Optimisation d’Azure Data Lake Storage Gen1 pour le niveau de performance
Data Lake Storage Gen1 prend en charge un débit élevé pour l’analytique intensive des E/S et le déplacement des données. Dans Data Lake Storage Gen1, il est important d’utiliser tout le débit disponible (la quantité de données qui peuvent être lues ou écrites par seconde) pour optimiser les performances. Pour cela, il convient d’effectuer le plus possible de lectures et d’écritures en parallèle.

Data Lake Storage Gen1 peut évoluer pour fournir le débit nécessaire pour tous les scénarios d’analyse. Par défaut, un compte Data Lake Storage Gen1 fournit automatiquement suffisamment de débit pour répondre aux besoins d’une vaste catégorie de cas d’usage. Pour les cas où les clients atteignent la limite par défaut, le compte Data Lake Storage Gen1 peut être configuré de manière à fournir un débit plus important en contactant le support de Microsoft.
Ingestion de données
Lors de l’ingestion de données à partir d’un système source dans Data Lake Storage Gen1, vous devez impérativement tenir compte du fait que le matériel source, le matériel réseau source et la connectivité réseau à Data Lake Storage Gen1 peuvent agir comme goulot d’étranglement.

Vous devez impérativement vous assurer que le déplacement des données n’est pas perturbé par ces facteurs.
Matériel source
Que vous utilisiez des machines locales ou des machines virtuelles dans Azure, vous devez sélectionner avec soin le matériel adapté. Pour le matériel du disque source, préférez les disques SSD aux disques durs HDD et choisissez les disques avec les broches les plus rapides. Pour le matériel réseau source, utilisez la carte réseau la plus rapide possible. Sur Azure, nous vous recommandons des machines virtuelles Azure D14 qui sont équipées de disques et du matériel de mise en réseau suffisamment puissants.
Connectivité réseau à Data Lake Storage Gen1
La connectivité réseau entre vos données sources et Data Lake Storage Gen1 peut parfois être le goulot d’étranglement. Lorsque vos données sources sont locales, envisagez d’utiliser une liaison dédiée avec Azure ExpressRoute. Si vos données sources sont dans Azure, les performances seront meilleures lorsque les données sont dans la même région Azure que le compte Data Lake Storage Gen1.
Configurer les outils d’ingestion des données pour une parallélisation maximale
Après avoir traité les goulots d’étranglement du matériel source et de la connectivité réseau, vous pouvez configurer vos outils d’ingestion. Le tableau suivant résume les paramètres clés de plusieurs outils d’ingestion populaires et fournit des articles détaillés concernant le réglage des performances. Pour en savoir plus sur l’outil à utiliser pour votre scénario, consultez cet article.
| Outil | Paramètres | Détails supplémentaires |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Lien |
| AdlCopy | Unités Azure Data Lake Analytics | Lien |
| DistCp | -m (mappeur) | Lien |
| Azure Data Factory | parallelCopies | Lien |
| Sqoop | fs.azure.block.size, -m (mappeur) | Lien |
Structure de votre jeu de données
Lorsque les données sont stockées dans Data Lake Storage Gen1, la taille du fichier, le nombre de fichiers et la structure de dossiers ont un impact sur le niveau de performance. La section suivante décrit les meilleures pratiques en la matière.
Taille du fichier
En règle générale, les moteurs d’analytique comme HDInsight et Azure Data Lake Analytics affichent une surcharge par fichier. Si vous stockez vos données sous forme de petits fichiers nombreux, cela peut nuire aux performances.
De manière générale, organisez vos données dans de grands fichiers pour des performances optimales. Il convient d’organiser les jeux de données dans des fichiers de 256 Mo ou plus. Dans certains cas, par exemple pour les images et les données binaires, il n’est pas possible de les traiter en parallèle. Dans ces cas, il est recommandé de conserver les fichiers individuels en dessous de 2 Go.
