Surveiller l’état des clusters Big Data à l’aide d’Azure Data Studio
Cet article explique comment afficher l’état d’un cluster Big Data à l’aide d’Azure Data Studio.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Utiliser Azure Data Studio
Après avoir téléchargé la dernière build Insiders d’Azure Data Studio, vous pouvez accéder au tableau de bord Cluster Big Data SQL Server pour afficher les points de terminaison de service et l’état d’un cluster Big Data. Certaines des fonctionnalités présentées ci-dessous ne sont disponibles que dans la build Insiders d’Azure Data Studio.
Commencez par créer une connexion à votre cluster Big Data dans Azure Data Studio. Pour plus d’informations, consultez Se connecter à un cluster Big Data SQL Server avec Azure Data Studio.
Cliquez avec le bouton droit sur le point de terminaison du cluster Big Data, puis cliquez sur Gérer.
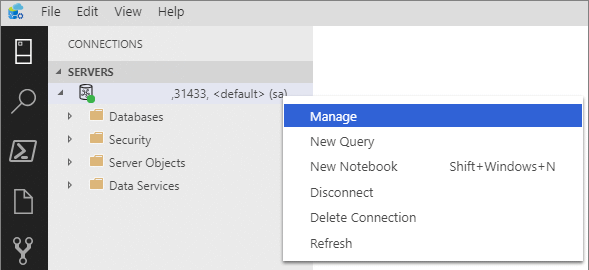
Sélectionnez l’onglet Cluster Big Data SQL Server pour accéder au tableau de bord du cluster Big Data.
Points de terminaison de service
Il est important de pouvoir accéder facilement aux différents services au sein d’un cluster Big Data. Le tableau de bord du cluster Big Data fournit une table de points de terminaison de service qui vous permet de voir et de copier les points de terminaison de service.
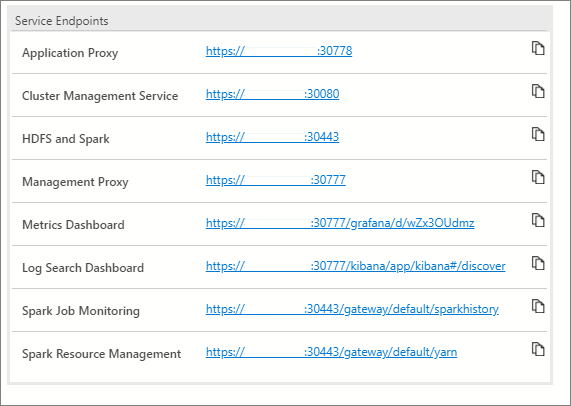
Ces services listent les points de terminaison qui peuvent être copiés et collés quand vous avez besoin du point de terminaison pour vous connecter à ces services. Par exemple, vous pouvez cliquer sur l’icône de copie à droite du point de terminaison, puis la coller dans une fenêtre de texte demandant ce point de terminaison. Le point de terminaison Service de gestion de cluster est nécessaire pour exécuter le notebook cluster status.
Tableaux de bord
La table des points de terminaison de service expose également plusieurs tableaux de bord de supervision :
- Metrics (Métriques) (Grafana)
- Logs (Journaux) (Kibana)
- Spark Job Monitoring (Supervision des travaux Spark)
- Spark Resource Management (Gestion des ressources Spark)
Vous pouvez cliquer directement sur ces liens. Vous serez invité à vous authentifier lors de l’accès à ces tableaux de bord. Pour les tableaux de bord des métriques et des journaux, fournissez les informations d’identification d’administrateur du contrôleur que vous avez définies au moment du déploiement à l’aide des variables d’environnement AZDATA_USERNAME et AZDATA_PASSWORD. Les tableaux de bord Spark utilisent des informations d’identification de passerelle (Knox) : l’identité Active Directory dans un cluster intégré à AD ou AZDATA_USERNAME et AZDATA_PASSWORD si l’authentification de base est utilisée dans votre cluster.
À partir de SQL Server 2019 (15.x) CU 5, lorsque vous déployez un nouveau cluster avec l’authentification de base, tous les points de terminaison, dont la passerelle, utilisent AZDATA_USERNAME et AZDATA_PASSWORD. Les points de terminaison sur les clusters mis à niveau vers la CU 5 continuent à utiliser root comme nom d’utilisateur pour se connecter au point de terminaison de la passerelle. Cette modification ne s’applique pas aux déploiements utilisant l’authentification Active Directory. Voir Informations d’identification pour l’accès aux services via le point de terminaison de passerelle dans les notes de publication.
Notebook Cluster Status
Vous pouvez également voir l’état du cluster Big Data en lançant le notebook Cluster Status (État du cluster). Pour lancer le notebook, cliquez sur la tâche Cluster Status.

Avant de commencer, vous avez besoin des éléments suivants :
- Nom du cluster Big Data
- Nom d’utilisateur du contrôleur
- Mot de passe du contrôleur
- Points de terminaison du contrôleur
Le nom du cluster Big Data par défaut est mssql-cluster, sauf si vous l’avez personnalisé durant votre déploiement. Vous trouverez le point de terminaison du contrôleur dans la table des points de terminaison de service du tableau de bord du cluster Big Data. Le point de terminaison est listé comme Cluster Management Service. Si vous ne connaissez pas les informations d’identification, demandez-les à l’administrateur ayant déployé votre cluster.
Cliquez sur Exécuter les cellules dans la barre d’outils supérieure.
À l’invite, entrez vos informations d’identification. Appuyez sur Entrée après chaque information d’identification : nom du cluster Big Data, nom d’utilisateur du contrôleur et mot de passe du contrôleur.
Notes
Si vous ne disposez pas d’un fichier de configuration avec votre cluster Big Data, vous êtes invité à indiquer le point de terminaison du contrôleur. Tapez-le ou collez-le, puis appuyez sur Entrée pour continuer.
Si vous avez réussi à vous connecter, le reste du notebook montre la sortie de chaque composant du cluster Big Data. Quand vous souhaitez réexécuter une certaine cellule de code, pointez sur celle-ci, puis cliquez sur l’icône Exécuter.
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour