Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA
Azure NetApp Files fournit des partages NFS natifs qui peuvent être utilisés pour les volumes /hana/shared, /hana/data et /hana/log. L’utilisation de partages NFS basés sur ANF pour les volumes /hana/data et /hana/log nécessite l’utilisation du protocole NFS v4.1. Le protocole NFS v3 n’est pas pris en charge pour l’utilisation de volumes /hana/data et /hana/log quand les partages sont basés sur ANF.
Important
L’utilisation du protocole NFS v3 implémenté sur Azure NetApp Files n’est pas prise en charge pour /hana/data et /hana/log. L’utilisation du NFS 4.1 est obligatoire pour les volumes /hana/data et /hana/log d’un point de vue fonctionnel. En revanche, pour le volume /hana/shared, les systèmes NFS v3 ou NFS v4.1 peuvent tous eux être utilisés d’un point de vue fonctionnel.
Points importants à prendre en compte
Lorsque vous envisagez d’utiliser Azure NetApp Files pour SAP Netweaver et SAP HANA, tenez compte des importantes considérations suivantes :
Pour connaître les limites des pools de capacité et de volume, consultez Limites des ressources Azure NetApp Files.
Les partages NFS basés sur Azure NetApp Files et les machines virtuelles qui montent ces partages doivent se trouver dans le même réseau virtuel Azure ou dans des réseaux virtuels appairés dans la même région.
Le réseau virtuel sélectionné doit avoir un sous-réseau délégué à Azure NetApp Files. Pour la charge de travail SAP, il est fortement recommandé de configurer une plage /25 pour le sous-réseau délégué à Azure NetApp Files.
Les machines virtuelles doivent être déployées à proximité suffisante du stockage Azure NetApp pour avoir une latence plus faible comme, par exemple, en a besoin SAP HANA pour les écritures de journal de restauration.
- Azure NetApp Files a des fonctionnalités permettant de déployer des volumes NFS dans des zones de disponibilité Azure spécifiques. Ce type de proximité zonale est suffisant dans la majorité des cas pour obtenir une latence inférieure à 1 milliseconde. La fonctionnalité est en préversion publique et décrite dans l’article Gérer le placement des volumes de zone de disponibilité pour Azure NetApp Files. Cette fonctionnalité ne nécessite aucun processus interactif avec Microsoft pour avoir une proximité entre votre machine virtuelle et les volumes NFS que vous allouez.
- Pour obtenir une proximité optimale, la fonctionnalité des groupes de volumes d’application est disponible. Cette fonctionnalité ne recherche pas seulement la proximité optimale, elle cherche le placement optimal des volumes NFS pour que les données HANA et les volumes de fichier journal de restauration soient gérés par différents contrôleurs. L’inconvénient est que cette méthode nécessite un processus interactif avec Microsoft pour épingler vos machines virtuelles.
Vérifiez que la latence entre le serveur de base de données et le volume Azure NetApp Files est mesurée et inférieure à 1 milliseconde.
Le débit d’un volume NetApp Azure est une fonction du quota de volume et du niveau de service, comme décrit dans Niveau de service pour Azure NetApp Files. Lors du dimensionnement de volumes HANA Azure NetApp, assurez-vous que le débit obtenu répond à la configuration système requise pour HANA. Vous pouvez également envisager d’utiliser un pool de capacité QoS manuel dans lequel la capacité et le débit du volume peuvent être configurés et mis à l’échelle indépendamment (pour découvrir des exemples spécifiques relatifs à la plateforme SAP Hana, consultez ce document)
Essayez de « consolider » les volumes pour obtenir des performances plus élevées dans un volume plus grand ; par exemple, utilisez un volume pour /sapmnt, /usr/sap/trans, … dans la mesure du possible.
Azure NetApp Files propose une stratégie d’exportation : vous pouvez contrôler les clients autorisés, le type d’accès (lecture et écriture, lecture seule, etc.).
