Stratégies de positionnement pour les services Service Fabric
Les stratégies de positionnement sont des règles supplémentaires qui peuvent être utilisées pour régir le positionnement des services dans certains scénarios spécifiques moins courants. Voici quelques exemples de ces scénarios :
- Votre cluster Service Fabric s’étend sur différentes zones géographiques, par exemple avec plusieurs centres de données locaux ou dans différentes régions Azure
- Votre environnement s’étend sur plusieurs zones de contrôle géopolitique ou juridique, ou d’autres cas de figure où des limites en matière de stratégie doivent être appliquées
- Vous devez tenir compte de certains facteurs de performance ou de latence des communications en raison des grandes distances ou de l’utilisation de liaisons réseau plus lentes ou peu fiables
- Vous devez autant que possible maintenir la colocalisation de certaines charges de travail en utilisant d’autres charges de travail ou en les rapprochant des clients
- Vous avez besoin de plusieurs instances sans état d’une partition sur un seul nœud
La plupart de ces exigences correspondent à la disposition physique du cluster, représentée comme les domaines d’erreur du cluster.
Les stratégies de positionnement avancées qui contribuent à résoudre ces scénarios sont les suivantes :
- Domaines non valides
- Domaines requis
- Domaines par défaut
- Désactivation de la compression de réplica
- Autoriser plusieurs instances sans état sur le nœud
La plupart des commandes suivantes peuvent être configurées par le biais des propriétés de nœud et des contraintes de positionnement, mais certaines sont plus complexes. Pour simplifier les choses, Service Fabric Cluster Resource Manager fournit ces stratégies de positionnement supplémentaires. Les stratégies de positionnement sont configurées pour chaque instance de service nommée. Elles peuvent également être mises à jour dynamiquement.
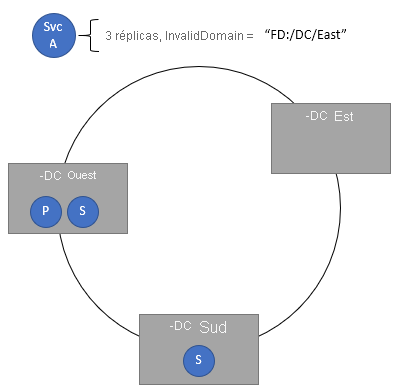
Spécification de domaines non valides
La stratégie de positionnement InvalidDomain vous permet de spécifier qu’un domaine d’erreur particulier n’est pas valide pour un service spécifique. Cette stratégie garantit qu’un service particulier ne s’exécute jamais dans une zone particulière, par exemple pour des raisons de stratégie géopolitiques ou d’entreprise. Vous pouvez spécifier plusieurs domaines non valides par le biais de différentes stratégies.
Code :
ServicePlacementInvalidDomainPolicyDescription invalidDomain = new ServicePlacementInvalidDomainPolicyDescription();
invalidDomain.DomainName = "fd:/DCEast"; //regulations prohibit this workload here
serviceDescription.PlacementPolicies.Add(invalidDomain);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("InvalidDomain,fd:/DCEast”)
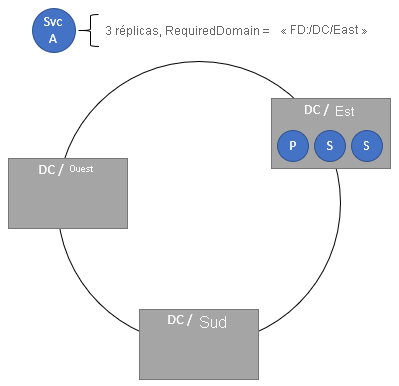
Spécification de domaines obligatoires
La stratégie de positionnement de domaine requise nécessite que le service se trouve uniquement dans le domaine spécifié. Vous pouvez spécifier plusieurs domaines obligatoires par le biais de différentes stratégies.
