Détection d’anomalies dans Azure Stream Analytics
Disponible à la fois dans le cloud et Azure IoT Edge, Azure Stream Analytics offre des fonctionnalités de détection des anomalies basées sur un Machine Learning intégré qui peuvent permettre de surveiller les deux anomalies qui se produisent le plus souvent : temporaires et persistantes. Les fonctions AnomalyDetection_SpikeAndDip et AnomalyDetection_ChangePoint permettent de détecter des anomalies directement dans votre travail Stream Analytics.
Les modèles Machine Learning supposent une série chronologique équitablement échantillonnée. Si la série chronologique n’est pas uniforme, vous pouvez insérer une étape d’agrégation avec une fenêtre bascule avant d’appeler la détection d’anomalie.
Pour l’instant, les opérations de Machine Learning ne prennent pas en charge les tendances de saisonnalité ni les corrélations multivariées.
Détection des anomalies à laide de Machine Learning dans Azure Stream Analytics
La vidéo suivante montre comment détecter une anomalie en temps réel à l’aide des fonctions Machine Learning dans Azure Stream Analytics.
Comportement du modèle
En règle générale, la précision du modèle s’améliore avec l’augmentation des données dans la fenêtre glissante. Les données de la fenêtre glissante spécifiée sont traitées comme si elles faisaient partie de la plage normale de valeurs pour cette période. Le modèle ne prend en considération que l’historique des événements de la fenêtre glissante pour vérifier si l’événement actuel est anormal. À mesure que la fenêtre glissante se déplace, les anciennes valeurs sont supprimées de l’entraînement du modèle.
Les fonctions établissent une certaine normalité selon ce qu’elles ont déjà vu jusqu’à présent. Les valeurs hors norme sont identifiées par la comparaison par rapport à la normale établie au sein du niveau de confiance. La taille de la fenêtre doit être basée sur le nombre minimal d’événements requis pour former le modèle à un comportement normal afin qu’il puisse reconnaître une anomalie lorsqu’elle se produit.
Le temps de réponse du modèle augmente avec la taille de l’historique, car il doit effectuer une comparaison avec un nombre plus élevé d’événements passés. Nous vous recommandons d’inclure uniquement le nombre nécessaire d’événements pour améliorer les performances.
Des lacunes dans la série chronologique peuvent être le résultat du modèle qui ne reçoit pas d’événements à certains moments au fil du temps. Cette situation est gérée par Stream Analytics à l’aide de la logique d'imputation. La taille de l’historique, ainsi que la durée, pour la même fenêtre glissante sont utilisées pour calculer la vitesse moyenne à laquelle les événements sont attendus.
Un générateur d’anomalies disponible ici peut être utilisé pour alimenter un Iot Hub en données avec différents modèles d’anomalies. Un travail Azure Stream Analytics peut être configuré avec ces fonctions de détection d’anomalies pour lire à partir de ce hub Iot et détecter les anomalies.
Pics et baisses
Les anomalies temporaires d’un flux d’événements d’une série chronologique sont appelées « pics et baisses ». Les pics et baisses peuvent être surveillés à l’aide de l’opérateur basé sur Machine Learning AnomalyDetection_SpikeAndDip.
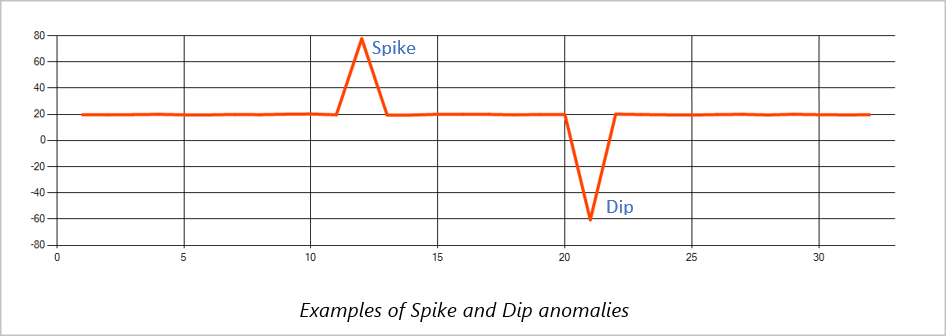
Dans la même fenêtre glissante, si un deuxième pic est plus petit que le premier, le score calculé pour le plus petit pic n’est probablement pas suffisamment important par rapport au score du premier pic au niveau de confiance spécifié. Vous pouvez essayer de réduire le paramètre de niveau de confiance du modèle pour détecter ces anomalies. Toutefois, si vous commencez à recevoir trop d’alertes, vous pouvez utiliser un intervalle de confiance plus élevé.
L’exemple de requête suivant suppose une vitesse d’entrée uniforme d’un événement par seconde dans une fenêtre glissante de 2 minutes avec un historique de 120 événements. La dernière instruction SELECT extrait et génère le score et le statut d’anomalie avec un niveau de confiance de 95 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Point de changement
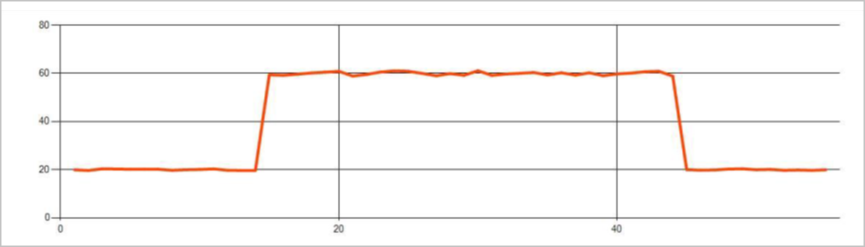
Les anomalies persistantes d’un flux d’événements d’une série chronologique sont des modifications de la distribution des valeurs du flux d’événements, telles que des modifications du niveau et des tendances. Dans Stream Analytics, ces anomalies sont détectées à l’aide de l’opérateur basé sur Machine Learning AnomalyDetection_ChangePoint.
Les changements persistants durent beaucoup plus longtemps que les pics et les chutes et peuvent indiquer des événements catastrophiques. Les modifications persistantes ne sont généralement pas visibles à l’œil nu, mais peuvent être détectées avec l’opérateur AnomalyDetection_ChangePoint.
L’image suivante est un exemple de modification de niveau :
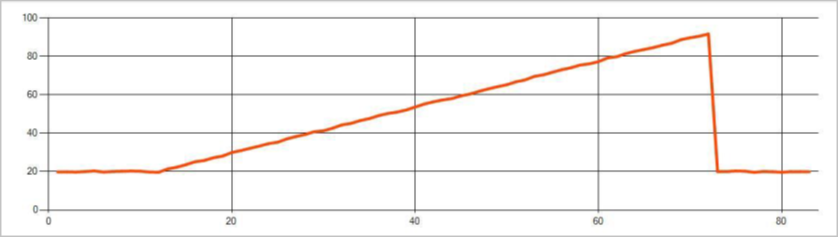
L’image suivante est un exemple de modification de tendance :
L’exemple de requête suivant suppose un taux d’entrée uniforme d’un événement par seconde dans une fenêtre glissante de 20 minutes avec une taille d’historique de 1 200 événements. La dernière instruction SELECT extrait et génère le score et le statut d’anomalie avec un niveau de confiance de 80 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Caractéristiques du niveau de performance
Le niveau de performance de ces modèles dépend de la taille de l’historique, de la durée de la fenêtre, de la charge d'événements, ainsi que de l'utilisation du partitionnement au niveau de la fonction. Cette section décrit ces configurations et fournit des exemples permettant de maintenir les taux d’ingestion de 1 K, 5 K et 10 000 événements par seconde.
- Taille de l’historique - Ces modèles fonctionnent de manière linéaire avec la taille de l’historique. Plus l’historique est volumineux, plus les modèles mettent du temps à évaluer un nouvel événement. Cela est dû au fait que les modèles comparent le nouvel événement à chacun des événements passés dans la mémoire tampon d’historique.
- Durée de la fenêtre - La durée de la fenêtre doit refléter le temps nécessaire à la réception du nombre d'événements défini par la taille de l’historique. Sans ce nombre d’événements dans la fenêtre, Azure Stream Analytics impute les valeurs manquantes. Par conséquent, la consommation du processeur est une fonction de la taille de l’historique.
- Charge d'événements - Plus la charge d’événements est importante, plus les modèles sont sollicités, ce qui a une incidence sur la consommation du processeur. Le travail peut être monté en charge moyennant un parallélisme massif, en supposant qu'il soit judicieux, en terme de logique métier, d'utiliser plus de partitions d’entrée.
- Partitionnement au niveau de la fonction - Le partitionnement au niveau de la fonction s’effectue avec
PARTITION BYau sein de l’appel de fonction de détection des anomalies. Ce type de partitionnement ajoute une charge, car l'état doit être conservé pour plusieurs modèles en même temps. Le partitionnement au niveau de la fonction est utilisé dans des scénarios tels que le partitionnement au niveau de l'appareil.
Relationship
La taille de l’historique, la durée de la fenêtre et la charge totale d’événements sont associées comme suit :
windowDuration (en ms) = 1000 * historySize / (nombre total d’événements d’entrée par seconde / nombre de partitions d’entrée)
Lors du partitionnement de la fonction par deviceId, ajoutez « PARTITION BY deviceId » à l’appel de la fonction de détection d’anomalie.
Observations
Le tableau suivant inclut les observations de débit pour un nœud unique (six SU) pour le cas nonpartitionné :
| Taille de l’historique (événements) | Durée de la fenêtre (ms) | Nombre total d’événements d’entrée par seconde |
|---|---|---|
| 60 | 55 | 2 200 |
| 600 | 728 | 1 650 |
| 6 000 / 750 | 10 910 | 1 100 |
Le tableau suivant inclut les observations de débit pour un nœud unique (six SU) pour le cas partitionné :
| Taille de l’historique (événements) | Durée de la fenêtre (ms) | Nombre total d’événements d’entrée par seconde | Nombre d’appareils |
|---|---|---|---|
| 60 | 1 091 | 1 100 | 10 |
| 600 | 10 910 | 1 100 | 10 |
| 6 000 / 750 | 218 182 | <550 | 10 |
| 60 | 21 819 | 550 | 100 |
| 600 | 218 182 | 550 | 100 |
| 6 000 / 750 | 2 181 819 | <550 | 100 |
L’exemple de code permettant d’exécuter les configurations non partitionées ci-dessus se trouve dans le référentiel Streaming At Scale d’exemples Azure. Le code crée une tâche Stream Analytics sans partitionnement au niveau de la fonction, utilisant des hubs d’événements comme entrée et sortie. La charge d’entrée est générée à l’aide de clients de test. Chaque événement d’entrée est un document json de 1 Ko. Les événements simulent un appareil IoT envoyant des données JSON (pour jusqu’à 1 K d’appareils). La taille de l’historique, la durée de la fenêtre et la charge totale des événements varient sur deux partitions d’entrée.
Remarque
Pour une estimation plus précise, personnalisez les échantillons en fonction de votre scénario.
Identification des goulots d’étranglement
Pour identifier les goulots d’étranglement dans votre pipeline, utilisez le volet Métriques dans votre travail Azure Stream Analytics. Examinez les événements d’entrée/sortie pour le débit, ainsi que le « Délai en filigrane » ou les Événements en backlog, pour voir si le travail suit la vitesse d’entrée. Pour les métriques Event Hubs, recherchez les Demandes limitées et ajustez les Unités de seuil en conséquence. Pour les métriques de Azure Cosmos DB, examinez la valeur Nombre maximal de RU/s consommées par groupe de clés de partition sous Débit pour vous assurer que les groupes de clés de partition sont consommés de manière uniforme. Pour Azure SQL DB, surveillez E/S journal et UC.