichiers sont montés sur chaque instance de calcul et partagés dans l’espace de travail.
- Téléchargez ce fichier d’environnement conda, workstation_env.yml sur votre ordinateur à l’aide du bouton Télécharger le fichier brut en haut à droite.
Sélectionnez Ajouter des fichiers, puis Charger des fichiers pour charger ce fichier dans votre espace de travail.
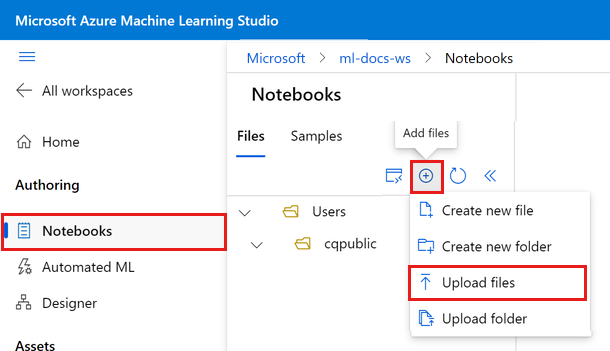
Sélectionnez Parcourir et sélectionner des fichiers.
Sélectionnez le fichier workstation_env.yml que vous avez téléchargé.
Sélectionnez Télécharger.
Le fichier workstation_env.yml se trouve en dessous du dossier qui porte votre nom d’utilisateur sous l’onglet Fichiers. Sélectionnez ce fichier pour le prévisualiser et voir les dépendances qu’il spécifie. Vous verrez un contenu du type suivant :
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibCréez un noyau.
Utilisez maintenant le terminal Azure Machine Learning pour créer un noyau Jupyter basé sur le fichier workstation_env.yml.
Sélectionnez Terminal pour ouvrir une fenêtre de terminal. Vous pouvez aussi ouvrir le terminal à partir de la barre de commandes de gauche :
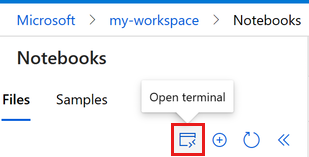
Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Une fois que le calcul s’exécute, un message de bienvenue s’affiche dans le terminal, et vous pouvez commencer à taper des commandes.
Affichez vos environnements conda actuels. L’environnement actif est marqué d’un *.
conda env listSi vous avez créé un sous-dossier pour ce tutoriel, basculez vers ce dossier via une commande
cd.Créez l’environnement en le basant sur le fichier conda fourni. La création de cet environnement prend quelques minutes.
conda env create -f workstation_env.ymlActivez le nouvel environnement.
conda activate workstation_envVérifiez que l’environnement actif est le bon (encore une fois en recherchant l’environnement marqué d’un *).
conda env listCréez un noyau Jupyter basé sur votre environnement actif.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Fermez la fenêtre de terminal.

Vous disposez maintenant d’un nouveau noyau. Vous ouvrirez ensuite un notebook et utiliserez ce noyau.
Créer un notebook
Sélectionnez Ajouter des fichiers, puis choisissez Créer un fichier.
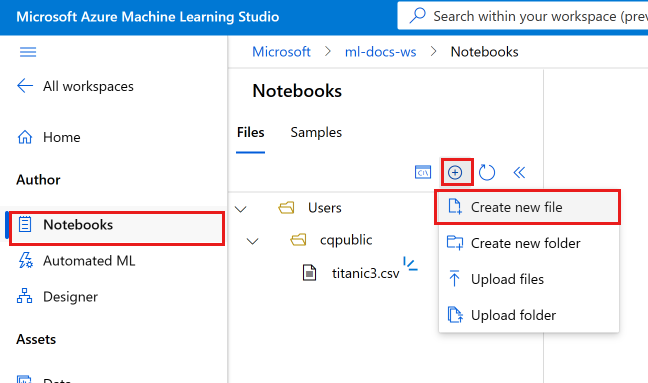
Nommez votre nouveau notebook develop-tutorial.ipynb (ou entrez le nom de votre choix).
Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.
Vous pouvez constater que le notebook est connecté au noyau par défaut en haut à droite. Passez à l’utilisation du noyau Tutorial Workstation Env si vous avez créé le noyau.
Développer un script d’entraînement
Dans cette section, vous allez développer un script d’entraînement Python capable de prédire les défauts de paiement par crédit carte, en utilisant les jeux de données de test et d’entraînement préparés à partir du jeu de données UCI.
Ce code utilise sklearn pour l’entraînement et MLflow pour la journalisation des métriques.
