Partitionnement des services fiables Service Fabric
Cet article présente les concepts de base pour le partitionnement des services fiables d’Azure Service Fabric. Le partitionnement permet le stockage des données sur les ordinateurs locaux pour que les données et le calcul puissent être mis à l’échelle ensemble.
Conseil
Un exemple complet du code utilisé dans cet article est disponible sur GitHub.
Partitionnement
Le partitionnement n’est pas propre à Service Fabric. En réalité, il s’agit d’un modèle de base de création de services évolutifs. Dans un sens plus large, le partitionnement peut être considéré comme un concept de division d’état (données) et de calcul en plus petites unités accessibles dans un souci d’amélioration de l’évolutivité et des performances. Le partitionnement des données constitue une forme bien connue de partitionnement.
Partitionnement des services sans état Service Fabric
Pour les services sans état, vous pouvez considérer une partition comme une unité logique contenant une ou plusieurs instances d’un service. La figure 1 illustre un service sans état avec cinq instances distribuées sur un cluster à l’aide d’une seule partition.
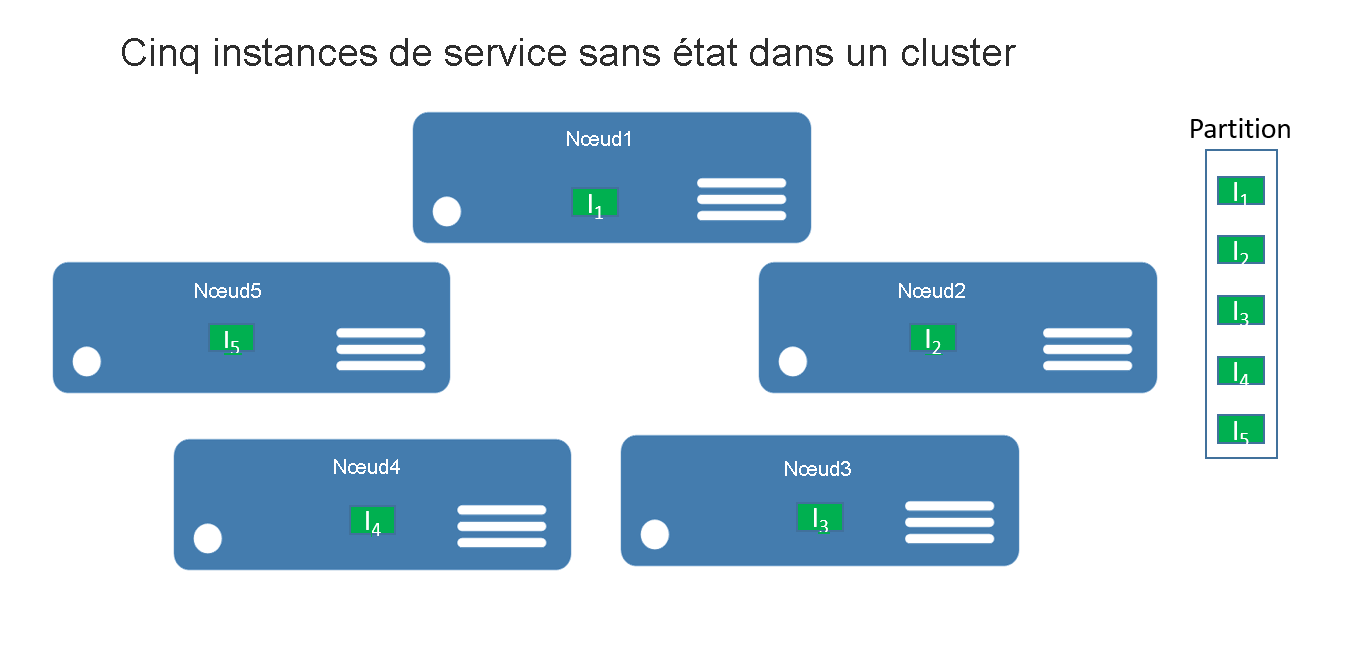
Il existe en réalité deux types de solutions de service sans état. Le premier est un service qui conserve son état en externe, par exemple dans une base de données Azure SQL (comme un site web qui stocke les données et les informations de la session). Le second est un service de calcul uniquement (comme une calculatrice ou la miniaturisation des images) qui ne gère aucun état persistant.
Dans les deux cas, le partitionnement d’un service sans état constitue un scénario extrêmement rare. L’évolutivité et la disponibilité passent normalement par une augmentation du nombre d’instances. Il n’y a que lorsque vous devez répondre à des demandes de routage spéciales qu’il est judicieux d’envisager plusieurs partitions pour des instances de service sans état.
Par exemple, imaginez un cas de figure où des utilisateurs dont les identifiants sont compris dans une certaine plage doivent être uniquement pris en charge par une instance de service particulière. Vous pouvez également partitionner un service sans état lorsque vous disposez d’un serveur principal véritablement partitionné (par exemple une base de données SQL partitionnée) et que vous souhaitez contrôler l’instance de service qui doit écrire sur la partition de base de données ou exécuter, au sein du service sans état, d’autres tâches de préparation nécessitant les mêmes informations de partitionnement que celles utilisées dans le serveur principal. Ces types de scénarios peuvent également être résolus de différentes façons et n’impliquent pas nécessairement un partitionnement du service.
La suite de cette procédure pas à pas se concentre sur les services avec état.
Partitionnement des services avec état Service Fabric
Service Fabric facilite le développement de services avec état évolutifs en offrant une excellente méthode de partitionnement d’état (données). Conceptuellement, vous pouvez considérer la partition d’un service avec état comme une unité d’échelle extrêmement fiable grâce aux réplicas distribués et équilibrés entre les nœuds du cluster.
Dans le cadre des services avec état Service Fabric, le partitionnement désigne le processus permettant d’assigner, à une partition de service donnée, la responsabilité d’une partie de l’état complet du service. (Comme indiqué précédemment, une partition est un ensemble de réplicas). Service Fabric présente l’avantage de placer les partitions sur des nœuds différents. Cela leur permet de croître jusqu’à la limite de ressource du nœud. En même temps que les besoins en matière de données augmentent, les partitions augmentent aussi et Service Fabric rééquilibre les partitions entre les nœuds. Cela garantit l’utilisation continue efficace des ressources matérielles.
Pour vous donner un exemple, imaginons que vous commenciez par un cluster à 5 nœuds et un service configuré avec 10 partitions et une cible de trois réplicas. Dans ce cas, Service Fabric équilibre et distribue les réplicas sur le cluster, et vous obtenez deux réplicas principaux par nœud. À présent, si vous devez effectuer un scale-out de votre cluster sur 10 nœuds, Service Fabric rééquilibre les réplicas principaux sur les 10 nœuds. De la même manière, si vous revenez à 5 nœuds, Service Fabric rééquilibre tous les réplicas sur les 5 nœuds.
La figure 2 montre la distribution des 10 partitions avant et après la mise à l’échelle du cluster.
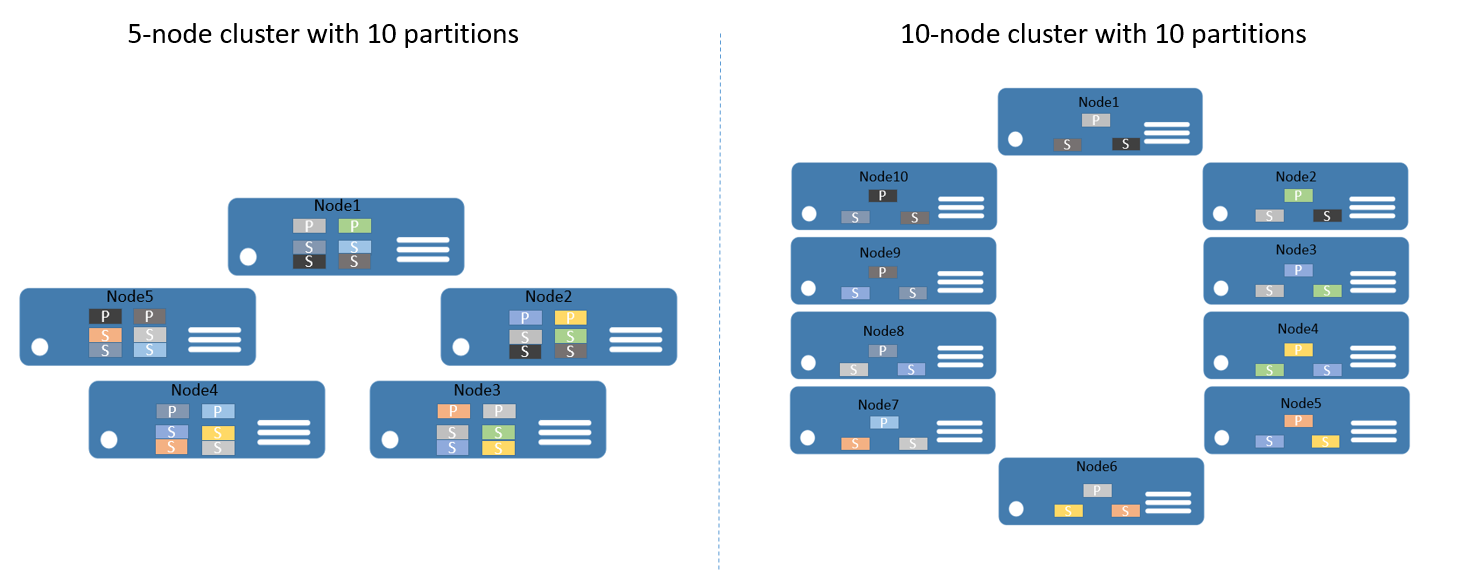
Le système est donc mis à l’échelle dans la mesure où les demandes des clients sont réparties entre plusieurs ordinateurs. Les performances globales de l’application sont améliorées et les conflits d’accès aux blocs de données sont réduits.