L’ID utilisateur pour sidadm et l’ID de groupe pour
sapsyssur les machines virtuelles doivent correspondre à la configuration dans Azure NetApp files.Implémenter des paramètres de système d’exploitation Linux mentionnés dans la note SAP 3024346
Important
Pour les charges de travail SAP HANA, une latence faible est critique. Collaborez avec votre représentant Microsoft pour vous assurer que les machines virtuelles et les volumes Azure NetApp Files soient déployés à proximité.
Important
En cas d’incompatibilité entre l’ID d’utilisateur pour sidadm et l’ID de groupe pour sapsys entre la machine virtuelle et la configuration Azure NetApp, les autorisations pour les fichiers sur les volumes NetApp Azure, montés sur les machines virtuelles, s’afficheront en tant que nobody. Veillez à spécifier l’ID d’utilisateur correct pour sidadm et l’ID de groupe pour sapsys, lors de l’intégration d’un nouveau système à Azure NetApp Files.
Option de montage NCONNECT
Nconnect est une option de montage pour les volumes NFS hébergés sur Azure NetApp Files qui permet au client NFS d’ouvrir plusieurs sessions sur un même volume NFS. L’utilisation de nconnect avec une valeur supérieure à 1 déclenche également l’utilisation par le client NFS de plusieurs sessions RPC côté client (dans le système d’exploitation invité) pour gérer le trafic entre le système d’exploitation invité et les volumes NFS montés. L’utilisation de plusieurs sessions gérant le trafic d’un volume NFS, mais également l’utilisation de plusieurs sessions RPC peuvent traiter des scénarios de performances et de débit tels que :
- Montage de plusieurs volumes NFS hébergés par Azure NetApp Files avec différents niveaux de service dans une même machine virtuelle
- Le débit d’écriture maximal pour un volume et une session Linux unique est compris entre 1,2 et 1,4 Go/s. Avoir plusieurs sessions sur un même volume NFS hébergé par Azure NetApp Files peut augmenter le débit.
Pour les versions de système d’exploitation Linux qui prennent en charge nconnect en tant qu’option de montage et certaines considérations importantes en matière de configuration de nconnect, en particulier avec différents points de terminaison de serveur NFS, lisez le document Meilleures pratiques des options de montage NFS Linux pour Azure NetApp Files.
Dimensionnement de la base de données HANA sur Azure NetApp Files
Le débit d’un volume NetApp Azure est fonction de la taille du volume et du niveau de service, comme décrit dans Niveaux de service pour Azure NetApp Files.
Il est important de comprendre la relation entre les performance et la taille, et qu’un point de terminaison de stockage du service présente des limites physiques. Durant leur création, chaque point de terminaison de stockage va être dynamiquement injecté dans le sous-réseau délégué Azure NetApp Files et se verra attribuer une adresse IP. Selon la capacité disponible et la logique de déploiement, des volumes Azure NetApp Files peuvent partager un point de terminaison de stockage
Le tableau ci-dessous montre qu’il peut être judicieux de créer un grand volume « Standard » pour stocker les sauvegardes, et qu’il n’est pas judicieux de créer un volume « Ultra » d’une taille supérieure à 12 To, car la capacité de bande passante physique maximale d’un volume unique serait dépassée.