Code :
ServicePlacementRequiredDomainPolicyDescription requiredDomain = new ServicePlacementRequiredDomainPolicyDescription();
requiredDomain.DomainName = "fd:/DC01/RK03/BL2";
serviceDescription.PlacementPolicies.Add(requiredDomain);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomain,fd:/DC01/RK03/BL2")
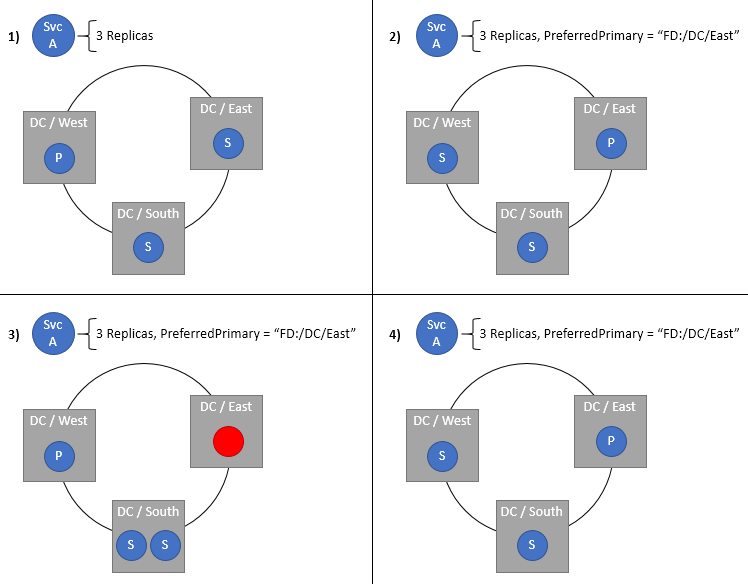
Spécification d’un domaine préféré pour les réplicas principaux d’un service avec état
Le domaine principal préféré spécifie le domaine d’erreur dans lequel les répliquas principaux seront placés. Le domaine principal se retrouve dans ce domaine lorsque tout est normal. Si le domaine ou le réplica principal échoue ou s’arrête, le réplica principal se déplace vers un autre emplacement, idéalement dans le même domaine. Si ce nouvel emplacement ne se trouve pas dans le domaine préféré, le Cluster Resource Manager le redéplace dans le domaine préféré dès que possible. Naturellement, ce paramètre convient uniquement aux services avec état. Cette stratégie est particulièrement utile dans les clusters qui sont répartis entre plusieurs centres de données ou régions Azure, mais vous préférez que des services soient placés dans un emplacement donné. Conserver les domaines principaux à proximité de leurs utilisateurs ou d’autres services permet de réduire la latence, en particulier pour les lectures, qui sont gérées par défaut par ces domaines principaux.
ServicePlacementPreferPrimaryDomainPolicyDescription primaryDomain = new ServicePlacementPreferPrimaryDomainPolicyDescription();
primaryDomain.DomainName = "fd:/EastUS/";
serviceDescription.PlacementPolicies.Add(primaryDomain);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("PreferredPrimaryDomain,fd:/EastUS")
Nécessite une distribution des réplicas et l’interdiction de la compression
Les réplicas sont normalement distribués sur plusieurs domaines d’erreur et les domaines sont mis à niveau si le cluster est sain. Toutefois, il peut arriver que plusieurs réplicas d’une partition donnée finissent par être temporairement compressés dans un domaine unique. Par exemple, supposons que le cluster comporte neuf nœuds dans trois domaines d’erreur : fd:/0, fd:/1 et fd:/2. Supposons également que votre service comporte trois réplicas. Supposons que les nœuds utilisés pour ces réplicas dans fd:/1 et fd:/2 sont injoignables. Normalement, Cluster Resource Manager préférerait les autres nœuds dans ces mêmes domaines d’erreur. Dans ce cas, supposons qu’en raison de problèmes de capacité, aucun des autres nœuds dans ces domaines n’est valide. Si Cluster Resource Manager génère des réplicas de remplacement, il devra choisir des nœuds dans fd:/0. Toutefois, faire cela créerait une situation dans laquelle la contrainte de domaine d’erreur est enfreinte. Il existe une grande chance que le jeu entier de réplicas soit inaccessible ou perdu.
Notes
Pour plus d’informations sur les contraintes et les priorités de contraintes en général, consultez cette rubrique.
Si vous avez déjà vu un message d’intégrité comme « The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: FaultDomain », vous avez rencontré cette situation ou quelque chose de semblable. En général, un ou deux réplicas sont temporairement compressés ensemble. Tant qu’il y a moins de réplicas que le quorum d’un domaine donné, vous êtes en sécurité. Cette compression est rare, mais elle peut se produire, et ces situations sont généralement temporaires étant donné que les nœuds redeviennent disponibles. Si les nœuds restent indisponibles et que Cluster Resource Manager doit générer des remplacements, il existe en général d’autres nœuds disponibles dans les domaines d’erreur idéaux.
