Présentation des utilitaires Microsoft Spark
Microsoft Spark Utilities (MSSparkUtils) est un package intégré qui vous permet d’effectuer aisément des tâches courantes. Vous pouvez utiliser MSSparkUtils pour travailler efficacement avec des systèmes de fichiers, pour récupérer des variables d’environnement, chaîner des notebooks et utiliser des secrets. MSSparkUtils est disponible dans les notebooks PySpark (Python), Scala, .NET Spark (C#) et R (Preview), et dans les pipelines Synapse.
Conditions préalables
Configurer l’accès à Azure Data Lake Storage Gen2
Les notebooks Synapse utilisent le pass-through Microsoft Entra pour accéder aux comptes ADLS Gen2. Vous devez être un Contributeur aux données Blob de stockage pour accéder au compte (ou au dossier) ADLS Gen2.
Les pipelines Synapse utilisent l’identité MSI (Managed Service Identity) de l’espace de travail pour accéder aux comptes de stockage. Pour utiliser MSSparkUtils dans vos activités de pipeline, l'identité de votre espace de travail doit être un Contributeur aux données Blob de stockage pour accéder au compte (ou au dossier) ADLS Gen2.
Procédez comme suit pour vous assurer que votre compte Microsoft Entra et votre espace de travail MSI ont accès au compte ADLS Gen2 :
Ouvrez le portail Azure et le compte de stockage auquel vous souhaitez accéder. Vous pouvez accéder au conteneur spécifique auquel vous souhaitez accéder.
Dans le volet de gauche, sélectionnez Contrôle d’accès (IAM) .
Sélectionnez Ajouter>Ajouter une attribution de rôle pour ouvrir la page Ajouter une attribution de rôle.
Attribuez le rôle suivant. Pour connaître les étapes détaillées, consultez Attribuer des rôles Azure à l’aide du portail Azure.
Paramètre Valeur Role Contributeur aux données Blob du stockage Attribuer l’accès à USER et MANAGEDIDENTITY Membres votre compte Microsoft Entra et votre identité d’espace de travail Remarque
Le nom de l’identité managée correspond également au nom de l’espace de travail.
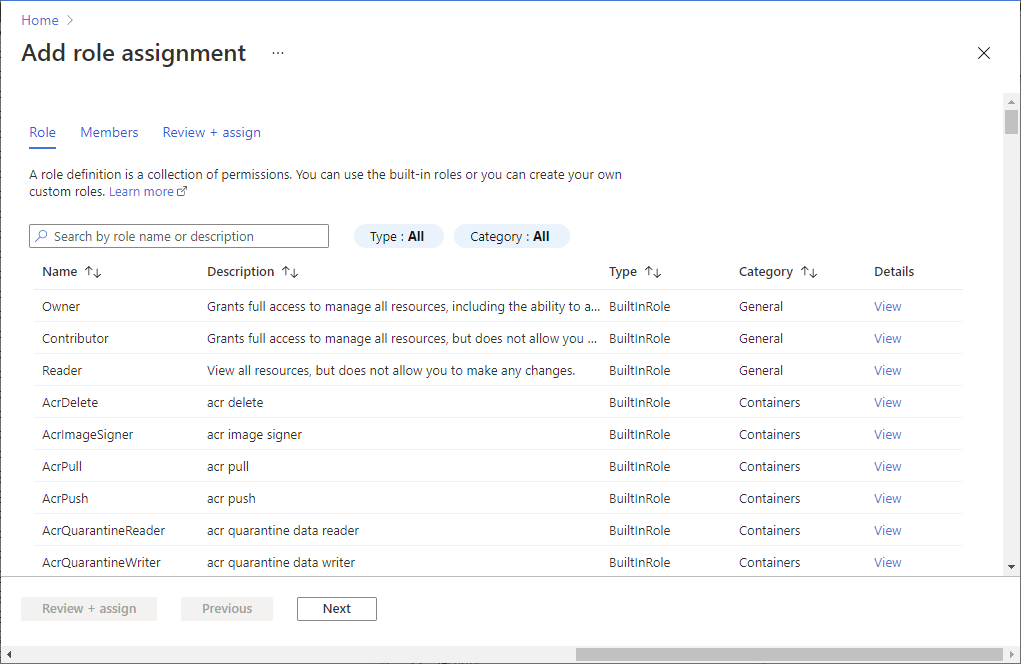
Sélectionnez Enregistrer.
Vous pouvez accéder aux données sur ADLS Gen2 à l’aide de Synapse Spark via l’URL suivante :
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Configurer l’accès à Stockage Blob Azure
Synapse utilise la signature d’accès partagé (SAS) pour accéder à Stockage Blob Azure. Pour éviter d’exposer des clés SAP dans le code, nous vous recommandons de créer un nouveau service lié dans l’espace de travail Synapse sur le compte Stockage Blob Azure auquel vous souhaitez accéder.
Procédez comme suit pour ajouter un nouveau service lié pour un compte Stockage Blob Azure :
- Ouvrez Azure Synapse Studio.
- Sélectionnez Gérer dans le volet gauche, puis Services liés sous Connexions externes.
- Recherchez Stockage Blob Azure dans le panneau Nouveau service lié à droite.
- Sélectionnez Continuer.
- Sélectionnez le compte Stockage Blob Azure pour y accéder et configurer le nom du service lié. Suggérer l’utilisation d’une clé de compte pour la méthode d’authentification.
- Sélectionnez Tester la connexion pour vérifier que les paramètres sont corrects.
- Sélectionnez Créer, puis sur Publier tout pour enregistrer vos modifications.
Vous pouvez accéder aux données sur Stockage Blob Azure à l’aide de Synapse Spark via l’URL suivante :
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Voici un exemple de code :
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Configurer l’accès à Azure Key Vault
Vous pouvez ajouter un compte Azure Key Vault en tant que service lié pour gérer vos informations d’identification dans Synapse. Pour ajouter un compte Azure Key Vault en tant que service lié Synapse, procédez comme suit :
Ouvrez Azure Synapse Studio.
Sélectionnez Gérer dans le volet gauche, puis Services liés sous Connexions externes.
Recherchez Azure Key Vault dans le panneau Nouveau service lié à droite.
Sélectionnez le compte Azure Key Vault pour y accéder et configurer le nom du service lié.
Sélectionnez Tester la connexion pour vérifier que les paramètres sont corrects.
Sélectionnez Créer, puis sur Publier tout pour enregistrer vos modifications.
Les notebooks Synapse utilisent le pass-through Microsoft Entra pour accéder à Azure Key Vault. Les pipelines Synapse utilisent l’identité de l’espace de travail (MSI) pour accéder à Azure Key Vault. Pour vous assurer que votre code fonctionne à la fois dans le notebook et dans le pipeline Synapse, nous vous recommandons d’accorder une autorisation d’accès secret à la fois à votre compte Microsoft Entra et à votre identité d’espace de travail.
Procédez comme suit pour accorder un accès secret à votre identité d’espace de travail :
- Ouvrez le portail Azure et le compte Azure Key Vault auquel vous souhaitez accéder.
- Dans le panneau gauche, sélectionnez Stratégies d’accès.
- Sélectionnez Ajouter une stratégie d’accès :
- Choisissez Gestion des clés, des secrets et des certificats en tant que modèle de configuration.
- Sélectionnez votre compte Microsoft Entra et votre identité d’espace de travail (identique au nom de votre espace de travail) dans le principal sélectionné ou assurez-vous qu’il est déjà attribué.
- Choisissez Sélectionner et Ajouter.
- Cliquez sur le bouton Enregistrer pour valider les modifications.
Utilitaires du système de fichiers
mssparkutils.fs fournit des utilitaires pour travailler avec différents systèmes de fichiers, notamment Azure Data Lake Storage Gen2 (ADLS Gen2) et Stockage Blob Azure. Veillez à configurer l’accès à Azure Data Lake Storage Gen2 et Stockage Blob Azure de manière appropriée.