Planification du partitionnement
Avant d’implémenter un service, vous devez toujours envisager la stratégie de partitionnement requise pour effectuer un scale-out. Il existe différentes approches, mais toutes se concentrent sur ce que l’application doit effectuer. Dans le contexte de cet article, passons en revue quelques-uns des aspects les plus importants.
Une bonne approche consiste à réfléchir de prime abord à la structure de l’état qui doit être partitionné.
Prenons un exemple simple : Si vous devez créer un service pour un sondage à l’échelle d’une région, vous pouvez créer une partition pour chaque ville de la région. Puis, vous pouvez stocker les votes pour chaque personne dans une ville dans la partition correspondant à cette ville. La figure 3 présente une liste de personnes associées au nom de la ville dans laquelle elles résident.
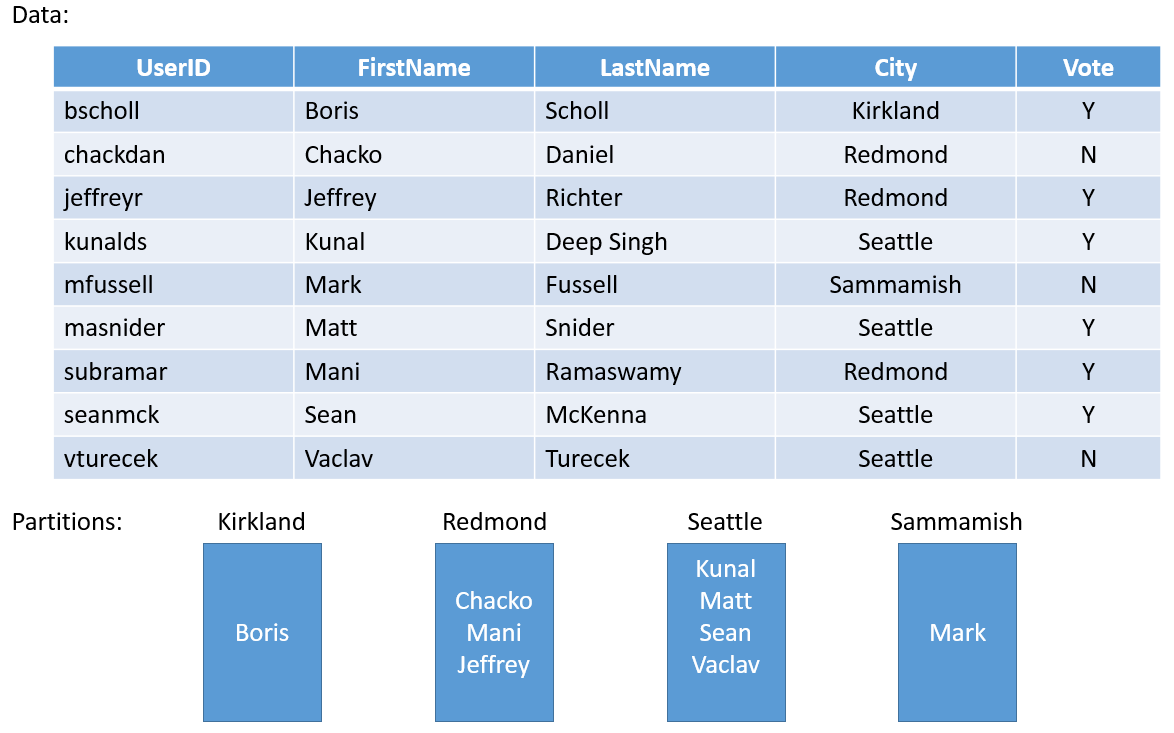
Comme la population varie considérablement d’une ville à l’autre, vous pouvez obtenir des partitions qui contiennent un grand nombre de données (par exemple, Seattle) et d’autres partitions avec un état très limité (par exemple, Kirkland). Par conséquent, que se passe-t-il si l’on utilise des partitions ayant des volumes d’état irréguliers ?
Dans cet exemple, vous pouvez facilement voir que la partition qui contient les votes pour la ville de Seattle génère davantage de trafic que celle de Kirkland. Par défaut, Service Fabric permet de s’assurer qu’il existe environ le même nombre de réplicas principaux et secondaires sur chaque nœud. Par conséquent, vous pouvez obtenir des nœuds qui contiennent des réplicas qui servent plus de trafic et d’autres qui en servent moins. Dans un cluster, vous préférerez sans doute éviter une telle alternance de points chauds et de points froids.
