Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des recommandations en matière de bonnes pratiques qui vous aident à utiliser des niveaux d’accès pour optimiser les performances et réduire les coûts. Pour en savoir plus sur les niveaux d’accès, consultez Niveaux d’accès pour les données blob.
Choisir les niveaux d’accès les plus rentables
Vous pouvez réduire les coûts en plaçant les données blob dans les niveaux d’accès les plus économiques. Choisissez parmi trois niveaux conçus pour optimiser vos coûts d’utilisation des données. Par exemple, le niveau chaud a un coût de stockage plus élevé, mais un coût de lecture inférieur. Par conséquent, si vous envisagez d’accéder fréquemment aux données, le niveau d’accès chaud peut être le choix le plus rentable. Si vous accédez aux données moins souvent, le niveau cool, froid ou d'archivage peut être le mieux adapté, car il réduit les coûts de stockage, mais il augmente les coûts de lecture.
Pour trouver le niveau d’accès le plus optimal, estimez le pourcentage de données lues chaque mois. Le graphique suivant montre l’impact sur les dépenses mensuelles de différents pourcentages de lecture.
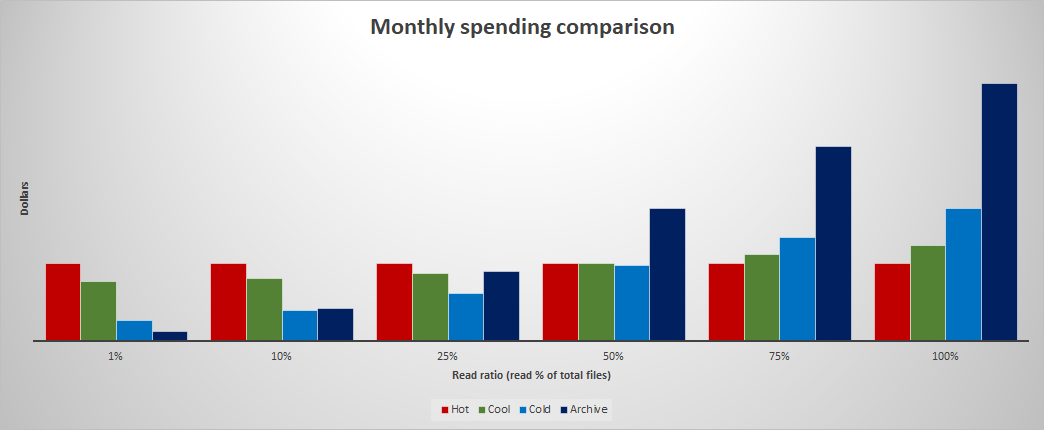
Pour modéliser et analyser le coût d’utilisation du stockage cool ou froid par rapport au stockage archive, consultez Archive contre froid et cool. Vous pouvez appliquer des techniques de modélisation similaires pour comparer les coûts de stockage chaud, tiède, froid ou d'archivage.
Appliquer un niveau intelligent pour optimiser les coûts automatiquement
Si vous n’êtes pas au courant du niveau d’accès le plus optimal pour chaque objet ou si vous ne souhaitez pas gérer le positionnement de ces objets, le niveau Intelligent peut être une excellente option à choisir. La hiérarchisation automatique des données inactives peut entraîner des économies importantes au fil du temps. Tout en facturant des frais de surveillance minimes, il simplifie davantage le modèle de facturation en ne facturant pas les transitions de niveau, les suppressions anticipées ou la réhydratation de capacité. Pour plus d’informations, consultez Optimiser les coûts avec un niveau intelligent .
Migrer des données directement vers les niveaux d’accès les plus rentables
Le choix du niveau le plus optimal avant peut réduire les coûts. Si vous modifiez le niveau d’un objet blob de blocs que vous chargez, vous payez pour l’écriture au niveau initial lorsque vous le chargez, puis payez pour l’écriture dans le nouveau niveau. Si vous modifiez des niveaux à l’aide d’une stratégie de gestion du cycle de vie, cette stratégie nécessite un jour pour prendre effet et un jour pour terminer l’exécution. Vous payez également le coût de capacité de stockage des données dans le niveau initial avant la modification du niveau.
Pour obtenir des conseils sur le chargement vers un niveau d’accès spécifique, consultez Définir le niveau d’accès d’un objet blob.
Pour le déplacement des données hors connexion vers le niveau souhaité, consultez Azure Data Box.
Déplacer des données dans les niveaux d’accès les plus rentables
Une fois les données chargées, vous devez analyser régulièrement vos conteneurs et objets blob pour comprendre comment ils sont stockés, organisés et utilisés en production. Ensuite, utilisez des stratégies de gestion du cycle de vie pour déplacer des données vers les niveaux les plus rentables. Par exemple, les données non accessibles pendant plus de 30 jours peuvent être plus rentables si elles sont placées dans le niveau froid. Envisagez d’archiver les données qui n’ont pas été consultées depuis plus de 180 jours.
