Haute disponibilité de la mise à l'échelle de SAP HANA avec Azure NetApp Files sur SUSE Enterprise Linux
Cet article explique comment configurer la réplication du système SAP HANA dans le cadre d’un déploiement de mise à l’échelle lorsque les systèmes de fichiers HANA sont montés via NFS avec Azure NetApp Files. Les exemples de configuration et les commandes d’installation utilisent le numéro d’instance 03 et l’ID système HANA HN1. La réplication SAP HANA se compose d’un nœud principal et d’au moins un nœud secondaire.
Lorsque les étapes de ce document sont marquées des préfixes suivants, cela signifie :
- [A] : l’étape s’applique à tous les nœuds.
- [1] : l’étape ne s’applique qu’à node1.
- [2] : l’étape ne s’applique qu’à node2.
Commencez par lire les notes et publications SAP suivantes :
- La note SAP 1928533 comporte les points suivants :
- La liste des tailles de machines virtuelles Azure prises en charge pour le déploiement de logiciels SAP.
- informations importantes sur la capacité par taille de machine virtuelle (VM) d’Azure
- Les combinaisons prises en charge de logiciels SAP, de systèmes d’exploitation et de bases de données.
- La version du noyau SAP requise pour Windows et Linux sur Azure.
- La note SAP 2015553 répertorie les conditions préalables au déploiement de logiciels SAP pris en charge par SAP sur Azure.
- La note SAP 405827 répertorie le système de fichier recommandé pour l’environnement HANA.
- La note SAP 2684254 a recommandé les paramètres de système d’exploitation pour SUSE Linux Enterprise Server (SLES) 15/SLES pour les applications SAP 15.
- La note SAP 1944799 contient des instructions SAP HANA pour l’installation du système d’exploitation SLES.
- La note SAP 2178632 contient des informations détaillées sur toutes les métriques de surveillance rapportées pour SAP sur Azure.
- La note SAP 2191498 contient la version requise de l’agent hôte SAP pour Linux sur Azure.
- La note SAP 2243692 contient des informations sur les licences SAP sur Linux dans Azure.
- La note SAP 1999351 contient des informations supplémentaires sur le dépannage de l’extension Azure Enhanced Monitoring pour SAP.
- La note SAP 1900823 contient des informations sur les exigences de stockage SAP HANA.
- Les guides de bonnes pratiques SUSE SAP (haute disponibilité) contiennent toutes les informations requises pour configurer la haute disponibilité NetWeaver et la réplication du système SAP HANA localement (à utiliser comme base de référence générale). Ils fournissent des informations beaucoup plus détaillées.
- Le wiki de la communauté SAP contient toutes les notes SAP nécessaires pour Linux.
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux
- Déploiement de machines virtuelles Azure pour SAP sur Linux
- Déploiement SGBD de machines virtuelles Azure pour SAP sur Linux
- Documentation SLES générale :
- Configuration d’un cluster SAP HANA
- Notes de publication de l’extension SLES High Availability 15 SP3
- Guide de renforcement de la sécurité des systèmes d’exploitation pour SAP HANA pour SUSE Linux Enterprise Server 15
- Guide SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Automation SAP de SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Analyse SAP de SUSE Linux Enterprise Server for SAP Applications 15 SP3
- Documentation SLES spécifique à Azure :
- Applications SAP NetApp su Microsoft Azure avec Azure NetApp Files
- Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux
Remarque
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Vue d’ensemble
Traditionnellement, dans un environnement de scale-up, tous les systèmes de fichiers pour SAP HANA sont montés à partir du stockage local. La configuration de la (HA) pour la réplication du système SAP HANA sur SUSE Enterprise Linux est publiée dans Configurer la réplication du système SAP HANA sur SLES.
Pour obtenir la haute disponibilité SAP HANA d’un système de scale-up sur des partages NFS Azure NetApp Files, nous avons besoin d’une configuration de ressource supplémentaire dans le cluster. Cette configuration est nécessaire afin que les ressources HANA puissent récupérer lorsqu’un nœud perd l’accès aux partages NFS sur Azure NetApp Files.
