Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
L’éditeur sans code facilite le développement d’un travail Stream Analytics pour traiter vos données de streaming en temps réel. Utilisez la fonctionnalité glisser-déplacer sans écrire de code. L’expérience fournit un canevas où vous pouvez vous connecter à des sources d’entrée pour voir rapidement vos données de diffusion en continu. Vous pouvez ensuite transformer les données avant de les envoyer à vos destinataires.
À l’aide de l’éditeur sans code, vous pouvez facilement :
- Modifier les schémas d’entrée.
- Effectuer des opérations de préparation des données comme les jointures et les filtres.
- Approcher des scénarios avancés, comme les agrégations de fenêtres de temps (fenêtres bascule, récurrentes et de session) pour les opérations de regroupement.
Après avoir créé et exécuté vos travaux Stream Analytics, vous pouvez facilement opérationnaliser les charges de travail de production. Utilisez l’ensemble approprié de métriques intégrées pour la supervision et la résolution des problèmes. Les travaux Stream Analytics sont facturés en fonction du modèle de tarification quand ils sont en cours d’exécution.
Prérequis
Avant de développer vos travaux Stream Analytics à l’aide de l’éditeur sans code, veillez à répondre à ces exigences :
- Les sources d’entrée de streaming et les ressources de destination cibles pour le travail de Stream Analytics doivent être accessibles publiquement et ne peuvent pas se trouver dans un réseau virtuel Azure.
- Vous devez disposer des autorisations nécessaires pour accéder aux ressources d’entrée et de sortie de streaming.
- Vous devez conserver les autorisations pour créer et modifier des ressources Azure Stream Analytics.
Note
L’éditeur sans code n’est actuellement pas disponible dans la région chine.
Tâche Azure Stream Analytics
Un travail Stream Analytics repose sur trois composants principaux : les entrées de streaming, les transformations et les sorties. Vous pouvez inclure autant de composants que vous le souhaitez, tels que plusieurs entrées, branches parallèles avec plusieurs transformations et plusieurs sorties. Pour plus d’informations, consultez la documentation Azure Stream Analytics.