Pour éviter ce problème, il y a deux choses à faire du point de vue du partitionnement :
- Essayer de partitionner l’état afin de garantir une répartition équitable entre toutes les partitions.
- Générer un rapport de charge pour chacun des réplicas du service. (Pour plus d'informations sur la procédure à suivre, consultez cet article sur Métriques et charge). Service Fabric permet de générer des rapports de charge utilisée par les services, notamment sur la quantité de mémoire ou le nombre d’enregistrements. Service Fabric s’appuie sur ces mesures pour détecter si certaines partitions gèrent des charges plus élevées que d’autres et pour rééquilibrer le cluster en déplaçant les réplicas vers des nœuds plus appropriés, afin qu’aucun nœud ne soit surchargé.
Il arrive que la quantité de données dans une partition donnée ne soit pas connue. Aussi, nous vous recommandons de commencer par adopter une stratégie de partitionnement qui répartit les données uniformément sur les partitions, puis de générer un rapport sur la charge. La première méthode permet d’éviter les situations décrites dans l’exemple du vote, tandis que la seconde lisse dans le temps les différences d’accès ou de charge temporaires.
Lors de la planification d’un partitionnement, vous devez également choisir le nombre de partitions de départ approprié. Du point de vue de Service Fabric, rien ne vous empêche de commencer par un nombre de partitions plus élevé que prévu pour votre scénario. En réalité, il est tout à fait acceptable de partir du nombre maximal de partitions.
Bien que ces cas soient rares, il peut arriver que vous ayez besoin de plus de partitions que prévu. Comme vous ne pouvez pas modifier le nombre de partitions après coup, vous devrez alors utiliser certaines approches de partitionnement avancées, telles que la création d’une nouvelle instance de service du même type. Vous devrez également implémenter une logique côté client qui achemine les demandes vers l’instance de service adaptée, en fonction des connaissances côté client que votre code client doit gérer.
Pour planifier votre partitionnement, vous devez également tenir compte des ressources informatiques disponibles. Comme l’état doit être accessible et stocké, vous êtes soumis aux contraintes suivantes :
- Les limites de bande passante du réseau
- Les limites de mémoire système
- Les limites de stockage du disque
Par conséquent, que se passe-t-il si vous subissez des contraintes de ressources dans un cluster en cours d’exécution ? Il vous suffit simplement d’effectuer un scale-out de votre cluster pour prendre en compte les nouvelles spécifications.
Le guide de planification de la capacité propose des conseils qui vous aideront à déterminer le nombre de nœuds nécessaires à votre cluster.
Prise en main du partitionnement
Cette section décrit comment débuter avec le partitionnement de votre service.
Service Fabric propose trois schémas de partition, au choix :
- Partitionnement par plage (également appelé UniformInt64Partition).
- Partitionnement nommé. Les applications qui utilisent ce modèle comportent généralement des données qui peuvent être compartimentées au sein d’un ensemble limité. Les régions, les codes postaux, les groupes de clients ou les autres limites de l’entreprise constituent des exemples courants de champs de données utilisés comme clés de partition nommées.
- Partitionnement singleton. Les partitions singleton sont généralement utilisées lorsque le service ne requiert aucun routage supplémentaire. Par exemple, les services sans état utilisent ce schéma de partitionnement par défaut.
Les schémas de partitionnement nommé et singleton sont des formes spéciales de partitions par plage. Par défaut, les modèles Visual Studio pour Service Fabric utilisent le partitionnement par plage, car il représente le schéma le plus courant et le plus utile. Le reste de cet article se concentre sur le schéma de partitionnement par plage.
Schéma de partitionnement par plage
Il permet de spécifier une plage d’entiers (identifiée par une clé basse et une clé haute) et un nombre de partitions (n). Il crée n partitions, chacune responsable d’une sous-plage qui ne chevauche pas la plage globale de clés de partition. Par exemple, un schéma de partitionnement par plage doté d’une clé basse de 0, d’une clé haute de 99 et d’un nombre total de 4 créera quatre partitions, telles qu’elles sont illustrées ci-dessous.
