Index columnstore : Vue d’ensemble
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Les index columnstore sont la norme pour le stockage et l’interrogation des tables de faits d’entreposage de données de grande taille. Ils utilisent un stockage de données en colonnes et un traitement des requêtes allant jusqu’à multiplier par 10 les performances des requêtes dans l’entrepôt de données par rapport au stockage orienté lignes classique. Vous pouvez également obtenir jusqu’à 10 fois la compression de données par rapport à la taille des données décompressées. À partir de SQL Server 2016 (13.x) SP1, les index columnstore sont compatibles avec l’analytique opérationnelle, qui permet d’exécuter des analyses en temps réel performantes sur une charge de travail transactionnelle.
Voici un scénario connexe :
- Index Columnstore dans l’entreposage de données
- Bien démarrer avec columnstore pour l’analytique opérationnelle en temps réel
Qu’est-ce qu’un index columnstore ?
Un index columnstore est une technologie permettant de stocker, de récupérer et de gérer les données suivant un format de données en colonnes, appelé columnstore.
Termes et concepts clés
Les termes et concepts clés suivants sont associés aux index columnstore.
columnstore
Un columnstore représente des données organisées logiquement sous la forme d’une table comportant des lignes et des colonnes, et stockées physiquement dans un format de données en colonnes.
Rowstore
Un rowstore représente des données organisées logiquement sous la forme d’une table comportant des lignes et des colonnes, et stockées physiquement dans un format de données en colonnes. Il s'agit de la méthode classique de stockage des données de tables relationnelles. Dans SQL Server, un rowstore fait référence à une table dans laquelle le format de stockage de données sous-jacent est un segment de mémoire, un index cluster ou une table optimisée en mémoire.
Remarque
Dans les discussions au sujet des index columnstore, les termes rowstore et columnstore sont utilisés pour mettre en évidence le format du stockage de données.
Rowgroup
Un rowgroup est un groupe de lignes compressées simultanément au format columnstore. Il contient généralement le nombre maximal de lignes par rowgroup, soit 1 048 576 lignes.
Dans un souci de haute performance et de taux de compression élevés, l’index columnstore découpe la table en rowgroups, puis compresse chaque rowgroup en colonnes. Le nombre de lignes dans le groupe de lignes doit être assez grand pour améliorer le taux de compression et assez petit pour tirer parti des opérations en mémoire.
Un rowgroup à partir duquel toutes les données ont été supprimées passe de l’état COMPRESSED à l’état TOMBSTONE, et est ensuite supprimé par un processus en arrière-plan nommé moteur de tuple. Pour plus d’informations sur les états de rowgroup, consultez sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Conseil
Avoir un trop grand nombre de rowgroups de petite taille réduit la qualité de l’index columnstore. Jusqu’à SQL Server 2017 (14.x), une opération de réorganisation est nécessaire pour fusionner des rowgroups COMPRESSED plus petits, suite à une stratégie de seuil interne qui détermine comment supprimer les lignes supprimées et combiner les rowgroups compressés.
À partir de SQL Server 2019 (15.x), une tâche de fusion en arrière-plan fonctionne également pour fusionner les rowgroups COMPRESSED à partir desquels un grand nombre de lignes a été supprimé.
Après la fusion de plusieurs rowgroups plus petits, la qualité de l’index doit être améliorée.
Remarque
À partir de SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance et les pools SQL dédiés dans Azure Synapse Analytics, le moteur de tuple est aidé par une tâche de fusion en arrière-plan qui compresse automatiquement les rowgroups delta ouverts plus petits qui existent depuis un certain temps, tel que déterminé par un seuil interne, ou qui fusionne les rowgroups compressés à partir desquels un grand nombre de lignes a été supprimé. Cela améliore la qualité de l’index columnstore dans le temps.
Segment de colonne
Un segment de colonne est une colonne de données issue du rowgroup.
- Chaque rowgroup contient un segment de colonne pour chaque colonne dans la table.
- Chaque segment de colonne est compressé et stocké sur un support physique.
- Il existe des métadonnées associées à chaque segment pour permettre une élimination rapide des segments sans les lire.