Commencez par le code qui va importer les packages et les bibliothèques que vous utiliserez dans le script d’entraînement.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitEnsuite, chargez et traitez les données pour cette expérience. Dans ce tutoriel, vous lisez les données d’un fichier sur Internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Préparez les données pour l’entraînement :
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAjoutez du code pour démarrer la journalisation automatique avec
MLflow, ce qui va vous permettre de suivre les métriques et les résultats. Du fait de la nature itérative du développement de modèles,MLflowvous permet de journaliser les paramètres et les résultats du modèle. Réexaminez ces exécutions pour comparer et comprendre le niveau de performance de votre modèle. Grâce à ces journaux, vous disposez également du contexte qui vous permet de déterminer le meilleur moment pour passer de la phase de développement à la phase d’entraînement de vos workflows dans Azure Machine Learning.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Formez un modèle.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Remarque
Vous pouvez ignorer les avertissements mlflow. Vous obtiendrez toujours le suivi de tous les résultats dont vous avez besoin.
Itérer
Maintenant que vous disposez des résultats du modèle, vous pouvez apporter des modifications et faire de nouveaux essais. Par exemple, essayez une autre technique de classifieur :
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Remarque
Vous pouvez ignorer les avertissements mlflow. Vous obtiendrez toujours le suivi de tous les résultats dont vous avez besoin.
Examiner les résultats
Maintenant que vous avez essayé deux modèles différents, utilisez les résultats suivis par MLFfow pour déterminer quel est le meilleur modèle. Vous pouvez vous concentrer sur des métriques telles que la précision ou sur d’autres indicateurs plus importants dans vos scénarios. Vous pouvez faire une analyse plus poussée de ces résultats en examinant les travaux créés par MLflow.
Dans le volet de navigation gauche, sélectionnez Travaux.
Sélectionnez le lien du tutoriel Développer sur le cloud.
Deux travaux différents sont présentés, un pour chaque modèle que vous avez essayé. Ces noms sont gérés automatiquement. Quand vous placez le pointeur sur un nom, utilisez éventuellement l’outil crayon situé en face du nom pour le changer.
Sélectionnez le lien correspondant au premier travail. Le nom apparaît en haut. Vous pouvez également le renommer ici avec l’outil crayon.
La page présente les détails du travail, notamment les propriétés, les sorties, les balises et les paramètres. Sous Balises figure estimator_name, qui décrit le type du modèle.
Sélectionnez l’onglet Métriques pour afficher les métriques qui ont été journalisées par
MLflow. (Attendez-vous à obtenir des résultats différents, car vous disposez d’un jeu d’entraînement différent.)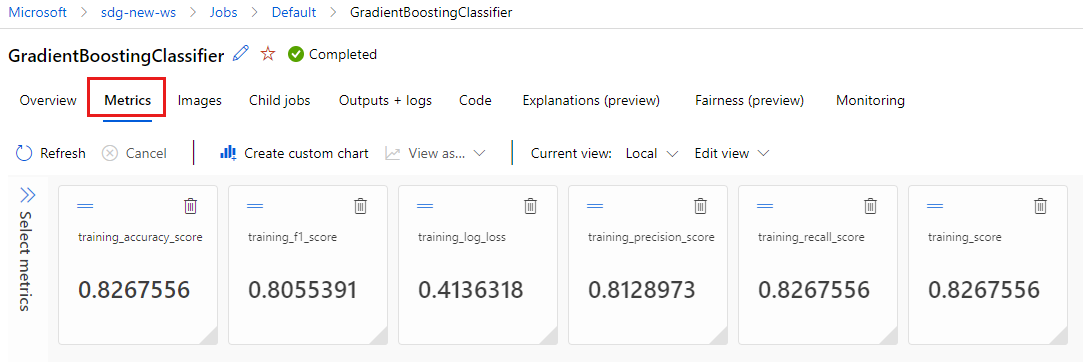
Sélectionnez l’onglet Images pour voir les images générées par
MLflow.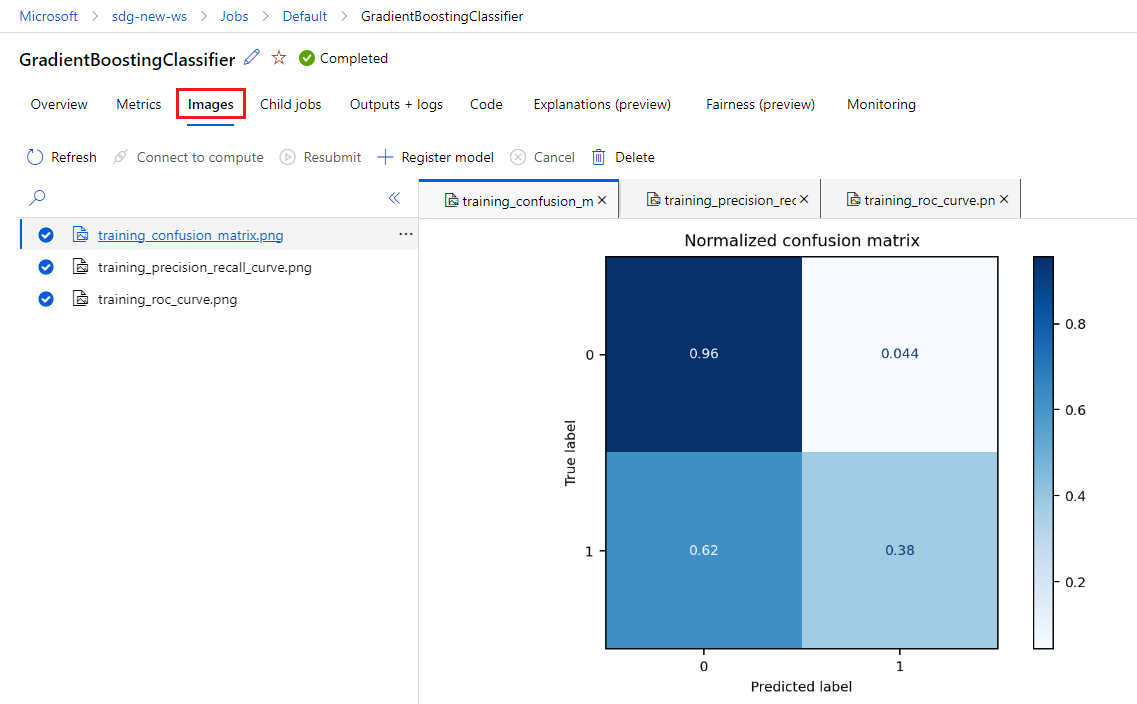
Revenez aux métriques et images de l’autre modèle et passez-les en revue.