Exécutez les commandes suivantes pour obtenir une vue d’ensemble des méthodes disponibles :
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Retourne comme résultat :
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Énumérer des fichiers
Répertorie le contenu d’un répertoire.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Affichez les propriétés de fichier
Retourne les propriétés du fichier, notamment le nom du fichier, son chemin d’accès, sa taille, l’heure de sa modification, s’il s’agit d’un répertoire et s’il s’agit d’un fichier.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Créer un répertoire
Crée le répertoire donné s’il n’existe pas, ainsi que les répertoires parents nécessaires.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Copier le fichier
Copie un fichier ou un répertoire. Prend en charge la copie sur plusieurs systèmes de fichiers.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Fichier de copie performant
Cette méthode fournit un moyen plus rapide de copier ou de déplacer des fichiers, en particulier de gros volumes de données.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Remarque
La méthode prend uniquement en charge le runtime Azure Synapse pour Apache Spark 3.3 et Le runtime Azure Synapse pour Apache Spark 3.4.
Afficher un aperçu du contenu du fichier
Renvoie jusqu’aux premiers octets « maxBytes » du fichier donné sous la forme d’une chaîne encodée au format UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Déplacer le fichier
Déplace un fichier ou un répertoire. Prend en charge le déplacement sur plusieurs systèmes de fichiers.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Écrire dans un fichier
Écrit la chaîne donnée dans un fichier encodé au format UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Ajouter du contenu à un fichier
Ajoute la chaîne donnée à un fichier, encodé au format UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Remarque
mssparkutils.fs.append()etmssparkutils.fs.put()ne prennent pas en charge l’écriture simultanée dans le même fichier en raison d’un manque de garanties d’atomicité.- Lorsque vous utilisez l’API
mssparkutils.fs.appenddans uneforboucle pour écrire dans le même fichier, nous vous recommandons d’ajouter unesleepinstruction autour de 0,5s~1 entre les écritures périodiques. Cela est dû au fait que l’opération interneflushde l’APImssparkutils.fs.appendest asynchrone. Par conséquent, un court délai permet de garantir l’intégrité des données.
Supprimer un fichier ou un répertoire
Supprime un fichier ou un répertoire.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Utilitaires de notebook
Non pris en charge.
Vous pouvez utiliser les utilitaires notebook MSSparkUtils pour exécuter un notebook ou quitter un notebook avec une valeur. Exécutez la commande suivante pour obtenir une vue d’ensemble des méthodes disponibles :
mssparkutils.notebook.help()
Obtenir les résultats :
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Remarque
Les utilitaires de notebook ne s’appliquent pas aux définitions de travail Apache Spark (SJD).
Référencer un notebook
Référence un notebook et renvoie sa valeur de sortie. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline. Le notebook référencé s’exécutera sur le pool Spark duquel le notebook appelle cette fonction.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Par exemple :
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Une fois l’exécution terminée, vous verrez un lien d’instantané nommé « Afficher l’exécution du notebook : Nom du notebook » affiché dans la sortie de la cellule, vous pouvez cliquer sur le lien pour afficher l’instantané de cette exécution spécifique.

Exécution de référence de plusieurs notebooks en parallèle
La méthode mssparkutils.notebook.runMultiple() vous permet d’exécuter plusieurs notebooks en parallèle ou avec une structure topologique prédéfinie. L’API utilise un mécanisme d’implémentation multithread au sein d’une session Spark, ce qui signifie que les ressources de calcul sont partagées par les exécutions du notebook de référence.
Avec mssparkutils.notebook.runMultiple(), vous pouvez :
Exécutez plusieurs notebooks simultanément, sans attendre que chacun d’eux se termine.
Spécifiez les dépendances et l’ordre d’exécution de vos notebooks à l’aide d’un format JSON simple.
Optimisez l’utilisation des ressources de calcul Spark et réduisez le coût de vos projets Synapse.
Affichez les instantanés de chaque enregistrement d’exécution de notebook dans la sortie, et déboguez/surveillez vos tâches de notebook de manière pratique.
Obtenez la valeur de sortie de chaque activité exécutive et utilisez-les dans les tâches en aval.
Vous pouvez également essayer d’exécuter mssparkutils.notebook.help("runMultiple") pour rechercher l’exemple et l’utilisation détaillée.