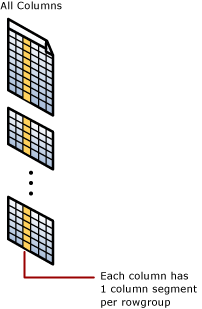
Index columnstore cluster
Un index columnstore cluster représente le stockage physique de la totalité de la table.
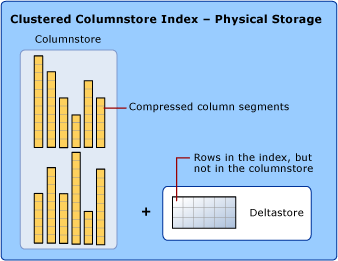
Pour réduire la fragmentation des segments de colonne et améliorer les performances, l’index columnstore peut stocker temporairement des données dans un index cluster appelé deltastore, ainsi que la liste en arbre B (B-tree) des ID des lignes supprimées. Les opérations deltastore sont effectuées en coulisse. Pour retourner des résultats de requête corrects, l'index columnstore cluster associe les résultats de columnstore et de deltastore.
Remarque
De manière générale, la documentation SQL Server utilise le terme B-tree en référence aux index. Dans les index rowstore, le moteur de base de données implémente une structure B+. Cela ne s’applique pas aux index columnstore ou aux index sur les tables à mémoire optimisée. Pour plus d’informations, consultez le Guide de conception et d’architecture d’index SQL Server et Azure SQL.
Rowgroup delta
Un rowgroup delta est un index B-tree en cluster utilisé uniquement avec des index columnstore. Il améliore la compression columnstore et les performances en stockant des lignes jusqu’à ce que leur nombre atteigne un certain seuil (1 048 576 lignes) et qu’elles soient alors déplacées dans le columnstore.
Lorsqu’un rowgroup delta atteint le nombre maximal de lignes, il passe de l’état OPEN à l’état CLOSED. Un processus en arrière-plan nommé moteur de tuple vérifie les groupes de lignes fermés. Lorsqu’il trouve un rowgroup fermé, il compresse le rowgroup delta et le stocke dans le columnstore en tant que rowgroup COMPRESSED.
Quand un rowgroup delta a été compressé, le rowgroup delta existant passe à l’état TOMBSTONE pour être supprimé ultérieurement par le moteur de tuple lorsqu’il n’y a aucune référence à celui-ci.
Pour plus d’informations sur les états de rowgroup, consultez sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Remarque
À partir de SQL Server 2019 (15.x), le moteur de tuple est aidé par une tâche de fusion en arrière-plan qui compresse automatiquement les rowgroups delta OPEN plus petits qui existent depuis un certain temps, tel que déterminé par un seuil interne, ou qui fusionne les rowgroups COMPRESSED à partir desquels un grand nombre de lignes a été supprimé. Cela améliore la qualité de l’index columnstore dans le temps.
Deltastore
Un index columnstore peut avoir plusieurs rowgroups delta, qui sont appelés collectivement le deltastore.
Lors d'un chargement en masse important, la plupart des lignes sont directement placées dans le columnstore sans passer par le deltastore. Il peut arriver que, à la fin du chargement en masse, le nombre de lignes soit inférieur à la taille minimale d'un rowgroup, qui est de 102 400 lignes. Dans ce cas, les lignes finales sont placées dans le deltastore plutôt que dans le columnstore. Pour les petits chargements en masse de taille inférieure à 102 400 lignes, toutes les lignes vont directement au deltastore.
index columnstore non cluster
Un index columnstore non cluster et un index columnstore cluster fonctionnent de la même manière. La différence réside dans le fait qu’un index non cluster est un index secondaire créé sur une table rowstore, tandis qu’un index cluster columnstore correspond au stockage principal de la table entière.
L’index non cluster contient une copie de tout ou partie des lignes et des colonnes de la table sous-jacente. L’index est défini comme une ou plusieurs colonnes de la table ; il a une condition facultative qui filtre les lignes.