Note
Les fonctionnalités et les types de sortie suivants ne sont pas disponibles lorsque vous utilisez l’éditeur sans code :
- Fonctions définies par l’utilisateur.
- Modification de requête sur la page de requête Azure Stream Analytics. Toutefois, vous pouvez afficher la requête générée par l’éditeur de code sans code dans la page de requête.
- Ajout d’entrées et de sorties sur les pages d’entrée et de sortie d'Azure Stream Analytics. Toutefois, vous pouvez afficher les entrées et sorties générées par l’éditeur sans code dans la page d’entrée et de sortie.
- Les types de sortie suivants ne sont pas disponibles : Fonction Azure, Azure Data Lake Storage Gen1, base de données PostgreSQL, file d'attente/sujet Service Bus, stockage de table.
Pour accéder à l’éditeur sans code pour créer votre travail Stream Analytics, utilisez l’une des approches suivantes :
Via le portail Azure Stream Analytics (préversion) : créez un travail Stream Analytics, puis sélectionnez l’éditeur zéro code sous l’onglet Prise en main de la page Vue d’ensemble, ou sélectionnez Éditeur zéro code dans le volet gauche.
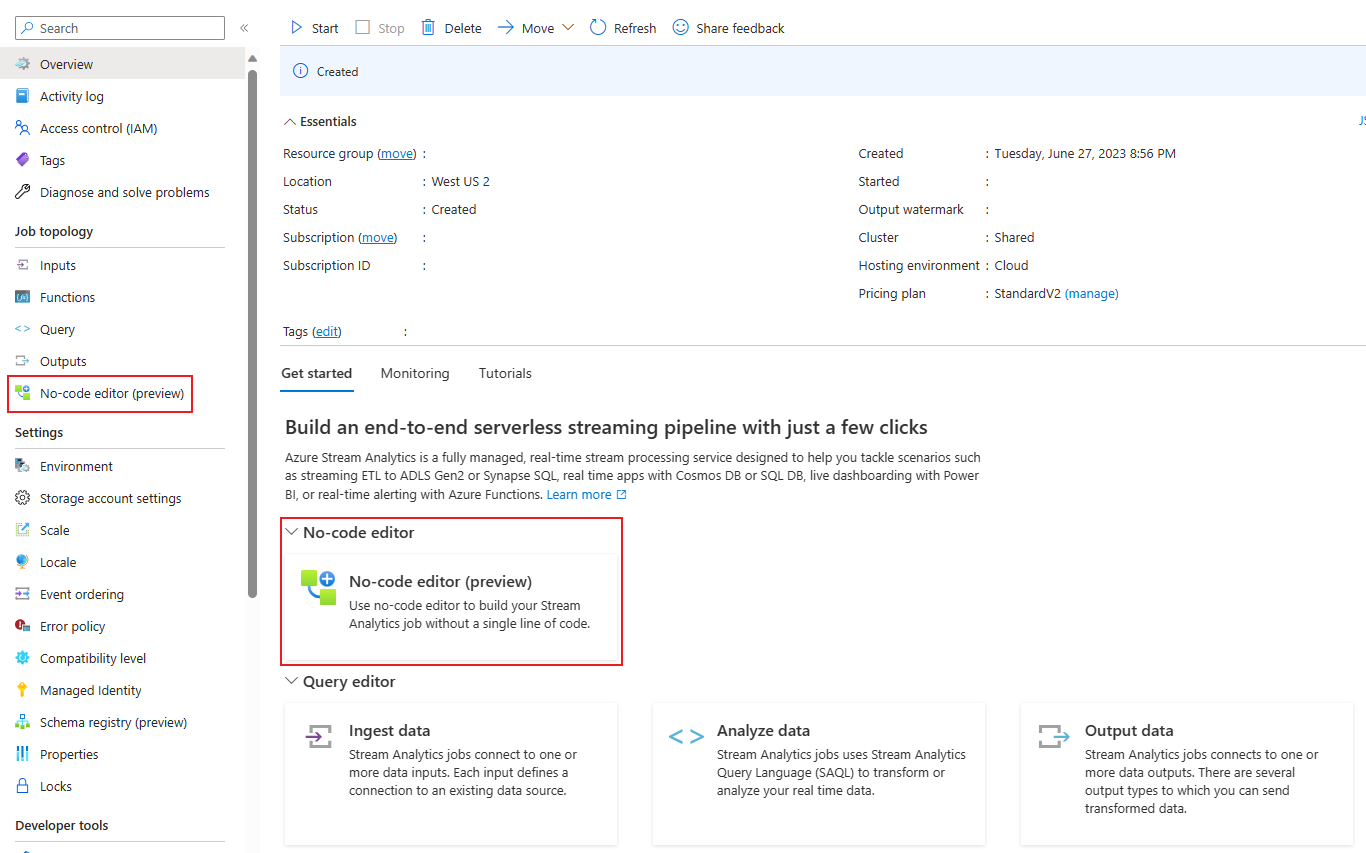
Via le portail Azure Event Hubs : ouvrez une instance Event Hubs. Sélectionnez Traiter des données, puis sélectionnez un modèle prédéfini de votre choix.
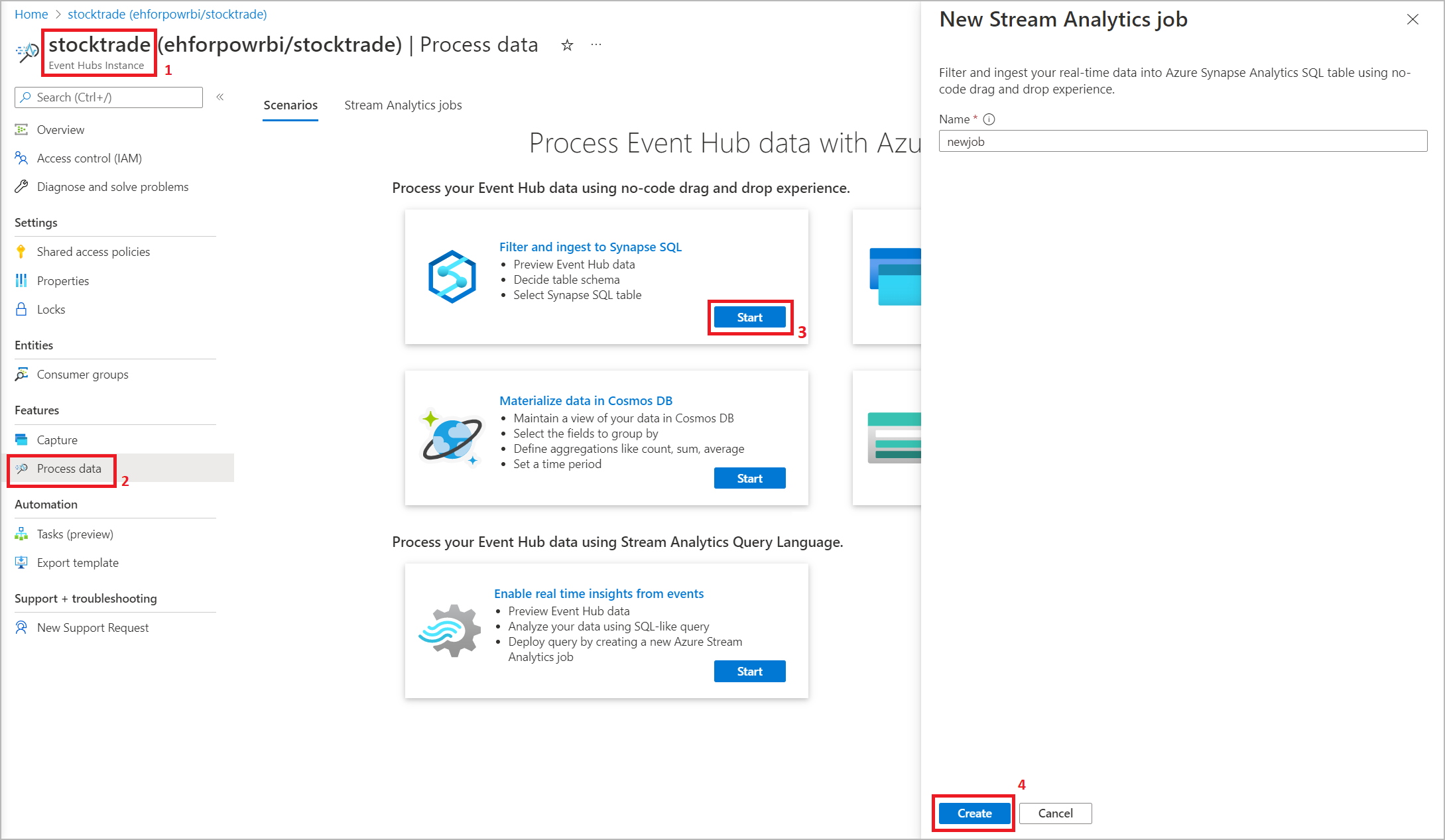
Les modèles prédéfinis peuvent vous aider à développer et à exécuter un travail pour répondre à différents scénarios, notamment :
- Capture des données des Event Hubs au format Delta Lake (préversion)
- Filtrage et ingestion dans Azure Synapse SQL
- Capture de vos données Event Hubs au format Parquet dans Azure Data Lake Storage Gen2
- Matérialisation des données dans Azure Cosmos DB
- Filtrer et ingérer des données dans Azure Data Lake Storage Gen2
- Enrichir les données et les ingérer dans un hub d’événements
- Transformer et stocker des données dans une base de données Azure SQL
- Filtrer et ingérer dans Azure Data Explorer