Si vous avez besoin d’un débit d’écriture supérieur au débit d’écriture maximal pour votre volume /hana/data qu’une session Linux unique peut fournir, vous pouvez également utiliser le partitionnement du volume de données SAP HANA comme alternative. Le partitionnement de volume de données SAP HANA agrège par bandes l’activité d’E/S pendant le rechargement des données ou les points d’enregistrement HANA sur plusieurs fichiers de données HANA situés sur plusieurs partages NFS. Pour plus d’informations sur l’agrégation par bandes des volumes de données HANA, consultez ces articles :
- Guide de l’administrateur HANA
- Blog sur SAP HANA – Partitionnement des volumes de données
- Note SAP N° 2400005
- Note SAP n° 2700123
| Taille | Débit Standard | Débit Premium | Débit Ultra |
|---|---|---|---|
| 1 To | 16 Mo/s | 64 Mo/s | 128 Mo/s |
| 2 To | 32 Mo/s | 128 Mo/s | 256 Mo/s |
| 4 To | 64 Mo/s | 256 Mo/s | 512 Mo/s |
| 10 To | 160 Mo/s | 640 Mo/s | 1 280 Mo/s |
| 15 To | 240 Mo/s | 960 Mo/s | 1 400 Mo/sec1 |
| 20 To | 320 Mo/s | 1 280 Mo/s | 1 400 Mo/sec1 |
| 40 To | 640 Mo/s | 1 400 Mo/sec1 | 1 400 Mo/sec1 |
1 : limites de débit de lecture d’écriture ou de session unique (si l’option de montage NFS nconnect n’est pas utilisée)
Il est important de comprendre que les données sont écrites sur les mêmes disques SSD sur le back-end de stockage. Le quota de performances du pool de capacité a été créé afin de pouvoir gérer l’environnement. Les KPI de stockage sont identiques pour toutes les tailles de base de données HANA. Dans presque tous les cas, cette hypothèse ne reflète pas la réalité et les attentes du client. La taille des systèmes HANA ne signifie pas nécessairement qu’un petit système nécessite un faible débit de stockage et qu’un grand système nécessite un débit de stockage élevé, mais en général nous pouvons nous attendre à des exigences de débit plus élevées pour les instances de base de données HANA plus volumineuses. En raison des règles de dimensionnement de SAP pour le matériel sous-jacent, ces instances HANA plus volumineuses fournissent également davantage de ressources de processeur et un parallélisme plus élevé dans des tâches telles que le chargement des données après un redémarrage d’instances. Par conséquent, les tailles de volume adoptées doivent répondre aux attentes et aux besoins des clients, et ne doivent pas être motivées uniquement par de pures exigences de capacité.
Quand vous concevez l’infrastructure pour SAP dans Azure, vous devez connaître les exigences de débit de stockage minimal (pour les systèmes de production) de SAP. Ces exigences se traduisent par des caractéristiques de débit minimal de :
| Type de volume et type d’E/S | KPI minimal exigé par SAP | Niveau de service Premium | Niveau de service Ultra |
|---|---|---|---|
| Écriture du volume de journal | 250 Mo/s | 4 To | 2 To |
| Écriture du volume de données | 250 Mo/s | 4 To | 2 To |
| Lecture du volume de données | 400 Mo/s | 6,3 To | 3,2 To |
Étant donné que les trois KPI sont exigés, le volume /hana/data doit être dimensionné vers la plus grande capacité afin de respecter les exigences de lecture minimales. Si vous utilisez des pools de capacité QoS manuels, la taille et le débit des volumes peuvent être définis indépendamment. Étant donné que la capacité et le débit sont établis à partir du même pool de capacité, le niveau de service et la taille du pool doivent être suffisamment importants pour fournir les performances totales attendues (voir l’exemple ici)
Pour les systèmes HANA, qui ne nécessitent pas une bande passante élevée, le débit du volume Azure NetApp Files peut être réduit via une taille de volume inférieure ou, avec une QoS manuelle, en ajustant directement le débit. Dans le cas où un système HANA nécessite un débit plus élevé, le volume peut être adapté en redimensionnant la capacité en ligne. Aucun KPI n’est défini pour les volumes de sauvegarde. Toutefois, le débit du volume de sauvegarde est essentiel pour un environnement performant. Les performances des volumes de journal et de données doivent être conçues afin de répondre aux attentes des clients.