Pour collecter des données de télémétrie, activez les rapports d’inventaire d’objets blob et activez le suivi de l’heure du dernier accès. Analysez les modèles d’utilisation en fonction de la dernière heure d’accès à l’aide d’outils tels qu’Azure Synapse ou Azure Databricks. Pour en savoir plus sur les méthodes d’analyse de vos données, consultez l’un des articles suivants :
Niveau objets blob d’ajout et de pages
Votre analyse peut révéler des objets blob d’ajout ou de page qui ne sont pas utilisés activement. Par exemple, vous pouvez avoir des fichiers journaux (objets blob d’ajout) qui ne sont plus en cours de lecture ou d’écriture, mais vous souhaitez les stocker pour des raisons de conformité. De même, vous pouvez sauvegarder des disques ou des instantanés de disque (blobs de pages). Vous pouvez également déplacer ces objets blob dans des niveaux plus sporadiques. Toutefois, vous devez d’abord les convertir en objets blob de blocs.
Pour obtenir des informations sur la conversion des blobs d’ajout et des blobs de pages en blobs de blocs, consultez Convertir des blobs d’ajout et des blobs de pages en blobs de blocs.
Empaquetez de petits fichiers avant de déplacer des données vers des niveaux plus froids
Chaque opération de lecture ou d’écriture entraîne un coût. Pour réduire le coût de lecture et d’écriture de données, envisagez d’empaqueter de petits fichiers dans des fichiers plus volumineux à l’aide de formats de fichiers tels que TAR ou ZIP. Moins de fichiers réduisent le nombre d’opérations nécessaires pour transférer des données.
Le graphique suivant montre l’impact relatif des fichiers d’emballage pour le niveau froid. Le coût de lecture suppose un pourcentage de lecture mensuel de 30%.
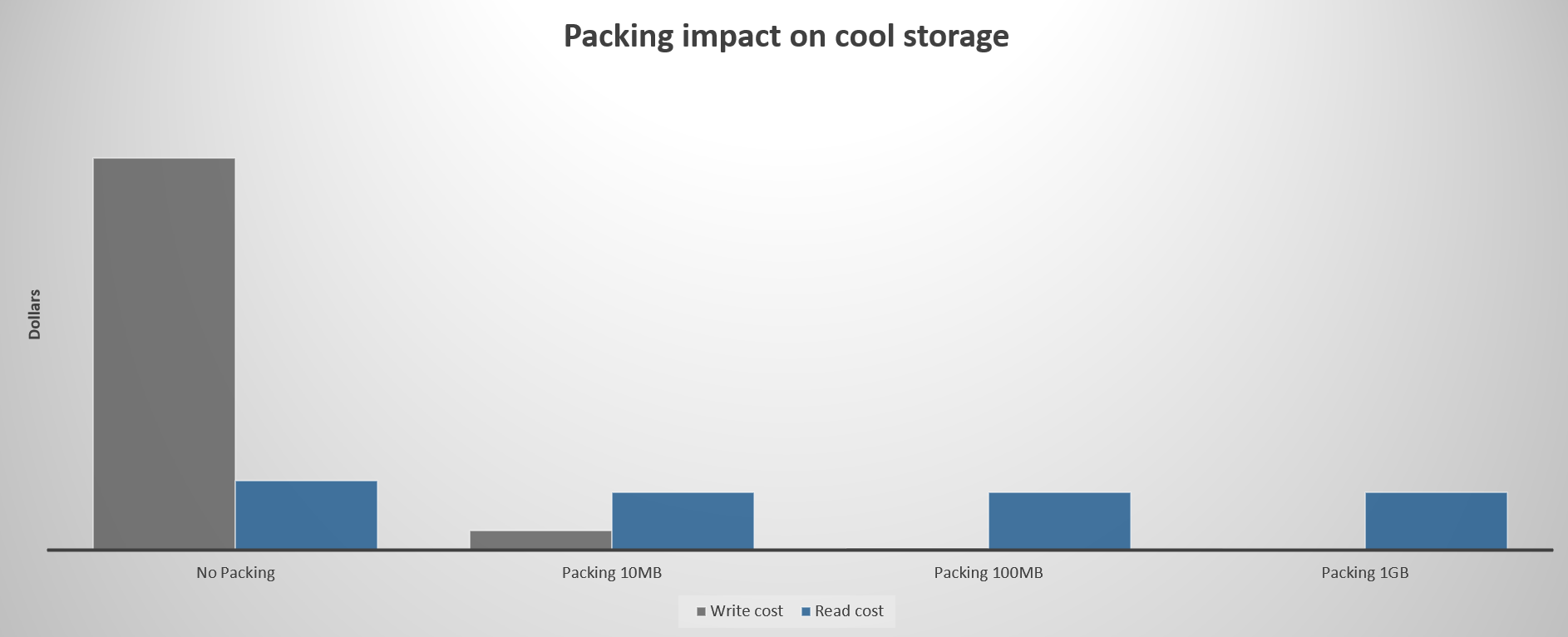
Le graphique suivant montre l’impact relatif des fichiers d’emballage pour le niveau Archive. Le coût de lecture suppose un pourcentage de lecture mensuel de 30%.

Pour modéliser et analyser les économies réalisées grâce à l'optimisation du regroupement des fichiers, consultez l’onglet Économies de Regroupement dans le classeur.
Conseil / Astuce
Pour faciliter les scénarios de recherche et de lecture, envisagez de créer un index qui mappe les chemins d’accès de fichiers compressés avec les chemins d’accès de fichiers d’origine, puis de stocker ces index sous forme d’objets blob de blocs dans le niveau chaud.