Surveiller l’intégrité de vos connecteurs de données
Pour garantir une ingestion de données complète et ininterrompue dans votre service Microsoft Sentinel, suivez l’intégrité, la connectivité et les performances de vos connecteurs de données.
Les fonctionnalités suivantes vous permettent d’effectuer cette supervision à partir de Microsoft Sentinel :
Workbook de monitoring de l’intégrité de la collecte de données : Ce classeur fournit des analyses supplémentaires, détecte les anomalies et donne un aperçu de l’état d’ingestion des données de l’espace de travail. Vous pouvez utiliser la logique du classeur pour surveiller l’intégrité générale des données ingérées, et créer des vues personnalisées et autres alertes basées sur des règles.
Table de données SentinelHealth (préversion) : l’interrogation de cette table fournit des insights sur les dérives d’intégrité, tels que les derniers événements d’échec par connecteur ou les connecteurs avec des changements d'état de réussite à échec, que vous pouvez utiliser pour créer des alertes et d’autres actions automatisées. La table de données SentinelHealth est actuellement prise en charge uniquement pour certains connecteurs de données.
Important
La table de données SentinelHealth est actuellement en PRÉVERSION. Consultez l’Avenant aux conditions d’utilisation pour les préversions de Microsoft Azure pour connaître les conditions juridiques supplémentaires s’appliquant aux fonctionnalités Azure sont en version bêta, en préversion ou non encore en disponibilité générale.
Afficher l’intégrité et l’état de vos systèmes SAP connectés : passez en revue les informations d’intégrité de vos systèmes SAP sous le connecteur de données SAP, puis utilisez un modèle de règle d’alerte pour obtenir des informations sur l’intégrité de la collecte de données de l’agent SAP.
Utiliser le classeur d’analyse du fonctionnement
Pour commencer, installez le classeur Monitoring de l’intégrité de la collecte de données à partir du Hub de contenu et affichez ou créez une copie du modèle à partir de la section Classeurs de Microsoft Sentinel.
Dans Microsoft Sentinel, dans le Portail Azure, sous Gestion du contenu, sélectionnez Hub de contenu.
Pour Microsoft Sentinel dans le portail Defender, sélectionnez Microsoft Sentinel>Gestion du contenu>Hub de contenu.Dans le Hub de contenu, dans la barre de recherche, entrez intégrité, puis sélectionnez Surveillance de l’intégrité de la collecte de données dans les résultats.
Sélectionnez Installer dans le volet d’informations. Lorsque vous voyez un message de notification indiquant que le classeur est installé ou si, au lieu d’Installer, vous voyez Configuration, passez à l’étape suivante.
Dans Microsoft Sentinel, sous Gestion des menaces, sélectionnez Classeurs.
Dans la page Classeurs, sélectionnez l’onglet Modèles, entrez intégrité dans la barre de recherche, puis sélectionnez Surveillance de l’intégrité de la collecte de données dans les résultats.
Sélectionnez Afficher le modèle pour utiliser le classeur tel quel, ou Enregistrer pour créer une copie modifiable du classeur. Une fois la copie créée, sélectionnez Afficher le classeur enregistré.
Une fois dans le classeur, commencez par sélectionner l’abonnement et l’espace de travail que vous souhaitez afficher, puis définissez la valeur TimeRange pour filtrer les données en fonction de vos besoins. Utilisez le bouton bascule Afficher l’aide pour afficher une explication à l’emplacement du classeur.
