Analyser les performances des travaux Azure Stream Analytics à l’aide des métriques et dimensions
Pour comprendre l’intégrité d’un travail Azure Stream Analytics, il est important de savoir comment utiliser les métriques et dimensions du travail. Vous pouvez utiliser le portail Azure, l’extension Visual Studio Code Stream Analytics ou un Kit de développement logiciel (SDK) pour obtenir les métriques et dimensions qui vous intéressent.
Cet article montre comment utiliser les métriques et les dimensions de travail Stream Analytics pour analyser les performances d’un travail via le portail Azure.
Le délai en filigrane et les événements d’entrée placés dans le backlog sont les principales métriques qui permettent de déterminer les performances de votre travail Stream Analytics. Si le délai en filigrane de votre travail augmente continuellement et si les événements d’entrée sont placés dans le backlog, cela signifie que votre travail n’arrive pas à suivre le rythme des événements d’entrée et à produire des sorties en temps opportun.
En guise de point de départ, examinons plusieurs exemples pour analyser les performances du travail via les données de la métrique Délai en filigrane.
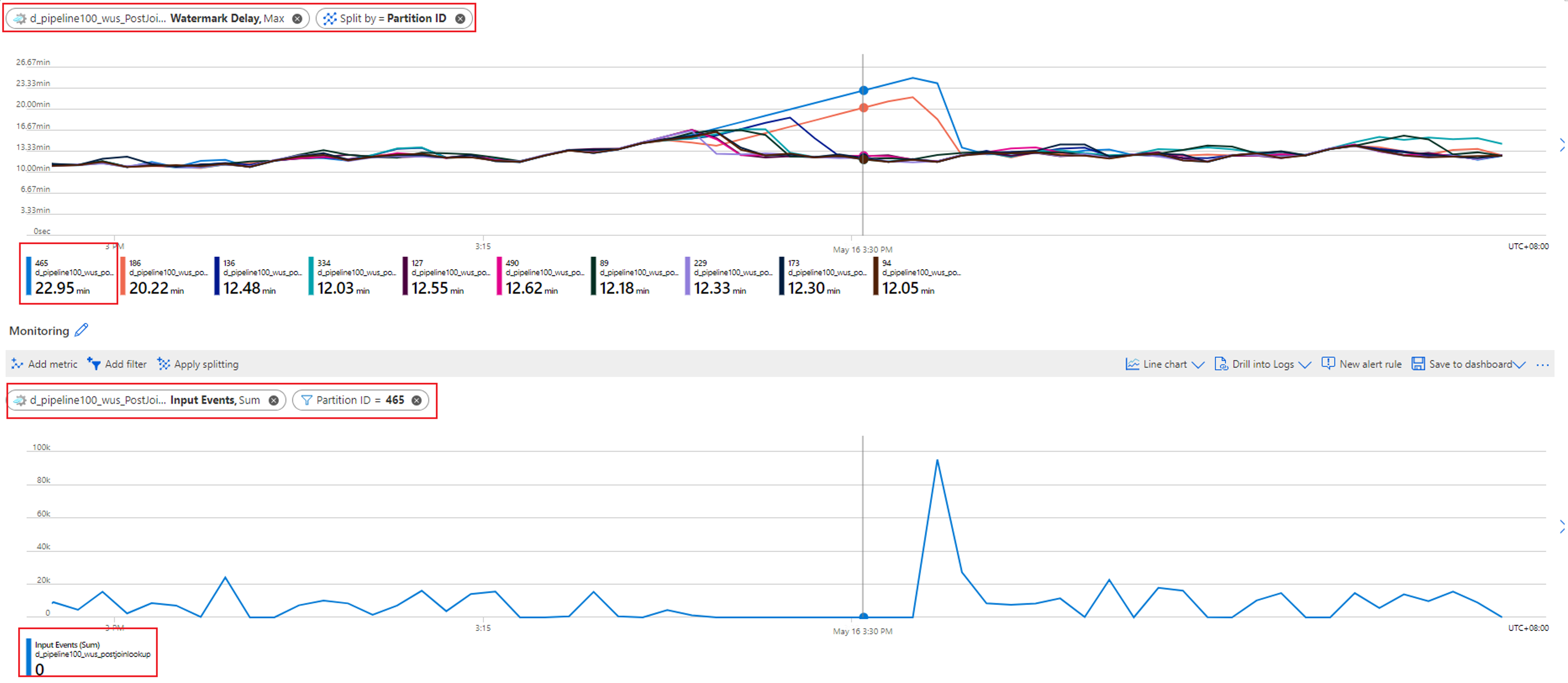
L’absence d’entrée pour certaines partitions entraîne une augmentation du délai en filigrane du travail
Si le délai en filigrane de votre travail parallèle embarrassant augmente constamment, accédez aux Métriques. Suivez ensuite les étapes ci-après pour déterminer si la cause racine est un manque de données dans certaines partitions de votre source d’entrée :
Vérifiez quelle partition présente le délai en filigrane croissant. Sélectionnez la métrique Délai en filigrane et fractionnez-la par la dimension ID de partition. Dans l’exemple suivant, la partition 465 présente un délai en filigrane élevé.