Important
Indépendamment de la capacité que vous déployez sur un volume NFS unique, le débit est supposé atteindre un plateau dans la plage de bande passante de 1,2 à 1,4 Go/s utilisée par un consommateur au cours d’une session. Ceci est lié à l’architecture sous-jacente de l’offre Azure NetApp Files et aux limites de session Linux associées relatives à NFS. Les valeurs de performances et de débit décrites dans l’article Résultats des tests de performances pour Azure NetApp Files ont été effectuées sur un volume NFS partagé avec plusieurs machines virtuelles clientes et, par conséquent, avec plusieurs sessions. Ce scénario est différent du scénario que nous mesurons dans SAP, où nous mesurons le débit depuis une seule machine virtuelle par rapport à un volume NFS hébergé sur Azure NetApp Files.
Pour respecter les exigences de débit minimal SAP pour les données et le journal, et conformément aux instructions pour /hana/shared, les tailles recommandées ressemblent à ceci :
| Volume | Taille Niveau de stockage Premium |
Taille Niveau de stockage Ultra |
Protocole NFS pris en charge |
|---|---|---|---|
| /hana/log/ | 4 Tio | 2 Tio | v4.1 |
| /hana/data | 6,3 Tio | 3,2 Tio | v4.1 |
| /hana/shared scale-up | Min (1 To, 1 x RAM) | Min (1 To, 1 x RAM) | v3 ou v4.1 |
| /hana/shared scale-out | 1 x RAM de nœud Worker par quatre nœuds Worker |
1 x RAM de nœud Worker par quatre nœuds Worker |
v3 ou v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 ou v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 ou v4.1 |
Pour tous les volumes, NFS v 4.1 est fortement recommandé.
Examinez attentivement les considérations relatives au dimensionnement du volume /hana/shared, car un volume /hana/shared bien dimensionné contribue à la stabilité du système.
Les tailles des volumes de sauvegarde sont des estimations. Des exigences précises doivent être définies en fonction de la charge de travail et des processus d’exploitation. Pour les sauvegardes, vous pouvez regrouper de nombreux volumes pour différentes instances de SAP HANA sur un (ou deux) volumes plus grands, qui peuvent avoir un niveau de service Azure NetApp Files inférieur.
Remarque
Les recommandations relatives aux tailles Azure NetApp Files qui sont indiquées dans ce document ciblent la configuration minimale stipulée par SAP à ses fournisseurs d’infrastructure. Dans les déploiements de clients et les scénarios de charge de travail réels, cela peut ne pas suffire. Prenez ces recommandations en tant que point de départ et adaptez-les en fonction des exigences de votre charge de travail spécifique.
Par conséquent, vous pouvez envisager de déployer un débit similaire pour les volumes Azure NetApp Files tels qu’ils sont déjà listés pour les disques de stockage Ultra. Prenez également en compte les tailles listées pour les volumes des différentes références SKU de machine virtuelle, comme déjà indiqué dans les tables de disques Ultra.
Conseil
Vous pouvez redimensionner les volumes Azure NetApp Files de manière dynamique, sans avoir à unmount les volumes, à arrêter les machines virtuelles ou à arrêter SAP HANA. Cela permet de répondre aux exigences à la fois attendues et imprévues de votre application en matière de débit.
La documentation sur le déploiement d’une configuration de scale-out de SAP HANA avec un nœud de secours en utilisant des volumes NFS v4.1 basés sur Azure NetApp Files est publiée dans Scale-out de SAP HANA avec un nœud de secours sur des machines virtuelles Azure avec Azure NetApp Files sur SUSE Linux Enterprise Server.
Paramètres du noyau Linux
Pour déployer SAP HANA sur Azure NetApp Files, les paramètres du noyau Linux doivent être implémentés conformément à la note SAP 3024346.