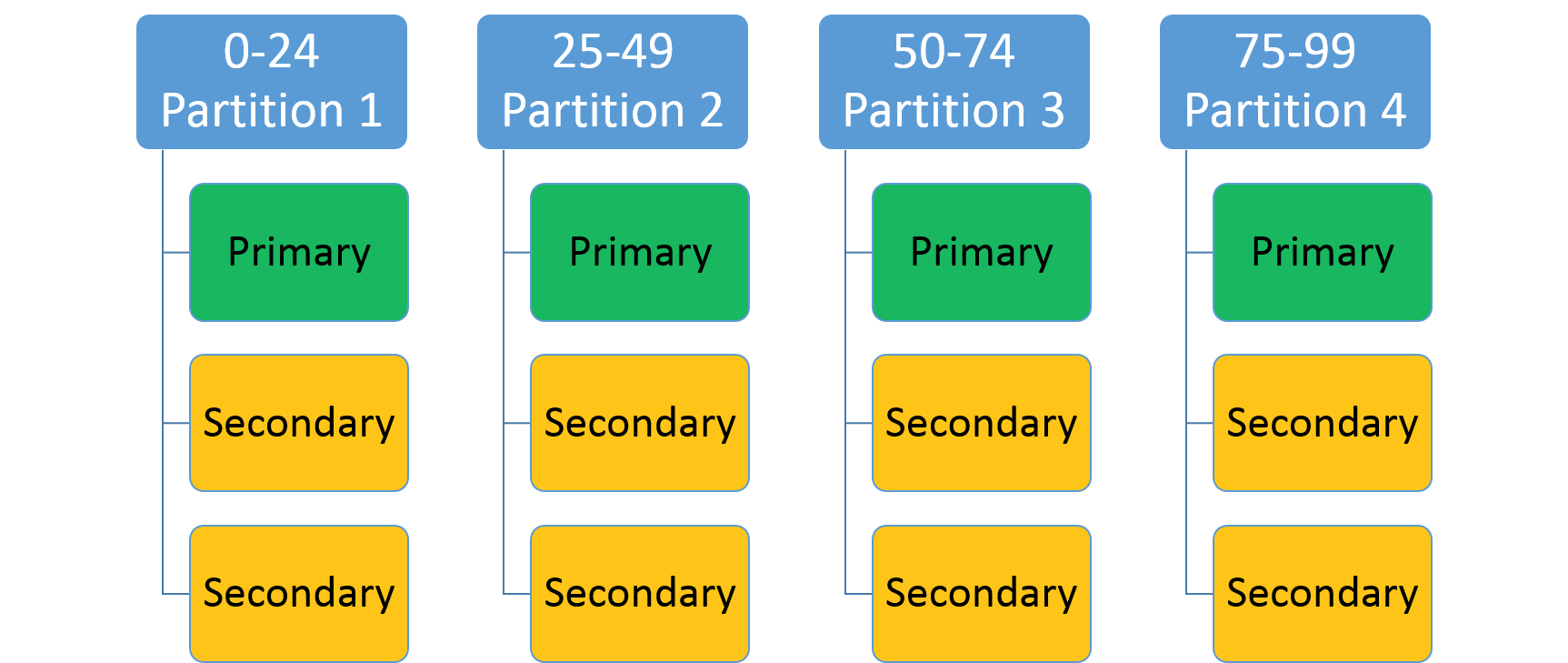
Une approche courante consiste à créer un hachage basé sur une clé unique dans l’ensemble de données. Un numéro d’immatriculation de véhicule, l’identifiant d’un d’employé ou une chaîne unique sont des exemples courants de clés. En utilisant cette clé unique, vous créez un code de hachage et modulez la plage de clés afin de l’utiliser comme clé. Vous pouvez spécifier les limites supérieures et inférieures de la plage de clé autorisée.
Sélection d’un algorithme de hachage
Une partie importante du hachage consiste à sélectionner l'algorithme de hachage. Il convient de tenir compte de l’objectif du hachage, à savoir si celui-ci est de regrouper des clés similaires proches les unes des autres (hachage sensible à la localité) ou si l’activité doit être distribuée de manière plus large entre toutes les partitions (hachage de distribution), ce qui est le cas de figure le plus courant.
Un bon algorithme de hachage de distribution a la particularité d’être facile à calculer, de comporter peu de collisions et de distribuer uniformément les clés. L’algorithme de hachage FNV-1 est très efficace, par exemple.
La page Wikipedia sur les fonctions de hachageest une ressource proposant de nombreux algorithmes de code de hachage généraux.
Création d’un service avec état avec plusieurs partitions
Nous allons créer le premier service fiable avec état à plusieurs partitions. Dans cet exemple, vous allez générer une application très simple dans laquelle vous souhaitez stocker tous les noms qui commencent par la même lettre dans la même partition.
Avant d’écrire le code, vous devez réfléchir aux partitions et aux clés de partition. Vous avez besoin de 26 partitions, soit une partition pour chaque lettre de l’alphabet, mais devez-vous utiliser des clés basses ou hautes ? Comme nous ne voulons littéralement qu’une partition par lettre, nous pouvons utiliser 0 comme clé basse et 25 comme clé haute puisque chaque lettre est sa propre clé.
