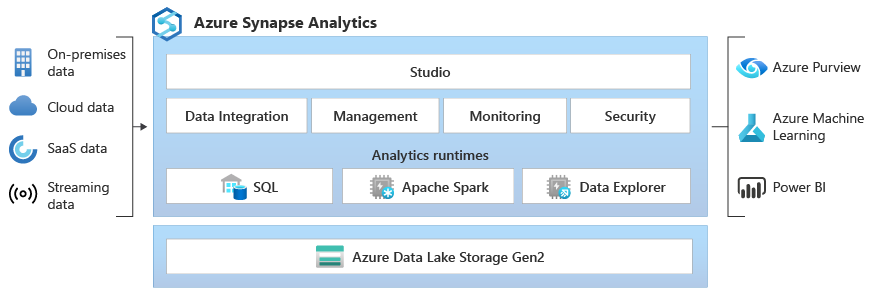
Qu’est-ce que l’explorateur de données Azure Synapse ? (Préversion)
L'explorateur de données Azure Synapse offre aux clients une expérience d'interrogation interactive permettant de dégager des informations à partir des données de journal et de télémétrie. Pour compléter les moteurs de runtime d’analyse SQL et Apache Spark existants, le runtime d’analyse Data Explorer est optimisé pour opérer une analytique des journaux d’activité efficace en utilisant une technologie d’indexation puissante afin d’indexer automatiquement les données en texte libre et semi-structurées que l’on trouve généralement dans les données de télémétrie.
Pour en savoir plus, consultez la vidéo suivante :
En quoi l’explorateur de données Azure Synapse est-il unique ?
Facilité d’ingestion : l’explorateur de données offre des intégrations prêtes à l’emploi pour l’ingestion de données haut débit sans code ou contenant peu de code, et la mise en cache des données de sources en temps réel. Les données peuvent être ingérées à partir de sources comme Azure Event Hubs, Kafka, Azure Data Lake, des agents open source tels que Fluentd/Fluent Bit et un vaste éventail de sources de données cloud et locales.
Aucune modélisation de données complexe : avec Data Explorer, nul besoin de créer des modèles de données ou des scripts complexes pour transformer des données avant de les utiliser.
Aucune maintenance d’index : les tâches de maintenance n’ont pas besoin d’optimiser les données pour les performances des requêtes et aucune maintenance d’index n’est nécessaire. Avec l’explorateur de données, toutes les données brutes sont immédiatement disponibles, ce qui vous permet d’exécuter des requêtes hautes performances avec accès concurrentiel massif sur vos données de diffusion en continu et persistantes. Vous pouvez utiliser ces requêtes pour générer des tableaux de bord et alertes en quasi-temps réel, et connecter des données d’analytique opérationnelle avec le reste de la plateforme d’analytique données.
Démocratisation de l’analytique données : l’explorateur de données démocratise l’analytique du Big Data en libre-service avec le langage de requête Kusto (KQL) intuitif, qui allie l’expressivité et la puissance de SQL à la simplicité d’Excel. Le langage KQL est hautement optimisé pour l’exploration de données brutes de télémétrie et de séries chronologiques en tirant parti de la technologie d’indexation de texte hors pair de l’explorateur de données pour la recherche de texte libre et d’expression régulière, ainsi que des fonctionnalités d’analyse complètes pour l’interrogation de données de traces\texte et de données semi-structurées JSON incluant des tableaux et des structures imbriquées. Le langage KQL offre une prise en charge avancée des séries chronologiques pour la création, la manipulation et l’analyse de plusieurs séries chronologiques, avec prise en charge de l’exécution de Python dans le moteur pour le scoring de modèle.
Technologie éprouvée à l’échelle de pétaoctets : Data Explorer est un système distribué avec des ressources de calcul et du stockage, capable d’adapter son échelle de manière indépendante de façon à pouvoir analyser des gigaoctets voire des pétaoctets de données.
intégration : Azure Synapse Analytics fournit une interopérabilité des données entre l’explorateur de données, Apache Spark et les moteurs SQL, qui permet aux ingénieurs, scientifiques et analystes des données d’accéder facilement et en toute sécurité aux mêmes données, ainsi que de collaborer sur celles-ci, dans le lac de données.
Quand utiliser l’explorateur de données Azure Synapse ?
Utilisez Data Explorer comme plateforme de données pour créer des solutions d'analyse de journaux et d'analyse IoT en quasi temps réel pour :
Consolidez et corrélez vos données de journaux et d’événements dans des sources de données locales, cloud et tierces.
Accélérez votre parcours d’opérations d’intelligence artificielle (reconnaissance de modèle, détection d’anomalie, prévision, etc.).
Remplacez les solutions de recherche de journal basées sur l’infrastructure pour réduire les coûts et accroître la productivité.
Créez des solutions d’analytique IoT pour vos données IoT.
Créez des solutions SaaS d’analytique pour offrir des services à vos clients internes et externes.