Pour les systèmes utilisant la haute disponibilité (HA) avec pacemaker et Azure Load Balancer, les paramètres suivants doivent être implémentés dans le fichier /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Les systèmes s’exécutant sans pacemaker ni Azure Load Balancer doivent implémenter ces paramètres dans /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Déploiement avec proximité zonale
Pour obtenir une proximité zonale de vos volumes NFS et vos machines virtuelles, vous pouvez suivre les instructions décrites dans Gérer le placement des volumes de zone de disponibilité pour Azure NetApp Files. Avec cette méthode, les machines virtuelles et les volumes NFS se trouvent dans la même zone de disponibilité Azure. Dans la plupart des régions Azure, ce type de proximité doit être suffisant pour avoir une latence inférieure à 1 milliseconde dans le cas des plus petites écritures de journal de restauration pour SAP HANA. Cette méthode ne nécessite aucun travail interactif avec Microsoft pour placer et épingler les machines virtuelles dans un centre de données spécifique. Par conséquent, vous pouvez facilement changer les tailles et les familles VM dans tous les types et familles VM proposés dans la zone de disponibilité que vous avez déployée. De cette façon, vous pouvez réagir de manière flexible quand les conditions changent ou passer plus rapidement à des tailles ou familles VM plus rentables. Nous recommandons cette méthode pour les systèmes hors production et les systèmes de production qui peuvent fonctionner avec des latences de journal de restauration plus proches de 1 milliseconde. Cette fonctionnalité est actuellement en préversion publique.
Déploiement via un groupe de volumes d’application Azure NetApp Files pour SAP HANA (AVG)
Pour déployer des volumes Azure NetApp Files à proximité de votre machine virtuelle, une nouvelle fonctionnalité appelée Groupe de volumes d’application Azure NetApp Files pour SAP HANA (AVG) a été développée. Une série d’articles documentent la fonctionnalité. Il est préférable de commencer par l’article Comprendre le groupe de volumes d’application Azure NetApp Files pour SAP HANA. À mesure que vous allez lire les articles, vous allez comprendre que l’utilisation de groupes de volumes d’application implique aussi celle de groupes de placement de proximité Azure. Les groupes de placement de proximité sont utilisés par la nouvelle fonctionnalité pour s’associer aux volumes créés. Pour garantir que tout au long de la durée de vie du système HANA, les machines virtuelles ne sont pas retirées des volumes Azure NetApp Files, nous vous recommandons d’utiliser une combinaison de groupe à haute disponibilité/groupe de placement de proximité pour chacune des zones où vous déployez. L’ordre de déploiement va ressembler à celui-ci :