Un index columnstore non cluster est compatible avec l’analytique opérationnelle en temps réel dans laquelle la charge de travail OLTP utilise l’index cluster sous-jacent, tandis que l’analytique s’exécute simultanément sur l’index columnstore. Pour plus d’informations, voir Bien démarrer avec columnstore pour l’analytique opérationnelle en temps réel.
Exécution en mode batch
L’exécution en mode batch est une méthode de traitement des requêtes utilisée pour traiter plusieurs lignes ensemble. L’exécution en mode batch est étroitement intégrée au format de stockage columnstore et optimisée pour celui-ci. L’exécution en mode batch est parfois appelée exécution vectorielle ou vectorisée. Les requêtes sur les index columnstore utilisent l’exécution en mode batch, qui permet généralement de multiplier les performances des requêtes par deux ou quatre. Pour plus d’informations, voir Guide d’architecture de traitement des requêtes.
Pourquoi utiliser un index columnstore ?
Un index columnstore peut offrir un niveau très élevé de compression de données (généralement multiplié par 10) afin de réduire de manière significative le coût de stockage de l’entrepôt de données. Pour l’analytique, il présente des performances réellement meilleures que celles d’un index en arbre B. Il s’agit du format de stockage de données de prédilection pour les charges de travail d’entreposage des données et d’analytique. À partir de SQL Server 2016 (13.x) , vous pouvez utiliser des index columnstore pour l’analyse en temps réel sur votre charge de travail opérationnelle.
Voici les raisons pour lesquelles les index columnstore sont si rapides :
Les valeurs columnstore d’un même domaine sont généralement similaires, ce qui se traduit par des taux de compression élevés. Les goulots d’étranglement d’E/S du système sont atténués ou éliminés, et l’encombrement en mémoire est considérablement réduit.
Les taux de compression élevés améliorent les performances des requêtes en utilisant un plus faible encombrement en mémoire. En conséquence, les performances des requêtes sont améliorées, car SQL Server peut exécuter davantage d’opérations de requêtes et sur les données en mémoire.
L’exécution par lot multiplie généralement les performances des requêtes par deux ou quatre grâce au traitement simultané de plusieurs lignes.
Les requêtes sélectionnent souvent seulement quelques colonnes d'une table, ce qui réduit les E/S totales à partir du support physique.
Quand utiliser un index columnstore ?
Voici les cas d’utilisation recommandés :
Utilisez un index cluster columnstore pour stocker les tables de faits et de grandes tables de dimension pour les charges de travail d’entreposage de données. Cette méthode peut permettre de multiplier par 10 les performances des requêtes et la compression des données. Pour plus d’informations, voir Index columnstore pour l’entreposage des données.
Utilisez un index columnstore non cluster pour effectuer une analyse en temps réel sur une charge de travail OLTP. Pour plus d’informations, voir Bien démarrer avec columnstore pour l’analytique opérationnelle en temps réel.
Pour plus de scénarios d’utilisation pour les index columnstore, consultez Choisir l’index columnstore le plus adapté à vos besoins.
Comment choisir entre un index rowstore et un index columnstore ?
Les index rowstore fonctionnent de manière optimale sur les requêtes qui recherchent une valeur spécifique au sein des données et sur celles qui interrogent une petite plage de valeurs. Utilisez les index rowstore avec des charges de travail transactionnelles, car ils passent principalement par des recherches de tables plutôt que par des analyses de tables.
Les index columnstore offrent des gains de performances élevés pour les requêtes analytiques qui analysent de grandes quantités de données, en particulier sur des tables volumineuses. Utilisez les index columnstore sur les charges de travail d’analytique et d’entreposage des données, en particulier sur les tables de faits, car ils passent généralement par des analyses de tables complètes plutôt que par des recherches de tables.
Les index columnstore en cluster ordonnés améliorent les performances des requêtes en fonction des prédicats de colonne ordonnés. Les index columnstore ordonnés peuvent améliorer l’élimination de groupes de lignes, ce qui peut améliorer les performances en ignorant complètement les groupes de lignes. Pour plus d’informations, consultez Réglage des performances avec les index columnstore cluster ordonnés. Pour obtenir la disponibilité de l’index columnstore ordonné, consultez la disponibilité de l’index de colonne ordonné.
Puis-je combiner les formats rowstore et columnstore dans la même table ?
Oui. À partir de SQL Server 2016 (13.x), il est possible de créer un index columnstore non cluster pouvant être mis à jour sur une table rowstore. L’index columnstore stocke une copie des colonnes sélectionnées. Il faut donc de l’espace supplémentaire pour ces données, même si elles sont compressées en moyenne 10 fois. Il est possible d’exécuter simultanément l’analytique sur l’index columnstore et les transactions sur l’index rowstore. Le columnstore est mis à jour en cas de modification des données de la table rowstore. Les deux index utilisent donc les mêmes données.
À partir de SQL Server 2016 (13.x), il est possible d’avoir un ou plusieurs index rowstore non cluster sur un index columnstore et d’effectuer des recherches de tables efficaces sur le columnstore sous-jacent. D’autres options sont également disponibles. Par exemple, vous pouvez appliquer une contrainte de clé primaire à l’aide d’une contrainte UNIQUE sur la table rowstore. Dans la mesure où une valeur non unique ne s’insère pas dans la table rowstore, SQL Server ne peut pas l’ajouter au columnstore.
Index columnstore ordonnés
En activant une élimination efficace des segments, les index columnstore en cluster ordonné (CCI) fournissent des performances beaucoup plus rapides en ignorant de grandes quantités de données ordonnées qui ne correspondent pas au prédicat de requête. Le chargement des données dans une table à index columnstore cluster ordonné peut prendre plus de temps que dans une table à index columnstore cluster non-ordonné en raison de l’opération de tri des données. Toutefois, les requêtes peuvent s’exécuter plus rapidement après avec l’index columnstore cluster ordonné.
- Pour plus d’informations sur les charges de travail d’entreposage de données de paramétrage des performances dans le Moteur de base de données SQL avec des index columnstore cluster ordonnés, consultez Réglage des performances avec des index columnstore cluster ordonnés.
- Pour plus d’informations sur l’utilisation du type d’index columnstore, consultez Choisir le meilleur index columnstore pour vos besoins.
Disponibilité de l’index columnstore ordonnée
Tout d’abord introduit avec ![]() SQL Server 2022 (16.x), les index columnstore ordonnés sont disponibles sur les plateformes suivantes.
SQL Server 2022 (16.x), les index columnstore ordonnés sont disponibles sur les plateformes suivantes.
| Plateforme | Index columnstore en cluster ordonnés | Index columnstore non cluster ordonnés |
|---|---|---|
| Azure SQL Database | Oui | Oui |
| SQL Server 2022 (16.x) | Oui | Non |
| Azure SQL Managed Instance | Oui | Oui |
| Sécurisation d’un pool SQL dédié dans Azure Synapse Analytics | Oui | Non |
Métadonnées
Toutes les colonnes dans un index columnstore sont stockées dans les métadonnées en tant que colonnes incluses. L'index columnstore n'a pas de colonnes clés.
Tâches associées
Toutes les tables relationnelles, sauf si vous les spécifiez en tant qu’index cluster columnstore, utilisent rowstore comme format de données sous-jacent. CREATE TABLE crée une table rowstore, sauf si vous spécifiez l’option WITH CLUSTERED COLUMNSTORE INDEX.
Quand vous créez une table avec l’instruction CREATE TABLE, vous pouvez en faire un columnstore en spécifiant l’option WITH CLUSTERED COLUMNSTORE INDEX. Si vous avez déjà une table rowstore et que vous souhaitez la convertir au format columnstore, utilisez l’instruction CREATE COLUMNSTORE INDEX.
| Tâche | Articles de référence | Notes |
|---|---|---|
| Créer une table sous forme de columnstore | CREATE TABLE (Transact-SQL) | À partir de SQL Server 2016 (13.x), vous pouvez créer la table en tant qu’index cluster columnstore. Il est inutile de créer au préalable une table rowstore pour la convertir ensuite en columnstore. |
| Créez une table à mémoire optimisée avec un index columnstore. | CREATE TABLE (Transact-SQL) | À partir de SQL Server 2016 (13.x), vous pouvez créer une table optimisée en mémoire avec un index columnstore. L’index columnstore peut également être ajouté après la création de la table, suivant la syntaxe ALTER TABLE ADD INDEX. |
| Convertir une table rowstore en table columnstore | CREATE COLUMNSTORE INDEX (Transact-SQL) | Convertissez un segment de mémoire ou un arbre B existant en columnstore. Les exemples montrent comment gérer les index existants, ainsi que le nom de l’index lors de cette conversion. |
| Convertir une table columnstore en rowstore | CREATE CLUSTERED INDEX (Transact-SQL) ou Reconvertir une table columnstore en segment rowstore | Cette conversion n’est généralement pas nécessaire, mais le cas peut se présenter. Les exemples montrent comment convertir un columnstore en segment de mémoire ou index cluster. |
| Créer un index columnstore sur une table rowstore | CREATE COLUMNSTORE INDEX (Transact-SQL) | Une table rowstore ne peut avoir qu’un seul index columnstore. À partir de SQL Server 2016 (13.x) , l’index columnstore peut avoir une condition de filtrage. Les exemples affichent la syntaxe de base. |
| Créer des index performants pour l’analytique opérationnelle | Bien démarrer avec columnstore pour l’analytique opérationnelle en temps réel | Décrit comment créer des index columnstore et en arbre B complémentaires pour que les requêtes OLTP utilisent des index en arbre B et que les requêtes analytiques utilisent des index columnstore. |
| Créer des index columnstore performants pour l’entreposage des données | Index columnstore pour l’entreposage des données | Décrit comment utiliser des index B-tree sur les tables columnstore pour créer des requêtes performantes en matière d’entreposage des données. |
| Utiliser un index B-tree pour appliquer une contrainte de clé primaire sur un index columnstore. | Index columnstore pour l’entreposage des données | Montre comment combiner des index B-tree et columnstore pour appliquer des contraintes de clé primaire sur l’index columnstore. |
| Supprimer un index columnstore | DROP INDEX (Transact-SQL) | La suppression d’un index columnstore utilise la syntaxe DROP INDEX standard des index en arbre B. La suppression d’un index columnstore cluster convertit la table columnstore en segment de mémoire. |
| Supprimer une ligne d’un index columnstore | DELETE (Transact-SQL) | Utilisez DELETE (Transact-SQL) pour supprimer une ligne. Ligne columnstore : SQL Server marque la ligne comme étant supprimée logiquement, mais ne récupère pas le stockage physique associé tant que l’index n’est pas régénéré. Ligne deltastore : SQL Server supprime la ligne logiquement et physiquement. |
| Mettre à jour une ligne dans l’index columnstore | UPDATE (Transact-SQL) | Utilisez UPDATE (Transact-SQL) pour mettre à jour une ligne. Ligne columnstore : SQL Server marque la ligne comme étant supprimée logiquement, puis insère la ligne mise à jour dans le delta store. Ligne deltastore : SQL Server met à jour la ligne dans le delta store. |
| Charger des données dans un index columnstore | Chargement de données d’index columnstore | |
| Obliger toutes les lignes du deltastore à aller dans le columnstore. | ALTER INDEX (Transact-SQL) ... REBUILDOptimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources |
ALTER INDEX avec l’option REBUILD oblige toutes les lignes à aller dans le columnstore. |
| Défragmenter un index columnstore | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE défragmente les index columnstore en ligne. |
| Fusionner des tables avec les index columnstore | MERGE (Transact-SQL) |
Contenu connexe
- Nouveautés des index columnstore
- Index columnstore - Conseils en matière de chargement de données
- Index columnstore - Performances des requêtes
- Bien démarrer avec columnstore pour l’analytique opérationnelle en temps réel
- Index Columnstore dans l’entreposage de données
- Défragmentation d’index columnstore
- Guide de conception et d’architecture d’index SQL Server et Azure SQL
- Architecture des index columnstore
- CREATE COLUMNSTORE INDEX (Transact-SQL)