Créer, exporter et scorer des modèles de machine learning Spark sur les Clusters Big Data SQL Server
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
L’exemple suivant montre comment créer un modèle avec Spark ML, exporter le modèle vers MLeap et scorer le modèle dans SQL Server avec son extension de langage Java. Ceci s’effectue dans le contexte d’un cluster Big Data SQL Server.
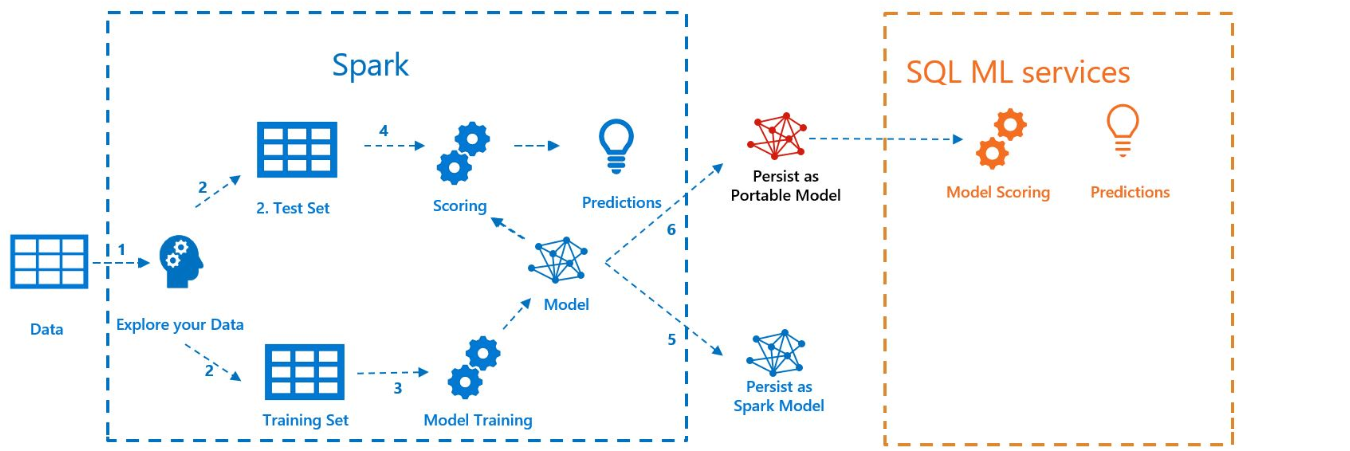
Le schéma ci-dessous illustre le travail effectué dans cet exemple :
Prérequis
Tous les fichiers de cet exemple se trouvent dans https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Pour exécuter l’exemple, vous devez également disposer des prérequis suivants :
-
- kubectl
- curl
- Azure Data Studio
Entraînement du modèle avec Spark ML
Pour cet exemple, les données de recensement (AdultCensusIncome.csv) sont utilisées pour générer un modèle de pipeline Spark ML.
Utilisez le fichier mleap_sql_test/Setup.sh pour télécharger le jeu de données à partir d’Internet et le placer sur HDFS dans votre cluster Big Data SQL Server. Ceci le rend accessible par Spark.
Téléchargez ensuite l’exemple de notebook train_score_export_ml_models_with_spark.ipynb. À partir d’une ligne de commande PowerShell ou bash, exécutez la commande suivante pour télécharger le notebook :
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Ce notebook contient des cellules avec les commandes nécessaires pour cette section de l’exemple.
Ouvrez le notebook dans Azure Data Studio et exécutez chaque bloc de code. Pour plus d’informations sur l’utilisation des notebooks, consultez Guide pratique pour utiliser des notebooks avec SQL Server.
Les données sont d’abord lues dans Spark et divisées en jeux de données d’entraînement et de test. Ensuite, le code entraîne un modèle de pipeline avec les données d’entraînement. Enfin, il exporte le modèle vers un bundle MLeap.
Conseil
Vous pouvez également passer en revue ou exécuter le code Python associé à ces étapes en dehors du notebook dans le fichier mleap_sql_test/mleap_pyspark.py.
Scoring du modèle avec SQL Server
Maintenant que le modèle de pipeline Spark ML se trouve dans un format de bundle MLeap de sérialisation courant, vous pouvez scorer le modèle en Java sans la présence de Spark.
Cet exemple utilise l’extension de langage Java dans SQL Server. Pour pouvoir scorer le modèle dans SQL Server, vous devez d’abord créer une application Java qui peut charger le modèle dans Java et le scorer. Vous pouvez trouver l’exemple de code pour cette application Java dans le dossier mssql-mleap-app.
Après avoir créé l’exemple, vous pouvez utiliser Transact-SQL pour appeler l’application Java et scorer le modèle avec une table de base de données. Vous pouvez voir cela dans le fichier source mleap_sql_test/mleap_sql_tests.py.
Étapes suivantes
Pour plus d’informations sur les clusters Big Data, consultez Guide pratique pour déployer des Clusters Big Data SQL Server sur Kubernetes