Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
SQL Server Distributed Replay n’est pas disponible avec SQL Server 2022 (16.x) et versions ultérieures.
La fonctionnalité Microsoft SQL Server Distributed Replay vous aide à évaluer l’impact de futures mises à niveau de SQL Server. Vous pouvez aussi l’utiliser pour évaluer l’impact de mises à niveau du matériel et du système d’exploitation ainsi que de l’optimisation de SQL Server.
Dépréciation de Distributed Replay dans SQL Server 2022
Distributed Replay est déconseillé à partir de SQL Server 2022 (16.x), comme indiqué dans les fonctionnalités du moteur de base de données déconseillées dans SQL Server 2022 (16.x). Distributed Replay a une dépendance à SQL Server Native Client (SNAC), qui a été supprimé de SQL Server 2022 (16.x). Cette modification est documentée sur la page Stratégies de prise en charge pour SQL Server Native Client. De plus, Distributed Replay s’appuie sur des fichiers .trc, qui sont capturés à l’aide de Trace SQL et de SQL Server Profiler, deux fonctionnalités qui sont également abandonnées.
Distributed Replay Controller a été supprimé du programme d’installation de SQL Server 2022 (16.x) et Distributed Replay Client n’est plus disponible dans SQL Server Management Studio (SSMS) à compter de la version 18. Pour obtenir Distributed Replay Controller, vous devez installer SQL Server 2019 (15.x) ou une version antérieure. Pour obtenir le Distributed Replay Client, vous devez installer SSMS 17.9.1.
Pour les clients sous SQL Server 2022 (16.x), une alternative consiste à utiliser les utilitaires RML (Replay Markup Language), qui comprennent ostress, pour relire une charge de travail.
Avantages de Distributed Replay
Comme SQL Server Profiler, vous pouvez utiliser Distributed Replay pour relire une trace capturée sur un environnement de test mis à niveau. Contrairement à SQL Server Profiler, Distributed Replay n’est pas limité à la relecture d'une charge de travail depuis un seul ordinateur.
Distributed Replay offre une solution plus scalable que SQL Server Profiler. Avec Distributed Replay, vous pouvez relire des charges de travail de plusieurs ordinateurs et mieux simuler une charge de travail critique.
La fonctionnalité Distributed Replay peut utiliser plusieurs ordinateurs pour relire les données de trace et simuler une charge de travail critique. Utilisez Distributed Replay pour tester la compatibilité des applications, tester les performances ou planifier la capacité.
Quand utiliser Distributed Replay
Les fonctionnalités de SQL Server Profiler et de Distributed Replay se chevauchent quelque peu.
Vous pouvez utiliser SQL Server Profiler pour relire une trace capturée sur un environnement de test mis à niveau. Vous pouvez également analyser les résultats de la relecture pour rechercher d’éventuelles incompatibilités de fonctions et de performances. Cependant, SQL Server Profiler ne peut relire une charge de travail que d’un seul ordinateur. Pendant la relecture d’une application OLTP intensive présentant de nombreuses connexions simultanées actives ou un débit élevé, SQL Server Profiler peut devenir un goulot d’étranglement des ressources.
Distributed Replay offre une solution plus scalable que SQL Server Profiler. Utilisez-le pour relire une charge de travail depuis plusieurs ordinateurs et mieux simuler des charges de travail critiques.
Le tableau suivant explique à quel moment utiliser chacun des outils.
| Outil | À utiliser quand... |
|---|---|
| SQL Server Profiler | Vous souhaitez utiliser le mécanisme de relecture classique sur un ordinateur unique. En particulier, vous avez besoin de fonctions de débogage ligne par ligne, telles que les commandes Étape, Exécuter jusqu’au curseuret Basculer le point d’arrêt. Vous souhaitez relire une trace Analysis Services. |
| Relecture Distribuée | Vous souhaitez évaluer la compatibilité des applications. Par exemple, vous souhaitez tester des scénarios de mise à niveau de SQL Server et du système d'exploitation, des mises à niveau du matériel ou des paramétrages d'index. La concurrence dans la trace capturée est si élevée qu’un seul client de relecture ne suffit pas à la simuler. |
Concepts de Distributed Replay
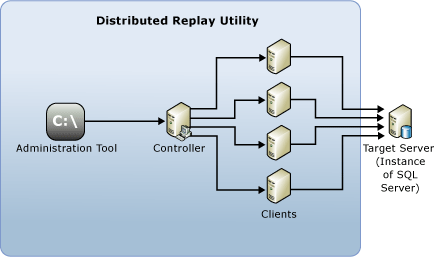
Les composants suivants constituent l'environnement de Distributed Replay :
Outil d'administration Distributed Replay : une application console, DReplay.exe, utilisée pour communiquer avec le contrôleur de relecture distribuée. Utilisez l’outil d’administration pour contrôler la relecture distribuée.
