Vue d’ensemble de l’architecture Cluster Resource Manager
Service Fabric Cluster Resource Manager est un service central qui s’exécute dans le cluster. Il gère l’état souhaité des services dans le cluster, notamment au niveau de la consommation des ressources et des règles de placement.
Pour gérer les ressources de votre cluster, Service Fabric Cluster Resource Manager doit disposer de plusieurs éléments :
- La liste des services existants
- La consommation de ressources actuelle (ou par défaut) de chaque service
- La capacité restante du cluster
- La capacité des nœuds du cluster
- La quantité de ressources consommées sur chaque nœud
La consommation des ressources d’un service donné peut évoluer au fil du temps et les services prennent généralement en charge plusieurs types de ressources. Dans différents services, il peut s’agir de ressources physiques réelles et de ressources physiques mesurées. Les services peuvent assurer le suivi des mesures physiques comme la consommation de mémoire et de disque. En général, les services peuvent se soucier des mesures logiques, comme « WorkQueueDepth » ou « TotalRequests ». Des mesures logiques et physiques peuvent être utilisées dans le même cluster. Les mesures peuvent être partagées entre plusieurs services ou être spécifiques à un service particulier.
Autres considérations
Les propriétaires et les opérateurs du cluster peuvent être différents des auteurs du service ou de l’application, ou il s’agit au minimum des mêmes personnes, mais avec des rôles différents. Lorsque vous développez votre application, vous avez quelques informations sur les éléments qu’elle nécessite. Vous avez une estimation des ressources qu’elle consomme et comment les différents services doivent être déployés. Par exemple, le niveau web doit s’exécuter sur des nœuds exposés à Internet, ce qui n’est pas le cas des services de base de données. Autre exemple : les services web sont probablement contraints par le processeur et le réseau, tandis que les services de niveau données s’occupent davantage de la consommation de mémoire et de disque. Toutefois, les tâches qui incombent à la personne qui gère un incident sur site pour ce service en production ou une mise à niveau du service, sont différentes et nécessitent des outils différents.
Le cluster et les services sont dynamiques :
- Le nombre de nœuds dans le cluster peut augmenter ou diminuer.
- Des nœuds présentant des tailles et types différents vont et viennent.
- Des services peuvent être créés ou supprimés, et peuvent modifier leur allocation de ressources ainsi que les règles de placement.
- Les mises à niveau ou autres opérations de gestion peuvent avoir un impact sur le cluster lors de l’application sur des niveaux d’infrastructure.
- Des échecs peuvent se produire à tout moment.
Composants et flux de données Cluster Resource Manager
Cluster Resource Manager doit suivre les spécifications de chaque service et la consommation des ressources de chaque objet de service au sein de ces services. Cluster Resource Manager se compose de deux éléments conceptuels : les agents, qui s’exécutent sur chaque nœud, et un service à haute tolérance face aux pannes. Les agents de chaque nœud suivent les rapports de charge des services, les agrègent et envoient des rapports régulièrement. Cluster Resource Manager rassemble toutes les informations auprès des agents locaux et réagit en fonction de sa configuration actuelle.
Examinons le schéma suivant :
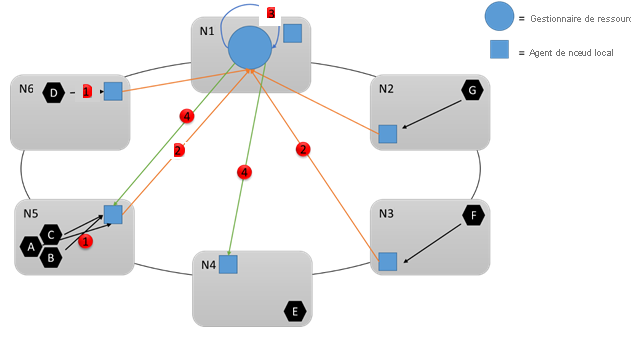
Pendant l’exécution, de nombreux changements peuvent se produire. Par exemple, supposons que la quantité de ressources que consomment certains services change, que certains services échouent et que certains nœuds se joignent au cluster ou le quittent. Toutes les modifications sur les nœuds sont agrégées et régulièrement envoyées au service Cluster Resource Manager (1,2) où elles sont agrégées à nouveau, analysées et stockées. À une fréquence de quelques secondes, ce service examine les changements et détermine si des actions sont nécessaires (3). Par exemple, il peut remarquer que des nœuds vides ont été ajoutés au cluster, et décider par conséquent de déplacer certains services vers ces nœuds. Cluster Resource Manager peut également remarquer qu’un nœud particulier est surchargé ou que certains services ont échoué ou ont été supprimés, en libérant des ressources ailleurs.
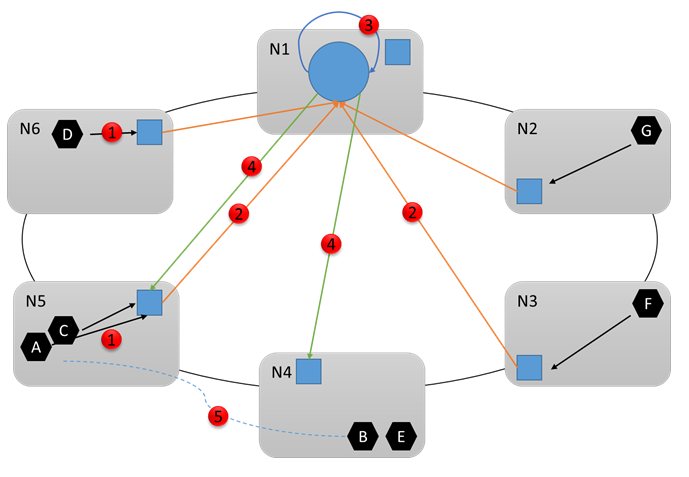
Examinons le schéma suivant pour voir ce qui se passe ensuite. Supposons que Cluster Resource Manager détermine que des modifications sont nécessaires. Il communique avec d’autres services système (en particulier Failover Manager) pour apporter les modifications nécessaires. Les commandes nécessaires sont envoyées aux nœuds appropriés (4). Par exemple, supposons que Resource Manager a remarqué que Node5 est surchargé et a donc décidé de déplacer le service B de Node5 à Node4. À la fin de la reconfiguration (5), le cluster a l’aspect suivant :
Étapes suivantes
- Cluster Resource Manager comporte de nombreuses options permettant de décrire le cluster. Pour en savoir plus sur celles-ci, consultez cet article sur la description d’un cluster Service Fabric.
- Les principales tâches de Cluster Resource Manager sont le rééquilibrage du cluster et l’application des règles de placement. Pour plus d’informations sur la configuration de ces comportements, consultez Équilibrage de votre cluster Service Fabric
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour