Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Le Runtime Fabric offre une intégration transparente avec Azure. Il fournit un environnement sophistiqué pour les projets d’Ingénieurs de données, et de science des données qui utilisent Apache Spark. Cet article fournit une vue d’ensemble des fonctionnalités et composants essentiels de Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 est une version d’exécution en disponibilité générale qui intègre les composants et mises à niveau suivants conçus pour améliorer vos fonctionnalités de traitement des données :
- Apache Spark 3.5
- Système d’exploitation : Mariner 2.0 (Azure Linux 2.0)
- Java : 11
- Scala : 2.12.17
- Python : 3.11
- Delta Lake : 3.2
- R : 4.4.1
Important
Le canal de version préliminaire du runtime 1.3 inclut un système d’exploitation mis à niveau de Mariner 2.0 (Azure Linux 2.0) vers Mariner 3.0 (Azure Linux 3.0). Utilisez le canal de mise en production d’accès anticipé pour tester vos charges de travail par rapport à cette modification avant qu’elle ne devienne la valeur par défaut. Cette validation est essentielle, en particulier si vos charges de travail ont des dépendances sur les packages au niveau du système d’exploitation.
Conseil
Fabric Runtime 1.3 inclut la prise en charge du moteur d’exécution natif, ce qui peut améliorer considérablement les performances sans plus de coûts. Pour activer le moteur d'exécution natif pour tous les travaux et notebooks de votre environnement, allez dans les paramètres de votre environnement, sélectionnez "Calcul Spark", puis l'onglet "Accélération", et cochez "Activer le moteur d'exécution natif". Une fois que vous avez enregistré et publié, ce paramètre est appliqué dans l’environnement, de sorte que tous les nouveaux jobs et notebooks héritent automatiquement et bénéficient d'une performance améliorée.
Intégrer Runtime 1.3
Note
Pour plus d’informations sur tous les runtimes Fabric disponibles et leur état actuel, consultez Les runtimes Apache Spark dans Fabric.
Utilisez les instructions suivantes, pour intégrer runtime 1.3 à votre espace de travail, et utiliser ses nouvelles fonctionnalités :
Accédez à la tabulation Paramètres de l’espace de travail dans votre espace de travail Fabric.
Accédez à tabulation Ingénieurs de données/Science et sélectionnez Paramètres Spark.
Sélectionnez l’onglet Environnement.
Sous les Versions du runtime, ouvrez la liste déroulante.
Sélectionnez 1.3 (Spark 3.5, Delta 3.2) et enregistrez vos modifications. Cette action définit la version 1.3 en tant que runtime par défaut pour votre espace de travail.
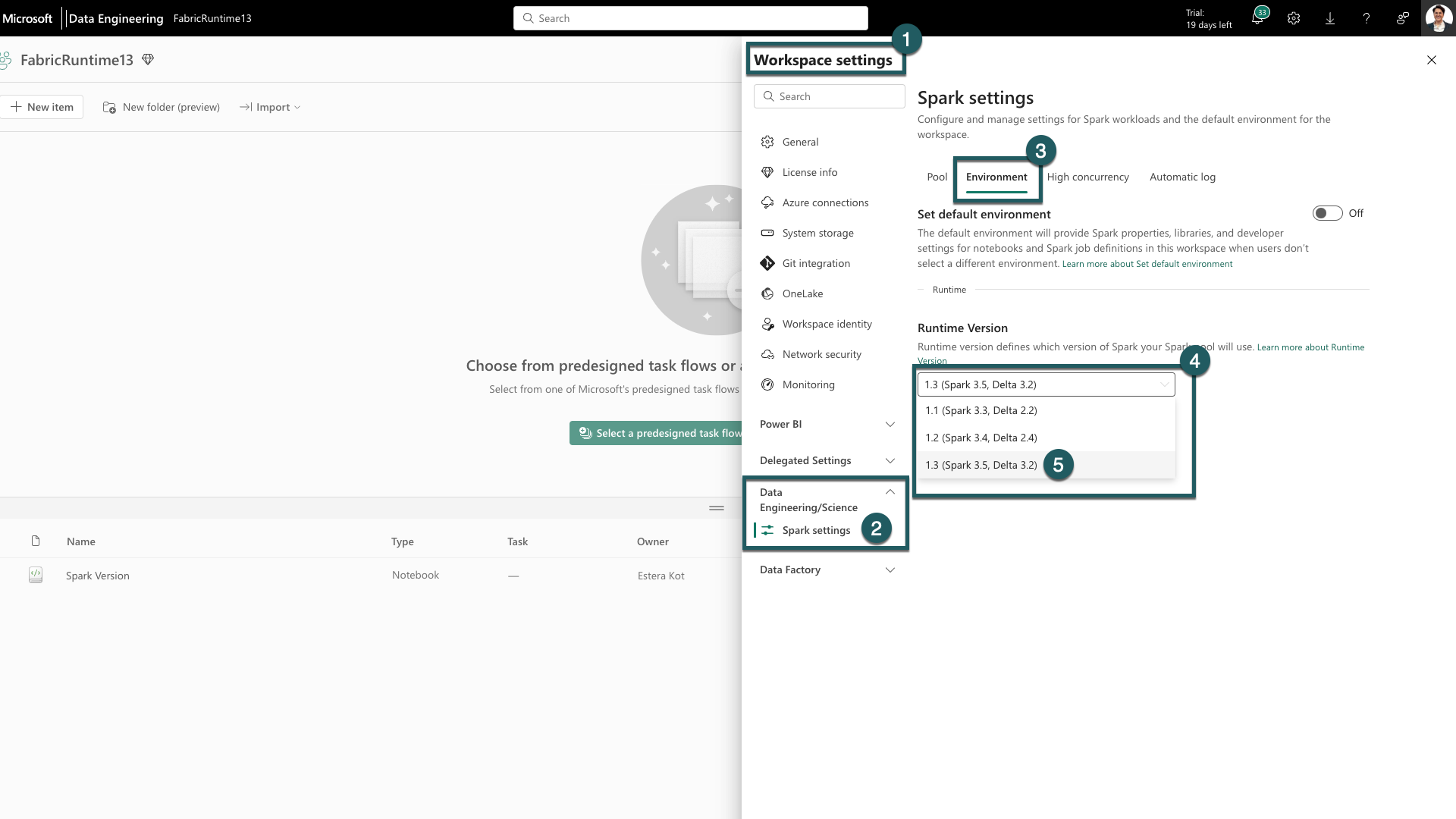

Vous pouvez maintenant commencer à utiliser les dernières améliorations et fonctionnalités introduites dans le runtime Fabric 1.3 (Spark 3.5 et Delta Lake 3.2).
En savoir plus sur Apache Spark 3.5
L’Apache Spark 3.5.0 est la sixième version de la série 3.x. Cette version est le fruit d’une vaste collaboration au sein de la communauté open-source, qui a permis de résoudre plus de 1 300 problèmes enregistrés dans Jira.
Dans cette version, il existe une mise à niveau en compatibilité pour le flux structuré. En outre, cette version élargit les fonctionnalités de PySpark et de SQL. Elle ajoute des fonctionnalités telles que la clause d’identifiant SQL, les arguments nommés dans les appels de fonctions SQL et l’inclusion de fonctions SQL pour les agrégations approximatives d’HyperLogLog.
D’autres nouvelles fonctionnalités incluent également des fonctions de table définies par l’utilisateur Python, la simplification de la formation distribuée via DeepSpeed et de nouvelles fonctionnalités de streaming structurées telles que la propagation de filigranes et l’opération dropDuplicatesWithinWatermark.
Vous pouvez consulter la liste complète et les modifications détaillées ici : Spark Release 3.5.0.
En savoir plus sur Delta Spark
Delta Lake 3.2 marque un engagement collectif à rendre Delta Lake interopérable sur l’ensemble des formats, plus facile à utiliser et plus performant. Delta Spark 3.2 est développé sur Apache Spark™ 3.5. L’artefact maven Delta Spark est renommé delta-core en delta-spark.
Vous pouvez consulter la liste complète et les changements précis ici : https://docs.delta.io/index.html.
Composants et bibliothèques
Pour obtenir des informations à jour, une liste détaillée des modifications et les notes de publication spécifiques pour Fabric runtimes, consultez les versions et mises à jour de Spark Runtimes et abonnez-vous.
Note
EventHubConnector est déconseillé dans Fabric Runtime 1.3 (Spark 3.5) et sera supprimé des futures versions de Fabric Runtime. Les clients sont encouragés à utiliser le connecteur Kafka Spark à la place, car Event Hubs est déjà compatible avec Kafka. Vous trouverez plus d’informations sur l’utilisation du connecteur Kafka Spark avec Event Hubs ici : Tutoriel Sur Event Hubs Kafka Spark
Contenu connexe
- Consultez Runtimes Apache Spark dans Fabric : vue d’ensemble, contrôle de version, prise en charge de plusieurs runtimes et mise à niveau du protocole Delta Lake
- Guide de migration de Spark Core
- Guide de migration de SQL, des jeux de données et du DataFrame
- Guide de migration de la diffusion en continu structurée
- Guide de migration de l’apprentissage automatique (MLlib)
- Guide de migration du PySpark (Python sur Spark)
- Guide de migration SparkR (R sur Spark)