La capture d’écran suivante montre un travail Stream Analytics achevé. Elle met en évidence l’ensemble des sections disponibles lors de la création.

- Ruban : sur le ruban, les sections suivent l’ordre d’un processus d’analyse classique, un hub d’événements comme entrée (également appelé source de données), des transformations (opérations ETL [Extraire, transformer et charger] de diffusion en continu), des sorties, un bouton pour enregistrer votre progression et un bouton pour démarrer le travail.
- Vue diagramme : cette vue est une représentation graphique de votre travail Stream Analytics, de l’entrée aux opérations aux sorties.
- Volet latéral : selon le composant que vous sélectionnez dans la vue diagramme, vous voyez les paramètres permettant de modifier l’entrée, la transformation ou la sortie.
- Onglets pour l’aperçu des données, les erreurs d'édition, les journaux de temps d'exécution et les métriques : pour chaque tuile, l’aperçu des données montre les résultats de cette étape (en direct pour les entrées, à la demande pour les transformations et les sorties). Cette section résume également les éventuelles erreurs de création et les avertissements susceptibles de survenir dans votre travail lorsqu'il est en cours de développement. En sélectionnant chaque erreur ou avertissement, vous sélectionnez cette transformation. Elle fournit également les indicateurs de performance du travail pour vous permettre de surveiller le bon fonctionnement du travail en cours.
Entrée de données de streaming
L’éditeur sans code prend en charge l’entrée de données de streaming à partir de trois types de ressources :
- Hubs d'événements Azure
- Azure IoT Hub
- Azure Data Lake Storage Gen2
Pour plus d’informations sur les entrées de données de streaming, consultez Données de streaming en tant qu’entrées dans Stream Analytics.
Note
L’éditeur sans code dans le portail Azure Event Hubs a uniquement Event Hub comme option d’entrée.

Azure Event Hubs comme entrée en streaming
Azure Event Hubs est une plateforme de streaming de Big Data et un service d’ingestion d’événements. Il peut recevoir et traiter des millions d’événements par seconde. Vous pouvez transformer et stocker des données envoyées à un hub d’événements via n’importe quel fournisseur d’analytique en temps réel ou adaptateur de stockage par lots.
Pour configurer un Event Hub en tant qu’entrée pour votre travail, sélectionnez l’icône Event Hub. Une vignette s’affiche dans la vue du diagramme, avec un volet latéral pour sa configuration et sa connexion.
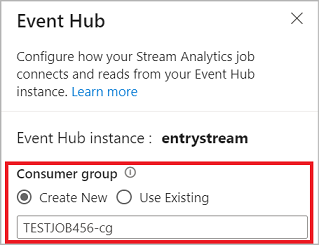
Lorsque vous vous connectez à votre event Hub dans l’éditeur sans code, créez un groupe de consommateurs (qui est l’option par défaut). Cette approche permet d’empêcher le hub d’événements d’atteindre la limite de lecteurs simultanés. Pour en savoir plus sur les groupes de consommateurs et comprendre si vous devez sélectionner un groupe de consommateurs existant ou en créer un, consultez Groupes de consommateurs.
Si votre hub d’événements se trouve dans le niveau De base, vous pouvez utiliser uniquement le groupe de consommateurs $Default existant. Si votre hub d’événements se trouve dans un niveau Standard ou Premium, vous pouvez créer un nouveau groupe de consommateurs.
Lorsque vous vous connectez au hub d’événements, si vous sélectionnez Identité managée comme mode d’authentification, le rôle Azure Event Hubs Propriétaire des données est accordé à l’identité managée pour la tâche Stream Analytics. Pour en savoir plus sur les identités managées pour un hub d’événements, consultez Utiliser des identités managées pour accéder à un hub d’événements à partir d’un travail Azure Stream Analytics.
Les identités managées éliminent les limitations des méthodes d’authentification basées sur l’utilisateur. Ces limitations incluent la nécessité de se réauthentifier en cas de changement de mot de passe ou d’expiration du jeton d’utilisateur tous les 90 jours.
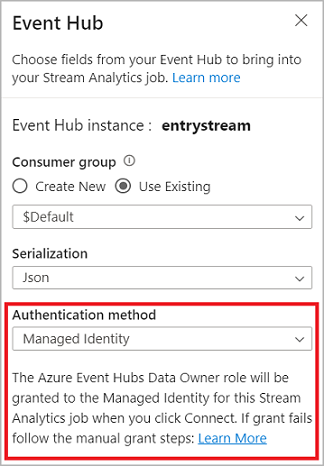
Après avoir configuré les détails de votre hub d’événements et sélectionné Connecter, vous pouvez ajouter des champs manuellement à l’aide de l’option + Ajouter un champ si vous connaissez les noms de champs. Pour détecter automatiquement les types de champs et de données en fonction d’un échantillon des messages entrants, sélectionnez Détection automatique des champs. Sélectionnez le symbole de l’engrenage pour modifier les informations de connexion si nécessaire.
Quand les travaux Stream Analytics détectent les champs, vous les voyez dans la liste. Vous voyez également un aperçu en direct des messages entrants dans le tableau Aperçu des données sous la vue du diagramme.
Modifier les données d’entrée
Vous pouvez modifier les noms de champs, supprimer les champs, modifier le type de données ou modifier l’heure de l’événement (Marquer comme heure de l’événement : clause TIMESTAMP BY si un champ de type datetime) en sélectionnant le symbole à trois points en regard de chaque champ. Vous avez également la possibilité de développer, de sélectionner et de modifier les champs imbriqués des messages entrants, comme illustré sur l’image suivante.
Conseil
Ce processus s’applique également aux données d’entrée de Azure IoT Hub et de Azure Data Lake Storage Gen2.