Voici un exemple simple d’exécution d’une liste de notebooks en parallèle à l’aide de cette méthode :
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Le résultat d’exécution du notebook racine est le suivant :

Voici un exemple d’exécution de notebooks avec une structure topologique à l’aide de mssparkutils.notebook.runMultiple(). Utilisez cette méthode pour orchestrer facilement les notebooks via une expérience de code.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Remarque
- La méthode prend uniquement en charge le runtime Azure Synapse pour Apache Spark 3.3 et Le runtime Azure Synapse pour Apache Spark 3.4.
- Le degré de parallélisme de l’exécution de plusieurs notebooks est limité au nombre total de ressources de calcul disponibles d’une session Spark.
Quitter un notebook
Quitte un notebook avec une valeur. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline.
Lorsque vous appelez une fonction exit() à partir d’un notebook de manière interactive, Azure Synapse lève une exception, ignore l’exécution des cellules de la sous-séquence et maintient la session Spark active.
Lorsque vous orchestrez un notebook qui appelle une fonciton
exit()dans un pipeline Synapse, Azure Synapse renvoie une valeur de sortie, termine l’exécution du pipeline et arrête la session Spark.Lorsque vous appelez une fonction
exit()dans un notebook référencé, Azure Synapse arrête l’exécution supplémentaire dans le notebook référencé et continue à exécuter les cellules suivantes du notebook qui appellent la fonctionrun(). Par exemple : Notebook1 possède trois cellules et appelle une fonctionexit()dans la deuxième cellule. Notebook2 possède cinq cellules et appellerun(notebook1)dans la troisième cellule. Lorsque vous exécutez Notebook2, Notebook1 est arrêté à la deuxième cellule lorsque vous atteignez la fonctionexit(). Notebook2 continue à exécuter sa quatrième cellule et sa cinquième cellule.
mssparkutils.notebook.exit("value string")
Par exemple :
Le notebook Sample1 se trouve sous folder/ avec les deux cellules :
- La cellule 1 définit un paramètre d’entrée dont la valeur par défaut est définie sur 10.
- La cellule 2 quitte le notebook avec l'entrée comme valeur de sortie.
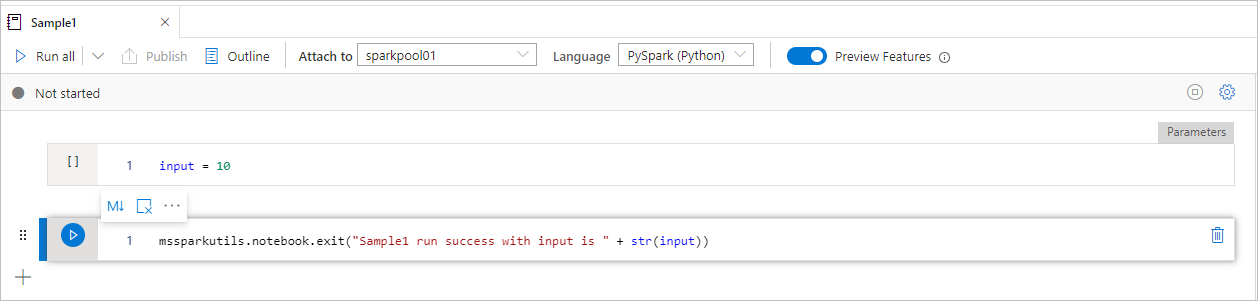
Vous pouvez exécuter Sample1 dans un autre bloc-notes avec les valeurs par défaut :
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Retourne comme résultat :
Sample1 run success with input is 10
Vous pouvez exécuter Sample1 dans un autre notebook et définir la valeur d’entrée sur 20 :
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Retourne comme résultat :
Sample1 run success with input is 20
Vous pouvez utiliser les utilitaires notebook MSSparkUtils pour exécuter un notebook ou quitter un notebook avec une valeur. Exécutez la commande suivante pour obtenir une vue d’ensemble des méthodes disponibles :
mssparkutils.notebook.help()
Obtenir les résultats :
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Référencer un notebook
Référence un notebook et renvoie sa valeur de sortie. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline. Le notebook référencé s’exécutera sur le pool Spark duquel le notebook appelle cette fonction.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Par exemple :
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Une fois l’exécution terminée, vous verrez un lien d’instantané nommé « Afficher l’exécution du notebook : Nom du notebook » affiché dans la sortie de la cellule, vous pouvez cliquer sur le lien pour afficher l’instantané de cette exécution spécifique.