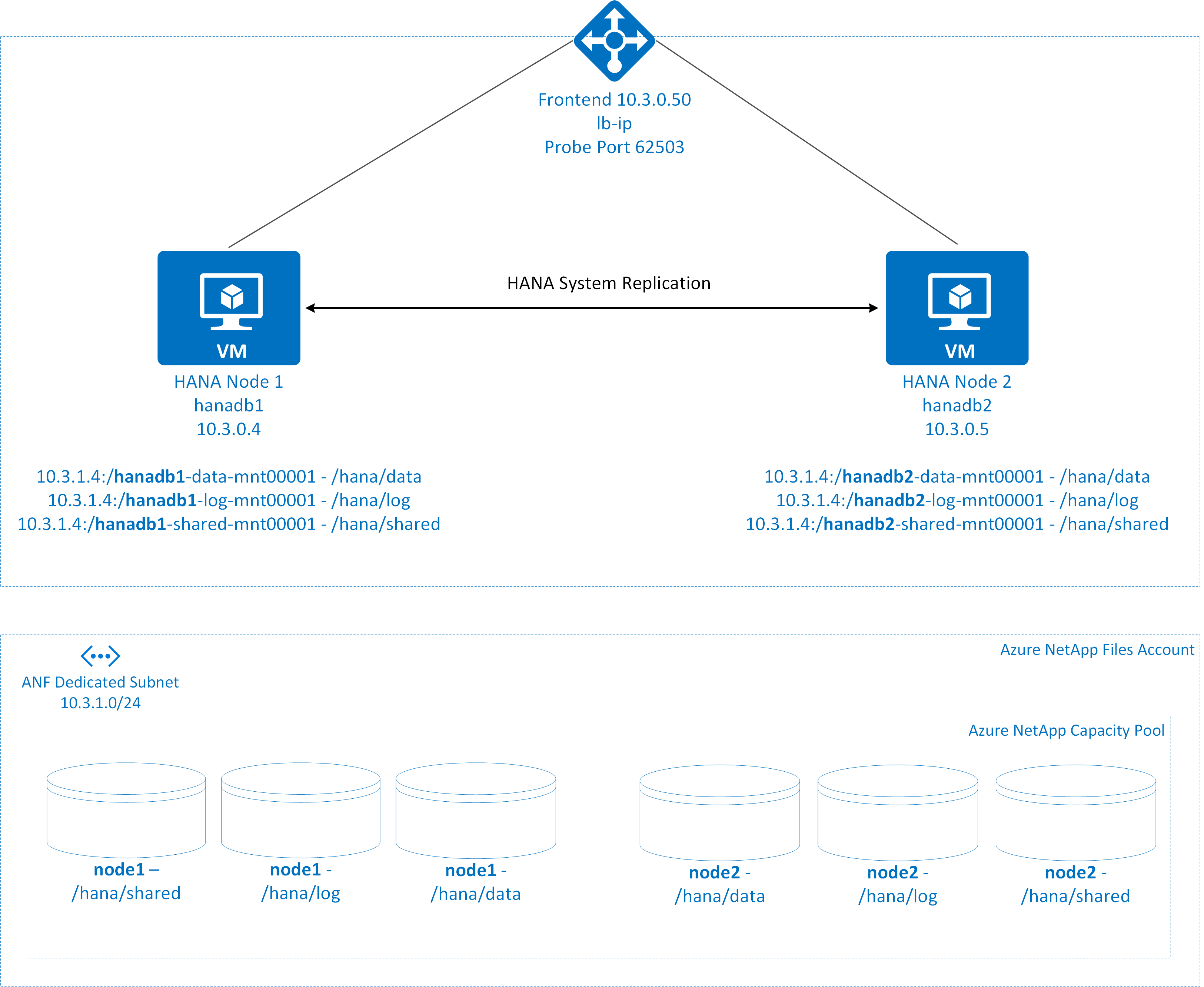
Les systèmes de fichiers SAP HANA sont montés sur des partages NFS à l’aide d’Azure NetApp Files sur chaque nœud. Les systèmes de fichiers /hana/data, /hana/log et /hana/shared sont uniques à chaque nœud.