Créer un script Python
Créez maintenant un script Python depuis votre notebook pour l’entraînement de modèle.
Dans la barre d’outils du notebook, sélectionnez le menu.
Sélectionnez Exporter au format > Python.
Nommez le fichier train.py.
Parcourez ce fichier et supprimez le code dont vous ne voulez pas dans le script d’entraînement. Par exemple, conservez le code pour le modèle que vous souhaitez utiliser, et supprimez le code pour le modèle dont vous ne voulez pas.
- Veillez à conserver le code qui démarre la journalisation automatique (
mlflow.sklearn.autolog()). - Vous pouvez supprimer les commentaires générés automatiquement et ajouter vos propres commentaires.
- Quand vous exécutez le script Python de manière interactive (dans un terminal ou un notebook), vous pouvez conserver la ligne qui définit le nom de l’expérience (
mlflow.set_experiment("Develop on cloud tutorial")). Vous pouvez même la nommer différemment pour l’afficher en tant qu’entrée distincte dans la section Travaux. En revanche, quand vous préparerez le script pour un travail d’entraînement, cette ligne sera inopérante ; il est préférable de l’omettre (la définition du travail inclut le nom de l’expérience). - Lorsque vous entraînez un seul modèle, les lignes destinées à démarrer et à arrêter une exécution (
mlflow.start_run()etmlflow.end_run()) ne sont pas non plus nécessaires (elles n’ont aucun effet), mais vous pouvez les y laisser si vous le souhaitez.
- Veillez à conserver le code qui démarre la journalisation automatique (
Une fois que vous avez terminé vos modifications, enregistrez le fichier.
Vous disposez maintenant d’un script Python à utiliser pour l’entraînement de votre modèle préféré.
Exécuter le script Python
Pour le moment, vous exécutez ce code sur votre instance de calcul, qui est votre environnement de développement Azure Machine Learning. Le tutoriel : Entraîner un modèle vous montre comment exécuter un script d’entraînement d’une manière plus scalable sur des ressources de calcul plus puissantes.
À gauche, sélectionnez Ouvrir le terminal pour ouvrir une fenêtre de terminal.
Affichez vos environnements conda actuels. L’environnement actif est marqué d’un *.
conda env listSi vous avez créé un noyau, activez-le maintenant :
conda activate workstation_envSi vous avez créé un sous-dossier pour ce tutoriel, basculez vers ce dossier via une commande
cd.Exécutez votre script d’entraînement.
python train.py
Remarque
Vous pouvez ignorer les avertissements mlflow. Vous obtiendrez toujours toutes les métriques et images depuis la journalisation automatique.
Examiner les résultats du script
Retournez dans Travaux pour examiner les résultats de votre script d’entraînement. Gardez à l’esprit que les données d’entraînement changent à chaque répartition. De ce fait, les résultats diffèrent aussi d’une exécution à l’autre.
Nettoyer les ressources
Si vous comptez suivre d’autres tutoriels, passez aux Étapes suivantes.
Arrêter l’instance de calcul
Si vous ne comptez pas l’utiliser maintenant, arrêtez l’instance de calcul :
- Dans la zone de navigation gauche de Studio, sélectionnez Calculer.