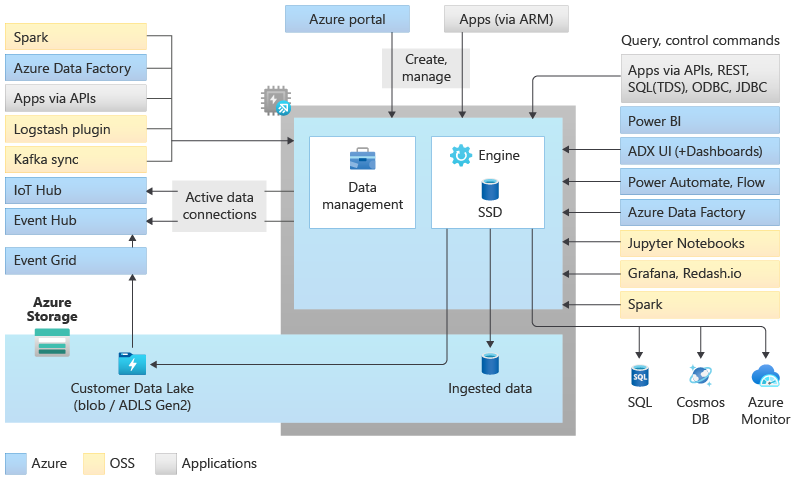
Architecture de pool de l’explorateur de données
Les pools Data Explorer implémentent une architecture de scale-out en séparant les ressources de calcul et de stockage. Celle-ci vous permet de mettre à l’échelle chaque ressource de manière indépendante et, par exemple, d’exécuter plusieurs calculs en lecture seule sur les mêmes données. Les pools Data Explorer consistent en un ensemble de ressources de calcul exécutant le moteur chargé de l’indexation, la compression, la mise en cache et le traitement automatiques des requêtes distribuées. Ils disposent également d’un deuxième ensemble de ressources de calcul exécutant le service de gestion des données responsable des tâches système en arrière-plan, ainsi que de l’ingestion des données managées et en file d’attente. Toutes les données sont conservées sur des comptes de stockage Blob gérés à l’aide d’un format en colonnes compressé.
Les pools de l’explorateur de données prennent en charge un riche écosystème pour l’ingestion de données à l’aide de connecteurs, de kits de développement logiciel (SDK), d’API REST et d’autres fonctionnalités gérées. Celui-ci permet de consommer des données de plusieurs façons pour des requêtes, rapports, tableaux de bord, alertes, API REST et kits de développement logiciel (SDK) ad hoc.
De nombreuses fonctionnalités uniques contribuent à faire de Data Explorer le meilleur moteur analytique pour l’analyse de journaux et de séries chronologiques sur Azure.
Les sections suivantes mettent en évidence les principaux facteurs de différenciation.
L’indexation de données en texte libre et semi-structurées permet d’exécuter des requêtes à haute performance avec accès concurrentiel massif en quasi-temps réel
Data Explorer indexe des données semi-structurées (JSON) et non structurées (texte libre), ce qui rend l’exécution de requêtes performantes sur ce type de données. Par défaut, chaque champ est indexé au cours de l’ingestion des données, avec la possibilité d’utiliser une stratégie de codage de bas niveau afin d’ajuster ou de désactiver l’index pour des champs spécifiques. L’étendue de l’index est une partition de données unique.
L’implémentation de l’index dépend du type du champ, comme suit :
| Type de champ | Implémentation de l’indexation |
|---|---|
| Chaîne | Le moteur crée un index de termes inversé pour les valeurs de colonne de chaîne. Chaque valeur de chaîne est analysée et divisée en termes normalisés, et une liste ordonnée de positions logiques contenant des ordinaux d’enregistrement est enregistrée pour chaque terme. La liste de termes triée ainsi obtenue, ainsi que leurs positions associées, sont stockées sous la forme d’un arbre B (B-tree) immuable. |
| Numérique DateTime TimeSpan |
Le moteur crée un index de transfert basé sur une plage unique. L’index enregistre les valeurs minimales/maximales pour chaque bloc, pour un groupe de blocs et pour la colonne entière dans la partition de données. |
| Dynamique | Le processus d’ingestion énumère tous les éléments « atomiques » dans la valeur dynamique, tels que les noms de propriété, les valeurs et les éléments de tableau, et les transfère au générateur d’index. Les champs dynamiques possèdent le même index de termes inversé que les champs de chaîne. |
Ces fonctionnalités d’indexation efficaces permettent à Data Explorer de rendre les données disponibles en quasi-temps réel pour exécuter des requêtes à haute performance avec accès concurrentiel massif. Le système optimise automatiquement les partitions de données pour améliorer les performances.
Langage de requête Kusto
Le langage KQL dispose d’une communauté importante et en pleine expansion grâce à l’adoption rapide d’Azure Monitor Log Analytics et d’Application Insights, de Microsoft Sentinel, d’Azure Data Explorer et d’autres offres de Microsoft. Le langage est bien conçu avec une syntaxe facile à lire, et permet une transition sans heurt des requêtes de traitement de données simples aux requêtes complexes. Cela permet à Data Explorer de fournir une prise en charge riche d’Intellisense et un vaste éventail de fonctionnalités de construction de langage, ainsi que d’autres fonctionnalités intégrées pour les agrégations, les séries chronologiques et l’analytique utilisateur, qui ne sont pas disponibles dans SQL pour l’exploration rapide des données de télémétrie.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour