Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server sur Linux
SQL Server sur Linux
Cet article explique les concepts relatifs aux instances de cluster de basculement SQL Server sur Linux.
Pour créer une instance de cluster de basculement SQL Server sur Linux, consultez Configurer une instance de cluster de basculement – SQL Server sur Linux (RHEL).
La couche de clustering
Dans Red Hat Enterprise Linux (RHEL), la couche de clustering est basée sur l’add-on HA Red Hat Enterprise Linux (RHEL).
Remarque
L’accès à la documentation et au module complémentaire HA de Red Hat requiert un abonnement.
Dans le serveur SUSE Linux Entreprise (SLES), la couche de clustering est basée sur l’Extension haute disponibilité (HAE) de SUSE Linux Enterprise.
Pour plus d’informations sur la configuration du cluster, les options de l’agent de ressources, la gestion, les meilleures pratiques et les suggestions, consultez Extension haute disponibilité SUSE Linux Enterprise 15.
Les modules complémentaires RHEL HA et SUSE HAE s’appuient sur Pacemaker.
Comme le montre le diagramme suivant, le stockage est présenté à deux serveurs. Les composants de clustering, Corosync et Pacemaker, coordonnent les communications et la gestion des ressources. L’un des serveurs a la connexion active aux ressources de stockage et au SQL Server. Lorsque Pacemaker détecte une défaillance, les composants de clustering sont chargés de déplacer les ressources vers l'autre nœud.
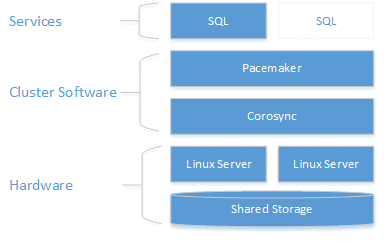
L’intégration de SQL Server avec Pacemaker sur Linux n’est pas aussi couplée qu’avec WSFC sur Windows. SQL Server n’a aucune connaissance de la présence du cluster. Toutes les orchestrations sont externes et le service est contrôlé en tant qu’instance autonome par Pacemaker. En outre, le nom du réseau virtuel est spécifique à WSFC, il n’existe aucun équivalent dans Pacemaker. Il est attendu que @@SERVERNAME et sys.servers retournent le nom du nœud, tandis que les DMV de cluster sys.dm_os_cluster_nodes et sys.dm_os_cluster_properties ne retournent aucun enregistrement. Pour utiliser une chaîne de connexion qui pointe vers un nom de serveur de chaîne et ne pas utiliser l’adresse IP, ils doivent inscrire sur leur serveur DNS l’adresse IP utilisée pour créer la ressource d’adresse IP virtuelle (comme expliqué dans les sections suivantes) avec le nom de serveur choisi.
Nombre d'instances et de nœuds
L’une des principales différences avec SQL Server sur Linux est qu’il ne peut y avoir qu’une seule installation de SQL Server par serveur Linux. Cette installation est appelée une instance. Contrairement à Windows Server, qui prend en charge jusqu’à 25 instances de FCI par cluster de basculement Windows Server (WSFC), une instance FCI basée sur Linux n’a qu’une seule instance. Cette instance unique est également une instance par défaut ; il n’existe pas de concept d’instance nommée sur Linux.
Un cluster Pacemaker peut comporter jusqu’à 16 nœuds lorsque Corosync est impliqué, donc une instance de cluster de basculement unique peut s’étendre sur 16 serveurs. Une instance de cluster de basculement implémentée avec l’Édition Standard de SQL Server prend en charge jusqu’à deux nœuds d’un cluster, même si le cluster Pacemaker a le maximum de 16 nœuds.
Dans une instance de cluster de basculement SQL Server, l’instance est active sur un nœud ou sur l’autre.
Adresse IP et nom
Sur un cluster Pacemaker Linux, chaque instance de cluster de basculement SQL Server a besoin d’une adresse IP et d’un nom uniques. Si la configuration FCI s’étend sur plusieurs sous-réseaux, une adresse IP est requise par sous-réseau. Le nom unique et la ou les adresses IP sont utilisés pour accéder à l’instance FCI pour que les applications et les utilisateurs finaux n’aient pas besoin de connaître le serveur sous-jacent du cluster Pacemaker.
Le nom de l’instance de cluster de basculement dans DNS doit être le même que le nom de la ressource d’instance de cluster de basculement créée dans le cluster Pacemaker. Le nom et l’adresse IP doivent être inscrits dans DNS.
Stockage partagé
Toutes les instances de cluster de basculement, qu’elles se trouvent sur Linux ou Windows Server, requièrent une certaine forme de stockage partagé. Ce stockage est présenté à tous les serveurs susceptibles d'héberger le FCI, mais un seul serveur peut utiliser le stockage pour le FCI à un moment donné. Les options disponibles pour le stockage partagé sous Linux sont les suivantes :
- iSCSI
- NFS (Network File System)
- Bloc de messages serveur (SMB)
Sous Windows Server, il existe des options légèrement différentes. Une option actuellement non prise en charge pour les instances FCI basées sur Linux est la possibilité d’utiliser un disque local sur le nœud pour tempdb, qui est l’espace de travail temporaire de SQL Server.
Dans une configuration qui s’étend sur plusieurs emplacements, ce qui est stocké dans un centre de données doit être synchronisé avec l’autre. En cas de basculement, l’instance de cluster de basculement peut être mis en ligne et le stockage est considéré comme identique. Pour cela, vous devez disposer d’une méthode externe pour la réplication du stockage, qu’elle soit effectuée via le matériel de stockage sous-jacent ou un utilitaire basé sur un logiciel.
Remarque
Pour SQL Server, les déploiements linux utilisant des disques présentés directement à un serveur doivent être mis en forme avec XFS ou ext4. D’autres systèmes de fichiers ne sont actuellement pas pris en charge. Toutes les modifications seront reflétées ici.
Le processus de présentation du stockage partagé est le même pour les différentes méthodes prises en charge :
- Configurer le stockage partagé
- Monter le stockage en tant que dossier sur les serveurs qui serviront de nœuds du cluster Pacemaker pour l’interface de cluster de basculement
- Si nécessaire, déplacez les bases de données système SQL Server vers un stockage partagé
- Tester le bon fonctionnement de SQL Server à partir de chaque serveur connecté au stockage partagé
L’une des principales différences avec SQL Server sur Linux est que même si vous pouvez configurer l’emplacement des fichiers journaux et des données utilisateur par défaut, les bases de données système doivent toujours exister à l’adresse /var/opt/mssql/data. Sur Windows Server, il est possible de déplacer les bases de données système, y compris tempdb. Ce fait joue un rôle sur la configuration du stockage partagé pour une instance de cluster de basculement.
Les chemins d’accès par défaut pour les bases de données non-système peuvent être modifiés à l’aide de l’utilitaire mssql-conf. Pour plus d’informations sur la modification des valeurs par défaut, Modifiez l’emplacement du répertoire de données ou de journaux par défaut. Vous pouvez également stocker des données et des transactions de SQL Server dans d’autres emplacements, à condition qu’elles aient la sécurité appropriée, même si ce n’est pas une localisation par défaut ; l’emplacement doit être indiqué.