Vue d’ensemble du réplica de stockage
Le réplica de stockage est la technologie de Windows Server qui permet une réplication de volumes entre des serveurs ou des clusters en cas de récupération d’urgence. Il vous permet également de créer des clusters de basculement étendus qui englobent deux sites, tout en maintenant l’ensemble des nœuds synchronisés.
Le réplica de stockage prend en charge la réplication synchrone et asynchrone :
- La réplication synchrone permet la mise en miroir des données dans des sites en réseau à faible latence avec des volumes cohérents en cas d’incident, ce qui garantit l’absence de perte de données au niveau du système de fichiers en cas de panne.
- La réplication asynchrone assure la mise en miroir des données entre des sites situés hors des zones métropolitaines sur des liaisons de réseau à latence élevée, mais sans garantie que les deux sites aient des copies identiques des données au moment de la panne.
Pourquoi utiliser le réplica de stockage ?
Le réplica de stockage offre des fonctionnalités de préparation aux situations d’urgence et de récupération d’urgence dans Windows Server. Windows Server garantit l’absence totale de perte de données, avec la possibilité de protéger de façon synchrone les données dans différents racks, étages, bâtiments, campus, régions et villes. Après un incident, toutes les données sont intactes ailleurs sans aucune perte. Il en est de même avant un incident. En effet, le réplica de stockage vous offre la possibilité de placer les charges de travail en lieu sûr avant une catastrophe, si vous en êtes averti quelques instants avant, encore une fois sans perte de données.
Le réplica de stockage permet une utilisation plus efficace de plusieurs centres de données. En étendant ou en répliquant des clusters, les charges de travail peuvent être exécutées dans plusieurs centres de données pour un accès plus rapide aux données par des applications et utilisateurs de proximité locaux, ainsi qu’une meilleure distribution de la charge et utilisation des ressources de calcul. Si un incident met un centre de données hors connexion, vous pouvez déplacer temporairement ses charges de travail classiques sur l’autre site.
Le réplica de stockage peut vous permettre de mettre hors service des systèmes de réplication de fichiers tels que DFS, qui ont été activés dans des solutions de récupération d’urgence d’entrée de gamme. Même si la réplication DFS fonctionne bien sur des réseaux à très faible bande passante, sa latence est élevée (souvent mesurée en heures ou en jours). Cela est dû à l’obligation de fermer les fichiers et à ses limitations artificielles destinées à empêcher l’encombrement du réseau. De par ces caractéristiques de conception, les fichiers les plus récents et les plus sensibles d’un réplica DFSR sont les moins susceptibles d’être répliqués. Le réplica de stockage fonctionne sous le niveau de fichier et ne présente aucune de ces restrictions.
Le réplica de stockage prend également en charge la réplication asynchrone pour des plages plus importantes et des réseaux à latence plus élevée. Comme il n’est pas basé sur un point de contrôle et effectue plutôt une réplication en continu, le delta des modifications a tendance à être beaucoup plus faible par rapport aux produits basés sur un instantané. Le réplica de stockage fonctionne au niveau de la partition et réplique donc tous les instantanés VSS créés par Windows Server ou par le logiciel de sauvegarde. En utilisant des instantanés VSS, il permet d’utiliser des instantanés de données cohérents avec l’application pour une récupération à un point dans le temps, en particulier les données utilisateur non structurées répliquées de manière asynchrone.
Configurations prises en charge
Vous pouvez déployer le réplica de stockage dans un cluster étendu, entre des configurations de cluster à cluster et de serveur à serveur (voir les schémas 1 à 3).
Un cluster étendu permet la configuration des ordinateurs et du stockage dans un seul cluster, où certains nœuds partagent un ensemble de stockage asymétrique et d’autres nœuds en partagent un autre, puis effectuent une réplication synchrone ou asynchrone avec reconnaissance des sites. Ce scénario peut utiliser des espaces de stockage avec un stockage SAS partagé, un réseau SAN et des numéros d’unité logique connectés par iSCSI. Il est géré avec PowerShell et l’outil graphique Gestionnaire du cluster de basculement, et permet le basculement automatisé de la charge de travail.

