Migration de données, ETL et chargement pour les migrations Netezza
Cet article est la deuxième partie d’une série de sept parties qui fournit des conseils sur la migration de Netezza vers Azure Synapse Analytics. L’objectif de cet article sont les bonnes pratiques pour la migration concernant ETL et le chargement.
Considérations relatives à la migration des données
Décisions initiales pour la migration des données à partir de Netezza
Lors de la migration d’un entrepôt de données Netezza, vous devez vous poser des questions de base sur les données. Par exemple :
Les structures de table inutilisées doivent-elle être migrées ?
Quelle est la meilleure approche de migration pour réduire les risques et l’impact utilisateur ?
Lors de la migration de DataMarts, rester physique ou passer au virtuel ?
Les sections suivantes décrivent ces points dans le contexte de la migration à partir de Netezza.
Migrer les tables inutilisées ?
Conseil
Dans les systèmes hérités, il n’est pas rare que les tables deviennent redondantes au fil du temps. Elles n’ont pas besoin d’être migrées dans la plupart des cas.
Il est logique de migrer uniquement les tables qui sont toujours utilisées dans le système existant. Les tables qui ne sont pas actives peuvent être archivées au lieu d’être migrées afin que les données restent disponibles si nécessaire à l’avenir. Pour déterminer les tables encore utilisées, il est préférable de vous fier aux fichiers journaux et métadonnées système plutôt qu’à la documentation, car celle-ci peut être obsolète.
Si cette option est activée, les tables d’historique des requêtes Netezza contiennent des informations qui sont utiles pour savoir quand telle ou telle table a été consultée pour la dernière fois, et ainsi déterminer si une table est candidate à la migration.
Voici un exemple de requête qui recherche si une table spécifique a été utilisée dans une période donnée :
SELECT FORMAT_TABLE_ACCESS (usage),
hq.submittime
FROM "$v_hist_queries" hq
INNER JOIN "$hist_table_access_3" hta USING
(NPSID, NPSINSTANCEID, OPID, SESSIONID)
WHERE hq.dbname = 'PROD'
AND hta.schemaname = 'ADMIN'
AND hta.tablename = 'TEST_1'
AND hq.SUBMITTIME > '01-01-2015'
AND hq.SUBMITTIME <= '08-06-2015'
AND
(
instr(FORMAT_TABLE_ACCESS(usage),'ins') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'upd') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'del') > 0
)
AND status=0;
| FORMAT_TABLE_ACCESS | SUBMITTIME
----------------------+---------------------------
ins | 2015-06-16 18:32:25.728042
ins | 2015-06-16 17:46:14.337105
ins | 2015-06-16 17:47:14.430995
(3 rows)
Cette requête utilise la fonction d’assistance FORMAT_TABLE_ACCESS et le chiffre à la fin de la vue $v_hist_table_access_3 pour déterminer la version de l’historique des requêtes installée.
Quelle est la meilleure approche de migration afin de réduire les risques et l’impact pour les utilisateurs ?
Cette question se pose souvent, car les entreprises cherchent à réduire l’impact des changements sur le modèle de données de l’entrepôt de données afin de gagner en agilité. Les entreprises voient souvent une opportunité de moderniser ou de transformer davantage leurs données lors d’une migration ETL. Cette approche présente un risque plus élevé, car elle modifie plusieurs facteurs simultanément, ce qui rend difficile la comparaison des résultats de l’ancien système par rapport au nouveau. L’apport de modifications de modèle de données ici peut également affecter les travaux ETL en amont ou en aval à d’autres systèmes. Face à ce risque, il est préférable de reconcevoir à cette échelle après la migration de l’entrepôt de données.
Même si un modèle de données est intentionnellement modifié dans le cadre de la migration globale, il est préférable de migrer le modèle existant tel quel vers Azure Synapse, plutôt que de procéder à une réingénierie sur la nouvelle plateforme. Cette approche minimise l'effet sur les systèmes de production existants, tout en bénéficiant des performances et de l'évolutivité élastique de la plateforme Azure pour les tâches de réingénierie ponctuelles.
Dans le cadre d’une migration à partir de Netezza, le modèle de données existant peut souvent être utilisé en l’état pour la migration vers Azure Synapse.
Conseil
Migrez le modèle existant tel quel initialement, même s’il est prévu de changer à l’avenir.
