Procédure de configuration de la réplication des données entrantes pour Azure Database pour MySQL - Serveur flexible
S’APPLIQUE À :  Azure Database pour MySQL – Serveur flexible
Azure Database pour MySQL – Serveur flexible
Cet article décrit la procédure de configuration de la Réplication des données entrantes dans le serveur flexible Azure Database pour MySQL en configurant les serveurs source et réplica. Cet article suppose que vous avez déjà utilisé des serveurs et des bases de données MySQL.
Notes
Cet article contient des références au terme esclave, un terme que Microsoft n’utilise plus. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Pour créer un réplica dans l’instance de serveur flexible Azure Database pour MySQL, Réplication des données entrantes synchronise les données provenant d’un serveur MySQL source qui s’exécute localement dans des machines virtuelles ou des services de base de données cloud. La réplication des données entrantes peut être configurée à l’aide d’une réplication basée sur la position du fichier de journal binaire (binlog) ou d’une réplication basée sur GTID. Si vous souhaitez obtenir plus d’informations sur la réplication binlog, consultez la Réplication MySQL.
Passez en revue les limitations et conditions requises de la Réplication des données entrantes avant de suivre les étapes décrites dans cet article.
Créer une instance de serveur flexible Azure Database pour MySQL à utiliser comme réplica
Créez une instance Azure Database pour MySQL : serveur flexible (par exemple,
replica.mysql.database.azure.com). Reportez-vous à Création d’une instance de serveur flexible Azure Database pour MySQL à l’aide du portail Azure pour la création de serveurs. Ce serveur est le serveur « réplica » pour la réplication des données entrantes.Créez les mêmes comptes d’utilisateur et les privilèges correspondants.
Les comptes d’utilisateur ne sont pas répliqués à partir du serveur source vers le serveur réplica. Si vous prévoyez de donner accès au serveur réplica aux utilisateurs, vous devez créer manuellement tous les comptes et les privilèges correspondants sur cette nouvelle instance de serveur flexible Azure Database pour MySQL.
Configurer le serveur MySQL source
Les étapes suivantes servent à préparer et à configurer le serveur MySQL hébergé localement, dans une machine virtuelle ou par un service de base de données hébergé par d’autres fournisseurs de cloud pour la réplication de données entrantes. Ce serveur est la « source » pour la réplication des données entrantes.
Avant de continuer, passez en revue les prérequis du serveur source.
Configuration réseau requise
Vérifiez que le serveur source autorise le trafic entrant et sortant sur le port 3306, qu’il dispose d’une adresse IP publique et que le DNS est accessible publiquement, ou qu’il a un nom de domaine complet (FQDN).
Si l’accès privé (intégration VNet) est utilisé, assurez-vous que vous disposez d’une connectivité entre le serveur source et le réseau virtuel dans lequel le serveur réplica est hébergé.
Veillez à fournir une connectivité de site à site à vos serveurs sources locaux par le biais d’ExpressRoute ou d’un VPN. Pour plus d’informations sur la création d’un réseau virtuel, consultez la documentation sur le réseau virtuel, en particulier les articles sur le démarrage rapide, qui fournissent des informations pas à pas.
Si l’accès privé (intégration VNet) est utilisé dans le serveur réplica et que votre source est une machine virtuelle Azure, assurez-vous que la connectivité de réseau virtuel à réseau virtuel est établie. L’apparage de réseaux virtuels est pris en charge. Vous pouvez également utiliser d’autres méthodes de connectivité pour la communication entre réseaux virtuels dans différentes régions, telles que la connexion de réseau virtuel à réseau virtuel. Pour plus d’informations, vous pouvez consulter Passerelle VPN de réseau virtuel à réseau virtuel.
Assurez-vous que les règles de groupe de sécurité réseau de votre réseau virtuel ne bloquent pas le port sortant 3306 (également entrant si MySQL est en cours d’exécution sur une machine virtuelle Azure). Pour plus d’informations sur le filtrage du trafic de groupe de sécurité réseau de réseau virtuel, consultez l’article Filtrer le trafic avec les groupes de sécurité réseau.
Configurez les règles de pare-feu de votre serveur source pour autoriser l’adresse IP du serveur réplica.
Suivez les étapes appropriées selon si vous souhaitez utiliser l’emplacement du journal bin ou la réplication des données dans basée sur GTID.
Vérifiez si la journalisation binaire a été activée sur le serveur source en exécutant la commande suivante :
SHOW VARIABLES LIKE 'log_bin';Si la variable
log_binest renvoyée avec la valeur « ON », la journalisation binaire est activée sur votre serveur.Si
log_binest retourné avec la valeur « OFF » et que votre serveur source s’exécute localement ou sur des machines virtuelles où vous pouvez accéder au fichier de configuration (my.cnf), vous pouvez effectuer les étapes suivantes :recherchez votre fichier de configuration MySQL (my.cnf) dans le serveur source. Par exemple : /etc/my.cnf
Ouvrez le fichier de configuration pour le modifier, puis recherchez-y la section mysqld.
Dans la section mysqld, ajoutez la ligne suivante :
log-bin=mysql-bin.logRedémarrez le service MySQL sur le serveur source (ou redémarrez) pour appliquer les modifications.
Une fois le serveur redémarré, vérifiez que la journalisation binaire est activée en exécutant la même requête que précédemment :
SHOW VARIABLES LIKE 'log_bin';
Configurez les paramètres du serveur source.
La réplication des données entrantes nécessite que le paramètre
lower_case_table_namessoit cohérent entre les serveurs source et réplica. Par défaut, ce paramètre est défini sur 1 dans le serveur flexible Azure Database pour MySQL.SET GLOBAL lower_case_table_names = 1;Créez un rôle de réplication et définissez une autorisation.
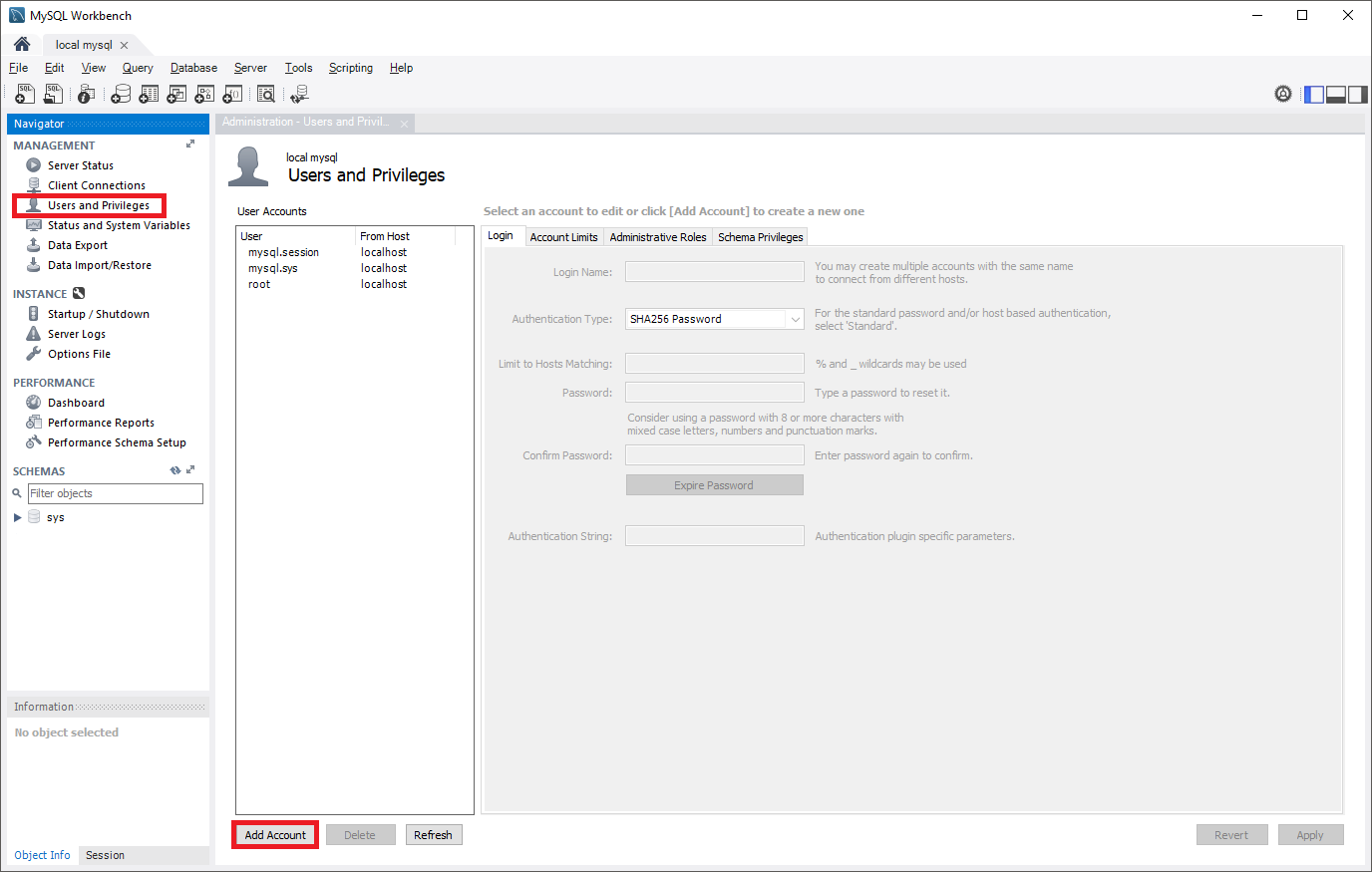
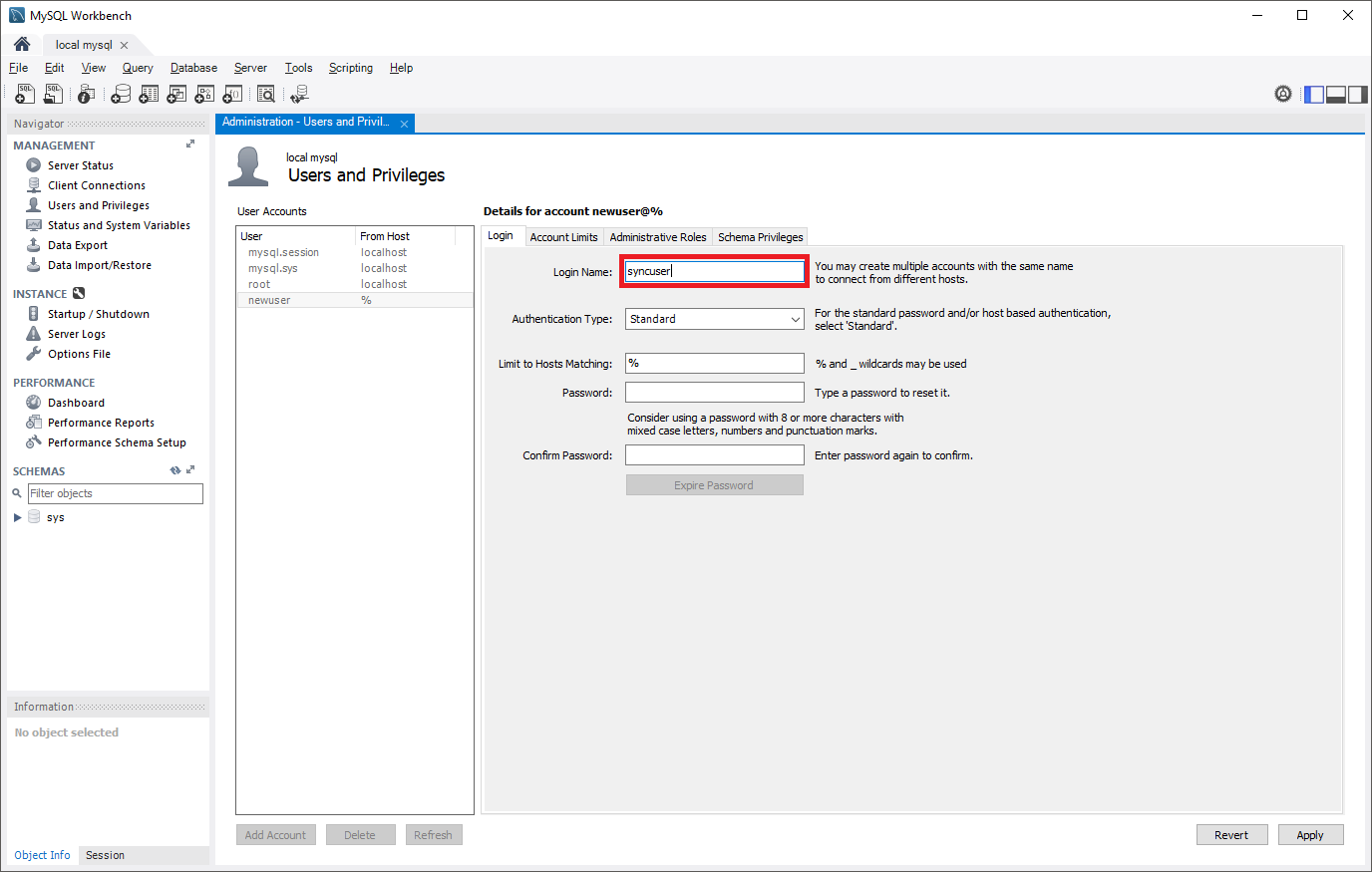
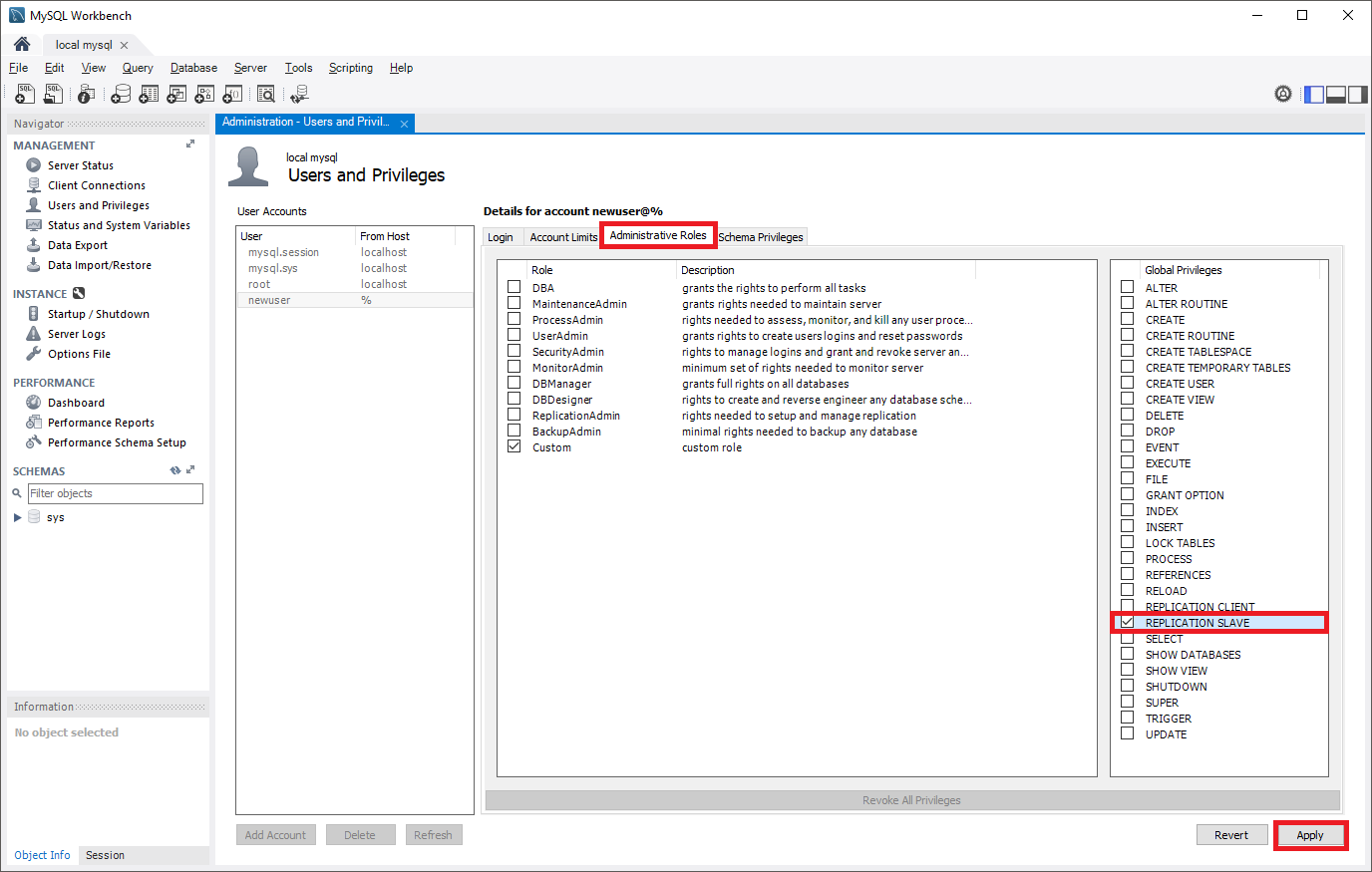
Créez un compte d’utilisateur sur le serveur source configuré avec des privilèges de réplication. Vous pouvez pour cela utiliser des commandes SQL ou un outil tel que MySQL Workbench. Si vous prévoyez une réplication avec SSL, cela doit être spécifié lors de la création de l’utilisateur. Pour comprendre comment ajouter des comptes d’utilisateur sur votre serveur source, reportez-vous à la documentation MySQL.