Vérifiez si des données d’entrée sont manquantes pour cette partition. Sélectionnez la métrique Événements d’entrée et filtrez-la sur cet ID de partition spécifique.


Quelles autres actions pouvez-vous entreprendre ?
Le délai en filigrane pour cette partition augmente parce qu’aucun événement d’entrée ne circule dans cette partition. Si la fenêtre de tolérance de votre travail pour les arrivées tardives est de plusieurs heures et si aucune donnée d’entrée ne circule dans une partition, le délai en filigrane pour cette partition continuera d’augmenter jusqu’à ce que la fenêtre d’arrivée tardive soit atteinte.
Par exemple, si votre fenêtre d’arrivée tardive est de 6 heures et si les données d’entrée ne circulent pas dans la partition d’entrée 1, le délai en filigrane pour la partition de sortie 1 augmentera jusqu’à atteindre 6 heures. Vous pouvez vérifier si votre source d’entrée produit des données comme prévu.
Une asymétrie des données d’entrée entraîne un délai en filigrane élevé
Comme mentionné dans le cas précédent, lorsque votre travail parallèle embarrassant présente un délai en filigrane élevé, la première chose à faire consiste à fractionner la métrique Délai en filigrane par la dimension ID de partition. Vous pouvez ensuite identifier si toutes les partitions ont un délai en filigrane élevé, ou s’il ne s’agit que de quelques-uns d’entre elles.
Dans l’exemple suivant, les partitions 0 et 1 ont un délai en filigrane (environ 20 à 30 secondes) plus élevé que les huit autres partitions. Les délais en filigrane des autres partitions sont toujours stables à environ 8 à 10 secondes.

Voyons à quoi ressemblent les données d’entrée pour toutes ces partitions avec la métrique Événements d’entrée fractionnée parID de partition :

Quelles autres actions pouvez-vous entreprendre ?
Comme indiqué dans l’exemple, les partitions (0 et 1) qui ont un délai en filigrane élevé reçoivent beaucoup plus de données d’entrée que les autres partitions. C’est ce que nous appelons une asymétrie des données. Les nœuds de diffusion en continu qui traitent des partitions présentant une asymétrie des données doivent consommer plus de ressources de processeur et de mémoire que d’autres, comme l’illustre la capture d’écran suivante.

Les nœuds de streaming qui traitent des partitions présentant une asymétrie des données plus élevée témoignent d’une utilisation plus élevée du processeur et/ou de l’unité de streaming (SU). Cette utilisation affecte les performances du travail et augmente le délai en filigrane. Pour atténuer ce problème, vous devez répartir vos données d’entrée de manière plus uniforme.
Vous pouvez également déboguer ce problème avec le diagramme de travail physique. Consultez Diagramme de travail physique : identifier les événements d’entrée distribués de façon inégale (asymétrie des données).