Monté sur node1 (hanadb1) :
- 10.3.1.4:/hanadb1-data-mnt00001 sur /hana/data
- 10.3.1.4:/hanadb1-log-mnt00001 sur /hana/log
- 10.3.1.4:/hanadb1-shared-mnt00001 sur /hana/shared
Monté sur node2 (hanadb2) :
- 10.3.1.4:/hanadb2-data-mnt00001 sur /hana/data
- 10.3.1.4:/hanadb2-log-mnt00001 sur /hana/log
- 10.3.1.4:/hanadb2-shared-mnt0001 sur /hana/shared
Remarque
Les systèmes de fichiers /hana/shared, /hana/data et /hana/log ne sont pas partagés entre les deux nœuds. Chaque nœud de cluster a ses propres systèmes de fichiers distincts.
La configuration de la réplication du système HA de SAP HANA utilise un nom d’hôte virtuel dédié et des adresses IP virtuelles. Sur Azure, un équilibreur de charge est nécessaire pour utiliser une adresse IP virtuelle. La configuration présentée montre un équilibreur de charge avec :
- Configuration frontale adresse IP : 10.3.0.50 pour hn1-db
- Port de la sonde : 62503
Configurer l’infrastructure Azure NetApp Files
Avant de poursuivre la configuration de l’infrastructure Azure NetApp Files, familiarisez-vous avec la documentation Azure NetApp Files.
Azure NetApp Files est disponible dans plusieurs régions Azure. Vérifiez si la région Azure que vous avez sélectionnée est compatible avec Azure NetApp Files.
Pour des informations sur la disponibilité d’Azure NetApp Files par région Azure, consultez Disponibilité d’Azure NetApp Files par région Azure.
Considérations importantes
Lorsque vous créez votre Azure NetApp Files pour les systèmes de mise à l'échelle SAP HANA, tenez compte des considérations importantes documentées dans les volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA.
Dimensionnement de la base de données HANA sur Azure NetApp Files
Le débit d’un volume NetApp Azure Files est une fonction de la taille de volume et du niveau de service, comme décrit dans Niveau de service pour Azure NetApp Files.
Lorsque vous concevez l’infrastructure pour SAP HANA sur Azure avec Azure NetApp Files, tenez compte des recommandations contenues dans les volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA.
La configuration de cet article est présentée avec des volumes Azure NetApp Files simples.
Important
Pour les systèmes de production, pour lesquels les performances sont essentielles, nous vous recommandons d’évaluer et d’envisager d’utiliser le groupe de volumes d’applications Azure NetApp Files pour SAP HANA.
Toutes les commandes permettant de monter /hana/shared dans cet article sont présentées pour les volumes /hana/shared NFSv4.1. Si vous avez déployé les volumes /hana/shared en tant que volumes NFSv3, n’oubliez pas d’ajuster les commandes de montage pour /hana/shared en conséquence.
Déployer des ressources Azure NetApp Files
Les instructions suivantes supposent que vous avez déjà déployé votre réseau virtuel Azure. Les ressources Azure NetApp Files et les machines virtuelles, où les ressources Azure NetApp Files seront montées, doivent être déployées dans le même réseau virtuel Azure ou dans des réseaux virtuels Azure appairés.
Créez un compte NetApp dans la région Azure sélectionnée en suivant les instructions de la page Création d’un compte NetApp.
Configurez un pool de capacité Azure NetApp Files en suivant les instructions de la page Configuration d’un pool de capacité Azure NetApp Files.
L’architecture HANA présentée dans cet article utilise un seul pool de capacité Azure NetApp Files au niveau de service Ultra. Pour les charges de travail HANA sur Azure, nous vous recommandons d’utiliser un niveau de service Ultra ou Premium d’Azure NetApp Files.
Déléguez un sous-réseau à Azure NetApp Files, comme décrit dans les instructions de la page Déléguer un sous-réseau à Azure NetApp Files.
Déployez des volumes Azure NetApp Files en suivant les instructions de la page Créer un volume NFS pour Azure NetApp Files.
Lorsque vous déployez les volumes, veillez à sélectionner la version NFSv4.1. Déployez les volumes dans le sous-réseau Azure NetApp Files désigné. Les adresses IP des volumes Azure NetApp Files sont attribuées automatiquement.
Les ressources Azure NetApp Files et les machines virtuelles Azure doivent être dans le même réseau virtuel Azure ou dans des réseaux virtuels Azure appairés. Par exemple, hanadb1-data-mnt00001, hanadb1-log-mnt00001 et ainsi de suite sont les noms de volume, et nfs://10.3.1.4/hanadb1-data-mnt00001, nfs://10.3.1.4/hanadb1-log-mnt00001 et ainsi de suite sont les chemin d’accès de fichiers pour les volumes Azure NetApp Files.
Sur hanadb1 :
- Volume hanadb1-data-mnt00001 (nfs://10.3.1.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.3.1.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.3.1.4:/hanadb1-shared-mnt00001)
Sur hanadb2 :
- Volume hanadb2-data-mnt00001 (nfs://10.3.1.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.3.1.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.3.1.4:/hanadb2-shared-mnt00001)
Préparer l’infrastructure
L’agent de ressource pour SAP HANA est inclus dans SUSE Linux Enterprise Server for SAP Applications. Une image pour SUSE Linux Enterprise Server for SAP Applications 12 ou 15 est disponible sur la Place de marché Azure. Vous pouvez utiliser l’image pour déployer de nouvelles machines virtuelles.
Déployer des machines virtuelles Linux manuellement via le portail Azure
Ce document part du principe que vous avez déjà déployé un groupe de ressources, un réseau virtuel Azure et un sous-réseau.
Déployez des machines virtuelles pour SAP HANA. Choisissez une image SLES appropriée et prise en charge pour le système HANA. Vous pouvez déployer une machine virtuelle dans l’une des options de disponibilité : groupe de machines virtuelles identiques, zone de disponibilité ou groupe à haute disponibilité.
Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous envisagez d’utiliser dans votre déploiement. Vous pouvez rechercher les types de machines virtuelles certifiées SAP HANA et leurs versions de système d’exploitation sur la page Plateformes IaaS certifiées SAP HANA. Veillez à consulter les détails du type de machine virtuelle pour obtenir la liste complète des versions de système d’exploitation prises en charge par SAP HANA pour le type de machine virtuelle spécifique.
Configurer Azure Load Balancer
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner l’équilibreur de charge existant dans la section réseau. Suivez les étapes suivantes pour configurer un équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données HANA.
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Pour plus d’informations sur les ports requis pour SAP HANA, consultez le chapitre Connections to Tenant Databases (Connexions aux bases de données locataires) dans le guide SAP HANA Tenant Databases (Bases de données locataires SAP HANA) ou la Note SAP 2388694.
Important
L’adresse IP flottante n’est pas prise en charge sur une configuration IP secondaire de carte réseau dans les scénarios d’équilibrage de charge. Pour plus d’informations, consultez Limitations d’Azure Load Balancer. Si vous avez besoin de plus d'adresses IP pour la machine virtuelle, déployez une deuxième carte réseau.
Lorsque des machines virtuelles sans adresse IP publique sont placées dans le pool back-end d’Azure Load Balancer Standard interne (sans adresse IP publique), il n’y a pas de connectivité Internet sortante à moins qu’une configuration supplémentaire ne soit effectuée pour permettre le routage vers les points de terminaison publics. Pour plus d’informations sur la façon de bénéficier d’une connectivité sortante, consultez Connectivité de point de terminaison public pour les machines virtuelles avec Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
- N’activez pas les timestamps TCP sur les machines virtuelles Azure placées derrière Load Balancer. L’activation des horodateurs TCP provoque l’échec des sondes d’intégrité. Affectez au paramètre
net.ipv4.tcp_timestampsla valeur0. Pour plus d’informations, consultez Sondes d’intégrité Load Balancer et la note SAP 2382421. - Pour empêcher que saptune redéfinisse sur
1la valeurnet.ipv4.tcp_timestampsqui avait été définie manuellement sur0, mettez à jour saptune vers la version 3.1.1 ou ultérieure. Pour plus d’informations, consultez saptune 3.1.1 – Dois-je mettre à jour ?.