Notes
Il s’agit d’un scénario simplifié car, en réalité, la distribution serait inégale. Les noms commençant par la lettre S ou M sont plus courants que ceux commençant par X ou Y.
Ouvrez Visual Studio>Fichier>Nouveau>Projet.
Dans la boîte de dialogue Nouveau projet , sélectionnez l’application Service Fabric.
Appelez le projet AlphabetPartitions.
Dans la boîte de dialogue Créer un service, choisissez Service avec état et appelez-le « Alphabet.Processing ».
Définissez le nombre de partitions. Ouvrez le fichier ApplicationManifest.xml situé dans le dossier ApplicationPackageRoot du projet AlphabetPartitions, puis configurez le paramètre Processing_PartitionCount sur 26, comme illustré ci-dessous.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Vous devez également mettre à jour les propriétés LowKey et HighKey de l’élément StatefulService dans le fichier ApplicationManifest.xml, comme illustré ci-dessous.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Pour que le service soit accessible, ouvrez un point de terminaison sur un port en ajoutant l’élément de point de terminaison de ServiceManifest.xml (situé dans le dossier PackageRoot) pour le service Alphabet.Processing, comme indiqué ci-dessous :
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Le service est maintenant configuré pour écouter un point de terminaison interne avec 26 partitions.
Vous devez ensuite remplacer la méthode
CreateServiceReplicaListeners()de la classe Processing.Notes
Pour cet exemple, supposons que vous utilisiez un HttpCommunicationListener simple. Pour plus d’informations sur la communication de service fiable, consultez modèle de communication de Reliable Service.
Le format suivant est recommandé pour l’URL sur laquelle se fait l’écoute du réplica :
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Vous devez donc configurer votre écouteur de communication pour l’écoute sur les points de terminaison correctes et avec ce modèle.Plusieurs réplicas de ce service peuvent être hébergés sur le même ordinateur, ce qui signifie que cette adresse doit être unique pour le réplica. C’est pourquoi l’ID de partition + ID de réplica sont dans l’URL. HttpListener peut écouter plusieurs adresses sur le même port tant que le préfixe d’URL est unique.
Le GUID supplémentaire est fourni dans les cas où des réplicas secondaires écouteraient également les demandes en lecture seule. Dans ce cas de figure, vous voudrez vous assurer qu’une nouvelle adresse unique est utilisée lors de la transition du réplica principal vers le réplica secondaire afin de forcer les clients à résoudre l’adresse. « + » est utilisé ici comme adresse afin de permettre au réplica d’écouter tous les hôtes disponibles (IP, FQDN, localhost, etc.). Le code ci-dessous en montre un exemple.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Il est également important de noter que l’URL publiée diffère légèrement du préfixe de l’URL d’écoute. L’URL d’écoute est donnée à HttpListener. L’URL publiée est l’URL qui est publiée dans le service de nommage Service Fabric, utilisé pour la découverte de service. Les clients demanderont cette adresse via ce service de découverte. L’adresse obtenue par les clients doit comporter l’IP ou le nom de domaine complet du nœud pour pouvoir établir la connexion. Vous devez remplacer « + » par l’adresse IP ou le nom de domaine complet du nœud comme indiqué ci-dessus.
La dernière étape consiste à ajouter la logique de traitement au service comme indiqué ci-dessous.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestlit les valeurs du paramètre de la chaîne de requête utilisée pour appeler la partition et appelleAddUserAsyncpour ajouter le nom au dictionnaire fiabledictionary.Ajoutons un service sans état au projet pour voir comment appeler une partition particulière.
Ce service sert d’interface web simple qui accepte le nom comme paramètre de la chaîne de requête, détermine la clé de partition et l’envoie au service Alphabet.Processing pour traitement.
Dans la boîte de dialogue Créer un service, choisissez Service sans état et appelez-le « Alphabet.Web » comme indiqué ci-dessous.
 .
.Mettez à jour les informations du point de terminaison dans le fichier ServiceManifest.xml du service Alphabet.WebApi pour ouvrir un port comme indiqué ci-dessous.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Vous devez retourner une collection de ServiceInstanceListeners dans la classe Web. Là encore, vous pouvez choisir d’implémenter un simple HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Maintenant, vous devez implémenter la logique de traitement. HttpCommunicationListener appelle
ProcessInputRequestlorsqu’une demande lui parvient. Par conséquent, vous devez ajouter le code ci-dessous.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Voici la procédure pas à pas. Le code lit la première lettre du paramètre de chaîne de requête
lastnamesous forme de caractère. Il détermine ensuite la clé de partition pour cette lettre en soustrayant la valeur hexadécimale deAde la valeur hexadécimale de la première lettre des noms.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');N’oubliez pas que, dans cet exemple, nous utilisons 26 partitions avec une seule clé de partition par partition. Nous obtenons ensuite la partition de service
partitionpour cette clé en utilisant la méthodeResolveAsyncsur l’objetservicePartitionResolver.servicePartitionResolverest défini commeprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();La méthode
ResolveAsyncaccepte l’URI de service, la clé de partition et un jeton d’annulation en tant que paramètres. L’URI du service pour le service de traitement estfabric:/AlphabetPartitions/Processing. Ensuite, nous obtenons le point de terminaison de la partition.ResolvedServiceEndpoint ep = partition.GetEndpoint()Pour finir, nous allons générer l’URL du point de terminaison ainsi que la chaîne de requête avant d’appeler le service de traitement.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Une fois le traitement effectué, nous pouvons réécrire la sortie.