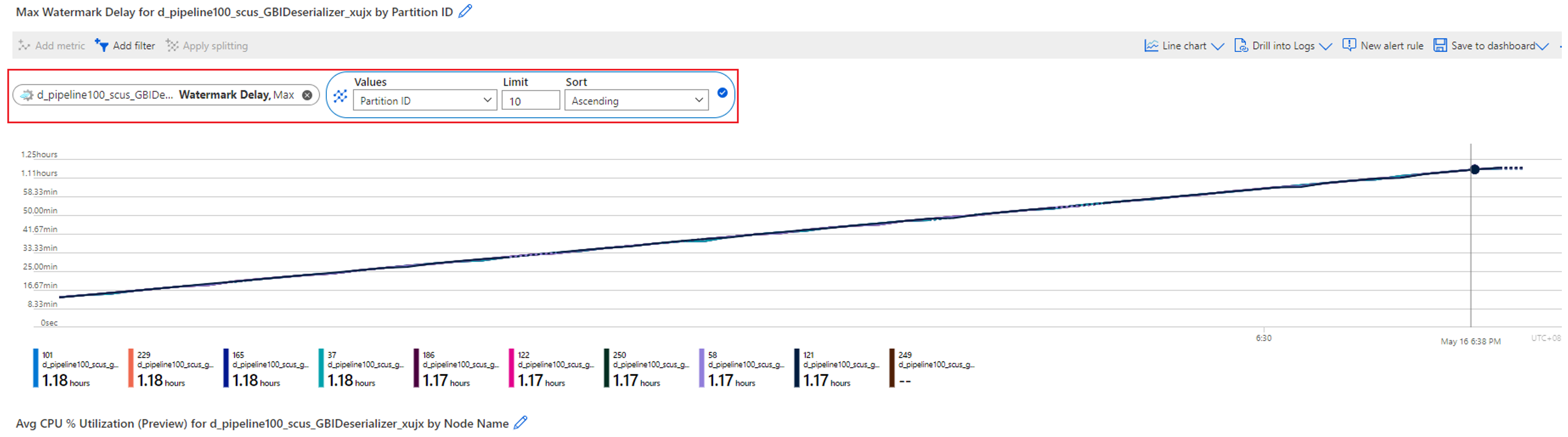
Une surcharge du processeur ou de la mémoire augmente le délai en filigrane
Quand un travail parallèle embarrassant présente un délai en filigrane croissant, il se peut que cela ne se produise pas seulement sur une ou quelques partitions, mais sur toutes les partitions. Comment vérifiez-vous que votre travail est dans ce cas ?
Fractionnez la métrique Délai en filigrane par ID de partition. Par exemple :
Fractionnez la métrique Événements d’entrée par ID de partition pour vérifier s’il existe une asymétrie des données d’entrée pour chaque partition.
Vérifiez l’utilisation du processeur et de l’unité de streaming pour déterminer si l’utilisation est trop élevée dans tous les nœuds de streaming.
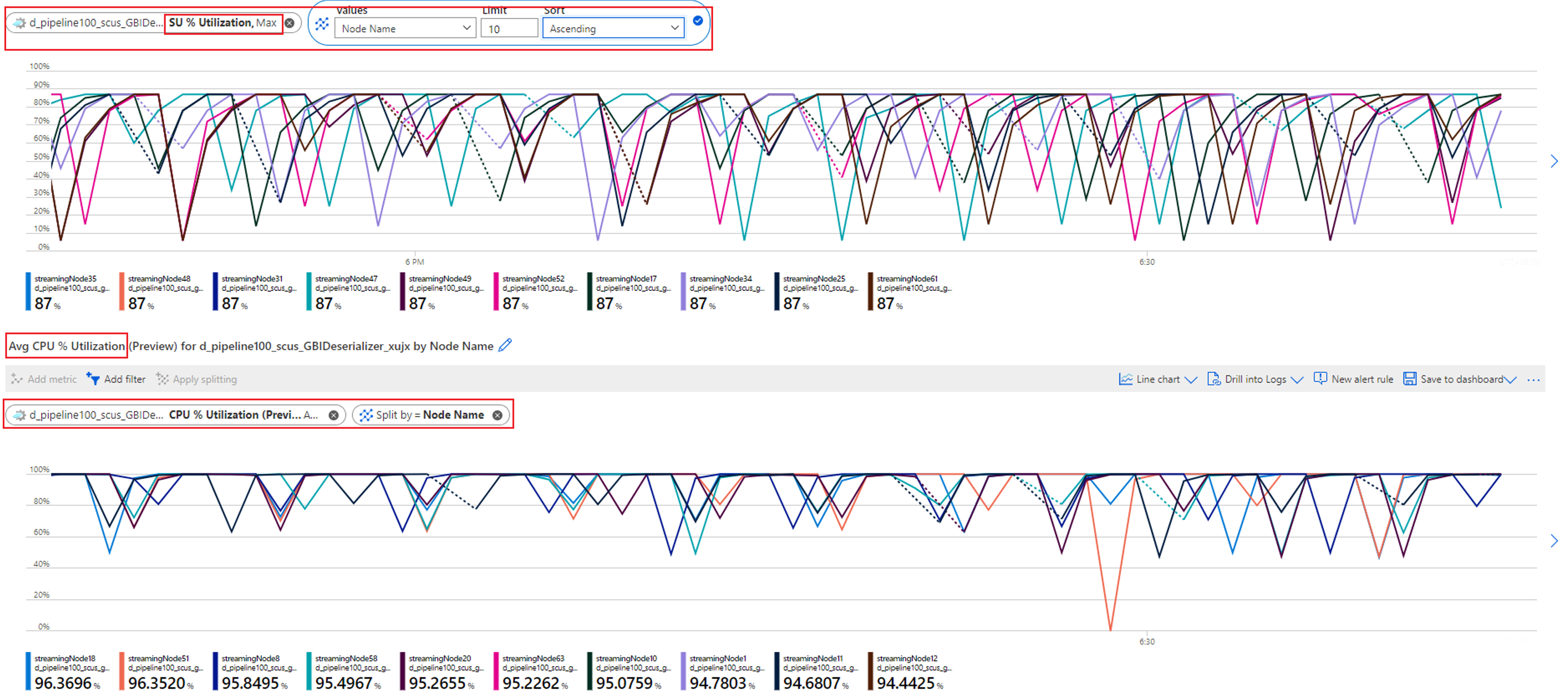
Si l’utilisation du processeur et de l’unité de streaming est très élevée (plus de 80 pour cent) dans tous les nœuds de streaming, vous pouvez conclure que ce travail a une grande quantité de données traitées dans chaque nœud de streaming.
Vous pouvez en outre contrôler le nombre de partitions allouées à un nœud de streaming en vérifiant la métrique Événements d’entrée. Filtrez par ID de nœud de streaming avec la dimension Nom de nœud et fractionnez par ID de partition.
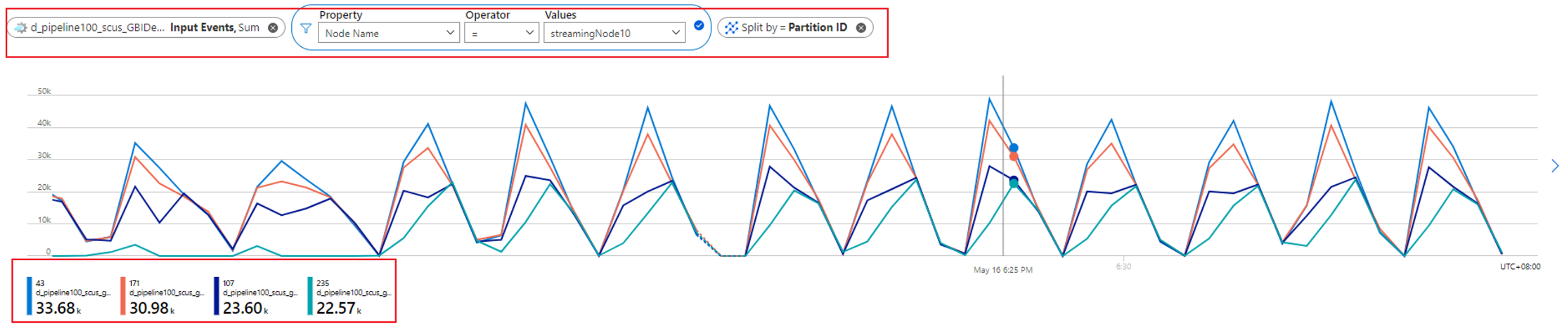
La capture d’écran précédente montre que quatre partitions sont allouées à un nœud de streaming qui occupe environ 90 à 100 % de la ressource de nœud de streaming. Vous pouvez utiliser une approche similaire pour examiner les autres nœuds de streaming afin de confirmer qu’ils traitent également des données de quatre partitions.



Quelles autres actions pouvez-vous entreprendre ?
Vous pourriez réduire le nombre de partitions de chaque nœud de streaming afin de réduire les données d’entrée pour celui-ci. À cette fin, vous pouvez doubler les unités de streaming pour que chaque nœud de streaming gère les données de deux partitions. Vous pouvez également quadrupler les unités de streaming pour que chaque nœud de streaming gère les données d’une partition. Pour plus d’informations sur la relation entre l’attribution d’unités de streaming et le nombre de nœuds de streaming, consultez Comprendre et ajuster les unités de streaming.
Que dois-je faire si le délai en filigrane continue d’augmenter quand un seul nœud de streaming gère les données d’une seule partition ? Repartitionnez votre entrée avec davantage de partitions pour réduire la quantité de données dans chaque partition. Pour plus de détails, consultez Utiliser le repartitionnement pour optimiser des travaux Azure Stream Analytics.
Vous pouvez également déboguer ce problème avec le diagramme de travail physique. Consultez Diagramme de travail physique : identifier la cause d’une surcharge de processeur ou de mémoire.