Migrer des DataMarts : garder l’approche physique ou choisir la virtualisation ?
Conseil
La virtualisation des DataMarts peut économiser des ressources de stockage et de traitement.
Dans les environnements d’entrepôt de données Netezza hérités, il est courant de créer plusieurs DataMarts structurés pour fournir de bonnes performances en matière de requêtes et de rapports en libre-service ad hoc pour un service ou une fonction commerciale donnés au sein d’une organisation. En tant que tel, un DataMart se compose généralement d’un sous-ensemble de l’entrepôt de données , il contient des versions agrégées des données sous une forme qui permet aux utilisateurs d’interroger facilement ces données avec des temps de réponse rapides via des outils de requête conviviaux, tels que Microsoft Power BI, Tableau ou MicroStrategy. Ce formulaire est généralement un modèle de données dimensionnel. Les DataMarts peuvent servir à exposer les données sous une forme utilisable, même si le modèle de données de l’entrepôt sous-jacent est différent, par exemple, un coffre de données.
Vous pouvez utiliser des DataMarts pour des unités commerciales individuelles au sein d’une organisation afin d’implémenter des régimes de sécurité des données robustes, en autorisant uniquement l’accès des utilisateurs à des DataMarts spécifiques qui les concernent, et en éliminant, en masquant ou en anonymisant les données sensibles.
Si ces DataMarts sont implémentés sous forme de tables physiques, il faut des ressources de stockage supplémentaires pour les stocker, ainsi que des opérations de traitement supplémentaires pour les créer et les actualiser régulièrement. De plus, comme les données dans les DataMarts sont celles datant de la dernière opération d’actualisation, elles ne sont pas toujours appropriées pour les tableaux de bord de données hautement volatiles.
Conseil
Les performances et la scalabilité d’Azure Synapse permettent la virtualisation sans sacrifier les performances.
Avec l’avènement des architectures MPP évolutives bon marché, comme Azure Synapse, et les caractéristiques de performances intrinsèques de ces architectures, vous pouvez envisager de fournir des fonctionnalités de DataMart sans avoir à instancier le DataMart sous forme d’ensemble de tables physiques. Cela est possible en virtualisant efficacement les DataMarts via des vues SQL sur l’entrepôt de données principal ou via une couche de virtualisation à l’aide de fonctionnalités telles que les vues dans Azure, ou les produits de visualisation de partenaires Microsoft. Cette approche simplifie ou élimine les besoins supplémentaires en stockage et en traitement des agrégations, et réduit le nombre total d’objets de base de données à migrer.
Il y a un autre avantage potentiel à cette approche. En implémentant l’agrégation et la logique de jointure dans une couche de virtualisation et en présentant des outils de création de rapports externes via une vue virtualisée, le traitement requis pour créer ces vues est envoyé dans l’entrepôt de données, qui est généralement le meilleur endroit pour exécuter des jointures, des agrégations et d’autres opérations de ce type sur de gros volumes de données.
Les principaux facteurs conduisant à choisir l’implémentation d’un DataMart virtuel par rapport à un DataMart physique sont les suivants :
Une plus grande agilité : un DataMart virtuel est plus facile à modifier que des tables physiques et les processus ETL associés.
Réduction du coût total de possession : une implémentation virtualisée nécessite moins de magasins et de copies de données.
Élimination des travaux ETL pour migrer et simplifier l’architecture d’entrepôt de données dans un environnement virtualisé.
Amélioration des performances : les DataMarts physiques étaient historiquement plus performants, mais les produits de virtualisation implémentent maintenant des techniques de mise en cache intelligentes pour l’atténuation.
Migration de données à partir de Netezza
Comprendre vos données
Une partie de la planification de la migration consiste à déterminer précisément le volume de données à migrer, car cela peut avoir un impact sur les choix de l’approche de migration. Examinez les métadonnées système pour déterminer l’espace physique pris par les « données brutes » dans les tables à migrer. Dans ce contexte, les « données brutes » correspondent à la quantité d’espace utilisé par les lignes de données d’une table, en excluant les surcharges, telles que les index et la compression. Cela est particulièrement vrai pour les tables de faits les plus volumineuses, qui concentrent généralement plus de 95 % des données.