Parfois, les pipelines de données ont un contrôle limité sur les données brutes qui possèdent un grand nombre de petits fichiers. Il est recommandé de faire appel à un processus de préparation pour générer les fichiers de grande taille à utiliser pour les applications en aval.
Organiser des données de série chronologique dans des dossiers
Pour les charges de travail Hive et ADLA, le nettoyage de partition de données de série chronologique peut aider certaines requêtes à lire uniquement un sous-ensemble de données, ce qui améliore le niveau de performance.
Ces pipelines qui ingèrent des données de série chronologique organisent souvent leurs fichiers selon une dénomination structurée pour les fichiers et les dossiers. Voici un exemple courant de données structurées par date : \DataSet\AAAA\MM\JJ\datafile_AAAA_MM_JJ.tsv.
Notez que les informations de date / heure s’affichent à la fois en tant que dossiers et dans le nom de fichier.
Pour la date et l’heure, voici un modèle courant : \DataSet\AAAA\MM\JJ\HH\mm\datafile_AAAA_MM_JJ_HH_mm.tsv.
Là encore, le type d’organisation des dossiers et fichiers sélectionné doit optimiser les plus gros fichiers et un nombre raisonnable de fichiers par dossier.
Optimiser des tâches à usage intensif d’E/S sur les charges de travail Hadoop et Spark sur HDInsight
Ces tâches appartiennent à l’une des trois catégories suivantes :
- Usage intensif du processeur. Ces tâches nécessitent de longues heures de calcul avec un minimum de temps d’E/S. L’exemple inclut les tâches de traitement en langage naturel et Machine Learning.
- Utilisation intensive de la mémoire. Ces tâches utilisent beaucoup de mémoire. Exemples : PageRank et travaux d’analytique en temps réel.
- Usage intensif des E/S. La plus grande partie du temps de ces tâches est consacrée aux E/S. Exemple courant : travail de copie qui ne traite que les opérations de lecture et écriture. Autres exemples : travaux de préparation de données qui lisent de nombreuses données, effectuent une transformation de données et réécrivent les données dans le magasin.
Les instructions suivantes ne s’appliquent qu’aux tâches avec un usage intensif d’E/S.
Considérations générales pour les clusters HDInsight
- Versions HDInsight. Pour des performances optimales, utilisez la dernière version de HDInsight.
- Régions. Placez le compte Data Lake Storage Gen1 dans la même région que le cluster HDInsight.
Un cluster HDInsight est composé de deux nœuds principaux et de nœuds Worker. Chaque nœud Worker fournit une quantité spécifique de cœurs et de mémoire, déterminée par le type de machine virtuelle. Lorsque vous exécutez une tâche, YARN est le négociateur de ressource qui alloue la mémoire et les cœurs disponible pour créer des conteneurs. Chaque conteneur exécute les tâches nécessaires pour terminer la tâche. Les conteneurs sont exécutés en parallèle pour traiter rapidement les tâches. Par conséquent, l’exécution du plus grand nombre possible de conteneurs en parallèle permet d’améliorer les performances.
Il existe trois couches au sein d’un cluster HDInsight qui peuvent être ajustées pour augmenter le nombre de conteneurs et utiliser tout le débit disponible.
- Couche physique
- Couche YARN
- Couche de charge de travail
Couche physique
Exécutez le cluster avec le plus de nœuds et/ou les plus grosses machines virtuelles. Un plus grand cluster permet d’exécuter plus de conteneurs YARN, comme le montre l’image ci-dessous.

Utilisez des machines virtuelles avec davantage de bande passante réseau. La quantité de bande passante réseau peut être un goulot d’étranglement si elle moins importante que le débit de Data Lake Storage Gen1. La taille de la bande passante réseau varie en fonction des machines virtuelles. Choisissez un type de machine virtuelle qui possède la plus grande bande passante possible.
Couche YARN
Utilisez des conteneurs YARN plus petits. Réduisez la taille de chaque conteneur YARN pour créer plusieurs conteneurs avec la même quantité de ressources.