Contrôleur Distributed Replay : un ordinateur exécutant le service Windows nommé contrôleur Distributed Replay SQL Server . Le contrôleur Distributed Replay orchestre les actions des clients Distributed Replay. Chaque environnement Distributed Replay ne doit contenir qu'une seule instance de contrôleur.
Clients Distributed Replay : un ou plusieurs ordinateurs (physiques ou virtuels) qui exécutent le service Windows nommé client Distributed Replay SQL Server . Les clients Distributed Replay fonctionnent ensemble pour simuler des charges de travail sur une instance de SQL Server. Chaque environnement Distributed Replay peut contenir un ou plusieurs clients.
Serveur cible : une instance de SQL Server que les clients Distributed Replay peuvent utiliser pour relire les données de trace. Nous conseillons de placer le serveur cible dans un environnement de test.
L'outil d'administration Distributed Replay, le contrôleur et le client peuvent être installés sur différents ordinateurs ou sur le même ordinateur. Il ne peut exister qu'une instance du contrôleur Distributed Replay ou du service client en cours d'exécution sur le même ordinateur.
L'illustration suivante montre l'architecture physique Distributed Replay de SQL Server :
Tâches de Distributed Replay
| Description de la tâche | Article |
|---|---|
| Fournit des explications sur la configuration de Distributed Replay. | Configurer Distributed Replay |
| Explique comment préparer les données de trace d'entrée. | Préparer les données de trace d’entrée |
| Fournit des explications sur la relecture des données de trace. | Relire les données de trace |
| Décrit comment examiner les résultats des données de trace de Distributed Replay. | Revoir les résultats du replay |
| Décrit comment utiliser l’outil d’administration pour lancer, surveiller et annuler des opérations sur le contrôleur. | Options de ligne de commande de l'outil d'administration (Distributed Replay Utility) |
Spécifications
Avant d’utiliser la fonctionnalité Distributed Replay, examinez les spécifications du produit décrites dans cet article.
Spécifications des traces d’entrée
Pour que les données de trace puissent être correctement relues, elles doivent répondre à des spécifications de version et de format et contenir des événements et des colonnes obligatoires.
Versions des traces d’entrée
Distributed Replay prend en charge les données de trace d'entrée recueillies dans les versions suivantes de SQL Server:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (Mise à jour cumulative 1 et versions ultérieures - consultez versions de la build de SQL Server 2017)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formats des traces d’entrée
Les données de trace d'entrée peuvent se présenter sous l'un des formats suivants :
Un fichier de trace unique ayant l'extension
.trc.Un jeu de fichiers de trace de substitution qui suivent la convention d’affectation des noms de substitution de fichier, par exemple :
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Événements et colonnes des traces d’entrée
Les données de trace d'entrée doivent contenir des événements et des colonnes spécifiques pour pouvoir être relues par Distributed Replay. Le modèle TSQL_Replay , dans SQL Server Profiler , contient tous les événements et toutes les colonnes obligatoires, ainsi que des informations supplémentaires. Pour plus d’informations sur ce modèle, consultez Exigences de reprise.
Avertissement
Si vous n’utilisez pas le modèle TSQL_Replay pour capturer les données de trace d’entrée, ou si les conditions applicables aux traces d’entrée ne sont pas satisfaites, vous pouvez recevoir des résultats de relecture inattendus.
Vous pouvez également créer un modèle de trace personnalisé et l'utiliser pour relire des événements avec Distributed Replay, à condition que ce modèle contienne les événements suivants :
- Auditer la connexion
- Déconnexion liée à l'audit
- Connexion existante
- Paramètre de sortie RPC
- RPC : Terminé
- RPC : Démarrage
- SQL : BatchCompleted
- SQL :BatchStarting
Si vous relisez des curseurs côté serveur, les événements suivants sont également obligatoires :
- FermerCurseur
- CursorExecute
- Ouverture du curseur
- CursorPrepare
- CursorUnprepare
Si vous relisez des instructions SQL préparées côté serveur, les événements suivants sont également obligatoires :
- Sql préparé par Exec
- Préparer SQL
Toutes les données de trace d'entrée doivent contenir les colonnes suivantes :
- Classe d'événements
- Séquence d'événements
- Données textuelles
- Nom d’application
- Nom d'utilisateur
- Nom de la base de données
- ID de base de données
- Nom d'hôte
- Données Binaires
- SPID
- Heure de début
- Heure de fin
- IsSystem
Combinaisons de traces d’entrée et de serveurs cibles prises en charge
Le tableau suivant répertorie les versions de données de trace prises en charge et, pour chacune d'entre elles, les versions de SQL Server prises en charge avec lesquelles les données peuvent être relues.
| Version des données des traces d’entrée | Versions de SQL Server prises en charge pour l’instance du serveur cible |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Configuration système requise
Les systèmes d'exploitation pris en charge pour exécuter l'outil d'administration et les services contrôleur et clients sont les mêmes que dans votre instance SQL Server . Pour plus d’informations sur les systèmes d’exploitation pris en charge pour votre instance SQL Server, consultez Exigences matérielles et logicielles pour SQL Server 2019.
Les fonctionnalités Distributed Replay sont prises en charge à la fois sur les systèmes d'exploitation basés sur des processeurs x86 et ceux basés sur des processeurs x64. Pour les systèmes d'exploitation basés sur des processeurs x64, seul le mode Windows on Windows (WOW) est pris en charge.
Limitations de l’installation
Un ordinateur ne peut avoir qu'une seule instance de chaque fonctionnalité Distributed Replay installée. Le tableau suivant indique le nombre d'installations autorisées pour chaque fonctionnalité dans un même environnement Distributed Replay.
| Fonctionnalité de Répétition Distribuée | Nombre maximal d'installations par environnement de réexécution |
|---|---|
| Service du contrôleur SQL Server Distributed Replay | 1 |
| Service du client SQL Server Distributed Replay | 16 (ordinateurs physiques ou virtuels) |
| Outil d'administration | Illimité |
Remarque
Bien qu'une seule instance de l'outil d'administration puisse être installée sur un même ordinateur, vous pouvez en démarrer plusieurs instances. Les commandes émises depuis plusieurs outils d'administration sont résolues dans l'ordre de leur réception.
Fournisseur d’accès aux données
Distributed Replay ne prend en charge que le fournisseur d'accès aux données SQL Server ODBC Native Client.
Spécifications pour la préparation du serveur cible
Nous conseillons de placer le serveur cible dans un environnement de test. Pour relire les données de trace avec une instance SQL Server différente de celle qui a servi à les enregistrer, vérifiez que les opérations suivantes ont été effectuées sur le serveur cible :
Toutes les connexions et tous les utilisateurs contenus dans les données de trace doivent être présents dans la même base de données sur le serveur cible.
Toutes les connexions et tous les utilisateurs présents sur le serveur cible doivent avoir les mêmes autorisations que sur le serveur d'origine.
Les ID de base de données sur la cible doivent idéalement être identiques à ceux qui sont sur la source. Si ce n’est pas le cas, la mise en correspondance peut être effectuée sur la base du DatabaseName s’il est présent dans la trace.
La base de données par défaut de chaque connexion contenue dans les données de trace doit être définie (sur le serveur cible) en tant que base de données cible relative à la connexion. Par exemple, les données de trace à relire contiennent les activités de la connexion Freddans la base de données Fred_Db située sur l’instance d’origine de SQL Server. Par conséquent, sur le serveur cible, la base de données par défaut de la connexion Freddoit être la base de données correspondant à Fred_Db (même si le nom de la base de données est différent). Pour définir la base de données par défaut de la connexion, utilisez la procédure stockée système
sp_defaultdb.
La relecture d’événements associés à des connexions manquantes ou incorrectes va entraîner des erreurs de relecture, mais l’opération de relecture va se poursuivre.