Pour connaître avec précision le volume de données à migrer pour une table donnée, extrayez un échantillon représentatif des données (par exemple, un million de lignes) dans un fichier de données ASCII plat délimité non compressé. Basez-vous ensuite sur la taille de ce fichier pour obtenir une taille moyenne de données brutes par ligne de cette table. Pour finir, multipliez cette taille moyenne par le nombre total de lignes de la table complète pour obtenir la taille de données brutes de la table. Utilisez cette taille de données brutes dans votre planification.
Mappage de type de données Netezza
Conseil
Évaluez l’impact des types de données non pris en charge dans le cadre de la phase de préparation.
la plupart des types de données Netezza ont un équivalent direct dans Azure Synapse. Le tableau suivant présente ces types de données et l’approche recommandée pour leur mappage.
| Type de données Netezza | Type de données Azure Synapse |
|---|---|
| bigint | bigint |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| DATE | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DOUBLE PRECISION | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | Les types de données INTERVAL ne sont pas pris en charge directement dans Azure Synapse Analytics, mais peuvent être calculés à l’aide de fonctions temporelles comme DATEDIFF. |
| MONEY | MONEY |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| real | RÉEL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Les types de données spatiales comme ST_GEOMETRY ne sont pas pris en charge actuellement dans Azure Synapse Analytics, mais les données peuvent être stockées en type VARCHAR ou VARBINARY. |
| TEMPS | TEMPS |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| timestamp | DATETIME |
Utilisez les métadonnées des tables de catalogue Netezza pour déterminer si l’un de ces types de données doit être migré, et autoriser cette migration dans votre plan de migration. Les principales vues de métadonnées dans Netezza pour ce type de requête sont les suivantes :
_V_USER: la vue utilisateur fournit des informations sur les utilisateurs dans le système Netezza._V_TABLE: la vue table contient la liste des tables créées dans le système de performances Netezza._V_RELATION_COLUMN: la vue catalogue système des colonnes de relation liste toutes les colonnes disponibles dans une table._V_OBJECTS: la vue objets liste les différents objets tels que les tables, les vues, les fonctions, etc., qui sont disponibles dans Netezza.
Par exemple, cette requête SQL Netezza affiche les colonnes et les types de colonnes :
SELECT
tablename,
attname AS COL_NAME,
b.FORMAT_TYPE AS COL_TYPE,
attnum AS COL_NUM
FROM _v_table a
JOIN _v_relation_column b
ON a.objid = b.objid
WHERE a.tablename = 'ATT_TEST'
AND a.schema = 'ADMIN'
ORDER BY attnum;
TABLENAME | COL_NAME | COL_TYPE | COL_NUM
----------+-------------+----------------------+--------
ATT_TEST | COL_INT | INTEGER | 1
ATT_TEST | COL_NUMERIC | NUMERIC(10,2) | 2
ATT_TEST | COL_VARCHAR | CHARACTER VARYING(5) | 3
ATT_TEST | COL_DATE | DATE | 4
(4 rows)
La requête peut être modifiée pour rechercher dans toutes les tables les occurrences de types de données non pris en charge.
Azure Data Factory peut être utilisé pour déplacer des données depuis un environnement Netezza hérité. Pour plus d’informations, consultez Connecteur IBM Netezza.
Les fournisseurs tiers proposent des outils et services permettant d’automatiser la migration, dont le mappage des types de données comme décrit plus haut. En outre, les outils ETL tiers, comme Informatica ou Talend, qui sont déjà utilisés dans l’environnement Netezza peuvent implémenter toutes les transformations de données requises. La section suivante explore la migration des processus ETL tiers existants.
Considérations relatives à la migration ETL
Décisions initiales concernant la migration ETL Netezza
Conseil
Planifiez l’approche de la migration ETL et recourez aux services Azure qui peuvent être utiles.
Pour le traitement ETL/ELT, les entrepôts de données Netezza hérités peuvent utiliser des scripts personnalisés avec des utilitaires Netezza, tels que nzsql et nzload, ou des outils ETL tiers, comme Informatica ou Ab Initio. Parfois, les entrepôts de données Netezza utilisent une combinaison d’approches ETL et ELT qui évolue au fil du temps. Lors de la planification d’une migration vers Azure Synapse, vous devez déterminer la meilleure façon d’implémenter le traitement ETL/ELT requis dans le nouvel environnement tout en réduisant l’impact sur les coûts et les risques. Pour en savoir plus sur le traitement ETL et ELT, consultez l’approche de conception ELT et ETL.