Dans les commandes suivantes, le nouveau rôle de réplication créé peut accéder à la source à partir de n’importe quel ordinateur, et pas seulement celui qui héberge la source. Cela s’effectue en spécifiant « syncuser@’%’ » dans la commande de création d’un utilisateur. Consultez la documentation MySQL pour en savoir plus sur la définition des noms de compte.
Réplication avec SSL
Pour exiger le protocole SSL pour toutes les connexions utilisateur, utilisez la commande suivante pour créer un utilisateur :
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%' REQUIRE SSL;Réplication sans SSL
Si le protocole SSL n’est pas requis pour toutes les connexions, utilisez la commande suivante pour créer un utilisateur :
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%';Définissez le serveur source en mode lecture seule.
Avant de commencer à vider la base de données, le serveur doit être placé en mode lecture seule. En mode lecture seule, le serveur source ne peut traiter aucune transaction d’écriture. Évaluer l’impact sur votre entreprise et planifiez la fenêtre de lecture seule lors d’une période creuse, si nécessaire.
FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;Récupérez le nom du fichier journal binaire et le décalage.
Exécutez la commande
show master statusafin de déterminer le nom de fichier du journal binaire actuel et le décalage.show master status;Les résultats doivent se présenter de la façon suivante. Veillez à noter le nom du fichier binaire, car vous en aurez besoin par la suite.

Vider et restaurer le serveur source
Déterminez les bases de données et les tables que vous souhaitez répliquer dans le serveur flexible Azure Database pour MySQL et effectuez la copie de sauvegarde à partir du serveur source.
Vous pouvez utiliser mysqldump pour vider les bases de données à partir de votre serveur principal. Pour plus d’informations, reportez-vous à Dump & Restore (Vider et restaurer). Il n’est pas nécessaire de vider la bibliothèque MySQL ni la bibliothèque de test.
Définissez le serveur source en mode lecture/écriture.
Une fois la base de données vidée, remettez le serveur MySQL source en mode lecture/écriture.
SET GLOBAL read_only = OFF; UNLOCK TABLES;Remarque
Avant que le serveur ne soit rétabli en mode lecture/écriture, vous pouvez récupérer des informations GTID en utilisant la variable globale GTID_EXECUTED. Cela va être utilisé lors d’une étape ultérieure pour définir GTID sur le serveur réplica.
Restaurez le fichier de vidage sur le nouveau serveur.
Restaurez le fichier de sauvegarde sur le serveur créé dans le serveur flexible Azure Database pour MySQL. Reportez-vous à Dump & Restore (Vider et restaurer) pour savoir comment restaurer un fichier de vidage sur un serveur MySQL. Si le fichier de vidage est volumineux, transférez-le vers une machine virtuelle dans Azure au sein de la même région que votre serveur réplica. Restaurez-le sur l’instance de serveur flexible Azure Database pour MySQL à partir de la machine virtuelle.
Remarque
Si vous souhaitez éviter de définir la base de données en lecture uniquement lorsque vous sauvegardez et restaurez, vous pouvez utiliser mydumper/myloader.
Définir GTID dans le serveur réplica
Ignorer l’étape si vous utilisez la réplication basée sur l’emplacement du journal bin
Les informations GTID du fichier de sauvegarde provenant de la source sont requises pour réinitialiser l’historique GTID du serveur cible (réplica).
Utilisez ces informations GTID de la source pour exécuter la réinitialisation GTID sur le serveur réplica à l’aide de la commande CLI suivante :
az mysql flexible-server gtid reset --resource-group <resource group> --server-name <replica server name> --gtid-set <gtid set from the source server> --subscription <subscription id>
Pour plus d’informations, consultez Réinitialisation de GTID.
Remarque
La réinitialisation GTID ne peut pas être effectuée sur un serveur compatible avec la géo-redondance. Désactivez la géo-redondance pour effectuer la réinitialisation GTID sur le serveur. Vous pouvez réactiver l’option de géo-redondance après la réinitialisation de GTID. L’action de réinitialisation GTID invalide toutes les sauvegardes disponibles et, par conséquent, une fois la géo-redondance activée, la géo-restauration peut prendre un jour avant que la géo-restauration puisse être effectuée sur le serveur
Lier les serveurs source et réplica pour démarrer Réplication des données entrantes
Définissez le serveur source.