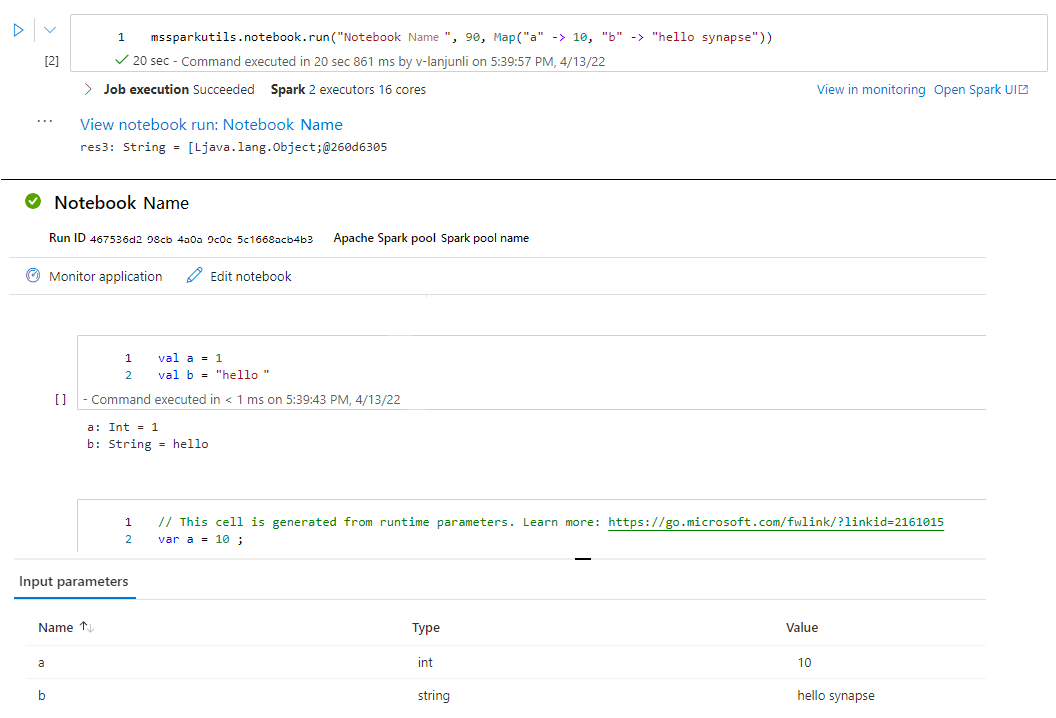
Quitter un notebook
Quitte un notebook avec une valeur. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline.
Lorsque vous appelez une fonction
exit()de notebook de manière interactive, Azure Synapse lève une exception, ignore l’exécution des cellules de la sous-séquence et maintient la session Spark active.Lorsque vous orchestrez un notebook qui appelle une fonciton
exit()dans un pipeline Synapse, Azure Synapse renvoie une valeur de sortie, termine l’exécution du pipeline et arrête la session Spark.Lorsque vous appelez une fonction
exit()dans un notebook référencé, Azure Synapse arrête l’exécution supplémentaire dans le notebook référencé et continue à exécuter les cellules suivantes du notebook qui appellent la fonctionrun(). Par exemple : Notebook1 possède trois cellules et appelle une fonctionexit()dans la deuxième cellule. Notebook2 possède cinq cellules et appellerun(notebook1)dans la troisième cellule. Lorsque vous exécutez Notebook2, Notebook1 est arrêté à la deuxième cellule lorsque vous atteignez la fonctionexit(). Notebook2 continue à exécuter sa quatrième cellule et sa cinquième cellule.
mssparkutils.notebook.exit("value string")
Par exemple :
Le notebook Sample1 est situé sous mssparkutils/dossier/ avec les deux cellules suivantes :
- La cellule 1 définit un paramètre d’entrée dont la valeur par défaut est définie sur 10.