Monter le volume Azure NetApp Files
[A] Créez des points de montage pour les volumes de base de données HANA.
sudo mkdir -p /hana/data/HN1/mnt00001 sudo mkdir -p /hana/log/HN1/mnt00001 sudo mkdir -p /hana/shared/HN1[A] Vérifiez le paramètre de domaine NFS. Assurez-vous que le domaine est configuré en tant que domaine Azure NetApp Files par défaut, c’est-à-dire defaultv4iddomain.com, et que le mappage est défini sur nobody.
sudo cat /etc/idmapd.confExemple de sortie :
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportant
Veillez à définir le domaine NFS dans /etc/idmapd.conf sur la machine virtuelle pour qu’il corresponde à la configuration de domaine par défaut sur Azure NetApp Files : defaultv4iddomain.com. En cas d’incompatibilité entre la configuration de domaine sur le client NFS (c’est-à-dire, la machine virtuelle) et le serveur NFS, par exemple la configuration Azure NetApp, les autorisations pour les fichiers sur les volumes Azure NetApp montés sur les machines virtuelles s’affichent en tant que nobody.
[A] Modifier
/etc/fstabsur les deux nœuds pour monter de façon permanente les volumes pertinents pour chaque nœud. L’exemple suivant montre comment monter les volumes de manière permanente.sudo vi /etc/fstabAjoutez les entrées suivantes dans
/etc/fstabsur les deux nœuds.Exemple pour hanadb1 :
10.3.1.4:/hanadb1-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Exemple pour hanadb2 :
10.3.1.4:/hanadb2-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Monter tous les volumes.
sudo mount -aPour les charges de travail qui nécessitent un débit plus élevé, envisagez d’utiliser l’option de montage
nconnect, comme indiqué dans l’article Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA. Vérifiez sinconnectest pris en charge par Azure NetApp Files sur votre version Linux.[A] Vérifiez que tous les volumes HANA sont montés avec la version NFSv4 du protocole NFS.
sudo nfsstat -mVérifiez que l’indicateur
versest défini sur 4.1.Exemple depuis hanadb1 :
/hana/log/HN1/mnt00001 from 10.3.1.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/data/HN1/mnt00001 from 10.3.1.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/shared/HN1 from 10.3.1.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4[A] Vérifiez nfs4_disable_idmapping. Cette option doit avoir la valeur Y. Pour créer la structure de répertoire où se trouve nfs4_disable_idmapping, exécutez la commande de montage. Vous ne serez pas en mesure de créer manuellement le répertoire sous
/sys/modules, car l’accès est réservé pour le noyau/pilotes.#Check nfs4_disable_idmapping sudo cat /sys/module/nfs/parameters/nfs4_disable_idmapping #If you need to set nfs4_disable_idmapping to Y sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping #Make the configuration permanent sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf
Installation de SAP HANA
[A] Configurez la résolution de nom d’hôte pour tous les hôtes.
Vous pouvez utiliser un serveur DNS ou modifier le fichier
/etc/hostssur tous les nœuds. Cet exemple vous explique comment utiliser le fichier/etc/hosts. Remplacez l'adresse IP et le nom d'hôte dans les commandes suivantes :sudo vi /etc/hostsInsérez les lignes suivantes dans le fichier
/etc/hosts. Modifiez l’adresse IP et le nom d’hôte en fonction de votre environnement.10.3.0.4 hanadb1 10.3.0.5 hanadb2[A] Préparez l’OS pour l’exécution de SAP HANA sur Azure NetApp avec NFS, comme indiqué dans la note SAP 3024346 - Paramètres du noyau Linux pour NFS NetApp. Créez le fichier de configuration
/etc/sysctl.d/91-NetApp-HANA.confpour les paramètres de configuration de NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confAjoutez les entrées suivantes au fichier de configuration :
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Créer le fichier de configuration
/etc/sysctl.d/ms-az.confavec d’autres paramètres d’optimisation.sudo vi /etc/sysctl.d/ms-az.confAjoutez les entrées suivantes au fichier de configuration :
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Conseil
Évitez de définir
net.ipv4.ip_local_port_rangeetnet.ipv4.ip_local_reserved_portsde manière explicite dans les fichiers de configuration sysctl, pour permettre à l’agent hôte SAP de gérer les plages de ports. Pour plus d’informations, consultez la note SAP 2382421.[A] Ajustez les paramètres
sunrpc, comme recommandé dans la note SAP 3024346 - Paramètres noyau Linux pour NFS NetApp.sudo vi /etc/modprobe.d/sunrpc.confInsérez la ligne suivante :
options sunrpc tcp_max_slot_table_entries=128[A] Configurer SLES pour HANA.