FIGURE 1 : Réplication du stockage dans un cluster étendu à l’aide du réplica de stockage
La configuration de cluster à cluster autorise la réplication entre deux clusters distincts, où un cluster se réplique de façon synchrone ou asynchrone avec un autre cluster. Ce scénario peut utiliser des espaces de stockage direct, des espaces de stockage avec un stockage SAS partagé, un réseau SAN et des numéros d’unité logique connectés par iSCSI. Il est géré avec Windows Admin Center et PowerShell, et nécessite une intervention manuelle pour le basculement.
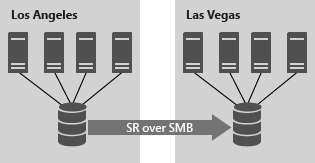
FIGURE 2 : Réplication du stockage de cluster à cluster à l’aide du réplica de stockage
La configuration de serveur à serveur autorise la réplication synchrone et asynchrone entre deux serveurs autonomes, en utilisant des espaces de stockage avec un stockage SAS partagé, un réseau SAN, des numéros d’unité logique connectés par iSCSI et des lecteurs locaux. Il est géré avec Windows Admin Center et PowerShell, et nécessite une intervention manuelle pour le basculement.
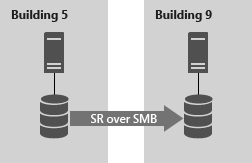
FIGURE 3 : Réplication du stockage de serveur à serveur à l’aide du réplica de stockage
Notes
Vous pouvez également configurer la réplication d’un serveur, en utilisant quatre volumes distincts sur un seul ordinateur. Toutefois, ce guide ne couvre pas ce scénario.
Fonctionnalités de réplica de stockage
Aucune perte de données, réplication au niveau du bloc. Avec la réplication synchrone, il n’existe aucun risque de perte de données. Avec la réplication au niveau du bloc, il n’existe aucun risque de verrouillage de fichier.
Déploiement et gestion simples. Le réplica de stockage est spécialement conçu pour être simple d’utilisation. La création d’un partenariat de réplication entre deux serveurs peut utiliser Windows Admin Center. Le déploiement de clusters étendus utilise un Assistant intuitif de l’outil familier Gestionnaire du cluster de basculement.
Invité et hôte. Toutes les fonctions du réplica de stockage sont exposées à la fois dans les déploiements basés sur l’invité et sur l’hôte virtualisés. Cela signifie que les invités peuvent répliquer leurs volumes de données même s’ils sont exécutés sur des plateformes de virtualisation autres que Windows ou dans des clouds publics, tant qu’ils utilisent Windows Server dans l’invité.
SMB3. Le réplica de stockage utilise la technologie mature et reconnue de SMB3, commercialisée pour la première fois dans Windows Server 2012. Cela signifie que toutes les caractéristiques avancées de SMB (telles que la prise en charge de Multichannel et SMB Direct sur les cartes réseau RoCE, iWARP et RDMA InfiniBand) sont disponibles pour le réplica de stockage.
Sécurité. Contrairement aux produits de nombreux fournisseurs, une technologie de sécurité de pointe est intégrée au réplica de stockage. Cela inclut la signature des paquets, le chiffrement intégral des données AES-128-GCM, la prise en charge de l’accélération du chiffrement AES-NI d’Intel et la prévention des attaques de l’intercepteur « man in the middle » de l’intégrité de l’authentification préalable. Le réplica de stockage utilise Kerberos AES256 pour toutes les authentifications entre les nœuds.
Synchronisation initiale hautes performances. Le réplica de stockage prend en charge la synchronisation initiale amorcée, où il existe déjà un sous-ensemble de données sur une cible provenant de copies, de sauvegardes ou de lecteurs livrés plus anciens. La réplication initiale copie uniquement les blocs différents, ce qui peut raccourcir la durée de synchronisation initiale et empêcher que les données n’utilisent une bande passante limitée. Les réplicas de stockage bloquent le calcul de la somme de contrôle et l’agrégation signifie que les performances de la synchronisation initiale sont limitées uniquement par la vitesse du réseau et du stockage.
Groupes de cohérence. La demande d’écriture garantit que des applications telles que Microsoft SQL Server peuvent écrire dans plusieurs volumes répliqués et savoir que les données sont écrites sur le serveur de destination de façon séquentielle.
Délégation d’utilisateur. Des autorisations peuvent être déléguées aux utilisateurs pour gérer la réplication sans être membres du groupe Administrateurs intégré sur les nœuds répliqués, ce qui limite leur accès à des zones non liées.
Contrainte de réseau. Le réplica de stockage peut être limité à des réseaux individuels par serveur et par volumes répliqués, afin de fournir la bande passante à l’application, à la sauvegarde et au logiciel de gestion.
Allocation dynamique. L’allocation dynamique des appareils SAN et des espaces de stockage est prise en charge afin de fournir des temps de réplication initiale presque instantanés dans de nombreuses situations. Une fois la réplication initiale lancée, le volume ne peut pas être réduit ni tronqué
Compression. Le réplica de stockage propose la compression des données transférées sur le réseau entre le serveur source et le serveur de destination. La compression du réplica de stockage pour le transfert de données est uniquement prise en charge dans Windows Server Datacenter : Édition Azure à compter de la build du système d’exploitation 20348.1070 et ultérieure (KB5017381).
Le réplica de stockage inclut les fonctionnalités suivantes :
| Fonctionnalité | Détails |
|---|---|
| Type | Basé sur l’hôte |
| Synchrone | Oui |
| Asynchrone | Oui |
| Indépendante du matériel de stockage | Oui |
| Unité de réplication | Volume (partition) |
| Création du cluster étendu Windows Server | Oui |
| Réplication de serveur à serveur | Oui |
| Réplication de cluster à cluster | Oui |
| Transport | SMB3 |
| Réseau | TCP/IP ou RDMA |
| Prise en charge de la contrainte de réseau | Oui |
| Compression réseau | Oui** |
| RDMA* | iWARP, InfiniBand, RoCE v2 |
| Configuration requise du pare-feu du port réseau de réplication | Port IANA unique (TCP 445 ou 5445) |
| Multipath/Multichannel | Oui (SMB3) |
| Prise en charge Kerberos | Oui (SMB3) |
| Chiffrement simultané et signature | Oui (SMB3) |
| Basculements par volume autorisés | Oui |
| Prise en charge du stockage alloué dynamiquement | Oui |
| Interface utilisateur de gestion intégrée | PowerShell, Gestionnaire du cluster de basculement |
*Peut nécessiter un câblage et un équipement supplémentaires sur le long terme. **Lors de l’utilisation de Windows Server Datacenter : Édition Azure à partir de la build du système d’exploitation 20348.1070
Conditions préalables pour le réplica de stockage
Forêt des services de domaine Active Directory.
Espaces de stockage avec JBOD SAS, espaces de stockage direct, SAN Fibre Channel, VHDX partagé, cible iSCSI ou stockage SAS/SCSI/SATA local. Disque SSD ou plus rapide recommandé pour les lecteurs de journaux de réplication. Microsoft recommande que le stockage des journaux soit plus rapide que le stockage des données. Les volumes de journal ne doivent jamais être utilisés pour d’autres charges de travail.
Au moins une connexion Ethernet/TCP sur chaque serveur pour la réplication synchrone, mais de préférence RDMA.
Au moins 2 Go de RAM et deux cœurs par serveur.
Un réseau entre les serveurs, avec une bande passante suffisante pour contenir votre charge d’écriture d’E/S et une latence d’opération complète d’au maximum 5 ms pour la réplication synchrone. La réplication asynchrone n’a pas de recommandation de latence.
Windows Server Datacenter Edition ou Windows Server Standard Edition. Le réplica de stockage s’exécutant sur Windows Server, Standard Edition, présente les limitations suivantes :
- Vous devez utiliser Windows Server 2019 ou version ultérieure
- Le réplica de stockage réplique un seul volume au lieu d’un nombre illimité de volumes.
- Les volumes peuvent avoir une taille allant jusqu’à 2 To au lieu d’une taille illimitée.
Arrière-plan
Cette section fournit des informations sur les termes généraux liés au secteur d’activité, la réplication synchrone et asynchrone, ainsi que les principaux comportements.
Termes généraux liés au secteur d’activité
La récupération d’urgence fait référence à un plan d’urgence pour la récupération suite à des catastrophes survenues sur un site afin que l’activité puisse continuer. La récupération d’urgence des données indique plusieurs copies des données de production à un emplacement physique distinct, par exemple un cluster étendu, où la moitié des nœuds se trouve sur un site et l’autre moitié sur un autre. La préparation aux situations d’urgence fait référence à un plan d’urgence pour déplacer à titre préventif les charges de travail vers un autre emplacement avant un incident annoncé, par exemple un ouragan.
Les contrats de niveau de service définissent la disponibilité des applications d’une entreprise et leur tolérance en matière de temps d’arrêt et de perte des données pendant les interruptions planifiées et non planifiées. L’objectif de délai de récupération définit la durée pendant laquelle l’entreprise peut tolérer une inaccessibilité totale des données. L’objectif de point de récupération définit la quantité de données que l’entreprise peut se permettre de perdre.
Réplication synchrone
La réplication synchrone garantit que l’application écrit les données à deux emplacements à la fois avant la fin de l’opération d’E/S. Cette réplication est plus adaptée aux données stratégiques, car elle nécessite des investissements dans le réseau et le stockage, et risque de dégrader les performances des applications en imposant l’écriture dans deux emplacements.
Quand des écritures d’application se produisent sur la copie des données sources, le stockage d’origine n’accuse pas immédiatement réception des E/S. Au lieu de cela, ces modifications de données sont répliquées sur la copie de destination distante et renvoient un accusé de réception. Ce n’est qu’à ce moment-là que l’application reçoit l’accusé de réception des E/S. Cela garantit une synchronisation constante du site distant avec le site source, tout en étendant les E/S de stockage sur le réseau. Dans le cas d’une défaillance du site source, les applications peuvent basculer vers le site distant et reprendre leurs opérations avec l’assurance de ne perdre aucune donnée.
| Mode | Diagramme | Étapes |
|---|---|---|
| Synchrone Aucune perte de données RPO |
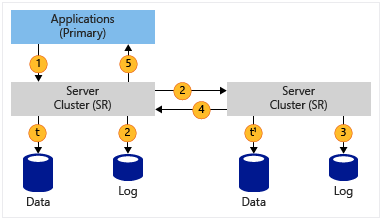 |
1. L’application écrit des données 2. Les données du journal sont écrites et les données sont répliquées sur le site distant 3. Les données du journal sont écrites sur le site distant 4. Accusé de réception du site distant 5. Réception de l’écriture d’application confirmée t & t1 : données vidées sur le volume, journaux toujours écrits en continu |
Réplication asynchrone
À l’inverse, la réplication asynchrone signifie que, quand l’application écrit des données, ces données sont répliquées sur le site distant sans garantie de recevoir un accusé de réception immédiatement. Ce mode permet de répondre plus rapidement à l’application et propose une solution de récupération d’urgence qui fonctionne géographiquement.
Quand l’application écrit des données, le moteur de réplication capture l’écriture et confirme immédiatement réception à l’application. Les données capturées sont ensuite répliquées vers l’emplacement distant. Le nœud distant traite la copie des données et renvoie tardivement un accusé de réception à la copie source. Étant donné que les performances de la réplication ne sont plus dans le chemin d’accès E/S de l’application, la réactivité et la distance du site distant sont des facteurs moins importants. Il existe un risque de perte de données si la source de données est perdue et que la copie de destination des données était toujours en mémoire tampon sans quitter la source.
Avec son objectif de point de récupération supérieur à zéro, la réplication asynchrone est moins adaptée pour les solutions HA (haute disponibilité) telles que les clusters de basculement, car elles sont conçues pour un fonctionnement continu avec redondance et sans perte de données.
| Mode | Diagramme | Étapes |
|---|---|---|
| Asynchrone Pratiquement aucune perte de données (dépend de plusieurs facteurs) RPO |
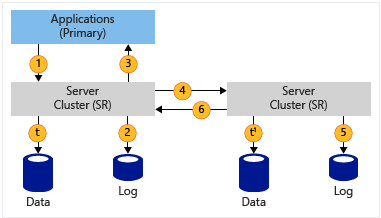 |
1. L’application écrit des données 2. Données du journal écrites 3. Réception de l’écriture d’application confirmée 4. Données répliquées sur le site distant 5. Données du journal écrites sur le site distant 6. Accusé de réception du site distant t & t1 : données vidées sur le volume, journaux toujours écrits en continu |
Principaux points d’évaluation et comportements
Bande passante réseau et latence avec stockage plus rapide. Il existe des limitations physiques concernant la réplication synchrone. Comme le réplica de stockage implémente un mécanisme de filtrage des E/S utilisant des journaux et nécessitant des boucles réseau, la réplication synchrone est susceptible de ralentir les écritures de l’application. En utilisant une faible latence, les réseaux à large bande passante ainsi que les sous-systèmes de disque de haut débit pour les journaux, vous réduisez la surcharge de performances.
Le volume de destination n’est pas accessible lors de la réplication dans Windows Server 2016. Quand vous configurez la réplication, le volume de destination est démonté, ce qui le rend inaccessible à toute lecture ou écriture par les utilisateurs. Sa lettre de pilote peut être visible dans des interfaces classiques telles que Explorateur de fichiers, mais une application ne peut pas accéder au volume lui-même. Les technologies de réplication au niveau du bloc ne sont pas compatibles avec le fait d’autoriser l’accès au système de fichier monté de la cible de destination dans un volume. NTFS et ReFS ne prennent pas en charge l’écriture de données dans le volume par les utilisateurs alors que les blocs sont en train de changer.
L’applet de commande Test-Failover a fait ses débuts dans Windows Server version 1709, et a également été incluse dans Windows Server 2019. Elle prend désormais en charge le montage temporaire d’un instantané en lecture-écriture du volume de destination pour les sauvegardes, les tests, etc. Pour plus d’informations, consultez Forum aux questions sur le réplica de stockage.
L’implémentation Microsoft de la réplication asynchrone est différente de la plupart. La plupart des implémentations du secteur d’activité de la réplication asynchrone s’appuie sur la réplication basée sur un instantané, où les transferts différentiels réguliers passent sur l’autre nœud et fusionnent. La réplication asynchrone du réplica de stockage fonctionne exactement comme la réplication synchrone, sauf qu’elle supprime la nécessité d’un accusé de réception synchrone sérialisé à partir de la destination. Cela signifie que le réplica de stockage a théoriquement un objectif de point de récupération inférieur, car la réplication est permanente. Toutefois, cela signifie également qu’il repose sur la garantie de cohérence d’application interne au lieu d’utiliser des instantanés pour forcer la cohérence dans les fichiers d’application. Le réplica de stockage garantit la cohérence d’incident dans tous les modes de réplication
De nombreux clients utilisent la réplication DFS comme solution de récupération d’urgence, même si elle est souvent peu pratique pour ce scénario. Incapable de répliquer les fichiers ouverts, elle est conçue pour minimiser l’utilisation de la bande passante au détriment des performances, ce qui conduit à des deltas de point de récupération importants. Le réplica de stockage peut vous permettre de retirer la réplication DFS de certains types de tâche de récupération d’urgence.
Le réplica de stockage n’est pas une solution de sauvegarde. Certains environnements informatiques déploient des systèmes de réplication en tant que solutions de sauvegarde, en raison de leurs options de perte nulle de données par rapport aux sauvegardes quotidiennes. Le réplica de stockage réplique toutes les modifications dans tous les blocs de données sur le volume, quel que soit le type de modification. Si un utilisateur supprime toutes les données d’un volume, le réplica de stockage réplique la suppression instantanément sur l’autre volume, en supprimant définitivement les données des deux serveurs. N’utilisez pas le réplica de stockage en remplacement d’une solution de sauvegarde jusqu’à une date et une heure données.
Le réplica de stockage n’est pas identique au réplica Hyper-V ni aux groupes de disponibilité AlwaysOn Microsoft SQL. Le réplica de stockage est un moteur indépendant du stockage à usage général. Par définition, il ne peut pas adapter son comportement de façon aussi idéale que la réplication au niveau de l’application. Cela peut entraîner des lacunes de fonctionnalités spécifiques qui vous encouragent à déployer ou conserver des technologies de réplication d’application particulières.
Notes
Ce document répertorie les problèmes connus ainsi que les comportements prévus, et comprend une section Forum Aux Questions.
Terminologie relative au réplica de stockage
Ce guide utilise souvent les termes suivants :
La source est le volume d’un ordinateur qui permet des écritures en local et effectue une réplication sortante. Également appelée « volume principal ».
La destination est le volume d’un ordinateur qui ne permet pas des écritures en local et effectue une réplication entrante. Également appelée « volume secondaire ».
Un partenariat de réplication est la relation de synchronisation entre un ordinateur source et un ordinateur de destination pour un ou plusieurs volumes et utilise un seul journal.
Un groupe de réplication est l’organisation des volumes et de leur configuration de réplication au sein d’un partenariat, sur chaque serveur. Un groupe peut contenir un ou plusieurs volumes.
Nouveautés du réplica de stockage
Pour obtenir une liste de nouvelles fonctionnalités du réplica de stockage dans Windows Server 2019, consultez Nouveautés du stockage