- La cellule 2 quitte le notebook avec l'entrée comme valeur de sortie.
Vous pouvez exécuter Sample1 dans un autre bloc-notes avec les valeurs par défaut :
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Retourne comme résultat :
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Vous pouvez exécuter Sample1 dans un autre notebook et définir la valeur d’entrée sur 20 :
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Retourne comme résultat :
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Vous pouvez utiliser les utilitaires notebook MSSparkUtils pour exécuter un notebook ou quitter un notebook avec une valeur. Exécutez la commande suivante pour obtenir une vue d’ensemble des méthodes disponibles :
mssparkutils.notebook.help()
Obtenir les résultats :
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Référencer un notebook
Référence un notebook et renvoie sa valeur de sortie. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline. Le notebook référencé s’exécutera sur le pool Spark duquel le notebook appelle cette fonction.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Par exemple :
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Une fois l’exécution terminée, vous verrez un lien d’instantané nommé « Afficher l’exécution du notebook : Nom du notebook » affiché dans la sortie de la cellule, vous pouvez cliquer sur le lien pour afficher l’instantané de cette exécution spécifique.
Quitter un notebook
Quitte un notebook avec une valeur. Vous pouvez exécuter des appels de fonction d’imbrication dans un notebook de manière interactive ou dans un pipeline.
Lorsque vous appelez une fonction
exit()de notebook de manière interactive, Azure Synapse lève une exception, ignore l’exécution des cellules de la sous-séquence et maintient la session Spark active.Lorsque vous orchestrez un notebook qui appelle une fonciton
exit()dans un pipeline Synapse, Azure Synapse renvoie une valeur de sortie, termine l’exécution du pipeline et arrête la session Spark.Lorsque vous appelez une fonction
exit()dans un notebook référencé, Azure Synapse arrête l’exécution supplémentaire dans le notebook référencé et continue à exécuter les cellules suivantes du notebook qui appellent la fonctionrun(). Par exemple : Notebook1 possède trois cellules et appelle une fonctionexit()dans la deuxième cellule. Notebook2 possède cinq cellules et appellerun(notebook1)dans la troisième cellule. Lorsque vous exécutez Notebook2, Notebook1 est arrêté à la deuxième cellule lorsque vous atteignez la fonctionexit(). Notebook2 continue à exécuter sa quatrième cellule et sa cinquième cellule.
mssparkutils.notebook.exit("value string")
Par exemple :
Le notebook Sample1 se trouve sous folder/ avec les deux cellules :
- La cellule 1 définit un paramètre d’entrée dont la valeur par défaut est définie sur 10.
- La cellule 2 quitte le notebook avec l'entrée comme valeur de sortie.
Vous pouvez exécuter Sample1 dans un autre bloc-notes avec les valeurs par défaut :
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Retourne comme résultat :
Sample1 run success with input is 10
Vous pouvez exécuter Sample1 dans un autre notebook et définir la valeur d’entrée sur 20 :
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Retourne comme résultat :
Sample1 run success with input is 20
Utilitaires d’informations d’identification
Vous pouvez utiliser les utilitaires d’informations d’identification MSSparkUtils pour récupérer les jetons d’accès des services liés et gérer les secrets dans Azure Key Vault.