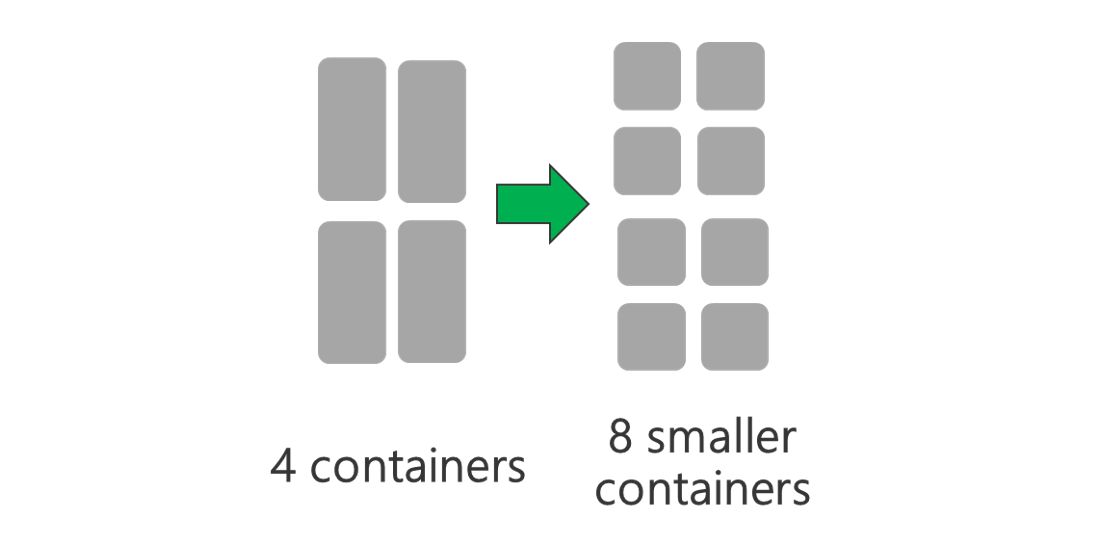
En fonction de votre charge de travail, il y aura toujours une taille de conteneur YARN minimale requise. Si vous sélectionnez un conteneur trop petit, vos tâches rencontreront des problèmes de mémoire insuffisante. En général, les conteneurs YARN ne doivent pas être inférieurs à 1 Go. Il est courant de voir des conteneurs YARN de 3 Go. Pour certaines charges de travail, des conteneurs YARN plus grands peuvent être nécessaires.
Augmentez le nombre de cœurs par conteneur YARN. Augmentez le nombre de cœurs alloués à chaque conteneur pour augmenter le nombre de tâches parallèles qui s’exécutent dans chaque conteneur. Cela fonctionne pour des applications comme Spark qui exécutent plusieurs tâches par conteneur. Pour des applications comme Hive qui exécutent un seul thread par conteneur, il est préférable d’avoir plus de conteneurs plutôt que plus de cœurs par conteneur.
Couche de charge de travail
Utilisez tous les conteneurs disponibles. Définissez le nombre de tâches de manière à ce qu’il soit égal ou supérieur au nombre de conteneurs disponibles. Ainsi, toutes les ressources sont utilisées.

L’échec des tâches est coûteux. Si chaque tâche doit traiter une grande quantité de données, l’échec d’une tâche entraîne une nouvelle tentative coûteuse. Par conséquent, il est préférable de créer davantage de tâches, chacune d’elle traitant une petite quantité de données.
Outre les consignes générales ci-dessus, chaque application possède des paramètres différents à configurer pour cette application spécifique. Le tableau suivant répertorie certains des paramètres et des liens pour paramétrer les performances pour chaque application.
| Charge de travail | Paramètre de définition des tâches |
|---|---|
| Spark sur HDInsight |
|
| Hive sur HDInsight |
|
| MapReduce sur HDInsight |
|
| Storm sur HDInsight |
|