Lecture de pages
S'applique à : ![]() SQL Server
SQL Server
Les E/S d’une instance du moteur de base de données SQL Server incluent les lectures logiques et physiques. Une lecture logique se produit chaque fois que le moteur de base de données demande une page au cache des tampons. Si la page ne se trouve pas actuellement dans le cache des tampons, le système effectue une lecture physique afin de copier la page contenue dans le cache.
Les requêtes de lecture générées par une instance du moteur de base de données sont contrôlées par le moteur relationnel et optimisées par le moteur de stockage. Le moteur relationnel détermine la méthode d'accès la plus efficace (par exemple une analyse de table, une analyse d'index ou une lecture par clé) ; les composants méthodes d'accès et gestionnaire de tampons du moteur de stockage déterminent le modèle général de lecture à exécuter, et optimisent les lectures nécessaires à l'implémentation de la méthode d'accès. Le thread exécutant le lot planifie les lectures.
Lecture anticipée
Le moteur de base de données prend en charge un mécanisme d’optimisation des performances appelé lecture anticipée. La lecture anticipée anticipe les pages d'index et de données nécessaires à l'exécution d'un plan d'exécution de requête et transfère les pages dans le cache des tampons avant leur utilisation à proprement dite par la requête. Cette opération permet le chevauchement du calcul et des E/S, ce qui permet d'optimiser l'utilisation du disque et de l'UC.
Le mécanisme de lecture anticipée permet au moteur de base de données de lire jusqu’à 64 pages contiguës (512 Ko) dans un fichier. La lecture est une lecture unique par ventilation-regroupement du nombre approprié de mémoires tampons (probablement non contiguës) dans le cache des tampons. Si les pages de la plage figurent déjà dans le cache des tampons, la page correspondante issue de la lecture est ignorée une fois la lecture terminée. Le début et la fin de la plage des pages peuvent faire l'objet d'une « troncation » si les pages correspondantes sont déjà en cache.
Il existe deux types de lecture anticipée : l'une destinée aux pages de données et l'autre aux pages d'index.
Lecture des pages de données
Les analyses de table utilisées pour la lecture des pages de données sont très efficaces dans le moteur de base de données. Les pages IAM (Index Allocation Map) d’une base de données SQL Server dressent la liste des étendues utilisées par une table ou un index. Le moteur de stockage peut lire la page IAM afin d'établir une liste des adresses de disques qui doivent être lues. Cela permet au moteur de stockage d'optimiser ses E/S sous la forme d'importantes lectures séquentielles en fonction de leur emplacement sur le disque. Pour plus d’informations sur les pages IAM, consultez Gestion de l’espace utilisé par les objets.
Lecture de pages d'index
Le moteur de stockage lit les pages d'index en série selon l'ordre des clés. Par exemple, l'illustration ci-dessous montre une représentation simplifiée d'un ensemble de pages d'arborescence contenant un ensemble de clés et le nœud d'index intermédiaire mappant les pages de l'arborescence. Pour plus d’informations sur la structure des pages dans un index, consultez Structures des index cluster.
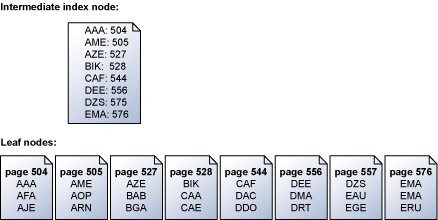
Le moteur de stockage utilise les informations de la page d'index intermédiaire au-dessus du niveau des feuilles pour planifier les lectures anticipées en série des pages contenant les clés. Si une requête est effectuée pour toutes les clés de ABC à DEF, le moteur de stockage lit d'abord la page d'index au-dessus de la page feuille. Cependant, elle ne lit pas simplement chaque page de données en séquence de la page 504 à la page 556, la dernière comportant des clés dans la plage désirée. Au lieu de cela, le moteur de stockage analyse la page d'index intermédiaire et génère la liste des pages feuille qui doivent être lues. Le moteur de stockage planifie alors toutes les lectures dans l'ordre des clés. Le moteur de stockage reconnaît également que les pages 504/505 et 527/528 sont contiguës et effectue une seule lecture par ventilation pour extraire les pages adjacentes en une seule opération. Lorsque plusieurs pages doivent être extraites par une opération en série, le moteur de stockage planifie un bloc de lectures à la fois. Lorsqu'un sous-ensemble de ces lectures est terminé, le moteur de stockage planifie le même nombre de nouvelles lectures jusqu'à ce que toutes les lectures nécessaires aient été planifiées.
Le moteur de stockage utilise la pré-extraction pour accélérer la recherche de table de consultation dans les index non-cluster. Les lignes feuille d'un index non-cluster contiennent des pointeurs vers les lignes de données contenant chaque valeur de clé spécifique. Lorsque le moteur de stockage lit les pages feuille de l'index non-cluster, il planifie également les lectures asynchrones des lignes de données dont les pointeurs ont déjà été extraits. Cela permet au moteur de stockage d'extraire des lignes de données de la table sous-jacente avant d'avoir terminé l'analyse de l'index non-cluster. La pré-extraction est utilisée que la table possède ou non un index cluster. SQL Server Entreprise utilise davantage de préextraction que les autres éditions de SQL Server, ce qui permet la lecture anticipée d’autres pages. Le niveau de pré-extraction ne peut être configuré dans aucune édition. Pour plus d’informations sur les index non cluster, consultez Structures d’index non-cluster.
Analyse avancée
La fonction d’analyse avancée de SQL Server Entreprise permet le partage d’analyses de tables complètes par plusieurs tâches. Si le plan d’exécution d’une instruction Transact-SQL exige une analyse des pages de données d’une table et le moteur de base de données détecte que la table est déjà en cours d’analyse pour un autre plan d’exécution, le moteur de base de données joint la deuxième analyse à la première, à l’emplacement actuel de la deuxième analyse. Le moteur de base de données lit chaque page une fois et transmet les lignes de chacune des pages aux deux plans d’exécution. Ce processus se poursuit jusqu'à ce que la fin de la table soit atteinte.
À ce moment, le premier plan d'exécution possède les résultats complets d'une analyse, mais le second plan d'exécution doit encore extraire les pages de données qui ont été lues avant le point où il a rejoint l'analyse en cours. L'analyse du second plan d'exécution revient alors à la première page de données de la table et poursuit l'analyse jusqu'au point de jonction avec la première analyse. Un nombre quelconque d'analyses peuvent ainsi être combinées. Le moteur de base de données continue à parcourir les pages de données jusqu’à ce que toutes les analyses soient terminées. Ce mécanisme est aussi appelé « analyse carrousel », ce qui explique pourquoi l'ordre des résultats retournés par une instruction SELECT dépourvue d'une clause ORDER BY ne peut pas être garanti.
Supposons par exemple que vous disposiez d'une table de 500 000 pages. L’UtilisateurA exécute une instruction Transact-SQL qui requiert une analyse de cette table. Lorsque cette analyse a déjà traité 100 000 pages, l’UtilisateurB exécute une autre instruction Transact-SQL qui analyse la même table. Le moteur de base de données planifie un ensemble de requêtes de lectures pour les pages à partir de la 100 001e et transmet les lignes de chaque page aux deux analyses. Lorsque l’analyse atteint la 200 000e page, l’UtilisateurC exécute une autre instruction Transact-SQL qui analyse la même table. En commençant par la page 200 001, le moteur de base de données transmet les lignes de chaque page lue aux trois analyses. Après avoir lu la 500 000 ème ligne, l'analyse est terminée pour l'UtilisateurA et les analyses pour l'UtilisateurB et l'UtilisateurC reprennent à partir de la page 1. Lorsque le moteur de base de données atteint la page 100 000, l’analyse pour l’UtilisateurB est terminée. L'analyse pour l'UtilisateurC se poursuit alors jusqu'à la 200 000 ème page. À ce stade, toutes les analyses sont terminées.
Sans analyse avancée, chaque utilisateur doit se battre pour utiliser l'espace tampon et causer des contentions de disque. Les mêmes pages sont alors probablement lues une fois pour chaque utilisateur, plutôt que d'être lues une fois et partagées entre plusieurs utilisateurs, ce qui ralentit les performances et consomme des ressources.
Voir aussi
Guide d’architecture des pages et des étendues
Écriture de pages