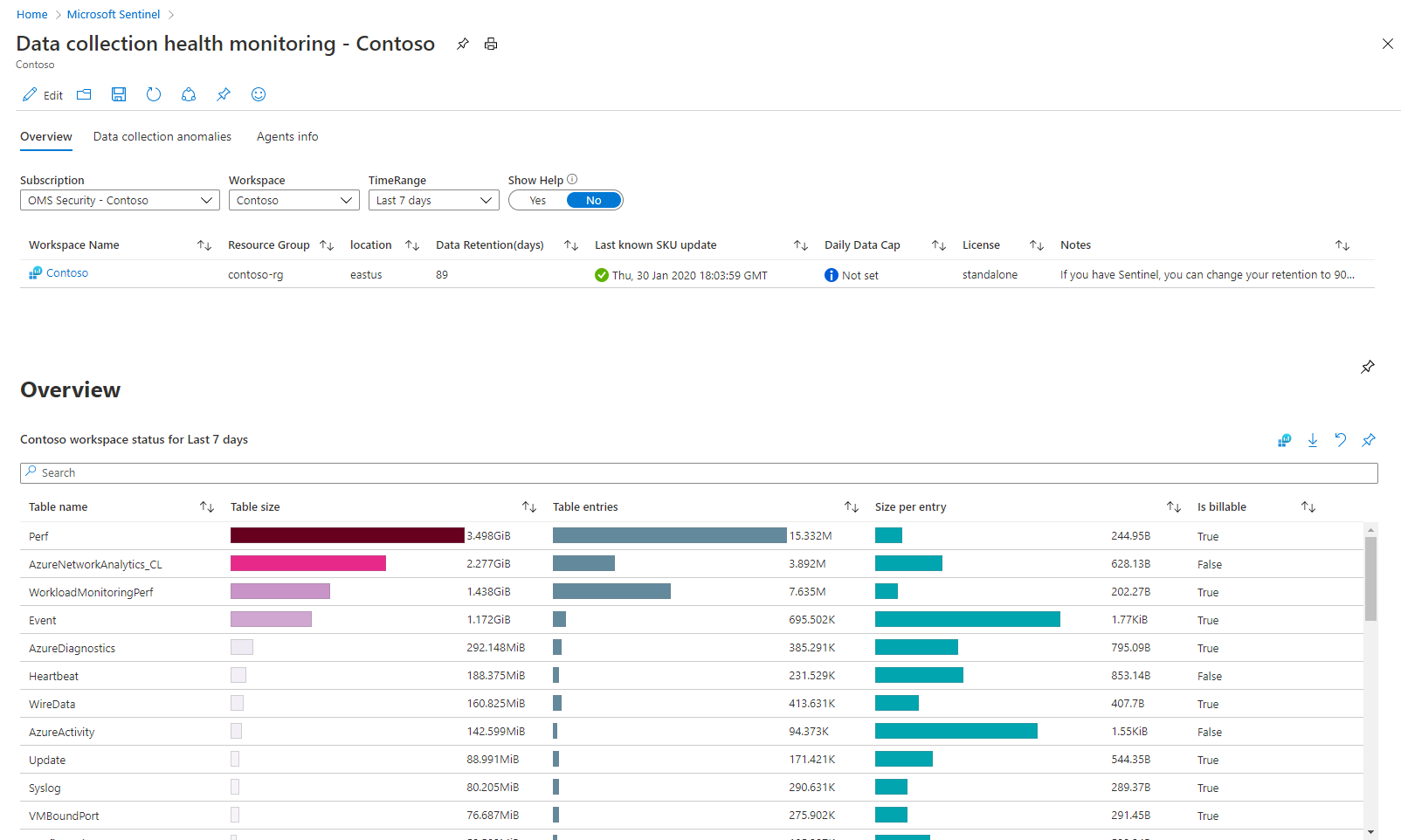

Ce classeur comporte trois sections dotées d’onglets :
L’onglet Vue d’ensemble affiche l’état général de l’ingestion de données dans l’espace de travail sélectionné : mesures du volume, taux d’EPS et heure de réception du dernier journal.
L’onglet Anomalies liées à la collecte de données vous aide à détecter des anomalies dans le processus de collecte des données, par table et source de données. Chaque onglet présente des anomalies pour une table particulière (l'onglet Général contient une collection de tables). Les anomalies sont calculées à l’aide de la fonction series_decompose_anomalies() qui retourne un score d’anomalie. Découvrez plus d’informations sur cette fonction. Définissez les paramètres suivants pour que la fonction les évalue :
AnomaliesTimeRange : Ce sélecteur d’heure s’applique uniquement à la vue des anomalies liées à la collecte de données.
SampleInterval : intervalle de temps pendant lequel les données sont échantillonnées dans l’intervalle de temps donné. Le score d’anomalie est calculé uniquement sur les données du dernier intervalle.
PositiveAlertThreshold : cette valeur définit le seuil du score d’anomalie positif. Elle accepte les valeurs décimales.
NegativeAlertThreshold : cette valeur définit le seuil du score d’anomalie négatif. Elle accepte les valeurs décimales.

L’onglet Informations de l’agent affiche des informations sur l’intégrité des agents installés sur vos différentes machines, qu’il s’agisse de machines virtuelles Azure, cloud, locales ou d’un ordinateur physique. Surveillez l’emplacement du système, l’état et la latence des pulsations, l’espace mémoire disponible et l’espace disque ainsi que les opérations de l’agent.
Dans cette section, vous devez sélectionner l’onglet qui décrit l’environnement de vos machines. Choisissez l’onglet Machines gérées par Azure si vous souhaitez afficher uniquement les machines gérées par Azure Arc, ou l’onglet Toutes les machines pour afficher les machines gérées et non gérées par Azure sur lesquelles l’agent Azure Monitor est installé.



Utilisez la table de données SentinelHealth (préversion publique)
Pour obtenir les données d’intégrité du connecteur de données à partir de la table de données SentinelHealth, vous devez d’abord activer la fonctionnalité Microsoft Sentinel Health pour votre espace de travail. Pour plus d’informations, consultez Activer la surveillance de l’intégrité pour Microsoft Sentinel.