Voici les types de données disponibles :
- DateHeure : champ de date et heure au format ISO.
- Flottant : nombre décimal.
- Entier : nombre entier.
- Enregistrement : objet imbriqué comportant plusieurs enregistrements.
- Chaîne : texte.
Azure IoT Hub comme entrée de streaming
Azure IoT Hub est un service managé, hébergé dans le cloud, qui joue le rôle de hub de messages central pour la communication entre une application IoT et les appareils attachés. Vous pouvez utiliser les données d’appareil IoT envoyées au hub IoT comme entrée pour un travail Stream Analytics.
Note
Vous pouvez utiliser une entrée Azure IoT Hub dans l’éditeur sans code du portail Azure Stream Analytics.
Pour ajouter un hub IoT en tant qu’entrée de streaming en continu pour votre tâche, sélectionnez le IoT Hub sous Entrées dans le ruban. Renseignez ensuite les informations nécessaires dans le volet droit pour connecter IoT Hub à votre travail. Pour en savoir plus sur les détails de chaque champ, consultez Transfert de données de l'IoT Hub vers le travail Stream Analytics.

Azure Data Lake Storage Gen2 en tant qu’entrée de streaming
Azure Data Lake Storage Gen2 (ADLS Gen2) est une solution de lac de données d’entreprise basée sur le cloud. Il est conçu pour stocker de gros volumes de données dans n’importe quel format et pour faciliter les charges de travail analytiques Big Data. Stream Analytics peut traiter les données stockées dans ADLS Gen2 en tant que flux de données. Pour en savoir plus sur ce type d’entrée, consultez Transférer des données depuis ADLS Gen2 vers un travail Stream Analytics.
Note
Vous pouvez utiliser l’entrée Azure Data Lake Storage Gen2 dans l’éditeur sans code du portail Azure Stream Analytics.
Pour ajouter un ADLS Gen2 en tant qu’entrée de streaming pour votre tâche, sélectionnez l’ADLS Gen2 sous Entrées dans le ruban. Renseignez ensuite les informations nécessaires dans le volet droit pour connecter ADLS Gen2 à votre travail. Pour en savoir plus sur les détails de chaque champ, consultez Transférer des données depuis ADLS Gen2 vers un travail Stream Analytics.

Entrées de données de référence
Les données de référence sont statiques ou changent lentement au fil du temps. En règle générale, vous l’utilisez pour enrichir les flux entrants et effectuer des recherches dans votre travail. Par exemple, vous pouvez joindre une entrée de flux de données à des données de référence, comme vous effectueriez une jointure SQL pour rechercher des valeurs statiques. Pour plus d’informations sur les entrées de données de référence, consultez Utiliser des données de référence pour effectuer des recherches dans Stream Analytics.
L’éditeur sans code prend désormais en charge deux sources de données de référence :
- Azure Data Lake Storage Gen2
- Azure SQL Database

Azure Data Lake Storage Gen2 en tant que données de référence
Les données de référence du modèle sont une séquence d’objets blob classés en ordre croissant selon la combinaison de date et d’heure spécifiée dans le nom de l’objet blob. Vous pouvez ajouter des objets blob à la fin de la séquence uniquement à l’aide d’une date et d’une heure supérieures à celle spécifiée par le dernier objet blob spécifié dans la séquence. Définissez des objets blob dans la configuration d’entrée.
Tout d’abord, dans la section Entrées du ruban, sélectionnez Référencer ADLS Gen2. Pour voir des détails sur chaque champ, consultez la section sur le stockage Blob Azure dans Utiliser des données de référence pour effectuer des recherches dans Stream Analytics.
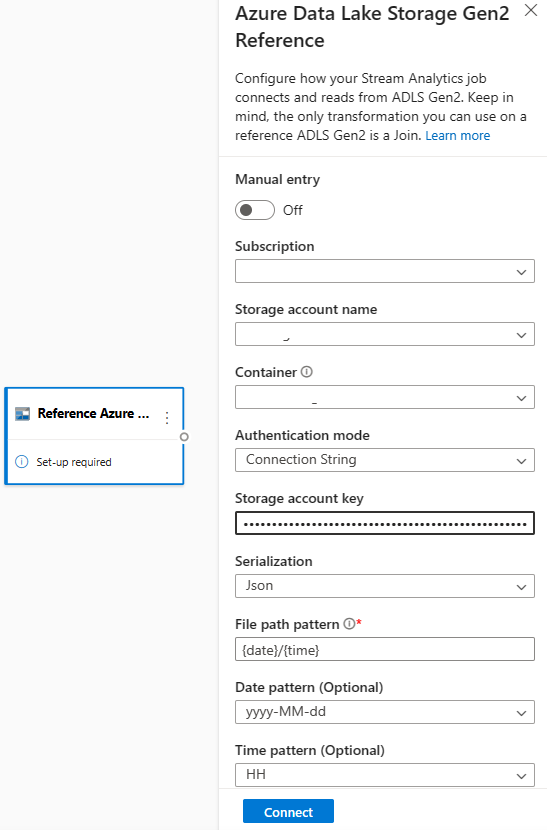
Ensuite, chargez un fichier de tableau JSON. Le système détecte les champs. Utilisez ces données de référence pour effectuer une transformation avec des données en flux continu provenant d’Event Hubs.