- Sous les onglets supérieurs, sélectionnez Instances de calcul
- Sélectionnez l’instance de calcul dans la liste.
- Dans la barre d’outils supérieure, sélectionnez Arrêter.
Supprimer toutes les ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans le portail Azure, sélectionnez Groupes de ressources tout à gauche.
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
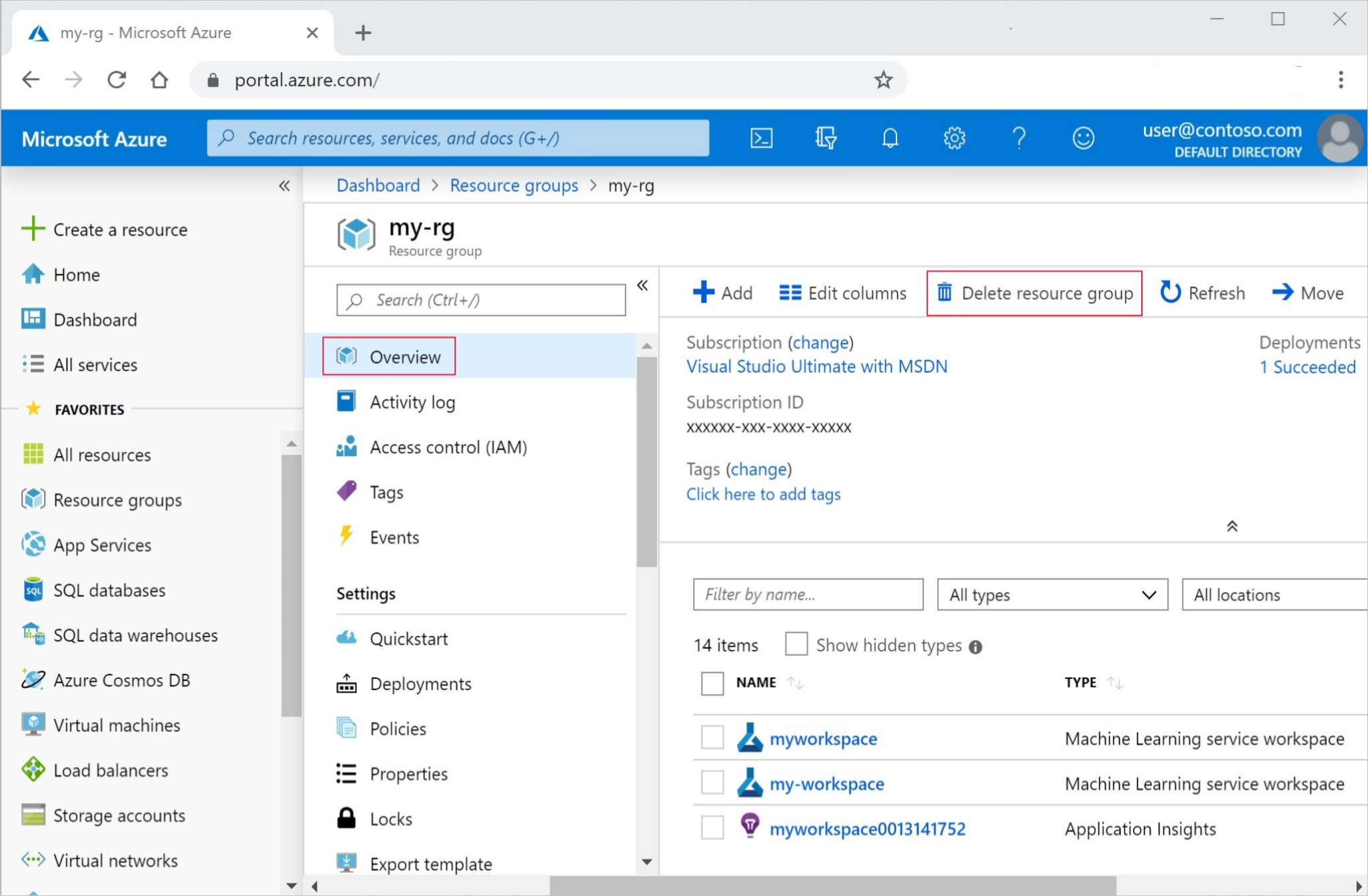
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
Pour en savoir plus :
- Des artefacts aux modèles dans MLflow
- Utilisation de Git avec Azure Machine Learning
- Exécution de notebooks Jupyter dans votre espace de travail
- Utilisation d’un terminal d’instance de calcul dans votre espace de travail
- Gérer les sessions de notebook et de terminal
Ce tutoriel vous a montré les premières étapes du processus de création d’un modèle et du prototypage sur l’ordinateur où réside le code. Pour votre entraînement de production, découvrez comment utiliser ce script d’entraînement sur des ressources de calcul distantes plus puissantes :