Scénarios d’utilisation de table temporelle
S'applique à : ![]() SQL Server
SQL Server
Les tables temporelles avec version du système sont utiles dans les scénarios qui requièrent un suivi de l'historique des modifications des données. Nous vous recommandons d'envisager l'utilisation de tables temporelles dans les cas d'utilisation suivants, afin de bénéficier d'importants avantages en termes de productivité.
Audit des données
Vous pouvez utiliser la version temporelle du système pour les tables qui stockent des informations critiques, afin de garder une trace de ce qui a été modifié et quand, et d'effectuer des analyses de données à tout moment.
Les tables temporelles vous permettent de planifier les scénarios d’audit de données dans les premières étapes du cycle de développement ou d’ajouter un audit de données à des applications ou solutions existantes quand vous en avez besoin.
Le diagramme suivant illustre un scénario avec une table Employee, dont l’échantillon de données comprend des versions de ligne actuelles (bleu) et historiques (gris).
La partie droite du diagramme indique les versions de ligne sur l’axe du temps et les lignes qui sont sélectionnées avec différents types de requêtes sur la table temporelle avec ou sans la clause SYSTEM_TIME.

Activer la version du système sur une nouvelle table pour l'audit des données
Si vous identifiez des informations nécessitant un audit des données, créez des tables de base de données en tant que tables temporelles version système. L’exemple suivant illustre un scénario avec une table appelée Employee dans une base de données RH hypothétique :
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
Diverses options pour créer une table avec gestion système des versions temporelle sont décrites dans Créer une table temporelle versionnée par le système.
Activer la version du système sur une table existante pour l'audit des données
Si vous avez besoin d’effectuer un audit des données dans des bases de données existantes, utilisez ALTER TABLE pour convertir les tables non temporelles en tables avec version système. Pour préserver votre application, ajoutez des colonnes de période avec l’option HIDDEN, comme expliqué dans Créer une table temporelle versionnée par le système.
L’exemple suivant illustre l’activation de la gestion système des versions sur une table Employee existante appartenant à une base de données de ressources humaines hypothétique. Il active le contrôle de version système dans le tableau Employee en deux étapes. Tout d’abord, les nouvelles colonnes de période sont ajoutées en tant que HIDDEN. Ensuite, il crée la table d’historique par défaut.
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Important
La précision du type de données datetime2 est la même dans la table source et dans la table de l’historique versionnée par le système.
Une fois exécuté le script précédent, toutes les modifications de données sont collectées en toute transparence dans la table de l’historique. Dans un scénario d’audit de données standard, vous souhaitez connaître toutes les modifications de données qui ont été appliquées à une ligne spécifique au cours d’une période digne d’intérêt. La table de l’historique par défaut est créée avec un arbre B rowstore cluster pour traiter efficacement ce cas d’utilisation.
Remarque
De manière générale, la documentation utilise le terme B-tree en référence aux index. Dans les index rowstore, le moteur de base de données implémente une structure B+. Cela ne s’applique pas aux index columnstore ou aux tables à mémoire optimisée. Pour plus d’informations, consultez le Guide de conception et d’architecture d’index SQL Server et Azure SQL.
Effectuer une analyse des données
Une fois que vous avez activé la version du système à l'aide de l'une des approches précédentes, l'audit des données n'est plus qu'une question à poser. La requête suivante recherche les versions de ligne dans la table Employee pour lesquelles EmployeeID = 1000 et qui ont été actives pendant au moins une partie de la période comprise entre le 1er janvier 2021 et le 1er janvier 2022 (limite supérieure comprise) :
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Remplacez FOR SYSTEM_TIME BETWEEN...AND par FOR SYSTEM_TIME ALL pour analyser l’historique complet des changements de données pour cet employé particulier :
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Pour rechercher les versions de ligne qui étaient actives uniquement pendant une période (et pas en dehors de celle-ci), utilisez CONTAINED IN. Cette requête est efficace, car elle interroge seulement la table de l’historique :
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Enfin, dans certains scénarios d’audit, vous pouvez voir l’aspect que présentait une table entière à n’importe quel point passé dans le temps :
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
Les tables temporelles avec versions gérées par le système stockent des valeurs pour les colonnes de période dans le fuseau horaire UTC, même si vous pouvez considérer qu’il est plus pratique de travailler dans votre fuseau horaire local, à la fois pour le filtrage des données et pour l’affichage des résultats. L’exemple de code suivant montre comment appliquer une condition de filtrage spécifiée dans le fuseau horaire local, puis convertie au format UTC en utilisant la clause AT TIME ZONE introduite dans SQL Server 2016 (13.x) :
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
La clause AT TIME ZONE est utile dans tous les autres scénarios faisant appel à des tables versionnées par le système.
Les conditions de filtrage spécifiées dans des clauses temporelles avec FOR SYSTEM_TIME sont dites SARG-able. SARG signifie argument de recherche, et SARG-able signifie que SQL Server peut utiliser l'index cluster sous-jacent pour effectuer une recherche au lieu d'une opération de balayage. Pour plus d’informations, consultez le Guide d'architecture et de conception de l'index SQL Server.
Si vous interrogez directement la table d’historique, vérifiez que votre condition de filtrage est aussi SARG-able en spécifiant des filtres sous la forme de <period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC'.
Si vous appliquez AT TIME ZONE à des colonnes de période, SQL Server effectue une analyse de table ou index, ce qui peut être très coûteux. Évitez ce type de condition dans vos requêtes :
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition.
Pour plus d’informations, consultez Interroger les données d'une table temporelle version système.
Analyses à un point dans le temps (voyage dans le temps)
Au lieu de se concentrer sur les modifications apportées aux enregistrements individuels, les scénarios de voyage temporel montrent comment l’ensemble des jeux de données changent au fil du temps. Parfois, le voyage dans le temps fait appel à plusieurs tables temporelles connexes, chacune évoluant à son propre rythme, dont vous pouvez analyser les éléments suivants :
- Tendances des indicateurs importants dans les données historiques et les données actuelles
- Instantané exact de la totalité des données « depuis » (AS OF) n’importe quel instant dans le passé (hier, il y a un mois, etc.)
- Différences entre deux points dans le temps dignes d’intérêt (il y a un mois et il y a trois mois, par exemple)
Il existe plusieurs scénarios concrets qui nécessitent une analyse des évolutions dans le temps. Pour illustrer ce scénario d’utilisation, nous allons examiner OLTP avec l’historique généré automatiquement.
OLTP avec l’historique des données généré automatiquement
Dans les systèmes de traitement transactionnel, vous pouvez analyser l’évolution de métriques importantes dans le temps. Dans l’idéal, l’analyse de l’historique ne doit pas compromettre les performances de l’application OLTP, où l’accès à l’état des données le plus récent doit se faire avec un minimum de latence et de verrouillage des données. Vous pouvez utiliser des tables temporelles avec versions gérées par le système pour permettre aux utilisateurs de conserver de façon transparente l’historique complet des modifications en vue d’une analyse ultérieure, séparément des données actuelles, avec un impact minime sur la charge de travail OLTP principale.
Pour les charges de travail de traitement transactionnel élevées, nous vous recommandons d’utiliser des tables temporelles versionnées par le système avec tables à mémoire optimisée ; ainsi, vous pouvez stocker les données actuelles en mémoire et l’historique complet des modifications sur le disque à moindres coûts.
Pour la table de l’historique, nous vous recommandons d’utiliser un index columnstore cluster pour les raisons suivantes :
L’analyse de tendances classique bénéficie des performances des requêtes que procure un index columnstore cluster.
La tâche de vidage des données avec des tables optimisées en mémoire fonctionne mieux sous une lourde charge de travail OLTP quand la table de l’historique a un index columnstore cluster.
Un index columnstore cluster fournit une excellente compression, surtout dans les scénarios où toutes les colonnes ne sont pas modifiées en même temps.
Utiliser des tables temporelles avec l’OLTP en mémoire réduit le besoin de conserver la totalité du jeu de données en mémoire et vous permet de différencier facilement les données à chaud des données à froid.
Parmi les exemples de scénarios concrets qui rentrent dans cette catégorie, citons la gestion des stocks ou la négociation en devises.
Le diagramme suivant montre un modèle de données simplifié utilisé pour la gestion de stocks :