Azure SQL Database en tant que données de référence
Vous pouvez utiliser Azure SQL Database en tant que données de référence pour votre travail Stream Analytics dans l’éditeur sans code. Pour plus d’informations, consultez la section relative à SQL Database dans Utiliser des données de référence pour effectuer des recherches dans Stream Analytics.
Pour configurer SQL Database comme entrée de données de référence, sélectionnez Référence SQL Database dans la section Entrées sur le ruban. Renseignez ensuite les informations pour connecter votre base de données de référence et sélectionnez la table avec les colonnes dont vous avez besoin. Vous pouvez également extraire les données de référence de votre table en modifiant manuellement la requête SQL.

Transformations
Les transformations de données de streaming sont fondamentalement différentes des transformations de données par lots. Quasiment toutes les données de diffusion en continu comprennent un composant de temps, qui affecte les tâches de préparation des données impliquées.
Pour ajouter une transformation de données de streaming à votre travail, sélectionnez le symbole de transformation dans la section Opérations du ruban pour cette transformation. La tuile respective est ajoutée à la vue du diagramme. Une fois que vous l’avez sélectionné, vous voyez le volet latéral de cette transformation pour le configurer.

Filtre
Utilisez la transformation Filtrer pour filtrer les événements en fonction de la valeur d’un champ dans l’entrée. Selon le type de données (nombre ou texte), la transformation conserve les valeurs qui correspondent à la condition sélectionnée.

Note
Chaque vignette affiche des informations sur les autres éléments dont la transformation a encore besoin pour être prête. Par exemple, lorsque vous ajoutez une nouvelle vignette, vous voyez un message d’installation requis . Si vous manquez un connecteur de nœud, vous voyez un message d’erreur ou un message d’avertissement .
Gérer les champs
La transformation Gestion des champs permet d’ajouter, de supprimer et de renommer des champs provenant d’une entrée ou d’une autre transformation. Les paramètres du volet latéral vous permettent d’ajouter un nouveau champ en sélectionnant Ajouter un champ ou en ajoutant tous les champs à la fois.

Vous pouvez également ajouter un nouveau champ à l’aide des fonctions intégrées pour agréger les données en amont. Actuellement, les fonctions intégrées prises en charge sont certaines fonctions dans Les fonctions de chaîne, les fonctions de date et d’heure et les fonctions mathématiques. Pour en savoir plus sur les définitions de ces fonctions, consultez Fonctions intégrées (Azure Stream Analytics).

Conseil
Une fois que vous avez configuré une vignette, la vue de diagramme présente un aperçu des paramètres dans la vignette. Par exemple, vous pouvez voir dans la zone Gestion des champs de l’image précédente les trois premiers champs gérés et les nouveaux noms qui leur sont attribués. Chaque vignette contient des informations pertinentes pour celle-ci.
Agrégat
Utilisez la transformation Aggregate pour calculer une agrégation (Sum, Minimum, Maximum ou Average) chaque fois qu'un nouvel événement se produit sur une période donnée. Cette opération vous offre également la possibilité de filtrer ou de découper l’agrégation en fonction d’autres dimensions de vos données. Vous pouvez inclure une ou plusieurs agrégations dans la même transformation.
Pour ajouter une agrégation, sélectionnez le symbole de transformation. Ensuite, connectez une entrée, sélectionnez l’agrégation, ajoutez des dimensions de filtre ou de tranche, puis sélectionnez la période pendant laquelle l’agrégation est calculée. Dans cet exemple, vous calculez la somme de la valeur de péage par l’état à partir duquel le véhicule provient au cours des 10 dernières secondes.

Pour ajouter une autre agrégation à la même transformation, sélectionnez Ajouter une fonction d’agrégation. Le filtre ou la tranche s’applique à toutes les agrégations de la transformation.
Rejoindre
Utilisez la transformation Jointure pour combiner des événements de deux entrées en fonction des paires de champs que vous sélectionnez. Si vous ne sélectionnez pas de paire de champs, la jointure est basée par défaut sur l’heure. La valeur par défaut est ce qui rend cette transformation différente de celle d’un lot.
Comme avec les jointures classiques, vous disposez d’options pour votre logique de jointure :
- Jointure interne : inclure uniquement les enregistrements des deux tables correspondant à la paire. Dans cet exemple, c'est là que la plaque d'immatriculation correspond aux deux entrées.
- Jointure externe gauche : inclure tous les enregistrements de la table de gauche (la première) et uniquement les enregistrements de la deuxième table correspondant à la paire de champs. Si aucune correspondance n’est trouvée, les champs de la deuxième entrée sont vides.
Pour sélectionner le type de jointure, sélectionnez le symbole correspondant au type préféré dans le volet latéral.
Enfin, sélectionnez la période sur laquelle vous souhaitez que la jointure soit calculée. Dans cet exemple, les 10 dernières secondes sont examinées. Plus la période est longue, moins la sortie est fréquente, et plus de ressources de traitement sont utilisées pour la transformation.
Par défaut, la sortie inclut tous les champs des deux tables. Les préfixes de gauche (premier nœud) et de droite (deuxième nœud) vous aident à différencier la source.