Exécutez la commande suivante pour obtenir une vue d’ensemble des méthodes disponibles :
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Vous obtenez le résultat suivant :
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Notes
Actuellement, getSecretWithLS(linkedService, secret) n’est pas pris en charge dans C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Obtenir un jeton
Retourne le jeton Microsoft Entra pour un public donné, un nom (facultatif). Le tableau ci-dessous répertorie tous les types d’audience disponibles :
| Type d’audience | Littéral de chaîne à utiliser dans l’appel d’API |
|---|---|
| Stockage Azure | Storage |
| Azure Key Vault | Vault |
| Gestion d’Azure | AzureManagement |
| Azure SQL Data Warehouse (dédié et sans serveur) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Explorateur de données Azure | AzureDataExplorer |
| Azure Database pour MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database pour PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Valider un jeton
Renvoie la valeur true si le jeton n’a pas expiré.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Obtenir la chaîne de connexion ou les informations d’identification du service lié
Renvoie la chaîne de connexion ou les informations d’identification du service lié.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Obtenir le secret à l’aide de l’identité de l’espace de travail
Renvoie le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide de l’identité de l’espace de travail. Veillez à configurer l’accès à Azure Key Vault de manière appropriée.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Obtenir le secret à l’aide des informations d’identification de l’utilisateur
Renvoie le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide des informations d’identification de l’utilisateur.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Placer le secret à l’aide de l’identité de l’espace de travail
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide de l’identité de l’espace de travail. Veillez à configurer l’accès à Azure Key Vault de manière appropriée.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Placer le secret à l’aide de l’identité de l’espace de travail
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide de l’identité de l’espace de travail. Veillez à configurer l’accès à Azure Key Vault de manière appropriée.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Placer le secret à l’aide de l’identité de l’espace de travail
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide de l’identité de l’espace de travail. Veillez à configurer l’accès à Azure Key Vault de manière appropriée.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Placer le secret à l’aide des informations d’identification de l’utilisateur
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide des informations d’identification de l’utilisateur.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Placer le secret à l’aide des informations d’identification de l’utilisateur
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide des informations d’identification de l’utilisateur.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Placer le secret à l’aide des informations d’identification de l’utilisateur
Place le secret Azure Key Vault pour un nom Azure Key Vault donné, un nom de secret et un nom de service lié à l’aide des informations d’identification de l’utilisateur.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Utilitaires d’environnement
Exécutez la commande suivante pour obtenir une vue d’ensemble des méthodes disponibles :
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Vous obtenez le résultat suivant :
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Obtient le nom d’utilisateur
Renvoie le nom de l’utilisateur actuel.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Obtenir l’identifiant utilisateur
Renvoie l’identifiant utilisateur actuel.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Obtenir l’ID de tâche
Renvoie l’ID de tâche.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Obtenir le nom de l’espace de travail
Renvoie le nom de l’espace de travail.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Obtenir le nom du pool
Renvoie le nom du pool Spark.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Obtenir l’ID de cluster
Renvoie l’ID de cluster actuel.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Contexte d’exécution
Les utilitaires d’exécution Mssparkutils ont exposé trois propriétés d’exécution. Vous pouvez utiliser le contexte d’exécution mssparkutils pour récupérer les propriétés répertoriées comme ci-dessous :
- Notebookname : nom du notebook actuel, renvoie toujours la valeur en mode interactif et en mode pipeline.
- Pipelinejobid : ID d’exécution du pipeline, renvoie la valeur en mode pipeline et renvoie une chaîne vide en mode interactif.
- Activityrunid : ID d’exécution de l’activité de notebook, renvoie la valeur en mode pipeline et renvoie une chaîne vide en mode interactif.
Actuellement, le contexte d’exécution prend en charge Python et Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Gestion des sessions
Arrêter une session interactive
Au lieu de cliquer manuellement sur le bouton Arrêter, il est parfois plus pratique d’arrêter une session interactive en appelant une API dans le code. Dans de tels cas, nous fournissons une API mssparkutils.session.stop() disponible pour Scala et Python qui prend en charge l’arrêt de la session interactive dans le code.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() L’API arrête la session interactive en cours de manière asynchrone en arrière-plan. Elle arrête la session Spark et libère les ressources occupées par la session afin qu’elles soient accessibles à d’autres sessions du même pool.
Notes
Nous vous déconseillons d’appeler des API intégrées au langage comme sys.exit dans Scala ou sys.exit() dans Python dans votre code, car ces API tuent simplement le processus de l’interpréteur, laissant la session Spark active et les ressources non libérées.
Dépendances de package
Si vous souhaitez développer des notebooks ou des travaux localement et que vous devez référencer les packages appropriés pour les indicateurs de compilation/IDE, vous pouvez utiliser les packages suivants.