L’exemple de code suivant crée la table ProductInventory comme table temporelle avec version système en mémoire, avec un index columnstore cluster sur la table de l’historique (qui remplace en fait l’index rowstore créé par défaut) :
Remarque
Vérifiez que votre base de données permet de créer des tables optimisées en mémoire. Consultez Création d’une table mémoire optimisée et d’une procédure stockée compilée en mode natif.
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
Pour le modèle ci-dessus, la procédure de gestion des stocks pourrait ressembler à ceci :
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
La procédure stockée spUpdateInventory insère un nouveau produit dans le stock ou met à jour la quantité du produit pour l’emplacement spécifique. La logique métier est simple et consiste à maintenir le dernier état exact en permanence en incrémentant/décrémentant le champ Quantity via la mise à jour de la table, tandis que les tables avec versions gérées par le système ajoutent de façon transparente une dimension d’historique aux données, comme l’illustre le diagramme ci-dessous.

À présent, l’interrogation du dernier état peut être effectuée efficacement dans le module compilé en mode natif :
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
L’analyse des changements de données au fil du temps devient facile avec la clause FOR SYSTEM_TIME ALL, comme l’illustre l’exemple suivant :
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
Le diagramme suivant montre l’historique des données pour un produit, que vous pouvez afficher facilement en important la vue ci-dessus dans Power Query, Power BI ou un outil décisionnel similaire :

Les tables temporelles peuvent être utilisées dans ce scénario pour effectuer d’autres types d’analyse de voyage dans le temps, tels que la reconstruction de l’état de l’inventaire à partir de n’importe quel point passé dans le temps AS OF ou la comparaison d’instantanés qui appartiennent à différents moments dans le temps.
Pour ce scénario d’usage, vous pouvez également convertir les tables Product et Location en tables temporelles, en vue d’analyser l’historique des modifications des données UnitPrice et NumberOfEmployee.
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Étant donné que le modèle de données implique maintenant plusieurs tables temporelles, la méthode recommandée pour une analyse AS OF consiste à créer une vue qui extrait les données nécessaires des tables connexes et à appliquer FOR SYSTEM_TIME AS OF à la vue, ce qui permet de simplifier sensiblement la reconstruction de l’état de l’ensemble du modèle de données :
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
La capture d’écran suivante montre le plan d’exécution généré pour la requête SELECT. Comme vous pouvez le constater, le moteur de base de données SQL Server prend en charge toute la complexité de la gestion des relations temporelles :

Le code suivant permet de comparer l’état du stock de produits entre deux points dans le temps (il y a un jour et il y a un mois) :
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Détection des anomalies
La détection d’anomalies (ou détection de valeurs hors norme) est l’identification des éléments qui ne sont pas conformes à un modèle attendu ou à d’autres éléments dans un jeu de données. Vous pouvez utiliser des tables temporelles avec version système pour détecter les anomalies qui se produisent régulièrement ou irrégulièrement, et vous pouvez effectuer des interrogations temporelles pour localiser rapidement des modèles spécifiques. Le type de données que vous collectez et votre logique métier déterminent la nature des anomalies.
L’exemple suivant illustre une logique simplifiée pour la détection des « pics » dans les chiffres de ventes. Supposons que vous travaillez avec une table temporelle qui collecte l’historique des produits achetés :
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
Le diagramme suivant montre les achats dans le temps :