Regrouper par
Utilisez la transformation Regrouper par pour calculer les agrégations sur tous les événements d’une fenêtre de temps donnée. Vous pouvez regrouper par les valeurs d’un ou plusieurs champs. Cette opération est similaire à la transformation Agrégation, mais elle offre plus d’options pour les agrégations. Elle inclut également des options plus complexes pour les fenêtres de temps. Comme pour Agrégation, vous pouvez ajouter plusieurs agrégations par transformation.
Voici les agrégations disponibles dans la transformation :
- Average
- Count
- Maximum
- Minimum
- Percentile (continu et discret)
- Écart type
- Somme
- Variance
Pour configurer la transformation :
- Sélectionnez votre agrégation par défaut.
- Sélectionnez le champ sur lequel vous souhaitez effectuer l’agrégation.
- Sélectionnez un champ de regroupement si vous souhaitez obtenir le calcul d’agrégation pour une autre dimension ou catégorie. Par exemple, État.
- Sélectionnez votre fonction pour les fenêtres de temps.
Pour ajouter une autre agrégation à la même transformation, sélectionnez Ajouter une fonction d’agrégation. N’oubliez pas que le champ Grouper par champ et la fonction de fenêtrage s’appliquent à toutes les agrégations de la transformation.

Un horodatage de fin de la fenêtre de temps apparaît pour référence dans la sortie de la transformation. Pour plus d’informations sur les fenêtres de temps que les travaux Stream Analytics prennent en charge, consultez Fonctions de fenêtrage (Azure Stream Analytics).
Union
Utilisez la transformation Union pour connecter deux entrées ou plus. Ajoutez des événements qui ont des champs partagés (avec le même nom et le même type de données) dans une table. La sortie exclut les champs qui ne correspondent pas.
Développer le tableau
Utilisez la transformation Développer le tableau pour créer une ligne pour chaque valeur dans un tableau.

Sorties de streaming
L’expérience de glisser-déposer sans code prend actuellement en charge plusieurs destinations de sortie pour stocker vos données traitées en temps réel.

Azure Data Lake Storage Gen2
Data Lake Storage Gen2 fait du stockage Azure la base pour créer des dépôts Data Lake d’entreprise sur Azure. Il est conçu pour traiter plusieurs pétaoctets d’informations tout en maintenant des centaines de gigabits de débit. Il vous permet de gérer facilement de grandes quantités de données. Le Stockage Blob Azure offre une solution peu coûteuse et évolutive pour stocker de grandes quantités de données non structurées dans le cloud.
Dans la section Sorties sur le ruban, sélectionnez ADLS Gen2 comme sortie pour votre travail Stream Analytics. Sélectionnez ensuite le conteneur dans lequel vous souhaitez envoyer la sortie du travail. Pour plus d’informations sur la sortie d’Azure Data Lake Gen2 pour un travail Stream Analytics, consultez Sortie de stockage d’objets blob et Azure Data Lake Gen2 à partir d’Azure Stream Analytics.
Lorsque vous vous connectez à Azure Data Lake Storage Gen2, si vous sélectionnez Identité managée comme mode d'authentification, le rôle Contributeur aux données blob de stockage est accordé à l'identité managée pour la tâche Stream Analytics. Pour en savoir plus sur les identités managées pour Azure Data Lake Storage Gen2, consultez Utiliser des identités gérées pour authentifier votre tâche Azure Stream Analytics sur Stockage Blob Azure.
Les identités managées éliminent les limitations des méthodes d’authentification basées sur l’utilisateur. Ces limitations incluent la nécessité de se réauthentifier en cas de changement de mot de passe ou d’expiration du jeton d’utilisateur tous les 90 jours.
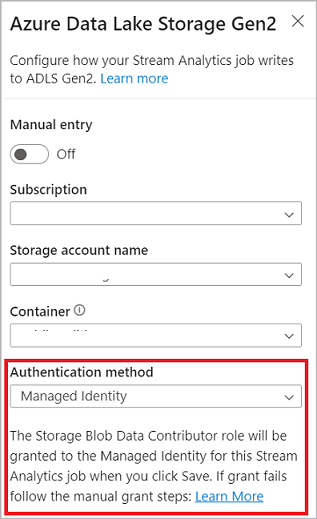
La fonctionnalité Livraison seule et unique (préversion) est prise en charge dans ADLS Gen2 comme sortie de l’éditeur zéro code. Vous pouvez l’activer dans la section Mode écriture de la configuration ADLS Gen2. Pour plus d’informations sur cette fonctionnalité, consultez Exactly once delivery (préversion) dans Azure Data Lake Gen2.

L'option Écrire dans une table Delta Lake (aperçu) est prise en charge dans ADLS Gen2 comme une option de sortie pour l'éditeur sans code. Vous pouvez accéder à cette option dans la section Sérialisation dans la configuration ADLS Gen2. Pour plus d’informations sur cette fonctionnalité, consultez Écriture dans une table Delta Lake.