Une fois la fonctionnalité d’intégrité activée, la table de données SentinelHealth est créée lors du premier événement de réussite ou d’échec généré pour vos connecteurs de données.
Connecteurs de données pris en charge
La table de données SentinelHealth est actuellement prise en charge uniquement pour les connecteurs de données suivants :
- Amazon Web Services (CloudTrail et S3)
- Dynamics 365
- Office 365
- Microsoft Defender for Endpoint
- Threat Intelligence - TAXII
- Threat Intelligence Platforms
- N’importe quel connecteur basé sur la Plateforme de connecteurs sans code
Fonctionnement des événements de table SentinelHealth
Les types d’événements d’intégrité suivants sont enregistrés dans la table SentinelHealth :
Modification de l’état de l’extraction des données. Consigné une fois par heure, tant que l’état d’un connecteur de données reste stable, avec des événements de réussite ou d’échec continus. Tant que l’état d’un connecteur de données ne change pas, la surveillance ne fonctionne que toutes les heures pour empêcher l’audit redondant et réduire la taille de la table. Si l’état du connecteur de données présente des défaillances continues, des informations supplémentaires sur les échecs sont incluses dans la colonne ExtendedProperties.
Si l’état du connecteur de données change, de réussite à échec, d’échec à réussite, l’événement est enregistré immédiatement pour permettre à votre équipe de prendre des mesures proactives et immédiates.
Les erreurs potentiellement temporaires, telles que la limitation du service source, sont journalisées uniquement après avoir continué pendant plus de 60 minutes. Ces 60 minutes autorisent Microsoft Sentinel à surmonter un problème temporaire dans le backend et à rattraper les données, sans intervention de l’utilisateur. Les erreurs qui ne sont définitivement pas temporaires sont journalisées immédiatement.
Récapitulatif des défaillances. Consigné une fois par heure, par connecteur, par espace de travail, avec un résumé agrégé des échecs. Les événements de résumé d’échec sont créés uniquement lorsque le connecteur a rencontré des erreurs d’interrogation pendant l’heure donnée. Ils contiennent des détails supplémentaires fournis dans la colonne ExtendedProperties, tels que la période pendant laquelle la plateforme source du connecteur a été interrogée, ainsi qu’une liste distincte des échecs survenus au cours de la période.
Pour plus d’informations, consultez Schéma des colonnes de la table SentinelHealth.
Exécuter des requêtes pour détecter les dérives d’intégrité
Créez des requêtes sur la table SentinelHealth pour vous aider à détecter les dérives d’intégrité dans vos connecteurs de données. Par exemple :
Détecter les événements d’échec les plus récents par connecteur :
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
Détecter les connecteurs avec les modifications de l’état échec à réussite :
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
Détecter les connecteurs avec les modifications de l’état réussite à échec :
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
Consultez plus d’informations sur les éléments suivants utilisés dans les exemples précédents dans la documentation Kusto :
- Instruction let
- Opérateur where
- Opérateur project
- Opérateur summarize
- joindre l’opérateur
- Fonction ago()
- arg_max() fonction d’agrégation
Pour découvrir plus d’informations sur KQL, consultez Vue d’ensemble du langage de requête Kusto (KQL).
Autres ressources :
Configurer des alertes et des actions automatisées pour les problèmes d’intégrité
Bien que vous puissiez utiliser les règles d’analyse Microsoft Sentinel pour configurer l’automatisation dans les journaux Microsoft Sentinel, si vous souhaitez être averti et prendre des mesures immédiates pour les dérives d’intégrité dans vos connecteurs de données, nous vous recommandons d’utiliser des règles d’alerte Azure Monitor.
Par exemple :
Dans une règle d’alerte Azure Monitor, sélectionnez votre espace de travail Microsoft Sentinel comme étendue de la règle et Recherche de journal personnalisé comme première condition.
Personnalisez la logique d’alerte en fonction des besoins, tels que la fréquence ou la durée de recherche arrière, puis utilisez les requêtes pour rechercher les dérives d’intégrité.
Pour les actions de règle, sélectionnez un groupe d’actions existant ou créez-en un en fonction des besoins pour configurer des notifications push ou d’autres actions automatisées, telles que le déclenchement d’une application logique, un webhook ou une fonction Azure dans votre système.
Pour plus d’informations, consultez Vue d’ensemble des alertes Azure Monitor et Journal des alertes Azure Monitor.
Étapes suivantes
- Découvrez l’audit et le monitoring de l’intégrité dans Microsoft Sentinel.
- Activez l’audit et le monitoring de l’intégrité dans Microsoft Sentinel.
- Surveillez l’intégrité de vos règles d’automatisation et guides opérationnel.
- Surveillez l’intégrité et l’intégrité de vos règles d’analytique.
- Découvrez-en plus sur les schémas des tables SentinelHealth et SentinelAudit.