Pour certaines charges de travail, il est préférable d’avoir toujours le nombre cible de réplicas, même si ces derniers sont rassemblés dans moins de domaines. Ces charges de travail sont supposent que des pannes de domaine simultanées totales ne surviendront pas, et peuvent généralement récupérer l’état local. D’autres charges de données seront indisponibles plus rapidement pour éviter les erreurs et pertes de données. La plupart des charges de travail s’exécutent avec plus de trois réplicas, plus de trois domaines d’erreur et plusieurs nœuds valides par domaine d’erreur. Par conséquent, la valeur par défaut est de ne pas exiger la distribution sur les domaines. Le comportement par défaut permet un équilibrage normal et un basculement pour gérer ces cas extrêmes, même si cela implique une compression de domaine temporaire.
Si vous souhaitez désactiver ce type de regroupement pour une charge de travail spécifique, vous pouvez spécifier la stratégie RequireDomainDistribution sur le service. Lorsque cette stratégie est définie, Cluster Resource Manager garantit que deux réplicas de la même partition ne s’exécutent pas dans le même domaine d’erreur ou de mise à niveau.
Code :
ServicePlacementRequireDomainDistributionPolicyDescription distributeDomain = new ServicePlacementRequireDomainDistributionPolicyDescription();
serviceDescription.PlacementPolicies.Add(distributeDomain);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomainDistribution")
Est-il possible d’utiliser ces configurations pour les services d’un cluster qui ne sont pas répartis géographiquement ? Oui, mais il n’y a pas de bonne raison de le faire. Les configurations de domaine requises, non valides et par défaut doivent être évitées, sauf si les scénarios le nécessitent. Il n’y a aucune raison de tenter de forcer une charge de travail à s’exécuter dans un seul rack ou de préférer un segment de votre cluster local plutôt qu’un autre. Différentes configurations matérielles doivent être réparties sur plusieurs domaines d’erreur et gérées par les contraintes de placement et les propriétés de nœud normales.
Placement de plusieurs instances sans état d’une partition sur un seul nœud
La stratégie de placement AllowMultipleStatelessInstancesOnNode autorise le placement de plusieurs instances sans état d’une partition sur un nœud unique. Par défaut, plusieurs instances d’une seule partition ne peuvent pas être placées sur un nœud. Même avec un service-1, il n’est pas possible de mettre à l’échelle le nombre d’instances au-delà du nombre de nœuds dans le cluster, pour un service nommé donné. Cette stratégie de positionnement supprime cette restriction et autorise la spécification de InstanceCount à une valeur supérieure au nombre de nœuds.
Si vous avez déjà vu un message d’intégrité comme « The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: ReplicaExclusion », vous avez rencontré cette situation ou quelque chose de semblable.
Pour pouvoir appliquer cette stratégie de placement à votre service, activez les configurations suivantes :
<Section Name="Common">
<Parameter Name="AllowCreateUpdateMultiInstancePerNodeServices" Value="True" />
<Parameter Name="HostReuseModeForExclusiveStateless" Value="1" />
</Section>
En spécifiant la stratégie AllowMultipleStatelessInstancesOnNode sur le service, InstanceCount peut être défini au-delà du nombre de nœuds dans le cluster.
Code :
ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription allowMultipleInstances = new ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription();
serviceDescription.PlacementPolicies.Add(allowMultipleInstances);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless –PartitionSchemeSingleton –PlacementPolicy @(“AllowMultipleStatelessInstancesOnNode”) -InstanceCount 10 -ServicePackageActivationMode ExclusiveProcess
Notes
Actuellement, la stratégie est uniquement prise en charge pour les services sans état avec le mode d’activation du package de service ExclusiveProcess.
Avertissement
La stratégie n’est pas prise en charge lorsqu’elle est utilisée avec des points de terminaison de port statique. L’utilisation conjointe peut entraîner un cluster défectueux, car plusieurs instances sur le même nœud essaient d’effectuer une liaison avec le même port, sans pouvoir l’établir.
Notes
L’utilisation d’une valeur élevée de MinInstanceCount avec cette stratégie de positionnement peut mener à des mises à niveau d’application bloquées. Par exemple, si vous disposez d’un cluster à cinq nœuds et que vous définissez InstanceCount=10, vous aurez deux instances sur chaque nœud. Si vous définissez MinInstanceCount=9, une tentative de mise à niveau d’application peut être bloquée avec MinInstanceCount=8, cela peut être évité.
Étapes suivantes
- Pour plus d’informations sur la configuration des services, consultez la rubrique En savoir plus sur la configuration des services