Azure Synapse Analytics
Des travaux Azure Stream Analytics peuvent envoyer une sortie à une table de pool SQL dédiée dans Azure Synapse Analytics, et traiter des taux de débit jusqu’à 200 Mo par seconde. Stream Analytics prend en charge les besoins les plus exigeants en matière d’analyse en temps réel et de traitement des données de chemin réactif pour des charges de travail telles que les rapports et les tableaux de bord.
Important
La table de pool SQL dédié doit être présente pour vous permettre de l'ajouter en tant qu'entrée à votre tâche Stream Analytics. Le schéma de table doit correspondre aux champs et aux types dans la sortie de votre travail.
Dans la section Sorties sur le ruban, sélectionnez Synapse comme sortie pour votre travail Stream Analytics. Sélectionnez ensuite la table de pool SQL à laquelle vous souhaitez envoyer la sortie du travail. Pour plus d’informations sur la sortie Azure Synapse pour une tâche Stream Analytics, consultez la sortie Azure Synapse Analytics depuis Azure Stream Analytics.
Azure Cosmos DB, une base de données distribuée globale
Azure Cosmos DB est un service de base de données distribuée à l’échelle mondiale, qui offre une mise à l’échelle élastique et sans limite dans le monde entier. Il offre également des requêtes enrichies et une indexation automatique sur des modèles de données indépendants du schéma.
Dans la section Sorties sur le ruban, sélectionnez CosmosDB comme sortie pour votre travail Stream Analytics. Pour plus d’informations sur la sortie Azure Cosmos DB pour un travail Stream Analytics, consultez Sortie Azure Cosmos DB depuis Azure Stream Analytics.
Lorsque vous vous connectez à Azure Cosmos DB, si vous sélectionnez Identité managée comme mode d’authentification, le rôle Contributeur est accordé à l’identité managée pour le travail Stream Analytics. Pour en savoir plus sur les identités managées pour Azure Cosmos DB, consultez Utiliser des identités managées pour accéder à Azure Cosmos DB à partir d’un travail Azure Stream Analytics (préversion).
La sortie Azure Cosmos DB dans l’éditeur sans code prend également en charge la méthode d’authentification des identités managées. Cette méthode offre les mêmes avantages que dans la sortie ADLS Gen2.
Azure SQL Database
Azure SQL Database est un moteur de base de données PaaS (Platform as a Service) entièrement managé qui vous permet de créer une couche de stockage de données hautement disponible et hautes performances pour les applications et les solutions dans Azure. À l’aide de l’éditeur sans code, vous pouvez configurer des travaux Azure Stream Analytics pour écrire les données traitées dans une table existante dans SQL Database.
Pour configurer Azure SQL Database en tant que sortie, dans la section Sorties du ruban, sélectionnez SQL Database. Entrez ensuite les informations nécessaires pour vous connecter à votre base de données SQL et sélectionnez la table dans laquelle vous souhaitez écrire des données.
Important
La table Azure SQL Database doit être présente pour vous permettre de l’ajouter en tant qu’entrée à votre tâche Stream Analytics. Le schéma de table doit correspondre aux champs et aux types dans la sortie de votre travail.
Pour plus d’informations sur la sortie dans Azure SQL Database d’un travail Stream Analytics, consultez Sortie dans Azure SQL Database d’Azure Stream Analytics.
Event Hubs
Avec les données en temps réel qui passent à ASA, l’éditeur sans code peut transformer et enrichir les données, puis générer les données vers un autre hub d’événements. Vous pouvez choisir la sortie Event Hubs quand vous configurez votre travail Azure Stream Analytics.
Pour configurer Event Hubs en tant que sortie, sélectionnez Event Hub sous la section Sorties du ruban. Entrez ensuite les informations nécessaires pour vous connecter à votre hub d’événements dans lequel vous souhaitez écrire des données.
Pour plus d'informations sur la sortie Event Hubs d'un job Stream Analytics, consultez La sortie Event Hubs depuis Azure Stream Analytics.
Explorateur de données Azure
Azure Data Explorer est une plateforme d’analytique Big Data très performante et complètement managée, qui facilite l’analyse de grands volumes de données. Vous pouvez également utiliser Azure Data Explorer comme sortie pour votre travail de Azure Stream Analytics à l’aide de l’éditeur sans code.
Pour configurer Azure Data Explorer en tant que sortie, sélectionnez Azure Data Explorer sous la section Outputs du ruban. Entrez ensuite les informations requises pour vous connecter à votre base de données Azure Data Explorer et spécifiez la table dans laquelle vous souhaitez écrire des données.
Important
La table doit exister dans votre base de données sélectionnée, et le schéma de la table doit correspondre exactement aux champs et à leurs types dans la sortie de votre travail.
Pour plus d’informations sur la sortie d’un travail Stream Analytics dans Azure Data Explorer, consultez la sortie Azure Data Explorer à partir d’Azure Stream Analytics (Version Préliminaire).
Power BI
Power BI propose une expérience de visualisation complète pour vos résultats d’analyse de données. En utilisant les données de sortie de Power BI vers Stream Analytics, les données de flux traitées sont écrites dans un jeu de données de streaming Power BI, ce qui vous permet de créer un tableau de bord Power BI en temps quasi réel.
Pour configurer Power BI en tant que sortie, sélectionnez Power BI sous la section Outputs du ruban. Entrez ensuite les informations requises pour vous connecter à votre espace de travail Power BI et fournissez les noms du jeu de données de streaming et de la table dans laquelle vous souhaitez écrire les données. Pour en savoir plus sur les détails de chaque champ, consultez Sortie Power BI d’Azure Stream Analytics.
Aperçu des données, erreurs de création, journaux d'exécution et indicateurs
L’expérience de glisser-déplacer sans code fournit des outils permettant de créer un pipeline d’analyse, de résoudre ses problèmes et d’évaluer son niveau de performance pour les données de diffusion en continu.
Aperçu instantané des données pour les entrées
Lorsque vous vous connectez à une source d’entrée, telle qu’un hub d’événements, puis sélectionnez sa vignette dans l’affichage diagramme (onglet Aperçu des données ), vous voyez un aperçu en direct des données entrantes si toutes les conditions suivantes sont remplies :
- Les données sont en cours de transmission de type push.
- L’entrée est configurée correctement.
- Les champs sont ajoutés.
Comme illustré dans la capture d’écran suivante, si vous souhaitez afficher ou accéder à une section spécifique, vous pouvez suspendre l’aperçu (1). Vous pouvez également le redémarrer si vous avez terminé.
Vous pouvez également afficher les détails d’un enregistrement spécifique (une cellule dans la table) en le sélectionnant, puis en sélectionnant Afficher/masquer les détails (2). La capture d’écran montre la vue détaillée d’un objet imbriqué dans un enregistrement.

Aperçu statique pour les transformations et les sorties
Après avoir ajouté et configuré des étapes dans la vue schématique, vous pouvez tester leur comportement en sélectionnant Obtenir un aperçu statique.