Les sections suivantes décrivent les options de migration et fournissent des recommandations pour différents cas d’usage. Cet organigramme résume une approche :
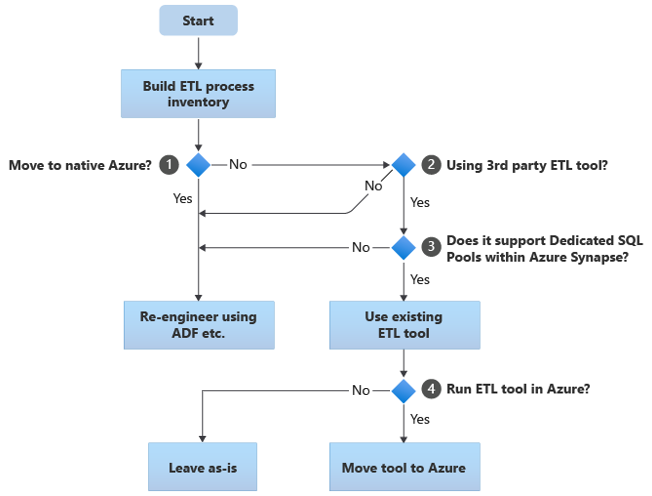
La première étape consiste toujours à créer un inventaire des processus ETL/ELT qui doivent être migrés. Comme pour d’autres étapes, il est possible que les fonctionnalités Azure intégrées standard rendent inutile la migration de certains processus existants. À des fins de planification, il est important de bien évaluer l’ampleur de la migration à effectuer.
Dans l’organigramme précédent, la décision 1 concerne une décision générale sur la migration vers un environnement totalement natif Azure. Si vous passez à un environnement totalement natif Azure, nous vous recommandons de reconcevoir le traitement ETL en utilisant des Pipelines et activités dans Azure Data Factory ou des Pipelines Azure Synapse. Si vous ne passez pas à un environnement totalement natif Azure, la décision 2 consiste à savoir si un outil ETL tiers existant est déjà utilisé.
Conseil
Tirez parti de l’investissement dans des outils tiers existants pour réduire les coûts et les risques.
Si un outil ETL tiers est déjà utilisé, en particulier s’il y a un investissement important dans les compétences, ou si plusieurs workflows et planifications existants utilisent cet outil, la décision 3 consiste à savoir si l’outil peut efficacement utiliser Azure Synapse comme environnement cible. Dans l’idéal, l’outil inclut des connecteurs natifs qui peuvent tirer parti des fonctionnalités Azure, telles que PolyBase ou COPY INTO, pour un chargement de données plus efficace. Il existe un moyen d’appeler un processus externe, comme PolyBase ou COPY INTO, et de passer les paramètres appropriés. Dans ce cas, utilisez les compétences et workflows existants avec Azure Synapse comme nouvel environnement cible.
Si vous décidez de conserver un outil ETL tiers existant, il peut y avoir des avantages à exécuter cet outil dans l’environnement Azure (plutôt que sur un serveur ETL local existant) et à laisser Azure Data Factory gérer l’orchestration globale des workflows existants. Un avantage particulier est que moins de données doivent être téléchargées à partir d’Azure, traitées, puis rechargées dans Azure. Par conséquent, la décision 4 consiste à laisser l’outil existant s’exécuter ou de le déplacer dans l’environnement Azure pour obtenir des avantages en termes de coût, de performances et de scalabilité.
Réingénierie des scripts existants spécifiques à Netezza
Si certains ou tous les traitements ETL/ELT de l’entrepôt Netezza existants sont gérés par des scripts personnalisés qui utilisent des utilitaires spécifiques à Netezza, tels que nzsql ou nzload, ces scripts doivent être recodés pour le nouvel environnement Azure Synapse. De même, si les processus ETL ont été implémentés avec des procédures stockées dans Netezza, ils doivent également être recodés.
Conseil
L’inventaire des tâches ETL à migrer doit inclure des scripts et des procédures stockées.