- À l’aide du formulaire, vous devez demander l’épinglage du groupe à haute disponibilité vide sur du matériel de calcul pour veiller à ce que les machines virtuelles ne soient pas déplacées.
- Affecter un groupe de placement de proximité au groupe à haute disponibilité et démarrer une machine virtuelle affectée à ce groupe à haute disponibilité
- Utiliser la fonctionnalité de groupe de volumes d’application Azure NetApp Files pour SAP HANA pour déployer vos volumes HANA
La configuration du groupe de placement de proximité pour utiliser des groupes de volumes d’application de manière optimale ressemble à celle-ci :
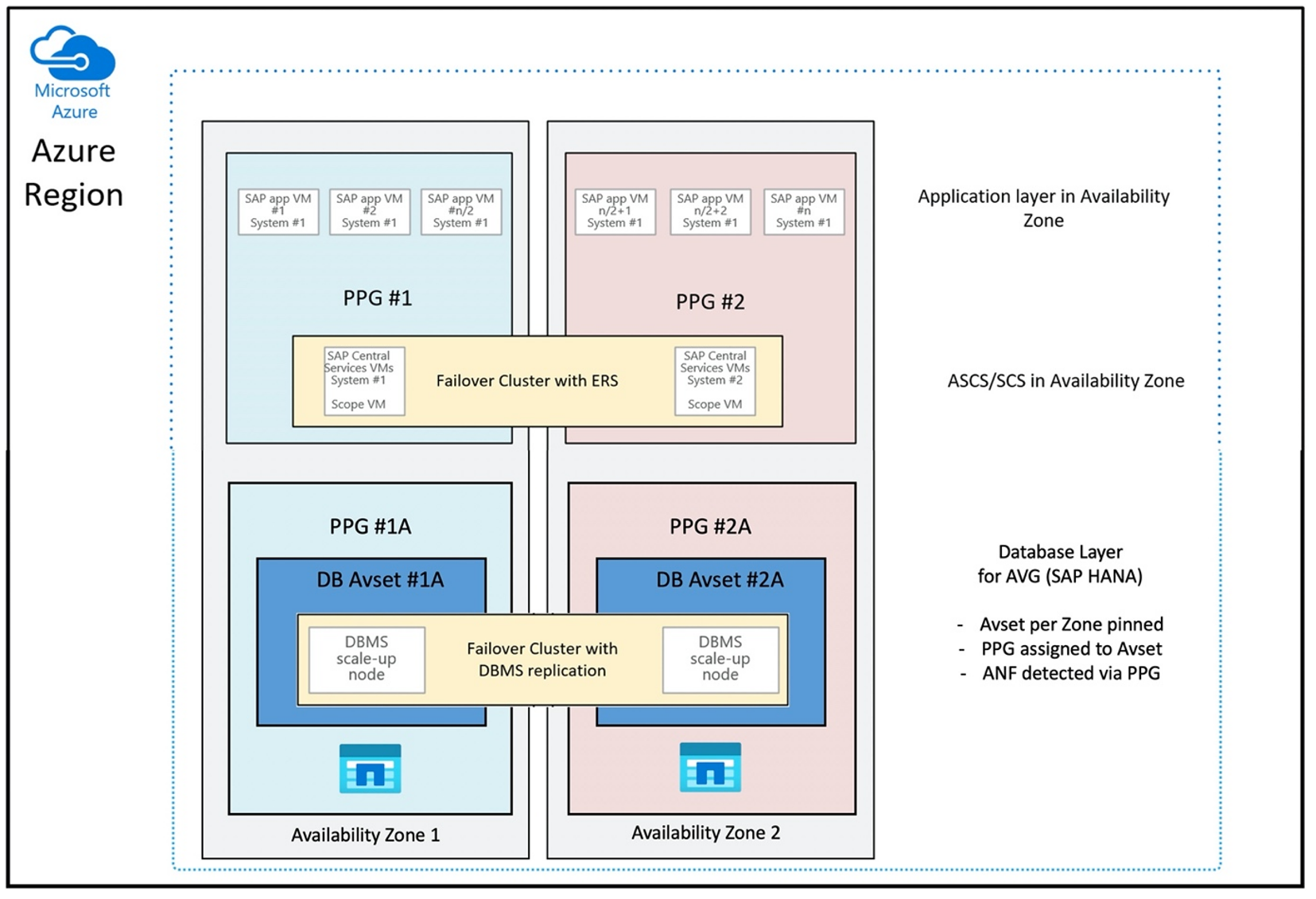
Le diagramme montre que vous allez utiliser un groupe de placement de proximité Azure pour la couche SGBD. Ainsi, il peut être utilisé avec des groupes de volumes d’application. De préférence, ajoutez uniquement les machines virtuelles qui exécutent les instances HANA dans le groupe de placement de proximité. Le groupe de placement de proximité est nécessaire, même si une seule machine virtuelle avec une seule instance HANA est utilisée, pour que le groupe de volumes d’application identifie la proximité optimale du matériel Azure NetApp Files, et pour allouer le volume NFS sur Azure NetApp Files aussi près que possible des machines virtuelles qui utilisent les volumes NFS.
Cette méthode génère des résultats optimaux pour avoir une latence faible, non seulement en rapprochant au maximum les volumes NFS et les machines virtuelles, mais en tenant également compte du placement des volumes de données et de journal de restauration sur différents contrôleurs du back-end NetApp. Toutefois, l’inconvénient est que votre déploiement VM est épinglé dans un seul centre de données. Vous avez alors moins de flexibilité pour changer les types et familles VM. Par conséquent, réservez cette méthode aux systèmes qui nécessitent absolument cette latence faible de stockage. Pour tous les autres systèmes, vous devez tenter le déploiement avec un déploiement zonal traditionnel de la machine virtuelle et d’Azure NetApp Files. Dans la plupart des cas, cela suffit en termes de faible latence. Ceci garantit également une maintenance et une administration faciles de la machine virtuelle et d’Azure NetApp Files.
Disponibilité
Les mises à jour et mises à niveau du système ANF sont appliquées sans affecter l’environnement du client. Le contrat SLA défini est de 99,99 %.
Volumes et adresses IP et pools de capacité
Avec ANF, il est important de comprendre comment l’infrastructure sous-jacente est créée. Un pool de capacité n’est qu’une construction qui fournit un budget de capacité et de performance, ainsi qu’une unité de facturation, en fonction de son niveau de service. Un pool de capacité n’a pas de relation physique avec l’infrastructure sous-jacente. Lorsque vous créez un volume sur le service, un point de terminaison de stockage est créé. Une adresse IP unique est attribuée à ce point de terminaison de stockage pour fournir un accès aux données du volume. Si vous créez plusieurs volumes, ceux-ci sont distribués au sein du parc de matériel nu sous-jacent lié à ce point de terminaison de stockage. ANF a une logique qui distribue automatiquement les charges de travail des clients une fois que les volumes et/ou la capacité du stockage configuré atteignent un niveau prédéfini interne. Vous pouvez rencontrer de tels cas, car un nouveau point de terminaison de stockage, avec une nouvelle adresse IP, est créé automatiquement pour accéder aux volumes. Le service Azure NetApp Files (ANF) ne permet pas au client de contrôler cette logique de distribution.
Volume du journal et volume de sauvegarde du journal
Le « volume du journal » ( /hana/log) est utilisé pour écrire le journal de phase de restauration par progression en ligne. Il existe donc des fichiers ouverts sur ce volume, et cela n’a pas de sens de créer une capture instantanée de ce volume. Les fichiers journaux de phase de restauration par progression en ligne sont archivés ou sauvegardés sur le volume de sauvegarde du journal une fois que le fichier journal de phase de restauration par progression en ligne est plein ou qu’une sauvegarde du journal de phase de restauration par progression est exécutée. Pour garantir des performances de sauvegarde raisonnables, le volume de sauvegarde du journal nécessite un bon débit. Pour optimiser les coûts de stockage, il peut être judicieux de consolider le volume de sauvegarde du journal de plusieurs instances HANA, afin que plusieurs instances HANA utilise le même volume et écrivent leurs sauvegardes dans des répertoires différents. Avec une telle consolidation, vous pouvez obtenir un débit plus élevé, car vous devez augmenter la taille du volume.
Il en va de même pour le volume sur lequel vous écrivez des sauvegardes complètes de base de données HANA.
Sauvegarde
En plus des sauvegardes en streaming et de la sauvegarde de bases de données SAP HANA par le service Sauvegarde Azure, comme décrit dans l’article Guide de sauvegarde pour SAP HANA sur les machines virtuelles Azure, Azure NetApp Files offre la possibilité d’effectuer des sauvegardes d’instantanés basés sur le stockage.
SAP HANA prend en charge :
- Prise en charge des sauvegardes de captures instantanées basées sur le stockage pour un système à conteneur unique avec SAP HANA 1.0 SPS7 et versions ultérieures
- Prise en charge des sauvegardes de captures instantanées basées sur le stockage pour les environnements HANA de conteneur de plusieurs bases de données avec un seul tenant (locataire) avec SAP HANA 2.0 SPS1 et versions ultérieures
- Prise en charge des sauvegardes de captures instantanées basées sur le stockage pour les environnements HANA de conteneur de plusieurs bases de données avec plusieurs tenants (locataires) avec SAP HANA 2.0 SPS4 et versions ultérieures
La création de sauvegardes de captures instantanées basées sur le stockage est une procédure simple en quatre étapes.
- Création d’une capture instantanée de base de données HANA (interne) : activité qui doit être effectuée par vous-même ou par des outils.
- SAP HANA écrit les données dans les fichiers de données pour créer un état cohérent sur le stockage : HANA effectue cette étape suite à la création d’une capture instantanée HANA.
- Création d’une capture instantanée sur le volume /hana/data sur le stockage : étape qui doit être effectuée par vous-même ou par des outils. Il n’est pas nécessaire d’effectuer une capture instantanée sur le volume /hana/log.
- Suppression de la capture instantanée de base de données HANA (interne) et reprise des opérations normales : étape qui doit être effectuée par vous-même ou par des outils.
Avertissement
Ne pas effectuer la dernière étape aura un impact sérieux sur la demande en mémoire de SAP HANA et peut entraîner son arrêt.
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Cette procédure de sauvegarde de capture instantanée peut être gérée de diverses façons à l’aide de différents outils. Par exemple, avec le script Python « ntaphana_azure.py disponible » sur GitHub https://github.com/netapp/ntaphana. Il s’agit d’un exemple de code, fourni tel quel sans aucune maintenance ni prise en charge.
Attention
Une capture instantanée en elle-même n’est pas une sauvegarde protégée, car elle se trouve sur le même stockage physique que le volume dont vous venez d’effectuer une capture instantanée. Il est obligatoire de « protéger » au moins une capture instantanée par jour à un autre emplacement. Cela peut être fait dans le même environnement, dans une région Azure distante ou dans le stockage d’objets blob Azure.
Solutions disponibles pour la sauvegarde cohérente des applications basées sur des captures instantanées de stockage :
- L’outil Azure Application Consistent Snapshot est un outil en ligne de commande qui permet de protéger les données des bases de données tierces. Il gère toute l’orchestration nécessaire pour placer les bases de données dans un état de cohérence d’application avant de prendre un instantané du stockage. Une fois qu’a été pris l’instantané de stockage, l’outil repasse les bases de données à l’état opérationnel. AzAcSnap prend en charge les sauvegardes basées sur des captures instantanées pour HANA - Grande instance et Azure NetApp Files. Pour plus d’informations, lisez l’article Qu’est-ce que l’outil Azure Application Consistent Snapshot
- Pour les utilisateurs de produits de sauvegarde Commvault, l’autre option est Commvault IntelliSnap V.11.21 et versions ultérieures. Cette version de Commvault (ou les versions ultérieures) offre une prise en charge des captures instantanées Azure NetApp Files. L’article Commvault IntelliSnap 11.21 fournit plus d’informations.
Sauvegarder la capture instantanée à l’aide du stockage d’objets blob Azure
La sauvegarde dans le stockage d’objets blob Azure est une méthode économique et rapide pour enregistrer les sauvegardes de captures instantanées de stockage de base de données HANA basées sur ANF. Pour enregistrer les captures instantanées dans le Stockage Blob Azure, l’outil préconisé est AzCopy. Téléchargez la dernière version de cet outil et installez-la par exemple dans le répertoire bin où est installé le script Python de GitHub. Téléchargez la dernière version de l’outil AzCopy :
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
La fonctionnalité la plus avancée est l’option SYNC. Si vous utilisez l’option SYNC, azcopy maintient la synchronisation entre les répertoires source et de destination. L’utilisation du paramètre --delete-destination est importante. Sans ce paramètre, azcopy ne supprime pas les fichiers sur le site de destination, et l’utilisation de l’espace côté destination augmente. Créez un conteneur d’objets blob de blocs dans votre compte Stockage Azure. Ensuite, créez la clé SAS pour le conteneur d’objets blob et synchronisez le dossier de captures instantanées avec le conteneur d’objets blob Azure.
Par exemple, si une capture instantanée quotidienne doit être synchronisée avec le conteneur d’objets blob Azure pour protéger les données, et que seule cette capture instantanée doit être conservée, vous pouvez utiliser la commande ci-dessous.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Étapes suivantes
Lisez l’article suivant :