Lorsque vous sélectionnez le bouton, le travail Stream Analytics évalue toutes les transformations et sorties pour vous assurer qu’elles sont correctement configurées. Stream Analytics affiche ensuite les résultats dans l’aperçu statique des données, comme illustré dans l’image suivante.

Vous pouvez actualiser l’aperçu en sélectionnant Actualiser l’aperçu statique (1). Quand vous actualisez l’aperçu, le travail Stream Analytics utilise de nouvelles données à partir de l’entrée et évalue toutes les transformations. Il renvoie ensuite une sortie avec les mises à jour que vous pourriez avoir effectuées. L’option Afficher/masquer les détails est également disponible (2).
Erreurs de création
Si vous avez des erreurs de création ou des avertissements, l’onglet Erreurs de création les répertorie, comme illustré dans la capture d’écran suivante. La liste comprend les détails de l’erreur ou de l’avertissement, le type de carte (entrée, transformation ou sortie), le niveau d’erreur et une description de l’erreur ou de l’avertissement.

Journaux d'exécution
Des journaux de runtime apparaissent aux niveaux avertissement, erreur ou information quand un travail est en cours d’exécution. Ces journaux sont utiles quand vous souhaitez modifier la topologie ou la configuration de votre travail Stream Analytics à des fins de résolution des problèmes. Activez les journaux de diagnostic et envoyez-les à l'espace de travail Log Analytics dans Settings pour obtenir davantage d'informations sur vos tâches en cours à des fins de débogage.

Dans l’exemple de capture d’écran suivant, l’utilisateur configure la sortie SQL Database avec un schéma de table qui ne correspond pas aux champs de la sortie du travail.

Mesures
Si le travail est en cours d’exécution, vous pouvez surveiller l'état de santé de votre travail sous l’onglet Métriques. Les quatre métriques affichées par défaut sont Retard de filigrane, Événements d’entrée, Événements d’entrée non traités et Événements de sortie. Utilisez ces métriques pour comprendre si les événements entrent et sortent du travail sans créer de backlog en entrée.

Vous pouvez sélectionner d’autres métriques dans la liste. Pour comprendre toutes les métriques en détail, consultez Métriques des travaux Azure Stream Analytics.
Démarrer un job Stream Analytics
Vous pouvez enregistrer le travail à tout moment lors de sa création. Après avoir configuré les entrées de streaming, les transformations et les sorties de diffusion en continu pour le travail, vous pouvez le démarrer.
Note
Bien que l’éditeur sans code soit en préversion dans le portail Azure Stream Analytics, le service Azure Stream Analytics est en disponibilité générale.

Vous pouvez configurer les options suivantes :
-
Heure de début de sortie : lorsque vous démarrez un travail, sélectionnez une heure pour que le travail commence à créer la sortie.
- Maintenant : cette option rend le point de départ du flux d’événements de sortie identique au démarrage du travail.
- Personnalisé : choisissez le point de départ de la sortie.
- Lors du dernier arrêt : cette option est disponible quand le travail a été démarré précédemment, mais a été arrêté manuellement ou a échoué. Lorsque vous choisissez cette option, la dernière heure de sortie est utilisée pour redémarrer le travail, donc aucune donnée n’est perdue.
- Unités de streaming : les unités de streaming représentent la quantité de calcul et de mémoire attribuée au travail pendant l’exécution de celui-ci. Si vous n’êtes pas sûr du nombre de SUs à choisir, commencez par trois et ajustez selon vos besoins.
- Gestion des erreurs des données de sortie : les stratégies de gestion des erreurs de sortie s’appliquent uniquement quand l’événement de sortie généré par un travail Stream Analytics n’est pas conforme au schéma du récepteur cible. Configurez la stratégie en choisissant Réessayer ou Supprimer. Pour plus d’informations, consultez Politique des erreurs de sortie d'Azure Stream Analytics.
- Démarrer : ce bouton démarre le travail Stream Analytics.

Liste des travaux Stream Analytics dans le portail Azure Event Hubs
Pour afficher la liste de tous les travaux Stream Analytics que vous avez créés à l’aide de l’expérience glisser-déplacer sans code dans le portail Azure Event Hubs, sélectionnez Traiter les données>Travaux Stream Analytics.

Voici les éléments de l’onglet Travaux Stream Analytics :
- Filtre : filtrez la liste par nom de travail.
- Actualiser : actuellement, la liste ne s’actualise pas automatiquement. Utilisez l’option Actualiser pour actualiser la liste et afficher l’état le plus récent.
- Nom du travail : le nom de cette zone est celui que vous fournissez à la première étape de la création d’un travail. Vous ne pouvez pas le modifier. Sélectionnez le nom du travail pour ouvrir le travail dans l’expérience glisser-déplacer sans code où vous pouvez arrêter le travail, le modifier et le redémarrer.
- État : cette zone affiche l’état du travail. Sélectionnez Actualiser en haut de la liste pour afficher l’état le plus récent.
- Unités de diffusion en continu : cette zone affiche le nombre d’unités de diffusion en continu que vous sélectionnez lorsque vous démarrez le travail.
- Filigrane de sortie : cette zone fournit un indicateur de l’activité des données produites par le travail. Tous les événements avant l'horodatage sont déjà calculés.
- Surveillance du travail : sélectionnez Ouvrir les métriques pour afficher les métriques associées à ce travail Stream Analytics. Pour plus d’informations sur les métriques que vous pouvez utiliser pour superviser votre travail Stream Analytics, consultez Métriques des travaux Azure Stream Analytics.
- Opérations : démarrer, arrêter ou supprimer le travail.
Étapes suivantes
Découvrez comment utiliser l’éditeur sans code pour traiter les scénarios courants à l’aide de modèles prédéfinis :