Configurez SLES comme décrit dans les notes SAP suivantes en fonction de votre version de SLES :
- 2684254 Paramètres de système d’exploitation recommandés pour SLES 15 ou SLES for SAP Applications 15
- 2205917 Paramètres de système d’exploitation recommandés pour SLES 12 ou SLES for SAP Applications 12
- 2455582 Linux : Exécution d’applications SAP compilées avec GCC 6.x
- 2593824 Linux : Exécution d’applications SAP compilées avec GCC 7.x
- 2886607 Linux : Exécution d’applications SAP compilées avec GCC 9.x
[A] Installez SAP HANA.
À compter de HANA 2.0 SPS 01, les conteneurs de base de données multilocataire (MDC) sont l’option par défaut. Lorsque vous installez le système HANA, SYSTEMDB et un locataire avec le même SID sont créés simultanément. Dans certains cas, vous ne souhaitez pas utiliser le locataire par défaut. Si vous ne souhaitez pas créer le locataire initial avec l’installation, suivez les instructions de la note SAP 2629711.
Démarrez le programme
hdblcmà partir du répertoire du logiciel d’installation HANA../hdblcmÀ l’invite, entrez les valeurs suivantes :
- Pour Choisir l’installation : entrez 1 (pour l’installation).
- Pour Sélectionner des composants supplémentaires pour l’installation : saisir 1.
- Pour Entrer le chemin d’installation [/hana/shared] : appuyez sur Entrée pour accepter la valeur par défaut
- Pour Entrer le nom d’hôte local [..] : appuyez sur Entrée pour accepter la valeur par défaut.
- Sous Souhaitez-vous ajouter des hôtes supplémentaires au système ? (y/n) [n] : sélectionnez n.
- Pour Entrer l'ID du système SAP HANA : entrez HN1.
- Pour Entrer le numéro d'instance [00] : entrez 03.
- Pour Sélectionner le mode de base de données / saisir l'index [1] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Sélectionner utilisation du système/Entrer l’index [4] : entrer 4 (pour personnalisé).
- Pour Entrer l'emplacement des volumes de données [/hana/data] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer l'emplacement des volumes de journalisation [/hana/log] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Restreindre l'allocation maximale de mémoire ? [n] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le nom d'hôte du certificat Pour l'hôte '...' [...] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le mot de passe de l'utilisateur de l'agent hôte SAP (sapadm) : entrez le mot de passe utilisateur de l’agent hôte.
- Pour Confirmer le mot de passe de l'utilisateur de l'agent hôte SAP (sapadm) : entrez à nouveau le mot de passe utilisateur de l’agent hôte pour confirmer.
- Pour Entrer le mot de passe de l'administrateur système (hn1adm) : entrez le mot de passe d’administrateur système (AS).
- Pour Confirmer le mot de passe de l'administrateur système (hn1adm) : entrez à nouveau le mot de passe d’administrateur système (AS) pour confirmer.
- Pour Entrer dans le répertoire d'origine de l'administrateur du système [/usr/sap/HN1/home] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer dans le Shell de connexion de l'administrateur système [/bin/sh] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Saisir l'ID utilisateur de l'administrateur système [1001] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer l’ID du groupe d’utilisateurs (sapsys) [79] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Saisir le mot de passe de l'utilisateur de la base de données (SYSTEM) : entrez le mot de passe utilisateur de la base de données.
- Pour Confirmer le mot de passe de l'utilisateur de la base de données (SYSTEM) : entrez à nouveau le mot de passe utilisateur de la base de données pour confirmer.
- Pour Redémarrer le système après le redémarrage de l’ordinateur ? [n] : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Souhaitez-vous continuer ? (y/n) : validez le résumé. Tapez Y pour continuer.
[A] Mettre à niveau l’agent hôte SAP.
Téléchargez la dernière archive de l’agent hôte SAP à partir du SAP Software Center et exécutez la commande suivante pour mettre à niveau l’agent. Remplacez le chemin d’accès à l’archive pour pointer vers le fichier que vous avez téléchargé.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>
Configurer la réplication de système SAP HANA
Suivez les étapes décrites dans Configurer la réplication du système SAP HANA pour configurer la réplication du système SAP HANA.
Configuration des clusters
Cette section décrit les étapes nécessaires au bon fonctionnement du cluster lorsque SAP HANA est installé sur des partages NFS à l’aide d’Azure NetApp Files.
Créez un cluster Pacemaker
Suivez les étapes décrites dans Configurer Pacemaker sur SUSE Enterprise Linux dans Azure pour créer un cluster Pacemaker de base pour ce serveur HANA.
Implémenter des hooks HANA – SAPHanaSR et susChkSrv
Cette étape importante permet d’optimiser l’intégration au cluster et de mieux détecter le moment où un basculement s’avère nécessaire. Nous vivement recommandons de configurer les hooks Python SAPHanaSR et susChkSrv. Suivez les étapes dans Implémenter les hooks de réplication de système Python SAPHanaSR et susChkSrv.
Configurer les ressources de cluster SAP HANA
Cette section décrit les étapes nécessaires à la configuration des ressources de cluster SAP HANA.
Créer les ressources de cluster SAP HANA
Suivez les étapes décrites dans Créer des ressources de cluster SAP HANA pour créer les ressources de cluster pour le serveur HANA. Après la création des ressources, vous devez voir l’état du cluster à l’aide de la commande suivante :
sudo crm_mon -r
Exemple de sortie :
# Online: [ hn1-db-0 hn1-db-1 ]
# Full list of resources:
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Créer des ressources de système de fichiers
Créez une ressource de cluster de système de fichiers factice. Il surveille et signale les échecs en cas de problème d’accès au système de fichiers monté sur NFS /hana/shared. Cela permet au cluster de déclencher le basculement en cas de problème d’accès à /hana/shared. Pour plus d’informations, consultez Handling failed NFS share in SUSE HA cluster for HANA system replication.
[A] Créez la structure de répertoire sur les deux nœuds.
sudo mkdir -p /hana/shared/HN1/check sudo mkdir -p /hana/shared/check[1] configurez le cluster pour ajouter la structure de répertoire pour la supervision.
sudo crm configure primitive rsc_fs_check_HN1_HDB03 Filesystem params \ device="/hana/shared/HN1/check/" \ directory="/hana/shared/check/" fstype=nfs \ options="bind,defaults,rw,hard,rsize=262144,wsize=262144,proto=tcp,noatime,_netdev,nfsvers=4.1,lock,sec=sys" \ op monitor interval=120 timeout=120 on-fail=fence \ op_params OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 \ op stop interval=0 timeout=120[1] clonez et vérifiez le volume nouvellement configuré dans le cluster.
sudo crm configure clone cln_fs_check_HN1_HDB03 rsc_fs_check_HN1_HDB03 meta clone-node-max=1 interleave=trueExemple de sortie :
sudo crm status # Cluster Summary: # Stack: corosync # Current DC: hanadb1 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Tue Nov 2 17:57:39 2021 # Last change: Tue Nov 2 17:57:38 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb1 (Monitoring) # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb2 (Monitoring) # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # rsc_SAPHana_HN1_HDB03 (ocf::suse:SAPHana): Master hanadb1 (Monitoring) # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]L’attribut
OCF_CHECK_LEVEL=20est ajouté à l’opération d’analyse afin que les opérations d’analyse effectuent un test en lecture/écriture sur le système de fichiers. Sans cet attribut, l’opération d’analyse vérifie uniquement que le système de fichiers est monté. Cela peut être un problème car, en cas de perte de connectivité, le système de fichiers peut rester monté, bien qu’il soit inaccessible.L’attribut
on-fail=fenceest également ajouté à l’opération d’analyse. Avec cette option, si l’opération d’analyse échoue sur un nœud, ce dernier est immédiatement isolé.
Important
Les délais d’attente dans la configuration précédente doivent être adaptés à la configuration spécifique de HANA afin d’éviter des actions de clôture inutiles. Ne fixez pas des valeurs de délai d’attente trop basses. Sachez que le moniteur du système de fichiers n’est pas lié à la réplication du système HANA. Pour plus d’informations, consultez la documentation SUSE.
Tester la configuration du cluster
Cette section explique comment vous pouvez tester votre configuration.
Avant de commencer un test, assurez-vous que Pacemaker n’a pas d’action ayant échoué (via l’état crm) et qu’aucune contrainte d’emplacement inattendue (par exemple, les restes d’un test de migration). Vérifiez également que la réplication du système HANA est en état de synchronisation, par exemple avec
systemReplicationStatus.sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Vérifiez l’état des ressources HANA avec cette commande :
SAPHanaSR-showAttr # You should see something like below # hanadb1:~ SAPHanaSR-showAttr # Global cib-time maintenance # -------------------------------------------- # global Mon Nov 8 22:50:30 2021 false # Sites srHook # ------------- # SITE1 PRIM # SITE2 SOK # Site2 SOK # Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost # -------------------------------------------------------------------------------------------------------------------------------------------------------------- # hanadb1 PROMOTED 1636411810 online logreplay hanadb2 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.058.00.1634122452 hanadb1 # hanadb2 DEMOTED 30 online logreplay hanadb1 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.058.00.1634122452 hanadb2Vérifiez la configuration du cluster pour un scénario d’échec lorsqu’un nœud est arrêté. L’exemple suivant montre l’arrêt du nœud 1 :
sudo crm status sudo crm resource move msl_SAPHana_HN1_HDB03 hanadb2 force sudo crm resource cleanupExemple de sortie :
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:25:36 2021 # Last change: Mon Nov 8 23:25:19 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Arrêter le HANA sur node1 :
sudo su - hn1adm sapcontrol -nr 03 -function StopWait 600 10Inscrire le nœud 1 comme nœud secondaire et vérifier le statut :
hdbnsutil -sr_register --remoteHost=hanadb2 --remoteInstance=03 --replicationMode=sync --name=SITE1 --operationMode=logreplayExemple de sortie :
#adding site ... #nameserver hanadb1:30301 not responding. #collecting information ... #updating local ini files ... #done.sudo crm statussudo SAPHanaSR-showAttrVérifiez la configuration du cluster pour un scénario d’échec lorsqu’un nœud perd l’accès au partage NFS (/hana/shared).
Les agents de ressource SAP HANA dépendent de binaires, qui sont stockés sur /hana/shared pour effectuer des opérations pendant le basculement. Le système de fichiers /hana/shared est monté sur NFS dans le scénario présenté.
Il est difficile de simuler une panne pendant laquelle l’un des serveurs perd l’accès au partage NFS. Vous pouvez remonter le système de fichiers en lecture seule en guise de test. Cette approche valide la capacité du cluster à basculer en cas de perte de l’accès à /hana/shared sur le nœud actif.
Résultat attendu : lors de l’exécution de /hana/shared en tant que système de fichiers en lecture seule, l’attribut
OCF_CHECK_LEVELde la ressourcehana_shared1, qui effectue des opérations de lecture/écriture sur le système de fichiers, échoue. Elle échoue, car elle ne peut rien écrire sur le système de fichiers et effectue un basculement de ressource HANA. Le même résultat est attendu lorsque votre nœud HANA perd l’accès aux partages NFS.État des ressources avant le début du test :
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:01:27 2021 # Last change: Mon Nov 8 23:00:46 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb1 ] # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Vous pouvez placer /hana/shared en mode lecture seule sur le nœud de cluster actif à l’aide de la commande suivante :
sudo mount -o ro 10.3.1.4:/hanadb1-shared-mnt00001 /hana/sharedbLe serveur
hanadb1redémarre ou se désactive en fonction de l’action définie. Une fois le serveurhanadb1arrêté, la ressource HANA passe àhanadb2. Vous pouvez vérifier l’état du cluster à partir dehanadb2.sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Wed Nov 10 22:00:27 2021 # Last change: Wed Nov 10 21:59:47 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Nous vous recommandons de tester minutieusement la configuration des clusters SAP HANA, en effectuant les tests décrits dans Réplication du système SAP HANA.