Toutes les fonctions de réplication de données entrantes sont effectuées par des procédures stockées. Vous trouverez toutes les procédures dans Procédures stockées de réplication de données entrantes. Les procédures stockées peuvent être exécutées dans l’interpréteur de commandes MySQL ou MySQL Workbench.
Pour lier deux serveurs et démarrer une réplication, connectez-vous au serveur réplica cible dans le service Azure Database pour MySQL, et définissez l’instance externe en tant que serveur source. Vous pouvez l’effectuer en utilisant la procédure stockée
mysql.az_replication_change_masteroumysql.az_replication_change_master_with_gtidsur le serveur Azure Database pour MySQL.CALL mysql.az_replication_change_master('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_log_file>', <master_log_pos>, '<master_ssl_ca>');CALL mysql.az_replication_change_master_with_gtid('<master_host>', '<master_user>', '<master_password>', <master_port>,'<master_ssl_ca>');- master_host : nom d’hôte du serveur source
- master_user : nom d’utilisateur pour le serveur source
- master_password : mot de passe pour le serveur source
- master_port : numéro de port sur lequel le serveur source écoute les connexions. (3306 est le port par défaut sur lequel MySQL écoute)
- master_log_file : nom de fichier du journal binaire à partir de l’exécution de
show master status - master_log_pos : position du journal binaire à partir de l’exécution de
show master status - master_ssl_ca : contexte du certificat d’autorité de certification. Si vous n’utilisez pas le protocole SSL, transmettez une chaîne vide.
Il est recommandé de transmettre ce paramètre comme variable. Pour plus d’informations, consultez les exemples suivants.
Notes
- Si le serveur source est hébergé dans une machine virtuelle Azure, activez l’option « Autoriser l’accès aux services Azure » pour autoriser les serveurs sources et de réplica à communiquer entre eux. Ce paramètre peut être modifié dans les options de sécurité de la connexion. Pour plus d’informations, consultez Gérer les règles de pare-feu à l’aide du portail.
- Si vous avez utilisé mydumper/myloader pour sauvegarder la base de données, vous pouvez obtenir les fichiers master_log_file et master_log_pos à partir du fichier /backup/metadata.
Exemples
Réplication avec SSL
La variable
@certest créée en exécutant les commandes MySQL suivantes :SET @cert = '-----BEGIN CERTIFICATE----- PLACE YOUR PUBLIC KEY CERTIFICATE'`S CONTEXT HERE -----END CERTIFICATE-----'La réplication avec SSL est définie entre un serveur source hébergé dans le domaine « companya.com » et un serveur réplica hébergé dans le serveur flexible Azure Database pour MySQL. Cette procédure stockée est exécutée sur le réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, @cert);CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, @cert);Réplication sans SSL
La réplication sans SSL est définie entre un serveur source hébergé dans le domaine « companya.com » et un serveur réplica hébergé dans le serveur flexible Azure Database pour MySQL. Cette procédure stockée est exécutée sur le réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, '');CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, '');Démarrez la réplication.
Appelez la procédure stockée
mysql.az_replication_startpour commencer la réplication.CALL mysql.az_replication_start;Vérifiez l’état de la réplication.
Appelez la commande
show slave statussur le serveur réplica pour afficher l’état de réplication.show slave status;Pour connaître l’état correct de la réplication, reportez-vous aux métriques de réplication - État des E/S du réplica et État SQL du réplica - dans la page Monitoring.
Si
Seconds_Behind_Masterest « 0 », la réplication fonctionne bien.Seconds_Behind_Masterindique que le retard du réplica. Si la valeur est différente de « 0 », cela signifie que le réplica est en train de traiter les mises à jour.
Autres procédures stockées utiles pour les opérations de réplication des données entrantes
Arrêter la réplication
Pour arrêter la réplication entre le serveur source et le serveur réplica, utilisez la procédure stockée suivante :
CALL mysql.az_replication_stop;
Supprimer la relation de réplication
Pour supprimer la relation entre le serveur source et le serveur réplica, utilisez la procédure stockée suivante :
CALL mysql.az_replication_remove_master;
Ignorer l’erreur de réplication
Pour ignorer une erreur de réplication et autoriser la poursuite de la réplication, utilisez la procédure stockée suivante :
CALL mysql.az_replication_skip_counter;
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos][LIMIT [offset,] row_count]

Étapes suivantes
- En savoir plus sur la Réplication des données entrantes pour le serveur flexible Azure Database pour MySQL.