Certains éléments du processus ETL sont faciles à migrer, par exemple, par simple chargement de données en bloc dans une table de mise en lots à partir d’un fichier externe. Il est même possible d’automatiser ces parties du processus, par exemple, en utilisant PolyBase au lieu de nzload. La réingénierie d’autres parties du processus qui contiennent des procédures SQL et/ou stockées arbitraires prend plus de temps.
Un moyen de vérifier la compatibilité de Netezza SQL avec Azure Synapse consiste à capturer des instructions SQL représentatives dans le journal de requêtes Netezza, à préfixer ces requêtes avec EXPLAIN et (en supposant l’existence un modèle de données migré semblable dans Azure Synapse), à exécuter ces instructions EXPLAIN dans Azure Synapse. Tout code SQL incompatible génère une erreur, et les informations d’erreur peuvent déterminer l’ampleur de la tâche de recodage.
Les partenaires Microsoftproposent des outils et des services pour migrer les procédures Netezza SQL et stockées vers Azure Synapse.
Utiliser des outils ETL tiers
Comme décrit dans la section précédente, dans de nombreux cas, le système d’entrepôt de données hérité existant sera déjà rempli et géré par des produits ETL tiers. Pour obtenir la liste des partenaires d’intégration de données Microsoft pour Azure Synapse, consultez Partenaires d’intégration de données.
Chargement de données à partir de Netezza
Choix à faire pour le chargement de données à partir de Netezza
Conseil
Les outils tiers peuvent simplifier et automatiser le processus de migration et donc réduire les risques.
Quand vous êtes prêt à migrer les données d’un entrepôt de données Netezza, vous devez réfléchir à certains points importants sur le chargement des données. Vous devez déterminer comment les données seront déplacées physiquement de l’environnement Netezza local existant vers Azure Synapse dans le cloud, et quels outils seront utilisés pour effectuer le transfert et le chargement. Tenez compte des questions suivantes, qui sont abordées dans les sections suivantes.
Allez-vous extraire les données dans des fichiers ou les déplacer directement via une connexion réseau ?
Allez-vous orchestrer le processus à partir du système source ou de l’environnement cible Azure ?
Quels outils utiliserez-vous pour automatiser et gérer le processus ?
Transférer des données via des fichiers ou une connexion réseau ?
Conseil
Ayez une idée précise des volumes de données à migrer et de la bande passante réseau disponible, car ces facteurs influencent le choix de l’approche de la migration.
Une fois que les tables de base de données à migrer ont été créées dans Azure Synapse, vous pouvez déplacer les données pour remplir ces tables hors du système Netezza hérité et dans le nouvel environnement. Il y a deux approches principales :
Extraction de fichier : extrayez les données des tables Netezza dans des fichiers plats, normalement au format CSV, en utilisant soit nzsql avec l’option -o, soit l’instruction
CREATE EXTERNAL TABLE. Utilisez une table externe dès que possible, car c’est l’approche qui offre le meilleur débit de données. L’exemple de code SQL suivant crée un fichier CSV par le biais d’une table externe :CREATE EXTERNAL TABLE '/data/export.csv' USING (delimiter ',') AS SELECT col1, col2, expr1, expr2, col3, col1 || col2 FROM your table;Utilisez une table externe si vous exportez des données vers un système de fichiers monté sur un hôte Netezza local. Si vous exportez des données vers une machine distante sur laquelle JDBC, ODBC ou OLEDB est installé, l’option « remotesource odbc » est la clause
USING.Avec cette approche, il faut suffisamment d’espace pour charger les fichiers de données extraits. L’espace peut être local dans la base de données source Netezza (si un stockage suffisant est disponible), ou distant dans le Stockage Blob Azure. Les meilleures performances sont obtenues lorsqu’un fichier est écrit localement, car cela évite la surcharge réseau.
Pour réduire les exigences de stockage et de transfert réseau, il est recommandé de compresser les fichiers de données extraits à l’aide d’un utilitaire tel que gzip.
Une fois extraits, les fichiers plats peuvent être déplacés dans Stockage Blob Azure (colocalisés avec l’instance Azure Synapse cible) ou chargés directement dans Azure Synapse à l’aide de PolyBase ou de COPY INTO. La méthode de déplacement physique des données du stockage local vers l’environnement cloud Azure dépend de la quantité de données et de la bande passante réseau disponible.
Microsoft propose plusieurs options pour déplacer de grands volumes de données, y compris AzCopy pour déplacer des fichiers sur le réseau dans le Stockage Azure, Azure ExpressRoute pour déplacer des données en bloc sur une connexion réseau privée et Azure Data Box pour déplacer des fichiers vers un appareil de stockage physique qui est ensuite expédié vers un centre de données Azure en vue du chargement. Pour plus d'informations, consultez Transfert de données.
Extraction directe et chargement sur le réseau : l’environnement Azure cible envoie une requête d’extraction de données, normalement via une commande SQL, au système Netezza hérité pour extraire les données. Les résultats sont envoyés sur le réseau et chargés directement dans Azure Synapse, sans avoir à « déposer » les données dans des fichiers intermédiaires. Le facteur de limitation de ce scénario est normalement la bande passante de la connexion réseau entre la base de données Netezza et l’environnement Azure. Pour les volumes de données très importants, cette approche n’est pas toujours pratique.
Il existe également une approche hybride qui combine les deux méthodes. Par exemple, vous pouvez utiliser l’approche d’extraction de réseau directe pour des tables de dimension plus petites et des exemples de tables de faits plus grandes pour fournir rapidement un environnement de test dans Azure Synapse. Pour les grandes tables de faits historiques, vous pouvez utiliser l’approche d’extraction et de transfert de fichiers avec Azure Data Box.
Orchestrer à partir de Netezza ou d’Azure ?
L’approche recommandée pour le déplacement vers Azure Synapse consiste à orchestrer l’extraction et le chargement des données à partir de l’environnement Azure en utilisant Azure Synapse Pipelines ou Azure Data Factory, ainsi que des utilitaires associés comme PolyBase ou COPY INTO. Le chargement des données est alors optimal. Cette approche tire parti des fonctionnalités Azure et fournit une méthode simple pour créer des pipelines de chargement de données réutilisables.
D’autres avantages de cette approche incluent une réduction de l’impact sur le système Netezza pendant le processus de chargement des données, car le processus de gestion et de chargement s’exécute dans Azure, et la possibilité d’automatiser le processus avec des pipelines de chargement de données basés sur des métadonnées.
Quels outils utiliser ?
La tâche de transformation et de déplacement des données est la fonction de base de tous les produits ETL. Si un tel produit est déjà utilisé dans l’environnement Netezza existant, l’utilisation de l’outil ETL existant peut simplifier la migration des données de Netezza vers Azure Synapse. Cette approche suppose que l’outil ETL prend en charge Azure Synapse comme environnement cible. Pour plus d’informations sur les outils qui prennent en charge Azure Synapse, consultez Partenaires d’intégration de données.
Si vous utilisez un outil ETL, envisagez d’exécuter cet outil dans l’environnement Azure pour tirer parti des performances, de la scalabilité et du coût du cloud Azure, et libérer des ressources dans le centre de données Netezza. Un autre avantage est la réduction du déplacement des données entre les environnements cloud et locaux.
Résumé
Pour résumer, nos recommandations relatives à la migration des données et des processus ETL associés de Netezza vers Azure Synapse sont les suivantes :
Planifiez la migration pour bien la réussir.
Faites un inventaire détaillé des données et des processus à migrer le plus tôt possible.
Appuyez-vous sur les fichiers journaux et métadonnées système pour avoir une compréhension fine de l’utilisation des données et des processus. Ne vous fiez pas entièrement à la documentation, qui peut parfois être obsolète.
Déterminez avec précision les volumes de données à migrer, et la bande passante réseau entre le centre de données local et les environnements cloud Azure.
Tirez parti des fonctionnalités Azure « intégrées » standard pour réduire la charge de travail de migration.
Identifiez et comprenez les outils les plus efficaces pour l’extraction et le chargement des données dans les environnements Netezza et Azure. Utilisez les outils appropriés dans chaque phase du processus.
Utilisez des services Azure, comme Azure Synapse Pipelines ou Azure Data Factory, pour orchestrer et automatiser le processus de migration tout en réduisant l’impact sur le système Netezza.
Étapes suivantes
Pour en savoir plus sur la sécurité, l’accès et les opérations, consultez l’article suivant de cette série : Sécurité, accès et opérations pour les migrations Netezza.