En supposant que le nombre de produits achetés varie peu pendant les jours normaux, la requête suivante identifie les valeurs hors norme de singleton ; les échantillons présentent une différence significative (x2) par rapport à leurs voisins immédiats, tandis que les échantillons environnants ne diffèrent pas considérablement (moins de 20 %) :
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Remarque
Cet exemple est intentionnellement simplifié. Dans les scénarios de production, vous utilisez généralement des méthodes statistiques avancées pour identifier les échantillons qui ne suivent pas le modèle commun.
Dimension à variation lente
En règle générale, les dimensions d’entreposage de données contiennent des données relativement statiques sur les entités telles que des produits, des clients ou des emplacements géographiques. Toutefois, dans certains scénarios, vous devez également tracer les modifications de données dans des tables de dimension. Étant donné que les modifications de dimensions se produisent beaucoup moins fréquemment, de manière imprévisible et en dehors de la planification des mises à jour normales qui s’applique aux tables de faits, ces types de tables de dimension sont appelés dimensions à variation lente.
Il existe plusieurs catégories de dimensions à variation lente, selon la façon dont l’historique des modifications est conservé :
| Type de dimension | Détails |
|---|---|
| Type 0 | L’historique n’est pas conservé. Les attributs de dimension reflètent les valeurs d’origine. |
| Type 1 | les attributs de dimension reflètent les valeurs les plus récentes (les valeurs précédentes sont remplacées) |
| Type 2 | chaque version de membre de dimension représentée par une ligne distincte dans la table, généralement avec des colonnes qui représentent la période de validité |
| Type 3 | Conservation d’un historique limité pour des attributs sélectionnés en utilisant des colonnes supplémentaires dans la même ligne |
| Type 4 | conservation de l’historique dans la table distincte tandis que la table de dimension d’origine conserve les dernières versions des membres de dimension (actuelles) |
Quand vous choisissez une stratégie de dimension à variation lente (SCD), il revient à la couche ETL (extraction, transformation et chargement) d’assurer l’exactitude des tables de dimension, ce qui exige nécessite beaucoup de code complexe et une maintenance supplémentaire.
Grâce aux tables temporelles avec versions gérées par le système, vous pouvez réduire considérablement la complexité de votre code dans la mesure où l’historique des données est conservé automatiquement. La mise en œuvre reposant sur deux tables, les tables temporelles sont plus proches de la dimension à variation lente de type 4. Cependant, étant donné que les requêtes temporelles vous permettent de référencer seulement la table active, vous pouvez aussi envisager des tables temporelles dans les environnements où vous prévoyez d’utiliser la dimension à variation lente de type 2.
Pour convertir votre dimension normale en dimension à variation lente, vous pouvez créer une dimension ou en convertir une en table temporelle avec versions gérées par le système. Si votre table de dimension existante contient des données historiques, créez une table distincte, déplacez-y les données historiques, puis conservez les versions de dimension actuelles (réelles) dans votre table de dimension d’origine. Ensuite, utilisez la syntaxe ALTER TABLE pour convertir votre table de dimension en table temporelle avec version système avec une table de l’historique prédéfinie.
L’exemple suivant illustre le processus et suppose que la table de dimension DimLocation a déjà ValidFrom et ValidTo comme colonnes datetime2 non nullables, qui sont remplies par le processus ETL :
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
Aucun code supplémentaire n’est nécessaire pour gérer la dimension à variation lente pendant le processus de chargement de l’entrepôt de données, une fois la création effectuée.
L’illustration suivante montre comment vous pouvez utiliser des tables temporelles dans un scénario simple impliquant deux dimension à variation lente (DimLocation et DimProduct) et une table de faits.

Afin d'utiliser les anciennes dimension à variation lente dans les rapports, vous devez adapter efficacement les requêtes. Par exemple, vous souhaiterez calculer le montant total des ventes et le nombre moyen de produits vendus par habitant au cours des six derniers mois. Les deux métriques nécessitent la corrélation des données à partir de la table de faits et des dimensions dont les attributs importants pour l’analyse ont pu évoluer (DimLocation.NumOfCustomers, DimProduct.UnitPrice). La requête suivante calcule correctement les métriques requises :
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
À propos de l’installation
L’utilisation de tables temporelles versionnées par le système pour la dimension à variation lente est acceptable si la période de validité calculée selon l’heure de transaction de base de données est appropriée pour votre logique métier. Si vous chargez des données avec un délai important, l’heure de transaction peut ne pas être acceptable.
Par défaut, les tables temporelles avec versions gérées par le système n’autorisent pas la modification des données historiques après le chargement (vous pouvez modifier l’historique après avoir défini SYSTEM_VERSIONING sur OFF). Ceci peut constituer une limitation dans les cas où les données historiques sont régulièrement modifiées.
Les tables temporelles avec version système génèrent une version de ligne à chaque modification de la colonne. Si vous souhaitez supprimer les nouvelles versions à l’occasion de la modification d’une colonne spécifique, vous devez incorporer cette limitation dans la logique ETL.
Si vous prévoyez un nombre important de lignes d’historique dans les tables de dimension à variation lente, envisagez d’utiliser un index columnstore cluster comme option de stockage principal pour la table de l’historique. L’utilisation d’un index columnstore réduit l’empreinte de la table d’historique et accélère vos requêtes analytiques.
Réparez une altération des données au niveau des lignes
Vous pouvez vous baser sur les données historiques des tables temporelles versionnées par le système pour rétablir rapidement des lignes individuelles dans tout état précédemment capturé. Cette propriété des tables temporelles est utile quand vous pouvez localiser les lignes affectées et/ou que vous connaissez l’heure de la modification non souhaitée des données. Cette connaissance vous permet d’effectuer des réparations efficacement sans gérer les sauvegardes.
Cette approche présente plusieurs avantages :
Vous pouvez contrôler précisément l’étendue de la réparation. Les enregistrements qui ne sont pas affectés doivent rester au dernier état, ce qui est souvent une exigence critique.
L’opération est efficace et la base de données reste en ligne pour toutes les charges de travail utilisant les données.
L’opération de réparation elle-même fait l’objet d’une gestion des versions. Comme vous disposez d’une piste d’audit pour l’opération de réparation elle-même, vous pouvez analyser ce qu’il s’est passé ultérieurement si nécessaire.
L’action de réparation peut être automatisée relativement facilement. L’exemple de code suivant montre une procédure stockée qui effectue la réparation des données de la table Employee utilisée dans un scénario d’audit de données.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
Cette procédure stockée accepte @EmployeeID et @versionNumber en tant que paramètres d’entrée. Cette procédure restaure par défaut l’état de la ligne à la dernière version de l’historique (@versionNumber = 1).
L’illustration suivante montre l’état de la ligne avant et après l’appel de la procédure. Le rectangle rouge indique la version de ligne actuelle qui est incorrecte, tandis que le rectangle vert indique la version correcte de l’historique.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

Cette procédure stockée de réparation peut être définie pour accepter un horodatage exact au lieu de la version de ligne. Elle va restaurer la ligne à n’importe quelle version qui était active pour le point dans le temps fourni (autrement dit, AS OF point dans le temps).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
Pour le même exemple de données, l’image suivante illustre une scénario de réparation avec une condition de temps. Vous pouvez voir mis en évidence le paramètre @asOf, une ligne sélectionnée dans l’historique telle qu’elle était au point dans le temps fourni et la nouvelle version de la ligne dans la table active après l’opération de réparation :

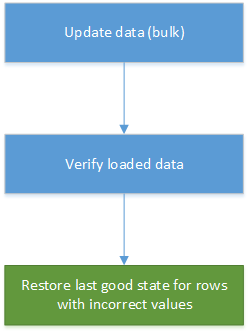
La correction des données peut être intégrée au processus de chargement automatisé des données dans les systèmes d’entreposage de données et de rapports. Si une valeur qui vient d’être mise à jour n’est pas correcte, dans de nombreux scénarios, restaurer la version précédente à partir de l’historique peut suffire. Le diagramme suivant montre comment ce processus peut être automatisé :
Contenu connexe
- Tables temporelles
- Bien démarrer avec les tables temporelles avec versions gérées par le système
- Vérifications de cohérence système des tables temporelles
- Partition avec des tables temporelles
- Considérations et limitations liées aux tables temporelles
- Sécurité de la table temporelle
- Tables temporelles avec version gérée par le système avec tables à mémoire optimisée
- Vues et fonctions des métadonnées des tables temporelles