La dernière étape consiste à tester le service. Visual Studio utilise les paramètres d’application pour un déploiement local et sur le cloud. Pour tester le service avec 26 partitions localement, vous devez mettre à jour le fichier
Local.xmldans le dossier ApplicationParameters du projet AlphabetPartitions, comme indiqué ci-dessous :<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Une fois le déploiement terminé, vous pouvez vérifier le service et toutes ses partitions dans l’Explorateur de Service Fabric.
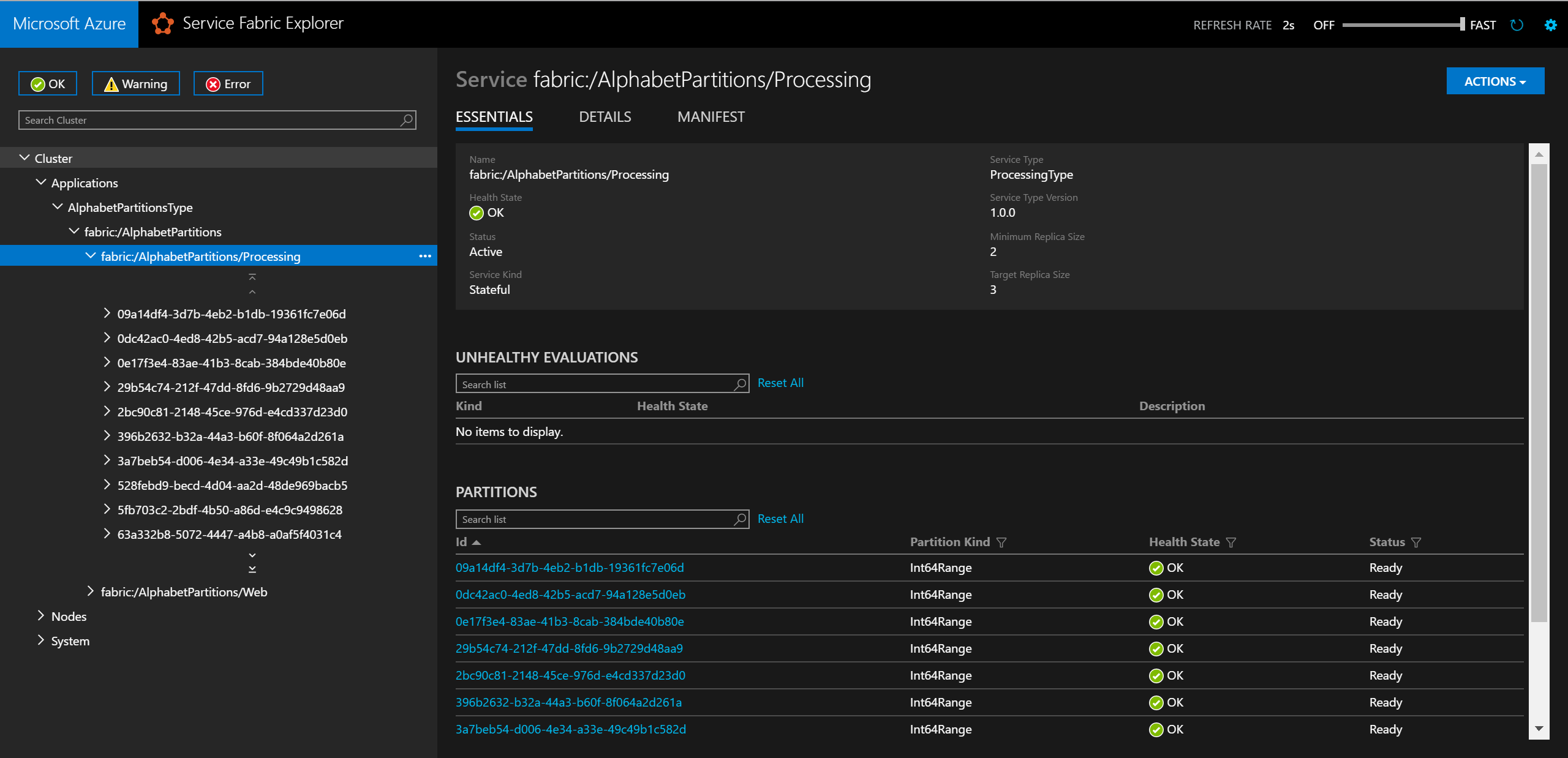
Dans un navigateur, vous pouvez tester la logique de partitionnement en entrant
http://localhost:8081/?lastname=somename. Vous verrez que chaque nom de famille commençant par la même lettre sera stocké dans la même partition.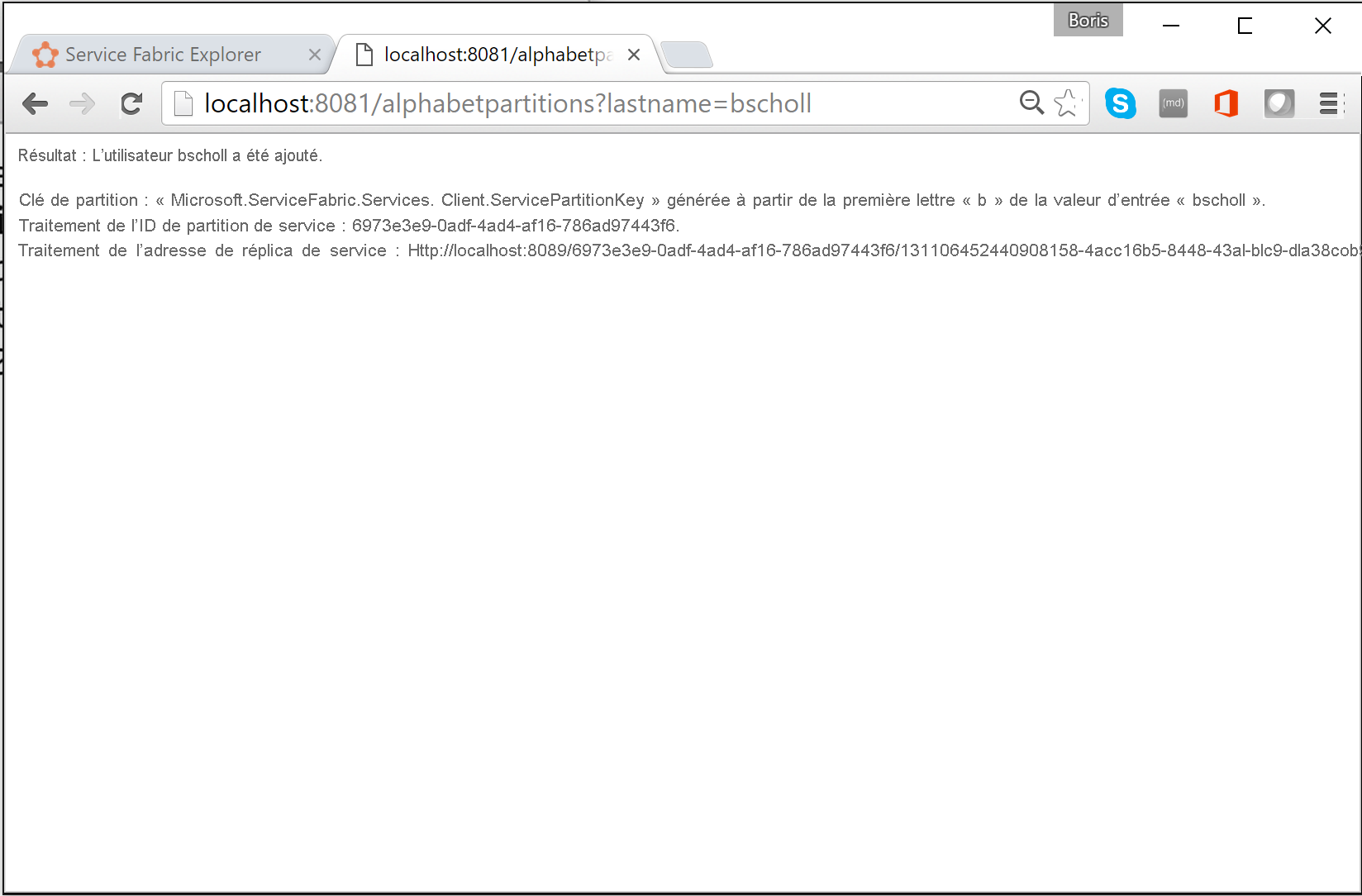
La solution complète du code utilisé dans cet article est disponible ici : https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Étapes suivantes
Pour plus d’informations sur les services Service Fabric :
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour