Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server 2017 (14.x) et versions ultérieures
SQL Server 2017 (14.x) et versions ultérieures
Cet article explique les étapes permettant de créer un groupe de disponibilité Always On avec un réplica sur un serveur Windows et l’autre réplica sur un serveur Linux.
Important
Les groupes de disponibilité multiplateformes SQL Server, qui incluent des réplicas hétérogènes avec une prise en charge totale de la haute disponibilité et de la reprise d’activité, sont disponibles avec DH2i DxEnterprise. Pour plus d’informations, consultez Groupes de disponibilité SQL Server avec des systèmes d’exploitation mixtes.
Consultez la vidéo suivante pour en savoir plus sur les groupes de disponibilité multiplateformes avec DH2i.
Cette configuration est multiplateforme, car les réplicas se trouvent sur des systèmes d’exploitation différents. Utilisez cette configuration pour la migration d’une plateforme vers l’autre ou la récupération d’urgence (DR). Cette configuration ne prend pas en charge la haute disponibilité.

Avant de continuer, vous devez être familiarisé avec l’installation et la configuration des instances sur Windows et Linux.
Scénario
Dans ce scénario, deux serveurs se trouvent sur des systèmes d’exploitation différents. Un serveur Windows 2022 nommé WinSQLInstance héberge le réplica principal. Un serveur Linux nommé LinuxSQLInstance héberge le réplica secondaire.
Configurer le groupe de disponibilité
Les étapes de création du groupe de disponibilité sont les mêmes que celles permettant de créer un groupe de disponibilité pour les charges de travail avec échelle de lecture. Le type de cluster AG est AUCUN, car il n’existe aucun gestionnaire de clusters.
Pour les scripts de cet article, les crochets pointus < et > identifient les valeurs que vous devez remplacer pour votre environnement. Les crochets pointus ne sont pas requis pour les scripts.
Installez SQL Server 2022 (16.x) sur Windows Server 2022, activez les groupes de disponibilité Always On à partir de Gestionnaire de configuration SQL Server et définissez l’authentification en mode mixte.
Conseil
Si vous validez cette solution dans Azure, placez les deux serveurs dans le même groupe à haute disponibilité pour vous assurer qu’ils sont séparés dans le centre de données.
Activer les groupes de disponibilité
Pour plus d'informations, voir Activer ou désactiver la fonction de groupe de disponibilité Always On.
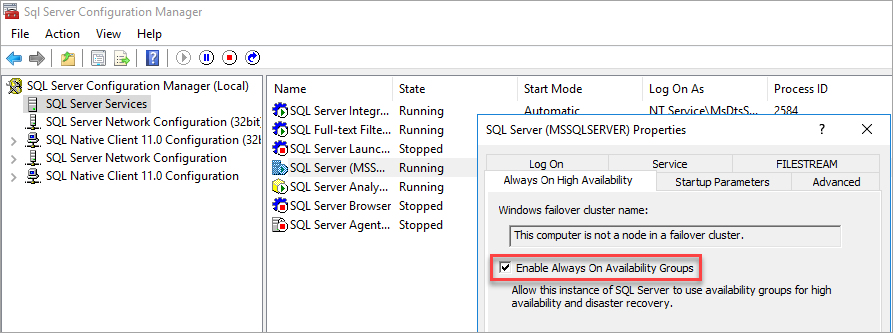
Le Gestionnaire de configuration SQL Server remarque que l’ordinateur n’est pas un nœud dans un cluster de basculement.
Après avoir activé les groupes de disponibilité, redémarrez SQL Server.
Définir l’authentification en mode mixte
Pour obtenir des instructions, consultez Modifier le mode d’authentification du serveur.
Installez SQL Server 2022 (16.x) sur Linux. Pour obtenir des instructions, consultez Guide à l’installation de SQL Server sur Linux. Activez
hadravec mssql-conf.Pour activer
hadrvia mssql-conf à partir d’une invite de Shell, émettez la commande suivante :sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Une fois que vous avez activé
hadr, redémarrez l’instance SQL Server :sudo systemctl restart mssql-server.serviceConfigurez le fichier
hostssur les deux serveurs ou enregistrez les noms de serveurs avec DNS.Ouvrez les ports de pare-feu pour TCP 1433 et 5022 sur Windows et Linux.
Sur le réplica principal, créez une connexion à la base de données et un mot de passe.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOAttention
Votre mot de passe doit respecter la stratégie de mot de passe par défaut de SQL Server. Par défaut, le mot de passe doit avoir au moins huit caractères appartenant à trois des quatre groupes suivants : lettres majuscules, lettres minuscules, chiffres de base 10 et symboles. Les mots de passe peuvent comporter jusqu'à 128 caractères. Utilisez des mots de passe aussi longs et complexes que possible.
Sur le réplica principal, créez une clé principale et un certificat, puis sauvegardez le certificat avec une clé privée.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOAttention
Votre mot de passe doit respecter la stratégie de mot de passe par défaut de SQL Server. Par défaut, le mot de passe doit avoir au moins huit caractères appartenant à trois des quatre groupes suivants : lettres majuscules, lettres minuscules, chiffres de base 10 et symboles. Les mots de passe peuvent comporter jusqu'à 128 caractères. Utilisez des mots de passe aussi longs et complexes que possible.
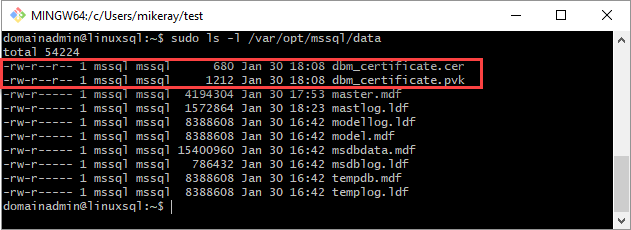
Copiez le certificat et la clé privée sur le serveur Linux (réplica secondaire) à l’adresse
/var/opt/mssql/data. Vous pouvez utiliserpscppour copier les fichiers sur le serveur Linux.Définissez le groupe et la propriété de la clé privée et du certificat sur
mssql:mssql.Le script suivant définit le groupe et la propriété des fichiers.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerDans le diagramme suivant, la propriété et le groupe sont définis correctement pour le certificat et la clé.
Sur le réplica secondaire, créez une connexion à la base de données et un mot de passe, puis créez une clé principale.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOAttention
Votre mot de passe doit respecter la stratégie de mot de passe par défaut de SQL Server. Par défaut, le mot de passe doit avoir au moins huit caractères appartenant à trois des quatre groupes suivants : lettres majuscules, lettres minuscules, chiffres de base 10 et symboles. Les mots de passe peuvent comporter jusqu'à 128 caractères. Utilisez des mots de passe aussi longs et complexes que possible.
Sur le réplica secondaire, restaurez le certificat que vous avez copié sur
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GODans l’exemple précédent, remplacez
<private-key-password>par le même mot de passe que vous avez utilisé lors de la création du certificat sur le réplica principal.Sur le réplica principal, créez un point de terminaison.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOImportant
Le pare-feu doit être ouvert pour le port TCP de l’écouteur. Dans le script précédent, le port est 5022. Utilisez n’importe quel port TCP disponible.
Sur le réplica secondaire, créez le point de terminaison. Répétez le script précédent sur le réplica secondaire pour créer le point de terminaison.
Sur le réplica principal, créez un groupe de disponibilité avec
CLUSTER_TYPE = NONE. L’exemple de script utiliseSEEDING_MODE = AUTOMATICpour créer le groupe de disponibilité.Remarque
Lorsque l’instance Windows de SQL Server utilise des chemins différents pour les données et les fichiers journaux, l’amorçage automatique échoue à l’instance Linux de SQL Server parce que ces chemins n’existent pas sur le réplica secondaire. Pour utiliser le script suivant pour un groupe de disponibilité multiplateforme, la base de données requiert le même chemin d’accès pour les données et les fichiers journaux sur le serveur Windows. Vous pouvez également mettre à jour le script pour définir
SEEDING_MODE = MANUAL, puis sauvegarder et restaurer la base de données avecNORECOVERYpour amorcer la base de données.Ce comportement s’applique aux images de la place de marché Azure.
Pour plus d’informations sur l’amorçage automatique, consultez Amorçage automatique - Disposition du disque.
Avant d’exécuter le script, mettez à jour les valeurs de vos groupes de disponibilité.
Remplacez
<WinSQLInstance>par le nom du serveur de l’instance du réplica principal.Remplacez
<LinuxSQLInstance>par le nom du serveur de l’instance du réplica secondaire.
Pour créer le groupe de disponibilité, mettez à jour les valeurs et exécutez le script sur le réplica principal.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );Pour plus d’informations, consultez CREATE AVAILABILITY GROUP.
Sur le réplica secondaire, joignez le groupe de disponibilité.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOCréez une base de données pour le groupe de disponibilité. Les étapes de l’exemple utilisent une base de données nommée
TestDB. Si vous utilisez l’amorçage automatique, définissez le même chemin d'accès pour les données et les fichiers journaux.Avant d’exécuter le script, mettez à jour les valeurs de votre base de données.
Remplacez
TestDBpar le nom de votre base de données.Remplacez
<F:\Path>par le chemin d’accès de votre base de données et de vos fichiers journaux. Utilisez le même chemin d’accès pour la base de données et les fichiers journaux.
Vous pouvez également utiliser les chemins d’accès par défaut.
Pour créer votre base de données, exécutez le script.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOPrenez une sauvegarde complète de la base de données.
Si vous n’utilisez pas l’amorçage automatique, restaurez la base de données sur le serveur du réplica secondaire (Linux). Migrez une base de données SQL Server de Windows vers Linux à l’aide de la sauvegarde et de la restauration. Restaurez la base de données
WITH NORECOVERYsur le réplica secondaire.Ajoutez la base de données au groupe de disponibilité. Mettez à jour l’exemple de script. Remplacez
TestDBpar le nom de votre base de données. Sur le réplica principal, exécutez la requête SQL pour ajouter la base de données au groupe de disponibilité.ALTER AG [ag1] ADD DATABASE TestDB; GOVérifiez que la base de données est alimentée sur le réplica secondaire.

Basculer le réplica principal
Chaque groupe de disponibilité contient un seul réplica principal. Le réplica principal autorise les opérations de lecture et d’écriture. Pour changer de réplica principal, vous pouvez effectuer un basculement. Dans un groupe de disponibilité standard, le gestionnaire de cluster automatise le processus de basculement. Dans un groupe de disponibilité avec le type de cluster AUCUN, le processus de basculement est manuel.
Il existe deux façons de basculer le réplica principal dans un groupe de disponibilité avec le type de cluster AUCUN :
- Basculement manuel sans perte de données
- Basculement manuel forcé avec perte de données
Basculement manuel sans perte de données
Utilisez cette méthode quand le réplica principal est disponible, mais que vous devez temporairement ou définitivement changer l’instance qui héberge le réplica principal. Pour éviter toute perte de données, avant d’effectuer le basculement manuel, vérifiez que le réplica secondaire cible est à jour.
Pour effectuer un basculement manuel sans perte de données :
Faites en sorte que le réplica principal actuel et le réplica secondaire cible soient
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Pour vérifier que les transactions actives sont validées sur le réplica principal et sur au moins un réplica secondaire synchrone, exécutez la requête suivante :
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;Le réplica secondaire est synchronisé quand
synchronization_state_desca pour valeurSYNCHRONIZED.Affectez la valeur 1 à
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.Le script suivant définit
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsur 1 sur un groupe de disponibilité nomméag1. Avant d’exécuter le script suivant, remplacezag1par le nom de votre groupe de disponibilité :ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Ce paramétrage garantit que chaque transaction active est validée sur le réplica principal et sur au moins un réplica secondaire synchrone.
Remarque
Ce paramètre n’est pas propre au basculement et doit être défini en fonction des exigences de l’environnement.
Définissez le réplica principal et le ou les réplicas secondaires qui ne participent pas au basculement hors connexion pour préparer le changement de rôle :
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPromouvez le réplica secondaire en réplica principal.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Changez le rôle de l’ancien réplica principal en des secondaires par
SECONDARYet exécutez la commande suivante sur l’instance SQL qui héberge l’ancien réplica principal :ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Remarque
Pour supprimer un groupe de disponibilité, utilisez DROP AVAILABILITY GROUP. Pour un groupe de disponibilité créé avec le type de cluster NONE ou EXTERNAL, exécutez la commande sur tous les réplicas faisant partie du groupe de disponibilité.
Pour reprendre le déplacement des données, exécutez la commande suivante pour chaque base de données du groupe de disponibilité sur l’instance de SQL Server qui héberge le réplica principal :
ALTER DATABASE [db1] SET HADR RESUMERecréez l’écouteur que vous avez créé à des fins d’échelle lecture et qui n’est pas géré par un gestionnaire de cluster. Si l’écouteur d’origine pointe vers l’ancien réplica principal, supprimez-le et recréez-le pour qu’il pointe vers le nouveau réplica principal.
Basculement manuel forcé avec perte de données
Si le réplica principal n’est pas disponible et ne peut pas être récupéré immédiatement, vous devez forcer un basculement vers le réplica secondaire avec perte de données. Cependant, si le réplica principal d’origine récupère après le basculement, il va assumer le rôle principal. Pour éviter que chaque réplica soit dans un état différent, supprimez le réplica principal d’origine du groupe de disponibilité après un basculement forcé avec perte de données. Une fois que le serveur principal d’origine revient en ligne, supprimez-y entièrement le groupe de disponibilité.
Pour forcer un basculement manuel avec perte de données du réplica principal N1 vers le réplica secondaire N2, effectuez les étapes suivantes :
Sur le réplica secondaire (N2), lancez le basculement forcé :
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Sur le nouveau réplica principal (N2), supprimez le réplica principal d’origine (N1) :
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Vérifiez que tout le trafic d’application pointe vers l’écouteur et/ou le nouveau réplica principal.
Si le réplica principal d’origine (N1) est mis en ligne, placez immédiatement le groupe de disponibilité AGRScale hors connexion sur le réplica principal d’origine (N1) :
ALTER AVAILABILITY GROUP [AGRScale] OFFLINES’il existe des données ou des modifications non synchronisées, conservez ces données via des sauvegardes ou d’autres options de réplication des données qui répondent aux besoins de votre entreprise.
Ensuite, supprimez le groupe de disponibilité du réplica principal d’origine (N1) :
DROP AVAILABILITY GROUP [AGRScale];Supprimez la base de données du groupe de disponibilité sur le réplica principal d’origine (N1) :
USE [master] GO DROP DATABASE [AGDBRScale] GO(Facultatif) Si vous le souhaitez, vous pouvez maintenant ajouter N1 comme nouveau réplica secondaire au groupe de disponibilité AGRScale.
Cet article a examiné les étapes de création d’un groupe de disponibilité multiplateforme pour prendre en charge les charges de travail de migration ou de lecture-échelle. Il peut être utilisé pour la récupération d’urgence manuelle. Il a également expliqué comment basculer le groupe de disponibilité. Un groupe de disponibilité multiplateforme utilise le type de cluster NONE et ne prend pas en charge la haute disponibilité.